生信入门马拉松之R语言基础-脚本项目管理、条件循环、表达矩阵和一丢丢数据挖掘(Day 7)
原创生信入门马拉松之R语言基础-脚本项目管理、条件循环、表达矩阵和一丢丢数据挖掘(Day 7)
原创
R语言基础学习笔记-Day7
1. 复习
- R包stringr
字符串操作的几个函数-长度、拆分、提取、字符检测、替换和删除。
数据框函数- 排序arrange()和desc参数、distinct()去重复、mutate()数据框新增列
注意??没有赋值就没有改变
- 管道符号%>%-实现连续的步骤非常易读
- 彩虹代码展现嵌套函数的逻辑。
- if条件语句:如果。。。就。。。
2. 脚本项目管理、条件循环
2.1 长脚本管理方式
2.1.1 不想运行且不想删除的代码:用if函数
if(T){...},代码运行
凡是带有{}的代码,均可以被折叠
下载数据的代码,保留但不反复运行,用if(F){...},可以控制其不运行但保留。
2.1.2 分成多个脚本,每个脚本最后保存Rdata,下一个脚本开头清空再加载。
save(pd,exp,gpl,file = "steploutput,Rdata"),这句代码将几个第一个脚本有用的变量保存到Rdata文件中,下次使用这些变量时直接加载load这个Rdata文件即可。方便快捷。多个脚本衔接靠Rdata文件实现。
2.1.3 为什么用Rdata而不是表格文件来衔接?
- 变量,自带变量名称,不需要再次赋值,也没有参数。?developer/article/2410016/undefined
- 表格文件需要赋值,读取参数不同导致读取结果不同,不能在后续代码中同等处理。
- Rdata可以保存多个变量,下次使用只需要一次load可以的到多个数据。 -Rdata不仅可以保存数据框,也可以保存其他任何数据结构,包括复杂的对象! 非常方便有历史代码记录,可重复性相当相当高,衔接非常非常奈斯棒棒!
2.2 实战项目的组织方式(两种方式非常奈斯和棒棒!)
2.2.1 组织方式一:
Rproject的工作目录,保存Rdata(文件夹),输入文件(文件夹)、输出文件(文件夹)、输出图片文件夹、脚本和Rmd文件。
组织方式一眼就很舒服,而且容易找寻,分门别类保存。
加载保存Rdata(文件夹)的Rdata文件:
读取:surv = read.table("import/xxx.txt")#tab键一键保存
保存:save(x,file = "Rdata/xxx.Rdata")
在工作目录外其他地方,以上两个代码不能读取成功。
2.2.2 组织方式二(小洁老师现在使用方式):
拆分1个项目为多个子项目(道理类似于脚本拆分子脚本),每个子项目为1个文件夹,每个文件夹一个Rproject; load("../1_data-pre(工作目录的隔壁文件夹)/xxx.Rdata")#访问隔壁文件夹的文件代码,..的意思是工作目录的上一级。
2.3 if条件语句
- 控制代码运行
- else if(F){}啥都不敢 if(F){}elese{}#运行else后的{}中的代码
2.4 ifelse函数
- 只有3个参数
ifelse(x,yes,no)
x:逻辑或逻辑值向量
yes:逻辑值T时返回的值
no,逻辑值F时返回的值
ifelse函数和str_detect()函数连用,王炸炸炸!!!
#ifelse()+str_detect(),王炸
samples = c("tumor1","tumor2","tumor3","normal1","normal2","normal3")
k1 = str_detect(samples,"tumor");k1
ifelse(k1,"tumor","normal")#检测samples中是否含有tumor关键词。
k2 = str_detect(samples,"normal");k2
ifelse(k2,"tumor","normal")#堪称学术造假的没有报错的错误!!!!!!
ifelse(k2,"normal","tumor")#检测samples中是否含有normal关键词。【小洁老师语录】没有报错只是最低要求,只是符合代码规则,要看是否达到目的。
2.5 多个条件
#### (3)多个条件
#代码1
i = 0
if (i>0){
print('+')
} else if (i==0) {
print('0')
} else if (i< 0){
print('-')
}#多个条件
#代码2
ifelse(i>0,"+",ifelse(i<0,"-","0"))#嵌套!!!代码2实现结果和代码1相同2.6 练习
library(dplyr)
x = c(-1,-1,4,5,2,0)
case_when(x>0 ~ "A",
x==0 ~ "0",
T ~"B")#取代不易读的ifelse函数。跟多个条件的两句代码比较看哈!!
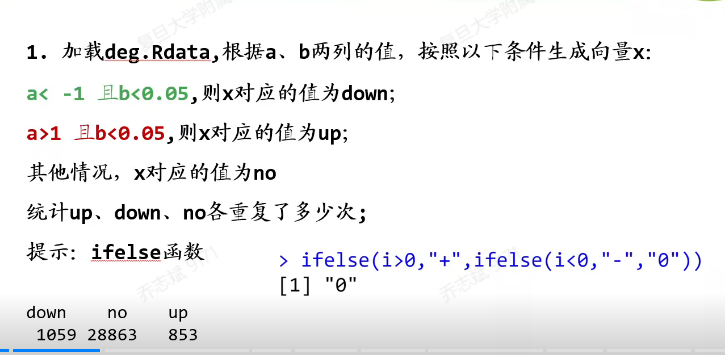
load("deg.Rdata")
k1 = deg$a< -1 & deg$b <0.05
k2 = deg$a>1 & deg$b <0.05
x <- ifelse(k1,"down",ifelse(k2,"up","no"))
table(x)
a <- deg$a
b <- deg$b
x <- ifelse((a< -1 & b<0.05),"down",ifelse((a>1 & b<0.05),"up","no"))#我的错误代码,小洁老师曾经讲过的点,我又犯了是a< -1或a<(-1),而不是a<-1,<-是赋值符号,我这样写a<-1,相当于又将a赋值了,所以结果错误。
table(x)2.7 for循环
对x里的每个元素进行同一操作
for(i in x){CODE}#x是向量;i是代称,i自动等于某个循环里的x元素
for( i in 1:4){
print(i)
}#for循环跑4次,i在第一次循环是1,第二次是2.。。第四次是4。【小洁老师语录】当一个代码需要复制粘贴3次以上时,要不写成函数,要不写成循环。
2.8 应用for循环:
#批量画图
par(mfrow = c(2,2))
for(i in 1:4){
plot(iris[,i],col = iris[,5])
}
#批量装包
pks = c("tidyr","dplyr","stringr")
for(g in pks){
if(!require(g,character.only = T))
install.packages(g,ask = F,update = F)#参数先忽略,可以自己探索查询看意思哦!2.9 隐式循环
apply(x,MARGIN,FUN,...)#x是数据框/矩阵名;MARGIN为1表示行,为2表示列,FUN是函数
test<- iris[1:6,1:4]
apply(test, 2, mean)#对test每一列求平均值
apply(test, 1, sum)#对test每一行求和- 向量/列表的隐式循环-lapply,批量操作
### 2.lapply(list, FUN, …)
# 对列表/向量中的每个元素实施相同的操作
lapply(1:4,rnorm)
x = list(a = 1:10,
b = rnorm(16),
c = seq(1,3,0.1))
slpply(x,length)#返回结果是个列表,用sapply(x,length)代码会返回一个向量2.10 两个数据框的连接
test1 <- data.frame(name = c('jimmy','nicker','Damon','Sophie'),
blood_type = c("A","B","O","AB"))
test1
test2 <- data.frame(name = c('Damon','jimmy','nicker','tony'),
group = c("group1","group1","group2","group2"),
vision = c(4.2,4.3,4.9,4.5))
test2
library(dplyr)
inner_join(test1,test2,by="name")
left_join(test1,test2,by="name")#左边更重要,右边的有的留没有不留
right_join(test1,test2,by="name")#右连接
full_join(test1,test2,by="name")#左右数据都保留思考题
如何挑出30个数里最大的5个?
x= rnorm(30)
tail(sort(x),5)
head(sort(x,decreasing = T),5)
2.11 练习
#1. 加载test1.Rdata,将两个数据框按照probe_id列连接在一起,按共同列取交集
load("test1.Rdata")
library(dplyr)
merge1 <- merge(dat,ids,by = "probe_id")
merge <- inner_join(dat,ids,by="probe_id")
class(merge)
#2. 找出logFC最小的10个基因和logFC最大的10个基因(symbol列就是基因名)
x <- arrange(merge,logFC)
x
head(x$symbol,10)
tail(x$symbol,10)记得检查目的有没有达到
3. 表达矩阵相关画图
3.1 表达矩阵画箱线图
- 数据:表达矩阵
- 画箱线图代码的模版:
ggplot(data = <DATA数据框>)+geom_point(mapping = aes(x = ?,y = ?))# ?是列名
3.2 表达矩阵和画图函数对应的参数要求不一致。怎么办?更改数据的文件类型。
表达矩阵需要变化
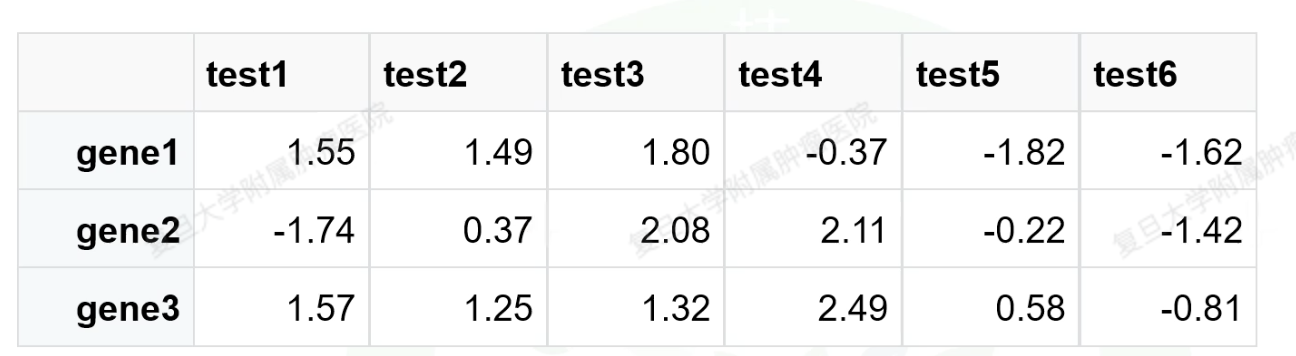
3.2.1 初始的表达矩阵:
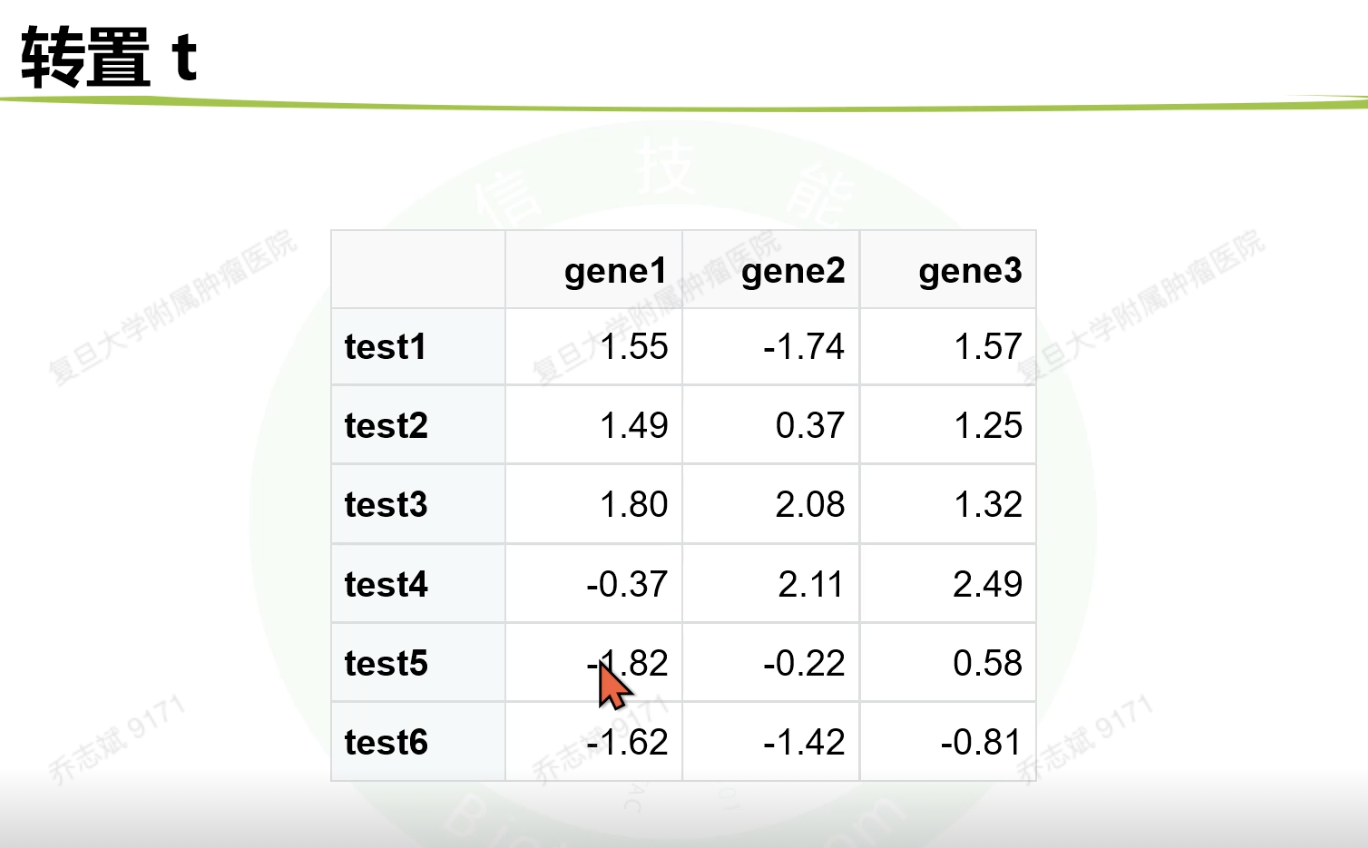
3.2.2 转置(行变列,列变行)
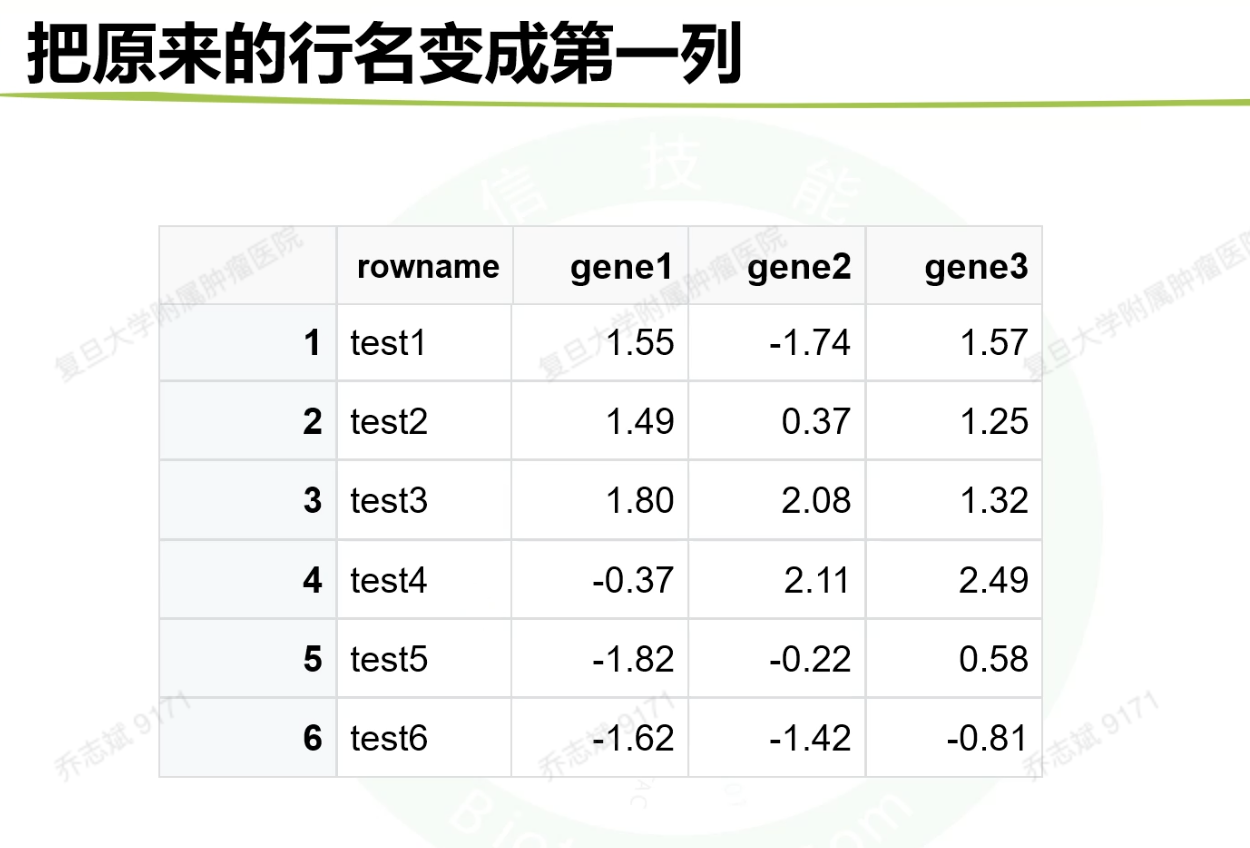
3.2.3 把原来的行名变成第一列
3.2.4 变形(宽变长)


一定要先单独学会某个包/函数,才能应用它吗?
不一定!克服畏难心理哟!!以下代码实现上述操作!
# 表达矩阵
set.seed(10086)#使rnorm返回的可重复需要加上的代码。
exp = matrix(rnorm(18),ncol = 6)
exp = round(exp,2)#四舍五入round(exp),取小数点后两位的函数round(exp,2)
rownames(exp) = paste0("gene",1:3)
colnames(exp) = paste0("test",1:6)
exp[,1:3] = exp[,1:3]+1
exp
library(tidyr)
library(tibble)
library(dplyr)
dat = t(exp) %>%
as.data.frame() %>%
rownames_to_column() %>%
mutate(group = rep(c("control","treat"),each = 3))
#rownames_to_colum()函数可以将行名改为一列
pdat = dat%>%
pivot_longer(cols = starts_with("gene"),
names_to = "gene",
values_to = "count")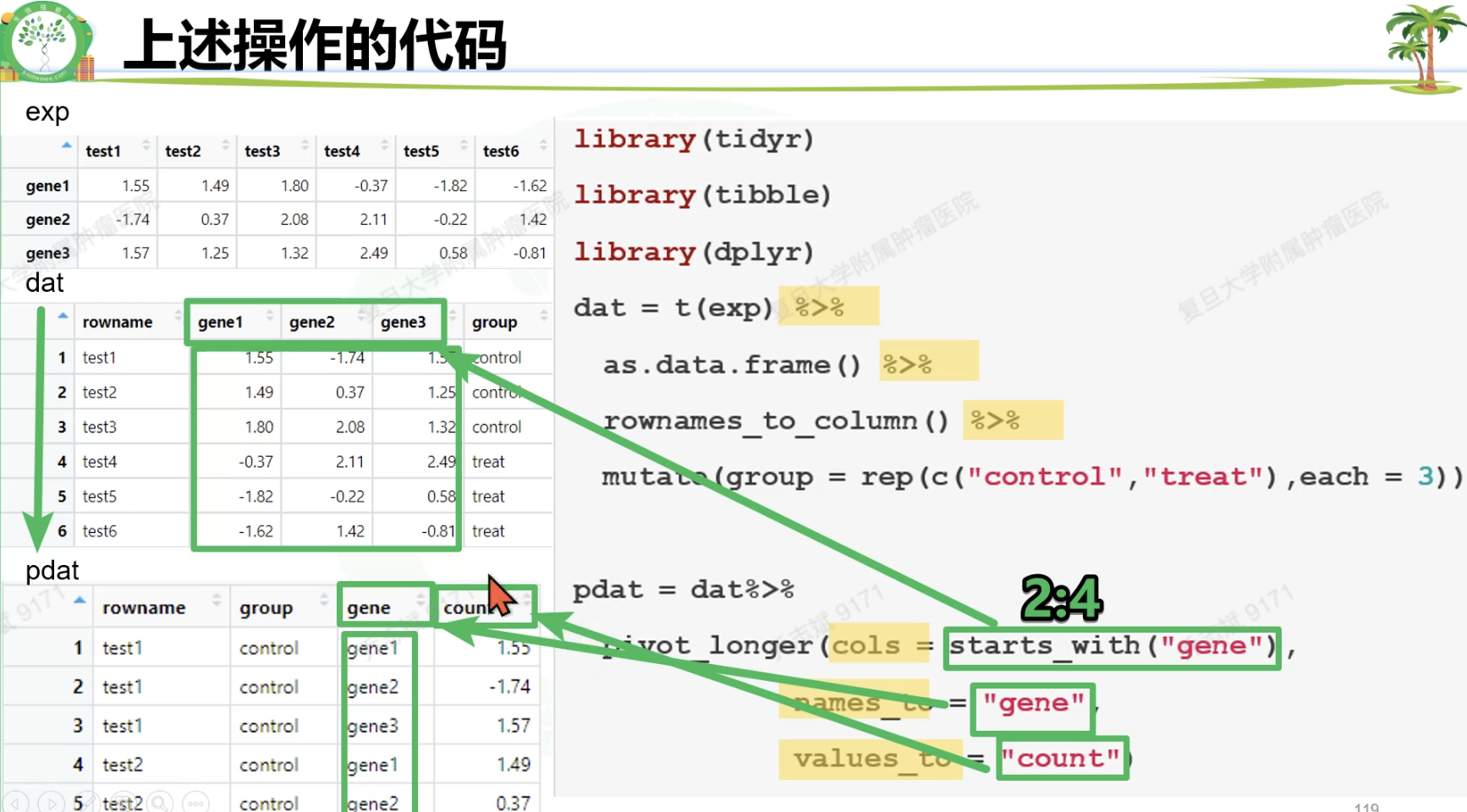

4. 一些顶呱呱的函数
match()
dir()
file.create()
file.exists()
file.remove()
自学哦!
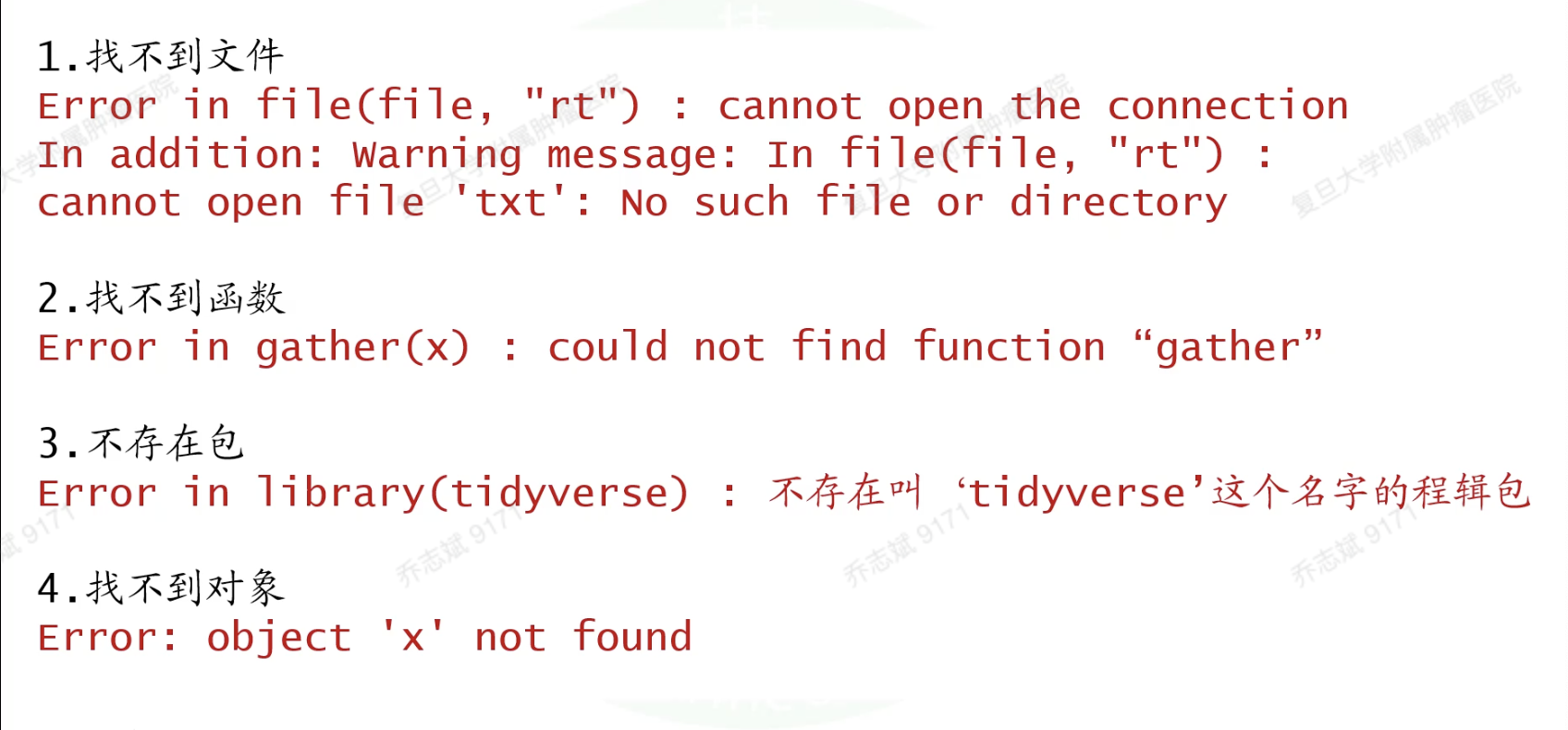
5. 四个报错
- 找不到文件
- 找不到函数
- 不存在包
- 找不到对象
6. 生信实战中R语言的几个重点函数

【小洁老师语录】编程能力,就是解决问题的能力,也是变优秀的能力
R语言基础入门课程-到此结束
7. 数据挖掘
生信技能树 小洁老师
7.1 为什么数据挖掘?
- 广义基因6w+个;哪些和自己感兴趣点有关?数据分析筛选。
- 表达矩阵:一行是一个基因在所有样品里的表达,一列是一个样本里所有基因的表达。
- 在表达矩阵中,寻找在不同组有表达差异的基因。
7.2 数据库:
GEO:啥数据都有
7.2.1 肿瘤专属:
TCGA、ICGC、CCLE、SEER(只能win软件下载)
7.3 什么类型数据可以挖掘
3套数据有3套流程,不可共用!
- 基因表达芯片
- 转录组
- 单细胞
- 突变、甲基化、拷贝数变异。。。
7.4 怎么筛选基因?
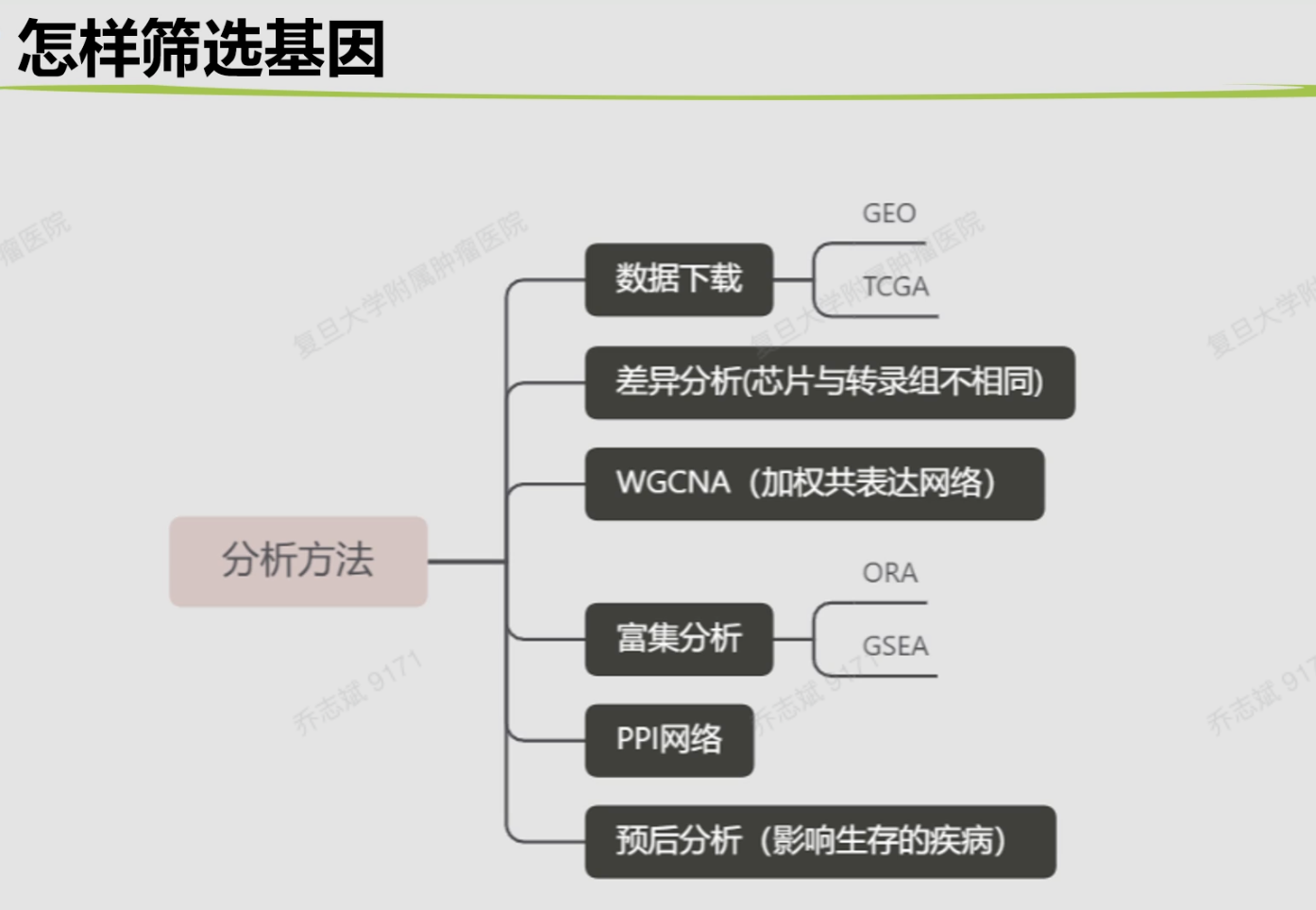
- 富集分析-找功能
- PPI网络:蛋白互作-相关文献
7.5 常见图表
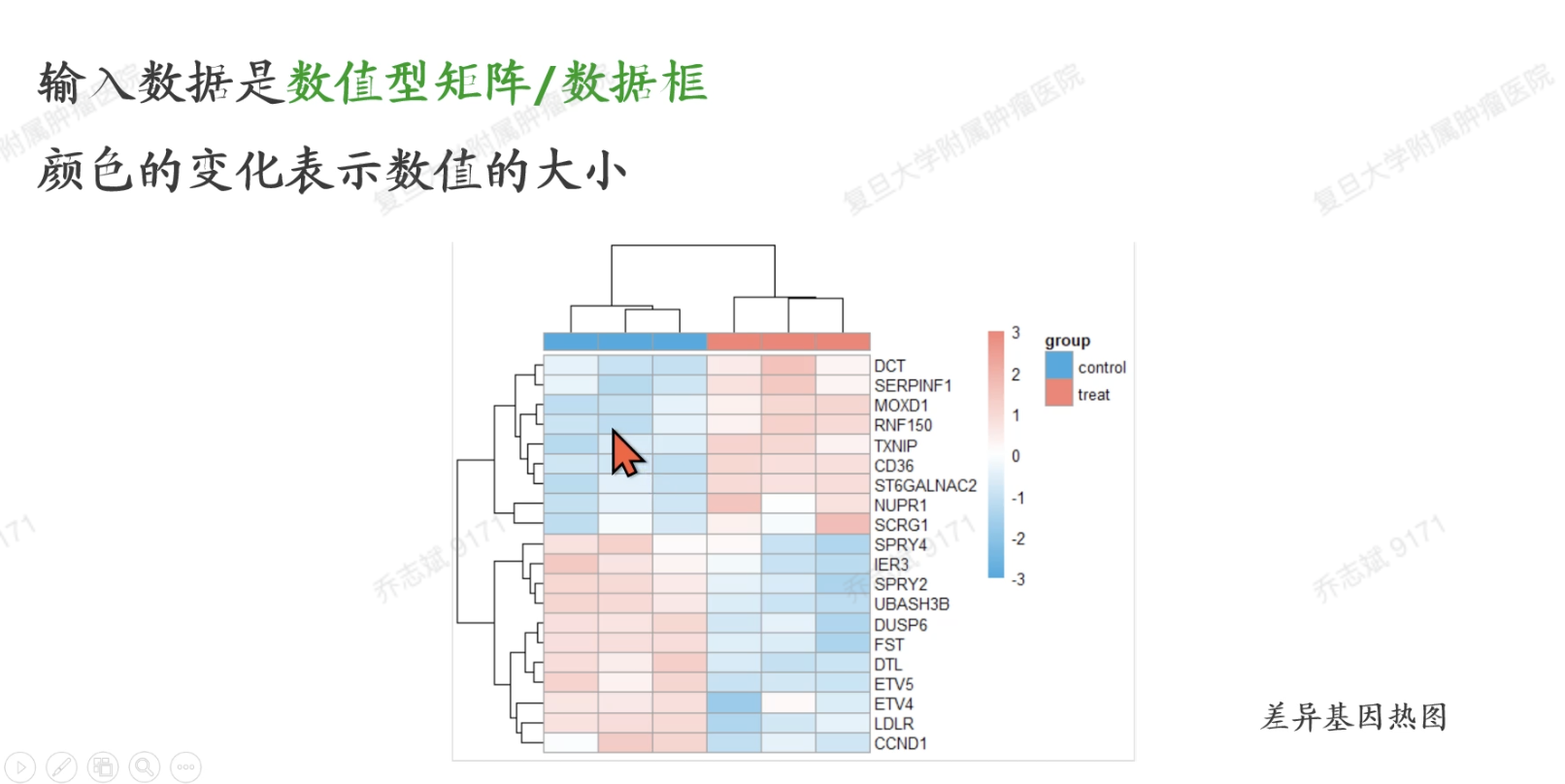
7.5.1 热图
输入数据是数值型矩阵/数据框
颜色变化表示数值大小
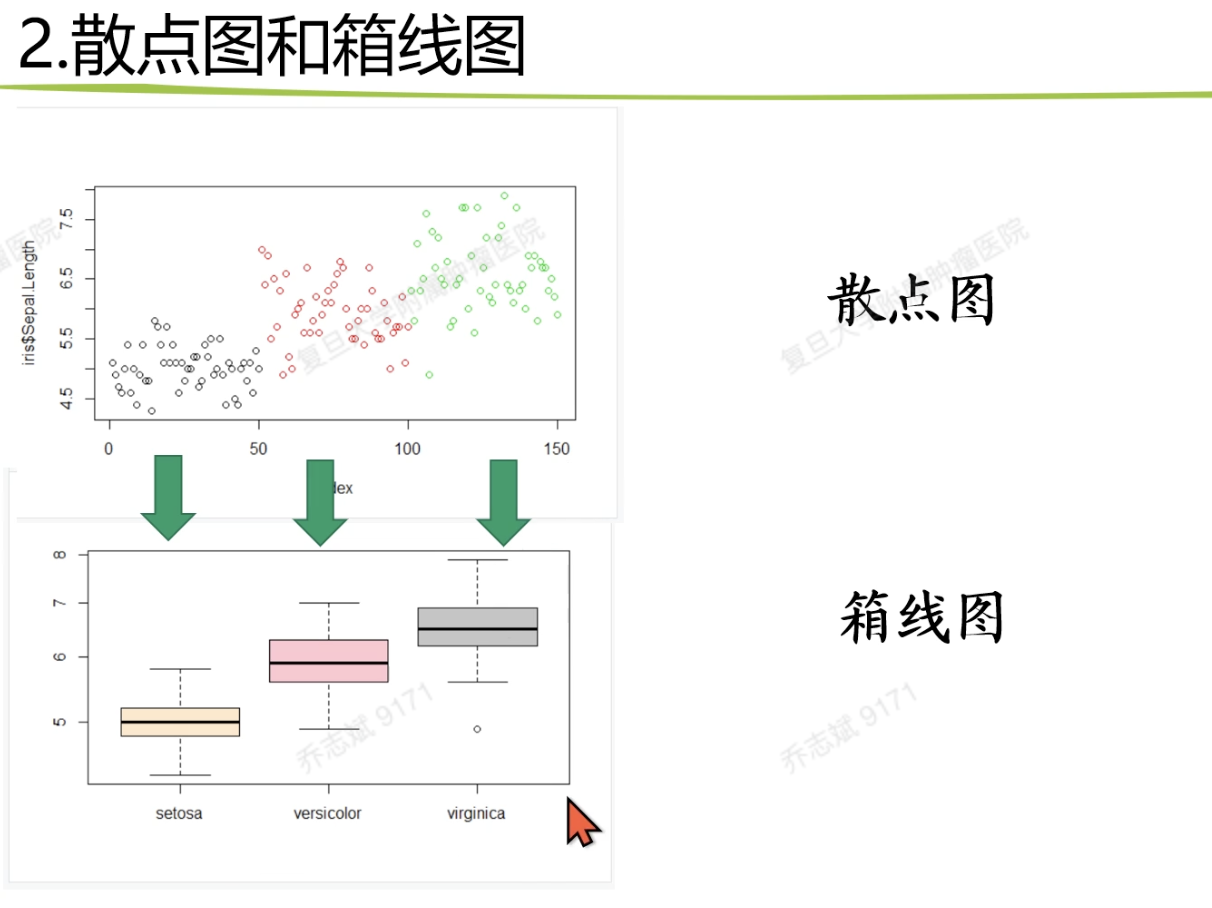
7.5.2 散点图和箱线图
- 散点图
向量即可画图
可以帮助理解箱线图
- 箱线图
输入数据是一个连续型向量(大小变化关系)和一个有重复值的离散型向量
- 五条线:
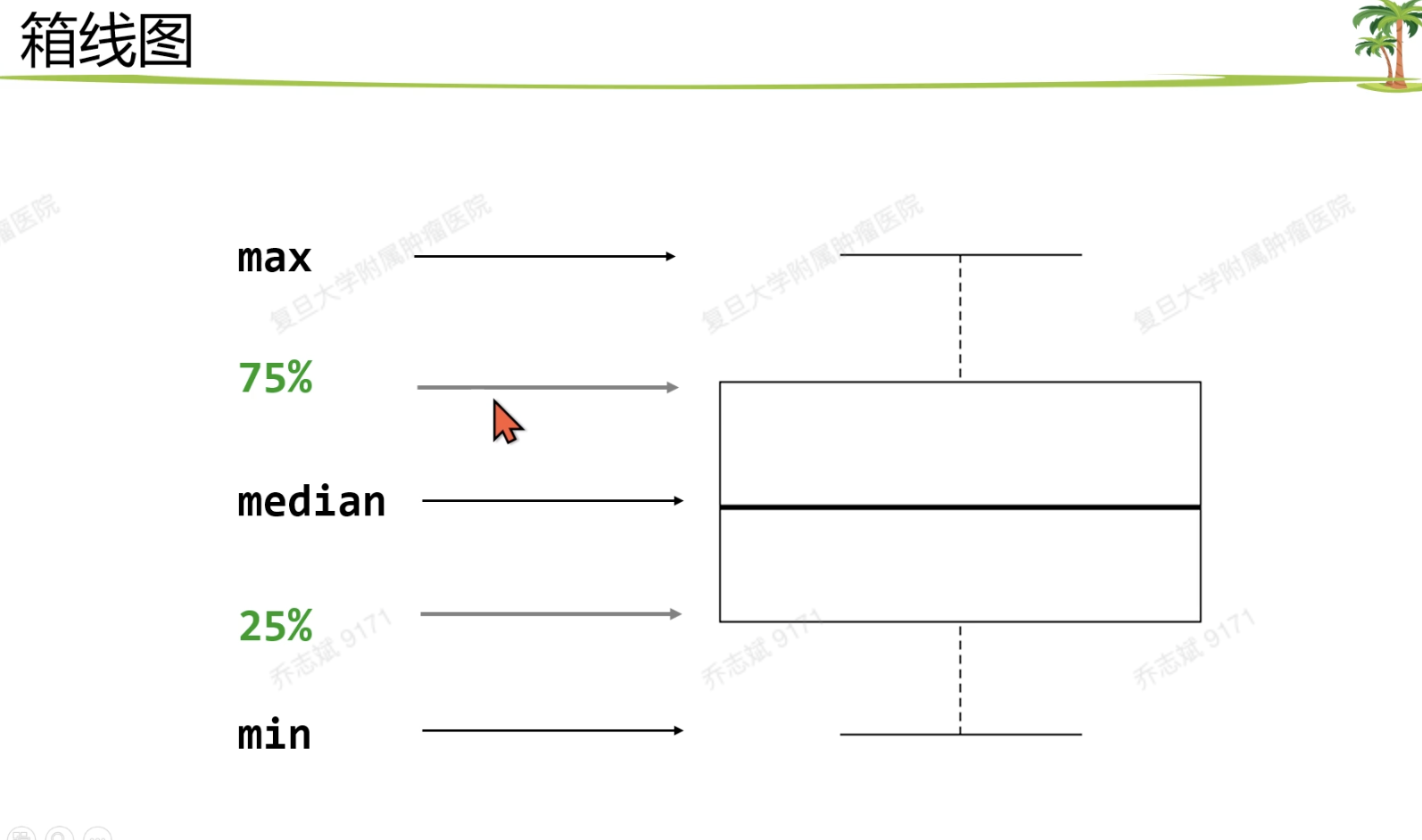
箱体越扁,数据重复性好,箱体越大,数据越分散。
7.5.3 箱线图的应用
单个基因在两组之间表达量的差异可视化。
分组信息:是一个有重复值的离散型的向量,分组向量的元素和表达矩阵的列是一一对应的。
7.5.4 火山图
多基因,差异分析---火山图
Foldchange(FC):处理组平均值/对照组平均值
logFoldchange(FC):Foldchang取log2
【小洁老师语录】芯片差异分析的起点是一个取过log的表达矩阵;如果拿到的是未log的矩阵,需要自行log。
理解logFC哦
处理-对照,反了全错

7.6 练习
纵坐标已经是log后的表达量,两个基因的logFC等于?

答案是5和-4
生信技能树
生信入门马拉松
小洁老师
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。