生信技能树-R语言-day5
原创生信技能树-R语言-day5
原创
课前
github最新版本的包有问题,如何解决
1,旧版本,需要giuhub软件
2,从别人的已安装该包的电脑上找一个
如何找:运行代码找找到位置
.libpaths()
找到和包一样名字的文件夹,编译好的r包,打包zip
发到自己电脑,解压放进去
文件的读取
csv的打开方式:
- 默认excel
- text
- sublime
- R语言读取(在r语言里对数据框的修改不会影响原数据)
读取 数据框
- read.csv("") 读取csv
- read.table("") 读取txt
table = read.csv("ex3.csv")
不过这两个方法有时候也可以互换用,不影响
如果读取失败,可能是csv里面需要指定一些参数
如果想知道读取后是什么数据结构,用class(变量名),不能输入文件名csv,不然是字符串,变量名一半不带“”,有“”的就是字符串
数据框导出为表格文件
csv格式

txt格式

Rdata
是R语言特有的数据储存格式,无法用其他文件打开
保存的事变量,不是表格文件,支持多个变量存到同一个Rdata
save()保存
load()读取

读取的时候会出现的一些问题
Header
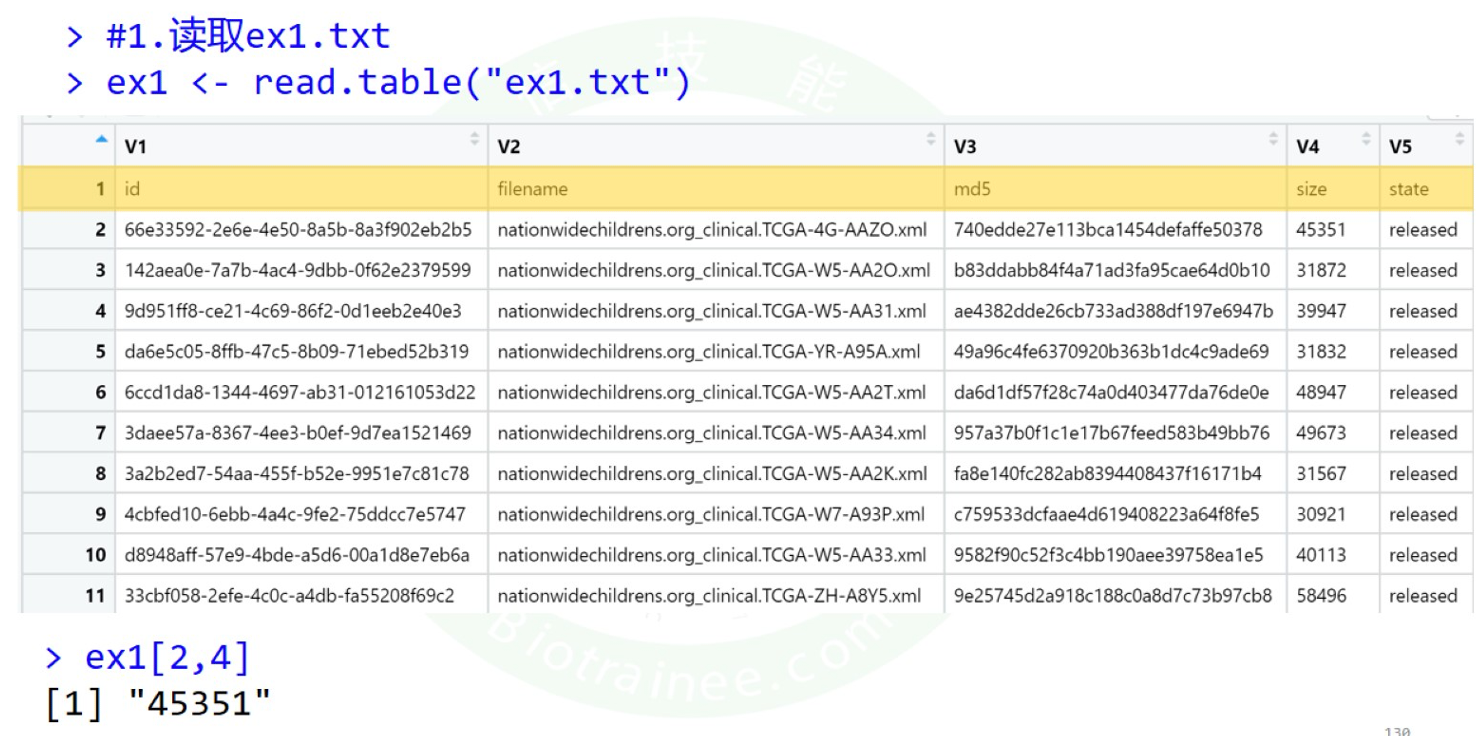
- 第一行其实有列名,只是去了第一行,且 使后面每一列数据类型都变成了字符型,因为向量只能有一个数据类型
- 当提取第二行,第四列的时候,其实取的事第一行,第四列
查看帮助文档,read.table代码,发现header = FALSE(把列名做为第一行)
read.csv\read.delim 的header = TURE

所以更改一下代码,加上header = T
列名就不被计为第一行了
row.names
check.name
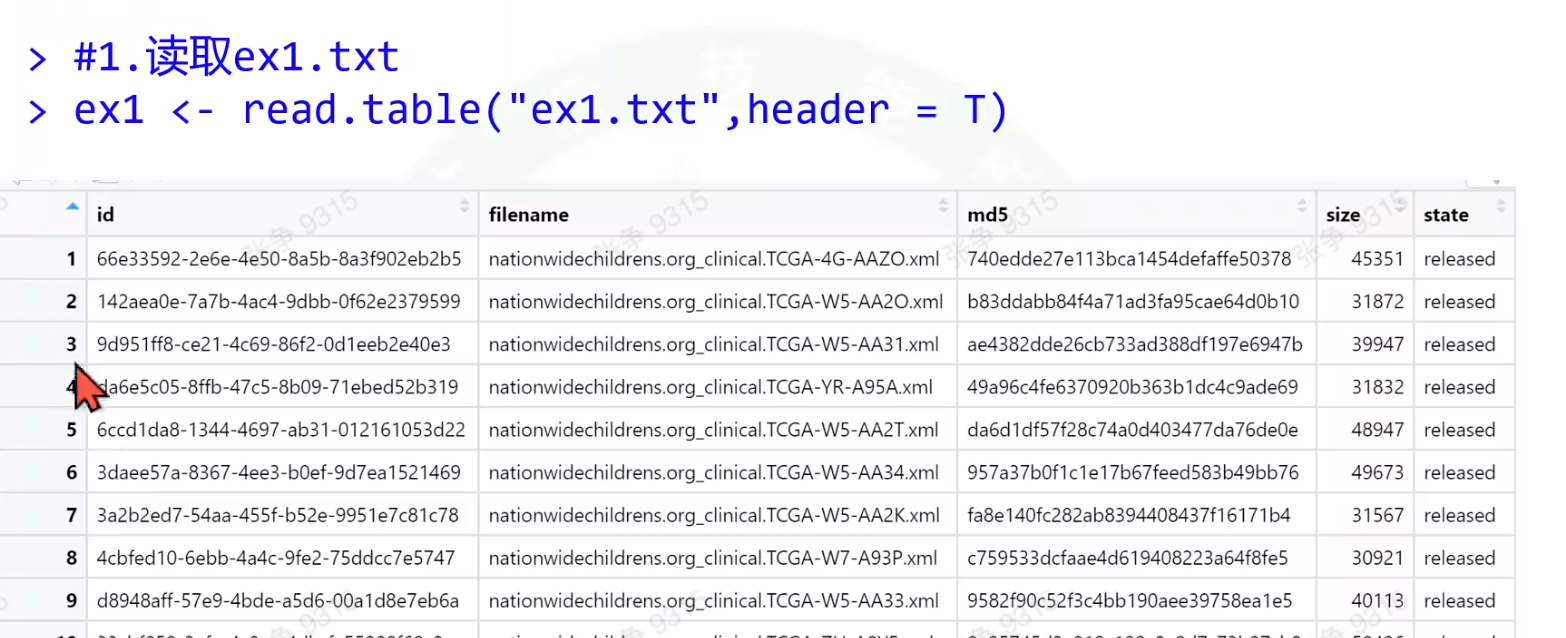
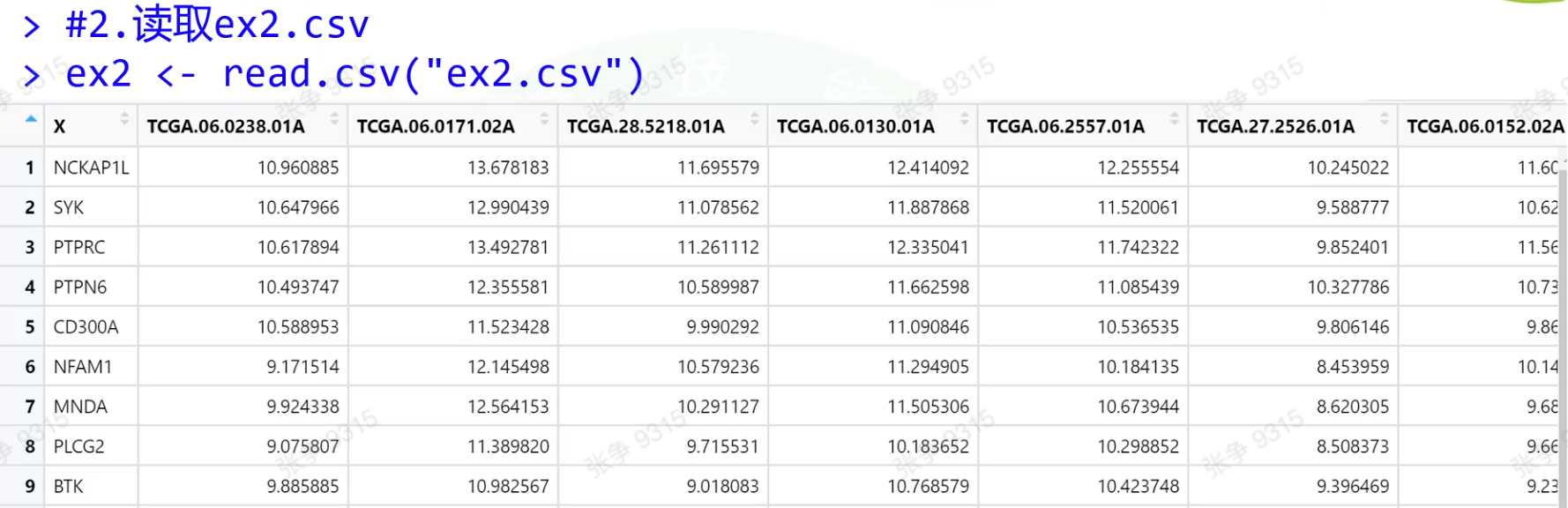
第一列其实是行名字,但在读取的时候,她自己加了一个x作为列名给第一列定义为了数据
列名里如果有特殊字符有时候也会被r语言自己检查,改为其他格式
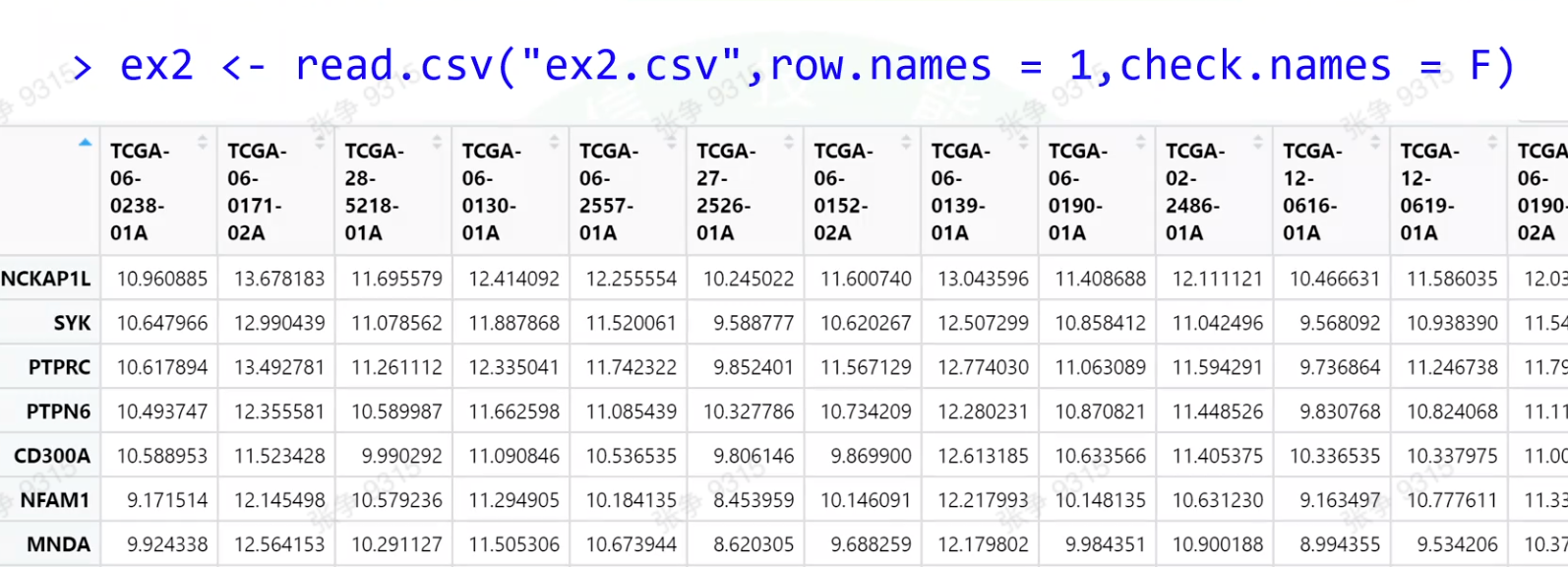
row.names = 1 把第一列 设置为行名字
check.names = F 不要检查我的列名里的特殊字符
数据框不允许重复的行名
练习题5-1

#2.加载y.Rdata(已保存在工作目录),求gene1列的平均值
> load("y.Rdata")
> mean(y$gene1) # 有error出现
Error in y$gene1 : $ operator is invalid for atomic vectors
> class(y)#y是一个矩阵,矩阵需要用到[] 取子集
[1] "matrix" "array"
> mean(y[,1]) #还是不对,因为矩阵只能有一个数据类型,不确定这是什么 类型
[1] NA
Warning message:
In mean.default(y[, 1]) : argument is not numeric or logical: returning NA
> y[,1]
GSM1 GSM2 GSM3 GSM4 GSM5 GSM6
"40" "20" "51" "46" "38" "49"
> class(y[,1])
[1] "character"
> as.numeric(y[,1]) #将字符型转化为数字型
[1] 40 20 51 46 38 49
> mean(as.numeric(y[,1]))s.numeric(y[,1]))
[1] 40.666677
3. 因为ex2是一个基因表达量数据,所以新的文件还要删掉前四行,以和ex2形式可以统一
>x1 = read.delim("GSE217012_Normalized_RPKM_LOG2_matrix.txt.gz",row.names = 1,check.names = F)
> colnames(x1) #可以看到名字是我想要的
[1] "QSeq ID" "Strand" "Source Seq Length" "/qseq_name"
[5] "LPS_ST-1 - log2 total RPKM" "LPS_ST-2 - log2 total RPKM" "LSP_ST-3 - log2 total RPKM" "FLS_OA 1 - log2 total RPKM"
[9] "FLS_OA 2 - log2 total RPKM" "FLS_OA 3 - log2 total RPKM" "RA_ST1 - log2 total RPKM" "RA_ST2 - log2 total RPKM"
[13] "RA_ST3 - log2 total RPKM" "RA_UT1 - log2 total RPKM" "RA_UT2 - log2 total RPKM" "RA_UT3 - log2 total RPKM"
[17] "RA_LPS_1 - log2 total RPKM" "RA_LPS_2 - log2 total RPKM" "RA_LPS_3 - log2 total
x2 = x1[,5:9] #删掉前四列
> x3 = x1[,-(1:4)]#反选,删掉前四列判断两个数据是否相同
identical(x2,x3) 会得到答案 true 或者alse
修改列名
library(stringr)
str_remove(colnames(x2), "- log2 total RPKM")
统计strand
这一列有多少数据
table(x$Strand)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。