实战 | 使用YOLOv8 Pose实现瑜伽姿势识别
实战 | 使用YOLOv8 Pose实现瑜伽姿势识别

视觉/图像重磅干货,第一时间送达!

介绍
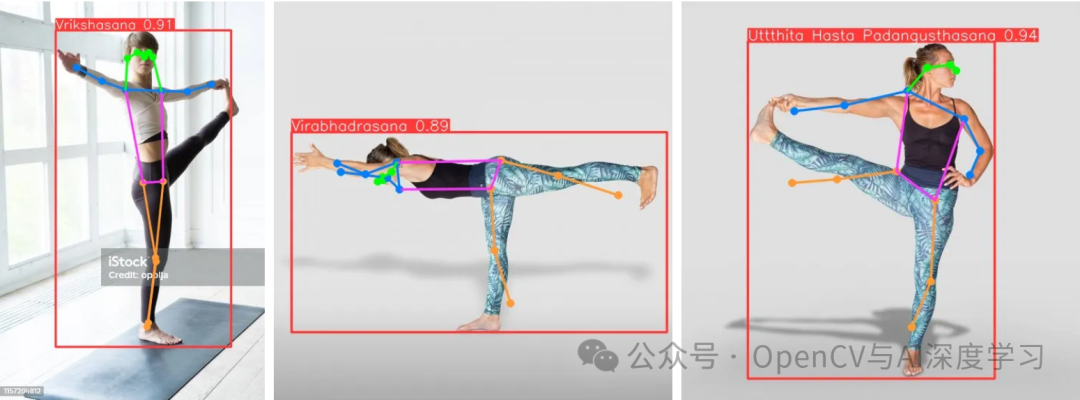
瑜伽是一种古老的运动,近年来由于其对身心健康的众多益处而广受欢迎。随着人们对瑜伽的兴趣日益浓厚,对能够准确分类瑜伽姿势的自动化系统的需求也越来越大。本文中我们将探讨如何使用 YOLOv8 Pose(一种先进的对象检测模型)对图像和视频中的瑜伽姿势进行分类。
我们将讨论以下主题:

1. YOLOv8 Pose简介
YOLO(You Only Look Once)是一种流行的实时目标检测算法,以其速度和准确性而闻名。YOLOv8 Pose 是 YOLOv8 的扩展,专为人体姿势估计而设计。它可以实时检测和分类人体关键点,使其成为瑜伽姿势分类的理想选择。
2. 数据准备
在开始之前,需要一个包含各种瑜伽姿势的图像或视频的数据集,以及身体关键点的相应标注。确保您的数据集结构良好且组织良好。

使用 Roboflow 的瑜伽姿势分类数据集
https://universe.roboflow.com/new-workspace-mujgg/yoga-pose3. 在Google Colab上训练YOLOv8 Pose
要在 Google Colab 上训练 YOLOv8 Pose,请按照以下步骤操作:
A. 将您的 roboflow 数据集或手动注释的数据集上传到 Google Drive 的单独文件夹(例如 Yoga)中,以便在 Colab 中轻松访问。
B. 创建一个新的 Colab 笔记本并安装您的 Google Drive:
from google.colab import drive
drive.mount('/content/drive')C. 安装所需的依赖项:
%pip install ultralytics
import ultralyticsD. 准备YOLO 格式的数据集和标注。
E. 为您的自定义数据集创建一个 YAML 文件(例如 data.yaml):
#data.yaml
train: /content/drive/MyDrive/yoga_data/train/images
val: /content/drive/MyDrive/yoga_data/val/images
nc: 5 # Number of classes (yoga poses)
names: ['pose1', 'pose2', 'pose3', 'pose4', 'pose5']F. 开始训练YOLOv8 Pose:
!yolo train model=yolov8n.pt data=data.yaml epochs=200 imgsz=640从 Gdrive 中的 running/pose/train/weights/best.pt 下载模型。
确保根据您的数据集和首选项调整超参数和路径。
此代码将模型及其权重保存到指定目录。
4. 在本地使用自定义训练模型进行模型预测
模型训练完成后,您可以使用以下代码片段进行预测:
在Opencv中查看:
import numpy as np
from ultralytics import YOLO
import cv2
import cvzone
import math
import time
cap = cv2.VideoCapture(0) # For Video
model = YOLO("../models/yolov8n.pt")
classNames = ["Bitilasana", "Lotus Pose","Tree Pose",....
] #include all the class names
prev_frame_time = 0
new_frame_time = 0
while True:
new_frame_time = time.time()
success,img = cap.read()
results = model(img,stream=True,verbose=False)
for r in results:
boxes = r.boxes
for box in boxes:
x1,y1,x2,y2 = box.xyxy[0]
x1,y1,x2,y2 = int(x1),int(y1),int(x2),int(y2)
w,h = x2-x1,y2-y1
cvzone.cornerRect(img,(x1,y1,w,h))
conf = math.ceil((box.conf[0]*100))/100
cls = int(box.cls[0])
cvzone.putTextRect(img,f'{classNames[cls]} {conf}',(max(0,x1),max(35,y1)),scale=1)
fps = 1/(new_frame_time - prev_frame_time)
prev_frame_time = new_frame_time
print(fps)
cv2.imshow("Image",img)
cv2.waitKey(1)或者创建单独的 conda 或 Venv 或 Pipenv 环境
pip install ultralytics
#in terminalfrom ultralytics import YOLO
# Load the YOLO model
model = YOLO("../models/best.pt") #colab custom trained model
Perform object detection on the image
results = model(source='Yoga.jpg',save=True, conf=0.7)
#For video
results = model(source='Yoga.mp4',save=True, conf=0.7)
简单地使用预训练模型来预测姿势手动标注:
from ultralytics import YOLO
# Load the YOLO model
model = YOLO('yolov8m-pose.pt')
# Define a class mapping dictionary
class_mapping = {
0: 'Pose1', # The key is the class id, you may need to adjust according to your model
# Add more mappings as needed
}
# Perform object detection on the image
results = model(source='Pose1.jpg')
# Replace class names with custom labels in the results
for result in results:
for cls_id, custom_label in class_mapping.items():
if cls_id in result.names: # check if the class id is in the results
result.names[cls_id] = custom_label # replace the class name with the custom label
# Perform object detection on the image
results = model(source='Pose1.jpg',save=True, conf=0.7)

本文分享自 OpenCV与AI深度学习 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与?腾讯云自媒体分享计划? ,欢迎热爱写作的你一起参与!