89. 三维重建24-立体匹配20,端到端立体匹配深度学习网络之置信度计算的几种思路
89. 三维重建24-立体匹配20,端到端立体匹配深度学习网络之置信度计算的几种思路

在上一篇文章88. 三维重建23-立体匹配19,端到端立体匹配深度学习网络之怎样估计立体匹配结果的置信度?中,我介绍了在立体匹配网络中引入置信度的好处,以及几篇典型的方法。我们看到了传统算法中的多种置信度的计算判据,也看到了深度学习时代我们学习置信度图的典型方案,另外我们还看到基于置信度如何优化得到更好的视差图的方案,以及把置信度的预测,与视差的生成,整合到同一个网络流程中,以循环神经网络的形式迭代式的得到最佳结果。

今天这篇文章,我想给大家进一步介绍立体匹配网络中置信度图计算的几种思路,通过这些方法我们有可能得到更好的置信度图计算结果。
一.通过左右一致性检查计算置信度
在上一篇文章88. 三维重建23-立体匹配19,端到端立体匹配深度学习网络之怎样估计立体匹配结果的置信度?中我已经讲过了,左右一致性检查是一个重要的置信度计算方法,很早的时候学者们就发现简单一个左右一致性检查就可以确定很多匹配错误,该方法特别适用于检测遮挡导致的匹配错误,即在一个视图中可见但在另外一个视图中不可见的区域。
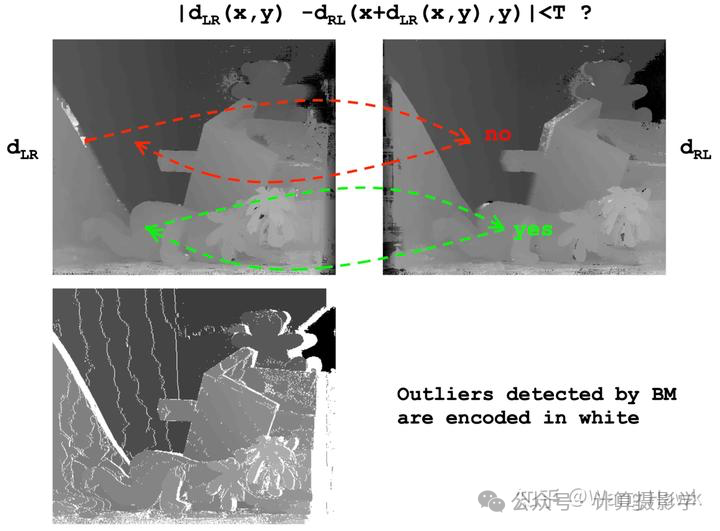
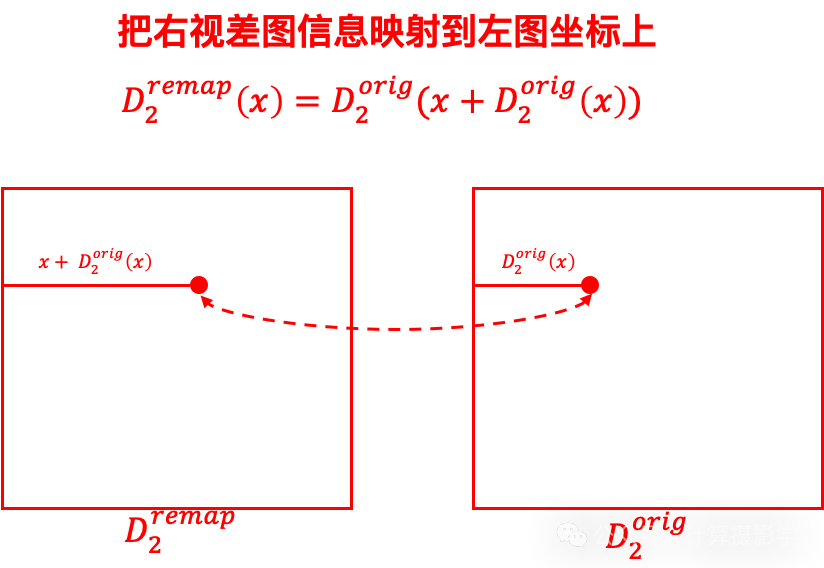
一般的左右一致性检查直接比较左右视差图的一致性。比如先把右视差图映射到左视差图的坐标上
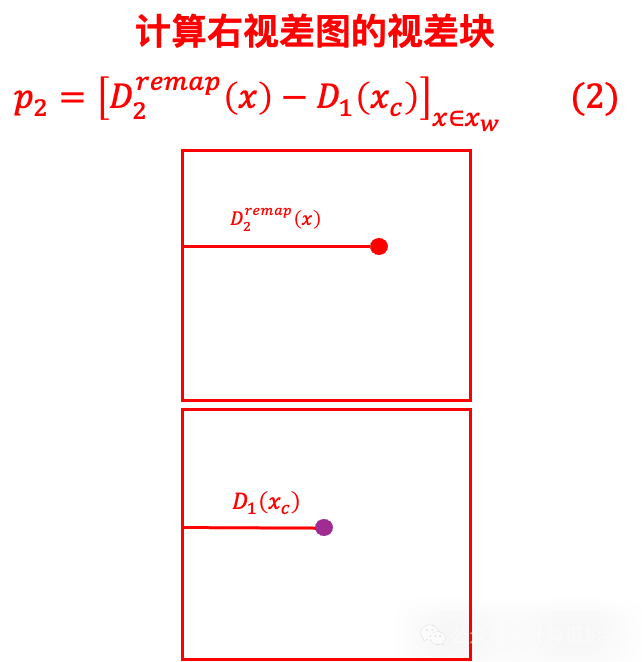
然后计算左右视差的差异,并将这种差异转换为置信度或概率。
在下面这篇文章[4]中提到不仅仅可以比较视差的一致性,还可以比较左右图特征的一致性。

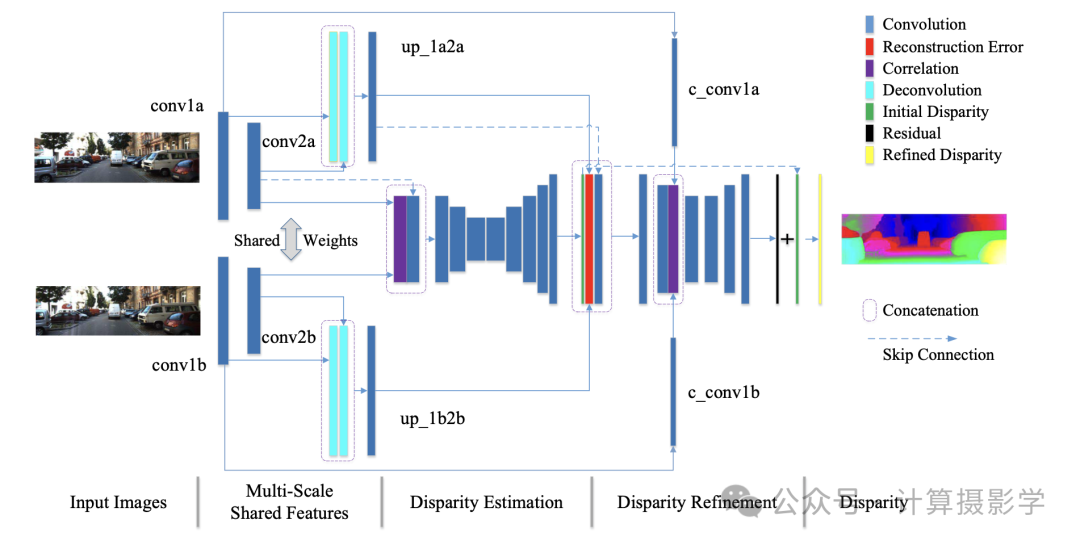
作者的总体思想是先利用一个基础网络获得初步的视差估计dispi, 接下来会计算两个特征一致性项,即特征相关度fc和重建re。
- 特征相关度 fc: 这一项通过计算左右图像特征图(cconvla 和 cconv1b)之间的相关度来衡量它在整个视差范围内测量两个特征图的对应程度,正确的视差值会产生较大的相关度值重建
- 误差re: 这一项是通过计算左图的多尺度融合特征与根据初步视差 dispi 反向变换的右图特征之间的绝对差来获得的。这一计算仅在特征图的每个位置执行一次位移,依赖于初步视差的相应值。如果重建误差较大,表明估计的视差可能不准确或来自被遮挡的区域。
在获得初步视差 dispi、特征相关度fc和重建误差re后,利用这三种信息,通过一个名为DRS-net的视差细化子网络估计与初步视差的残差。这个残差与初步视差相加,得到最终细化的视差图 dispr。
这个过程可以描述为下面的公式:
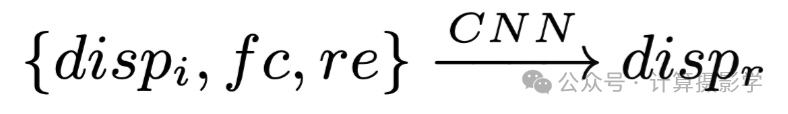
我们也可以使用由全卷积层组成的深或浅网络来学习左右一致性,比如上一篇文章中提到的两篇文章就是这样做的。Seki等人[2]提出了一个基于补丁的置信度预测(PBCP)网络,它需要两个视差图,一个从左图像估计,另一个从右图像估计。PBCP使用一个双通道网络。第一个通道强制执行左-右一致性,而第二个通道强制执行局部一致性。该网络以分类器的方式进行训练,为每个像素输出一个标签,指示估计的视差是否正确。
Jie等人[3]使用左右比较递归(LRCR)模型,将左右一致性检查与视差估计联合执行,而不是将其视为一个独立的后处理步骤。它由两个并行卷积LSTM网络组成,产生两个误差图;一个用于左视差,另一个用于右视差。然后将这两个误差图与其相关联的代价立方体连接起来,并用作3D卷积LSTM的输入,以在下一步中选择性地聚焦在左右不匹配区域上。


二.仅通过单幅原始视差图计算置信度
很显然,上面这种方案需要同时计算两幅视差图,这样的算力消耗是很大的。那么有没有办法只通过单幅原始视差图来计算置信度呢?显然是有的。
比如下面这篇文章[5]就提出了一种很有效的方案,利用所谓的Reflective Confidence的方法来计算置信度图。

作者先通过基础的立体匹配网络,获得一个代价立方体,其尺寸为H × W × disparity max,然后利用我们之前讲过的CBCA+SGM对这个代价立方体进行聚合处理,并利用tanh函数将代价立方体的每个值归一化到[-1, 1]之间,得到一个优化后的匹配代价信息。
按照很多论文的讨论,此时就应该用WTA来获得视差图了。 不过就像我之前讲过的一样,WTA也是可以被神经网络层替换的,这样有机会得到更好的结果——作者正是这样做的,他们让代价立方体通过一个视差网络,同时输出视差图和置信度图。

为了训练这个视差网络,作者在代价立方体上采样9x9xdisparity max的小patch,对于每个patch,其目标label是中心像素点的理想视差值。接下来就将这些patch馈入如下图所示的一个全局视差网络(GDN,即global disparity network)。这个网络通过全连接层FC3输出其预测的视差向量y,它代表着每一个可能的视差值对应的预测得分,很显然分数最高的视差值作为中心像素的最终预测视差,即预测的视差值为argmax_i y_i

同时,为了从视差网络中获得置信度,作者通过二元交叉熵损失同时训练由两个完全连接层(即FC4和FC5)组成的二分类器,训练的真值被作者称为Reflective GT,是当前由FC3的输出所预测的视差值是否与理想视差值尽可能接近。其更具体的过程如下图所示:
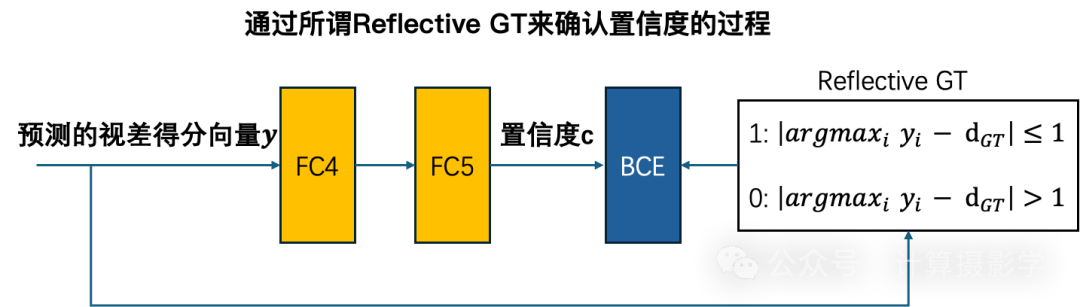
虽然作者是在patch上对网络进行的训练,但只要在训练往常后,将全连接层替换为1x1的卷积层,进行网络的重参数化,那么就很容易在全图上进行推理,加速推理的过程。这样就有可能实现一次性推理得到全尺寸的视差图和置信度图了。
你可以看到,作者这种方法不需要计算两个视角的视差图,相比第一节里面的各种方法显然节省了算力。
下面这篇文章[6]干脆把置信度图的预测当成一个独立的回归问题

作者观察到在视差图上,正确视差图patch和错误的视差图patch是有明显空间上的不同的。比如下图中,左边列出了2个正确匹配的9X9的patch(即中心像素的视差值和GT差异小于某个阈值),而右边则是两个错误匹配的patch。你可以很明显看到这两种patch的区分,错误匹配的视差patch违背了空间上的平滑一致性。

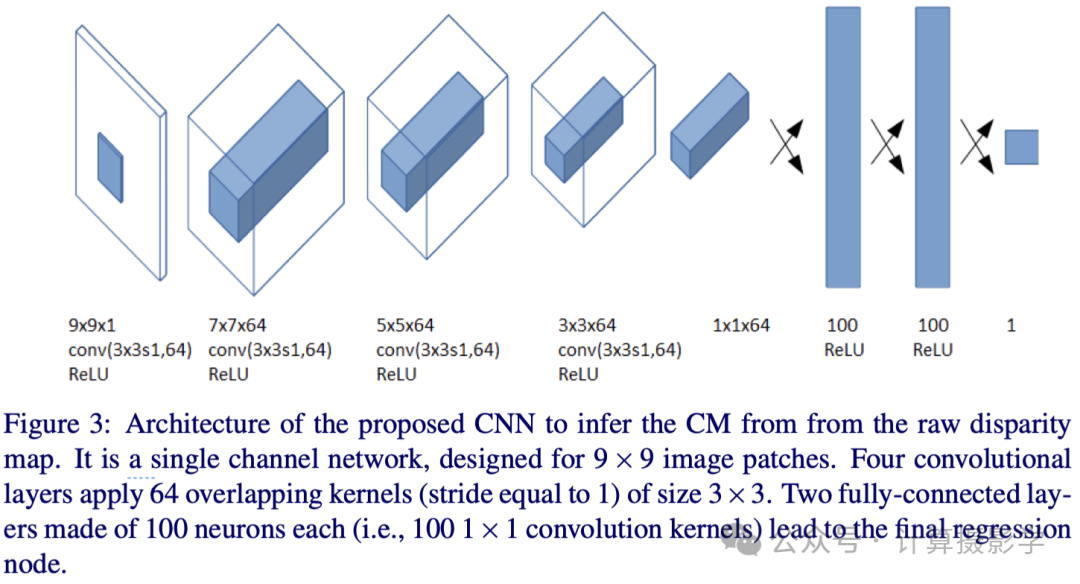
所以作者认为可以利用一个神经网络直接来预测视差图对应的置信度图,其网络结构也非常简单,训练也是抽样一些patch来进行的,其真值也是对应patch的中心像素的视差值是否正确,跟上文中的Reflective GT类似。
这种处理方法的好处是,置信度图的预测网络可以作为一个独立的部分存在,即与视差匹配网络独立。 那么,它的泛化性如何呢?作者也考虑了这个问题,于是他们利用在KITTI 2012上训练或优化的一些立体匹配算法得到的视差图进行了训练,在Middleburry 2014数据集上进行了交叉验证。这两个数据集完全不同,前者都是室外场景,而后者则都是室内场景。其结果表明作者选用的方法能够得到很不错的置信度图结果,具体可以参考原文,我们可以看看作者论文中的一幅图,能看到这里得到的置信度图结果。如果仔细观察,你会发现目标的边缘处,以及遮挡处的置信度较低,在纹理丰富的公共区域的置信度较高,这也符合我们对置信度图的认知。

这样的方法在很多论文中都得到了体现,比如下面这篇文章[7]也是一样的,下面的图我相信你一看就能明白
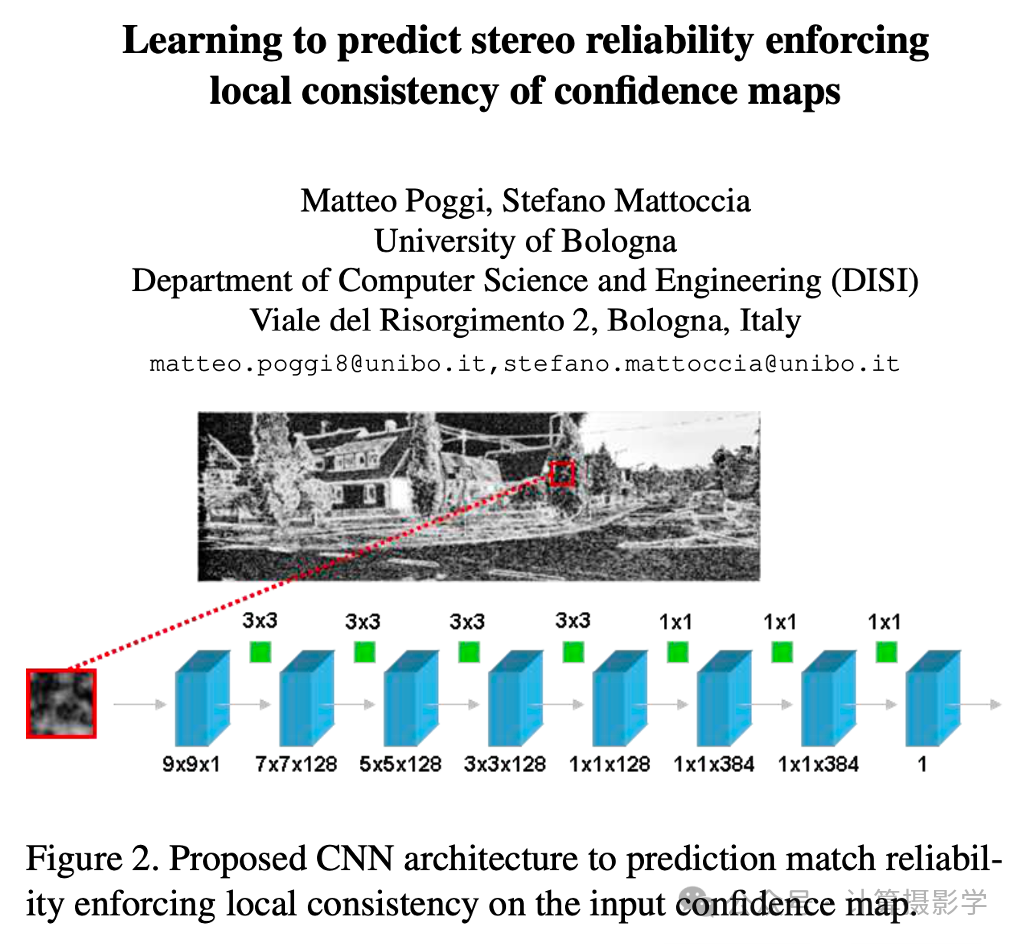
三.通过匹配概率密度函数来计算置信度
上面讲的我相信读者还比较容易理解,现在我们来看一个特别的类型,即通过匹配概率密度函数来计算置信度。
传统的匹配网络一般输出确定性的结果,而没有考虑到这种结果的不确定性。而下面这篇文章则采用了一种叫做概率神经网络的方法,能够给出结果的不确定性。概率神经网络其实已经有很多年的历史了,但它们在实践中并没有得到广泛的应用,主要是速度太慢了。因此,尽管神经网络可能提供有关预测可靠性和网络内部工作的重要信息,但在实践中,神经网络的不确定性在很大程度上被忽视了。
那么有没有好的方法利用神经网络的这种能力呢?下面的文章[8]给出了一个不错的思路

作者介绍了两种轻量级方法,使概率深度网络的监督学习变得实用:
- 首先,他们提出了用于分类和回归的概率输出层,只需要对现有网络进行最小的更改,就可以让网络给出结果的不确定性估计。
- 其次,作者采用了假设的密度滤波技术,并表明激活层的不确定性可以以一种实用的方式传播到整个网络中。同样,这种方式也只需要对现有的网络做微小的改动,就允许从输入到输出的每一层都考虑到不确定性。
由于篇幅原因,我只给出此文的一个非常粗浅而符合直觉的介绍,首先你可以看到下面是深度神经网络的一般性的表示,
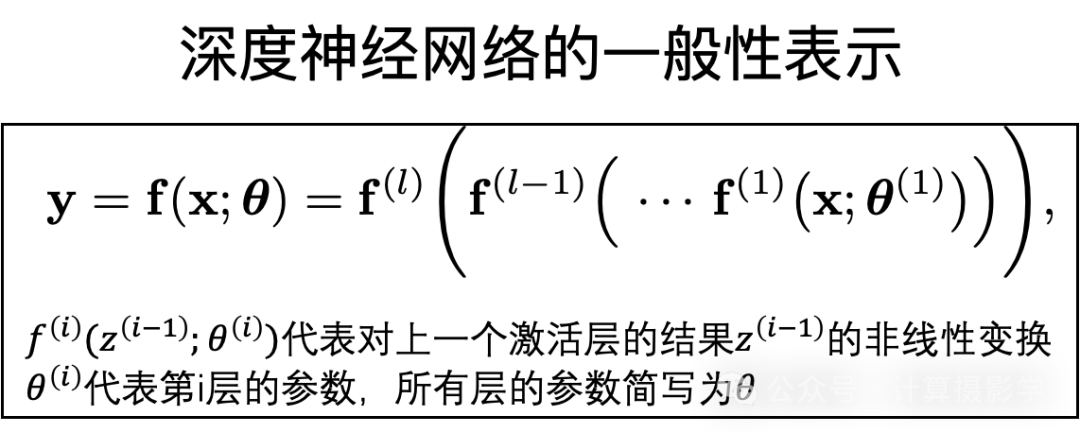
那么,为了得到输出结果的不确定性,一个简单的方法是将输出的y替换为概率分布,即:

它可以给出输出y的每一个可能的值的概率值。
为了便于实现,我们不直接输出所有可能值的概率值,而用概率分布函数来替代。 举个简单例子,如果输出的y遵循高斯分布,那么我们只需要输出这个分布的均值的标准差即可。 这样对于任何可能的输出值,只需要代入高斯分布的公式,即可求出对应的概率了。
那么实践中,我们只需要对网络的最后一层进行改变,让它不再输出单点的预测值,而是一个概率分布函数的参数即可。比如我们选择高斯分布,只需要让网络输出高斯分布的均值的方差即可,这样整个网络的改动非常少,参数量增加也微乎其微。
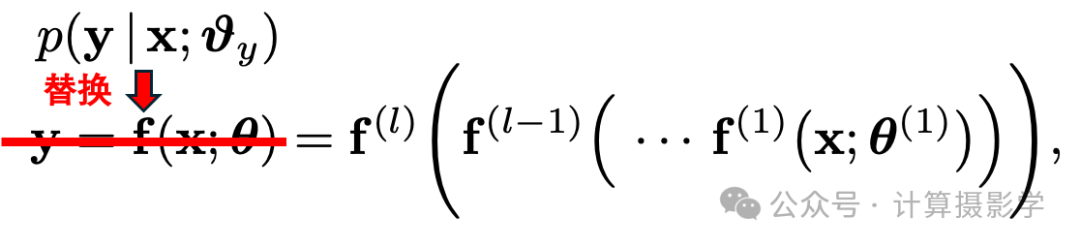
当然,作者提出,不仅仅可以对最后一层做这样的改变,网络的所有层都可以改变,以考虑到每一层的输出的不确定性,这个就稍微复杂一些了,你可以参考原文进行理解。总之,下面这一幅论文中的截图,可以概括作者的思想:(a)是传统的神经网络的输入、激活,以及输出。可以看到都是确定的值。 (b)是刚才讲的仅对输出层进行改变的方式,可以看到输出了概率分布的参数。 (c)则对网络的所有层都进行了改变,包括输入。

总之,有了上面这种网络结构上的改变作为基础,预测匹配结果的置信度,就是顺理成章的事情了,实际上它可以用在任何领域。比如下面展示了利用更改后的FlowNet进行光流计算时同时给出预测光流值的均值和不确定性的结果。

总之,这一流派通过对网络结构的概率化改变,来自然的预测结果的置信度,是一个有趣的方法。 不过我对这个方案的认知还不够,也没有实践经验,建议感兴趣的读者认真阅读原文来加以理解和实践。
四.结合局部信息和全局信息来计算置信度
在我们前面介绍的多种预测置信度图的方案中,通常利用的是输入信息中的局部特征。比如刚才我们提到的很多方法,都是基于输入视差图的小patch来训练的。它们要么是认为两个视角的对应的小块之间存在某种关联关系,要么是认为单一视差图的局部小块内存在某种特征(例如局部的平滑性)。基于这些信息,这些方法训练局部性的网络来计算置信度图。
然而,一些学者提出,除了这种局部信息,还应该参考全局的信息来更好的预测置信度图。最好是把全局信息和局部信息结合在一起,这是符合我们的直觉的。
比如下面这篇文章[9]就是如此做的。

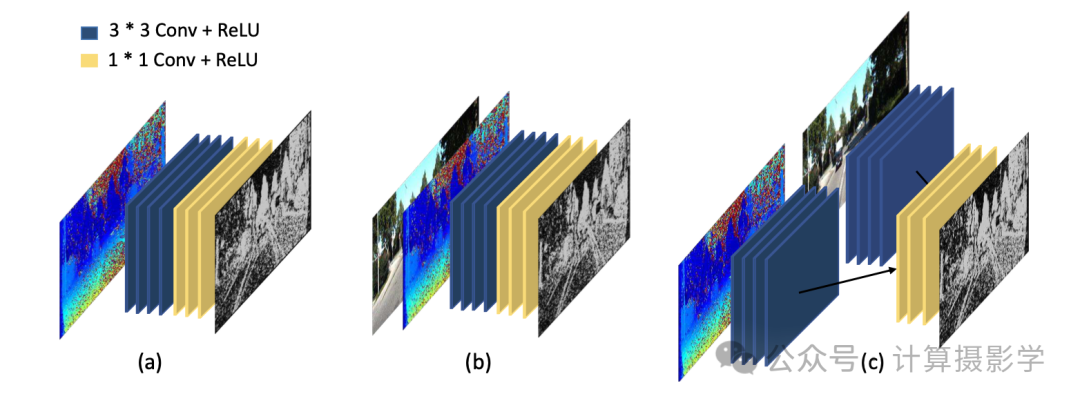
作者们首先展示了各种仅依赖局部信息的置信度图计算方法,如下图所示。它们要么是直接通过原始视差图来计算,要么在原始视差图上附加别的信息(例如参考图像)来计算,但无论如何,都仅仅使用了局部的信息,也仅仅使用了感受野很小的卷积核。
作者们首先提出了一种利用全局信息的网络结构,如下图所示。 通过一些初始的卷积层分别从参考图像和视差图上提取特征图,将两者于通道上连接到一起后,再利用encoder-decoder结构,恢复出全尺寸的置信度图。 这种编码+解码的结构,具有大的感受野,可以捕获图像中的全局上下文信息,这种结构被作者称为ConfNet,理论上可以比仅利用局部信息的方法得到更好的置信度图。

然而,虽然更大的感受野使得在计算每像素得分时能够包括更多的信息,但也起到了正则化因子的作用,从而导致更平滑的置信度估计,这导致在处理高频模式时精度较差。于是,作者又提出了结合全局信息和局部信息的结构,如下图所示。其中橙色块CCCNN/LFN是两种不同的局部网络,即上面的(a)图和(c) 图的结构。可以看到,参考图像+视差图、全局网络的输出、局部网络的输出,这三路信息通过一些网络层进一步提取特征,然后整合到一起,最后输出优化后的置信度图。由于整合了多种信息,这样得到的置信度图当然更好。
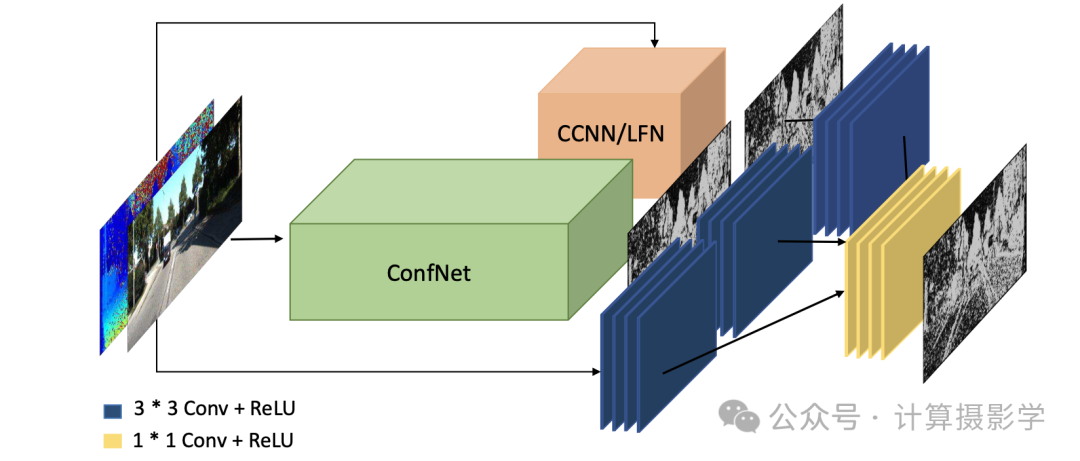
作者给出的结果图也证明了我们描述的内容,混合结构LGC-Net得到的置信度图更加接近理想的置信度图。

五.混合多种置信度计算方法
在参考文献[1]中,还提到了一些论文混合了多种置信度图的估计方法的结果,来得到更高的准确度。比如Haeusler等人[10]将23个置信度信息馈入一个随机森林,并使用传统技术进行最终的置信度估计,与输入的任何置信度图相比,产生了更好的精度。
对于这些方法,我不做过多的介绍,因为我总有这种想法:如果你能够结合多种方法得到更好的置信度图,那也可能仅用一个更强大的方法达到同样的目的,甚至更好更快。
所以对这部分感兴趣的朋友,可以阅读参考论文[1]了解详情。
六. 总结
今天我给大家介绍了五类得到立体匹配结果置信度的方法,我用思维导图总结如下:
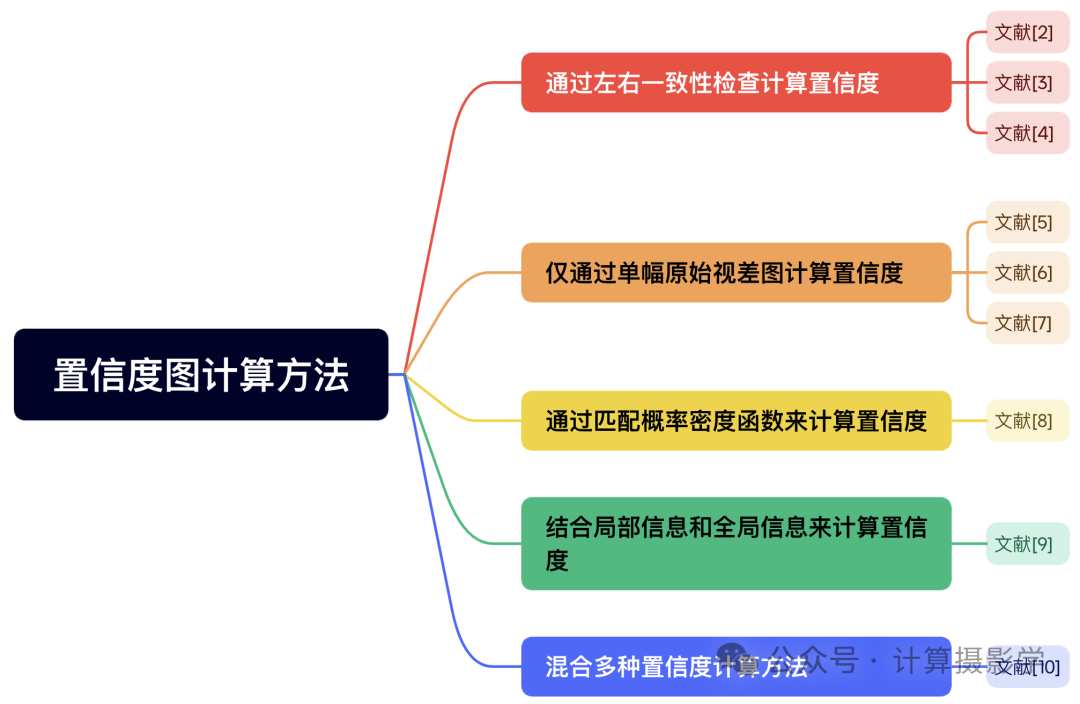
阅读今天的文章,再结合我上一篇文章88. 三维重建23-立体匹配19,端到端立体匹配深度学习网络之怎样估计立体匹配结果的置信度?,我想你已经对计算立体匹配结果的置信度有了一个总体上的认识了。从实用性角度讲,我个人比较喜欢今天提到的方法二和方法四,因为它们便于实现,且效率很高,大家也可以在评论中给出自己的意见。
七. 参考文献
- Hamid Laga, Laurent. Valentin Jospin, Farid Boussaid, and Mohammed Bennamoun. (2020). A Survey on Deep Learning Techniques for Stereo-based Depth Estimation. arXiv preprint arXiv:2006.02535. Retrieved from https://arxiv.org/abs/2006.02535
- A. Seki and M. Pollefeys, “Patch Based Confidence Prediction for Dense Disparity Map,” in BMVC, vol. 2, no. 3, 2016, p. 4.
- 5. Z. Jie, P. Wang, Y. Ling, B. Zhao, Y. Wei, J. Feng, and W. Liu, “Left-Right Comparative Recurrent Model for Stereo Matching,”in IEEE CVPR, 2018, pp. 3838–3846
- Z. Liang, Y. Feng, Y. G. H. L. W. Chen, and L. Q. L. Z. J. Zhang, “Learning for Disparity Estimation Through Feature Constancy,”in IEEE CVPR, 2018, pp. 2811–2820
- A. Shaked and L. Wolf, “Improved stereo matching with constant highway networks and reflective confidence learning,” in IEEE CVPR, 2017, pp. 4641–4650
- M. Poggi and S. Mattoccia, “Learning from scratch a confidence measure,” in BMVC, 2016
- M. Poggi and S. Mattoccia, “Learning to predict stereo reliability enforcing local consistency of confidence maps,” in IEEE CVPR, 2017, pp. 2452–2461.
- J. Gast and S. Roth, “Lightweight probabilistic deep networks,”in IEEE CVPR, 2018, pp. 3369–3378
- F. Tosi, M. Poggi, A. Benincasa, and S. Mattoccia, “Beyond local reasoning for stereo confidence estimation with deep learning,”in ECCV, 2018, pp. 319–334
- R. Haeusler, R. Nair, and D. Kondermann, “Ensemble learning for confidence measures in stereo vision,” in IEEE CVPR, 2013, pp. 305–312