CalciteЯЕСа(Цп)ЃКжДааСїГЬ-КЯЗЈадаЃбщ
дДДCalciteЯЕСа(Цп)ЃКжДааСїГЬ-КЯЗЈадаЃбщ
дДД
ЛљБОИХФю
КЯЗЈадаЃбщЪЧSQLДІРэЕФЕкЖўВНЃЌдкМЦЫужДааЧАЃЌЬсЧАбщжЄSQLе§ШЗадЁЃИУбщжЄВйзїЪЧЗЧЯпадЕФЃЌашвЊЛљгкгяЗЈЪїДІРэИїжжЧЖЬзЕФИДдгЧщПіЁЃCalciteКЯЗЈадаЃбщЛљгкSqlValidator НгПкКЭЖдгІЪЕЯжРрSqlValidatorImpl ЭъГЩЁЃ
CalciteКЯЗЈадаЃбщЩцМАЕНСНИіЛљБОИХФюЃК
- УќУћПеМфЃЈSqlValidatorNamespaceЃЉЃКУшЪіSqlNodeНкЕуЙиСЊЕФЙиЯЕФЃаЭаХЯЂЃЌАќРЈSchemaаХЯЂЃЌзжЖЮРраЭЕШ
- УќУћНтЮігђЃЈSqlValidatorScopeЃЉЃКЛљгкНгПкЗНЗЈЬсЙЉвЛЯЕСаНтЮібщжЄЙІФм
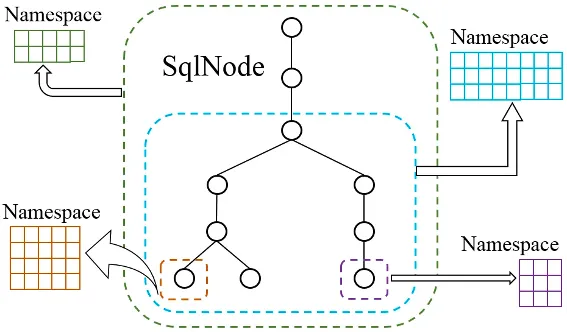
SqlValidatorScopeЛљгкЕФЛљБОНтЮі&бщжЄЙІФмСаБэШчЯТЫљЪОЃК
ЛљБОЙІФм | ЫЕУї |
|---|---|
resolve | УћзжНтЮі,?ИљОнИјЖЈЕФpathВщевSqlNode |
findQualifyingTableNames | ЪеМЏНтЮігђФкЕФЫљгаЪ§ОнБэаХЯЂ |
findAllColumnNames | ЪеМЏНтЮігђФкЫљгаЕФСаУћаХЯЂ |
findAliases | ЪеМЏНтЮігђФкЕФЫљгаБ№Ућ(alias)аХЯЂ |
fullyQualify | ЗЕЛиСаЕФШЋГЦЃЌР§ШчЁАdeptnoЁБЕУЕНЁАemp.deptnoЁБ |
addChild | дкНтЮігђФкзЂВсвЛИіSqlValidatorNamespace |
getMonotonicity | ЗЕЛиФГИіБэДяЪНдкИУНтЮігђФкЪЧЗёгаађ |
getOrderList | зїгУгђФкгаађЕФБэДяЪНЃЌШєУЛгадђЗЕЛиnull |
validateExpr | дкНтЮігђЗЖЮЇФкбщжЄБэДяЪНЕФКЯЗЈад |
lookupWindow | ВщевНтЮігђФкЕФWindowБэДяЪНЃЌЮДевЕНдђЗЕЛиnull |
resolveTable | НтЮігђЗЖЮЇФкНтЮіЪ§ОнБэЕФаХЯЂ |
resolveColumn | НтЮіСаУћВЂЗЕЛиЦфРраЭЃЌВЛКЯЗЈЕФХзГівьГЃ |
жДааСїГЬ
CalciteКЯЗЈадаЃбщжївЊЗжЮЊСНИіжДааНзЖЮЃК
1. зЂВсНзЖЮЃКБщРњећИіSqlNodeгяЗЈЪїЃЌЛљгкMAPЙўЯЃБэЮЌЛЄИїИіSqlNodeНкЕуЕФУќУћПеМфNamespaceКЭНтЮігђScopeЁЃ
вдШчЯТВщбЏSQLЮЊР§ЃЌЪзЯШЪЖБ№ЕНТЬЩЋSELECTНкЕуЛсЩњГЩЖдгІSelectNamesapceКЭSelectScopeЃЌМЬајЪЖБ№зЯЩЋTableНкЕуЩњГЩЖдгІIdentifierNamespaceКЭTableScopeЁЃЭЌбљЕФЃЌвРДЮВЛЖЯБщРњжДааЃЌЭъГЩЫљгаНкЕуЕФNamespaceКЭScopeзЂВсЁЃ
select emp_id, dept_id,
(select dept_name from hr.depts where dept_id = e.dept_id) as dname
from hr.emps as e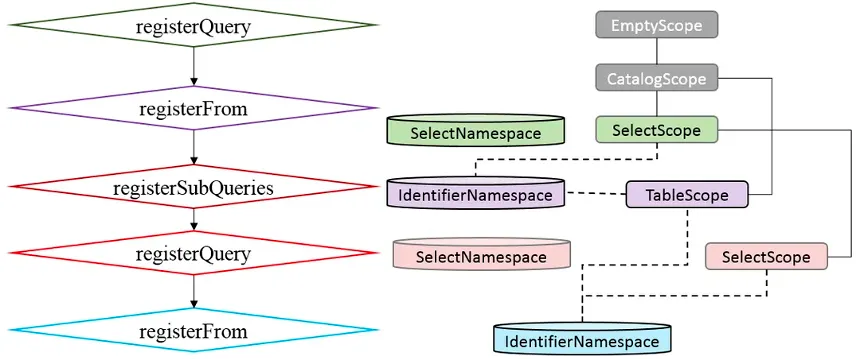
2.?аЃбщНзЖЮЃКSqlValidatorЖЈвхСЫаЃбщЕФШЋСїГЬЃЌЛљгкИїНкЕувбзЂВсЙиСЊЕФNamespaceКЭScopeжДааЖдгІvalidateВйзїЁЃаЃбщДІРэПЩМђЛЏЮЊ:??validate = Namespace#validate + Scope#validateExpr + ЖюЭтаЃбщ
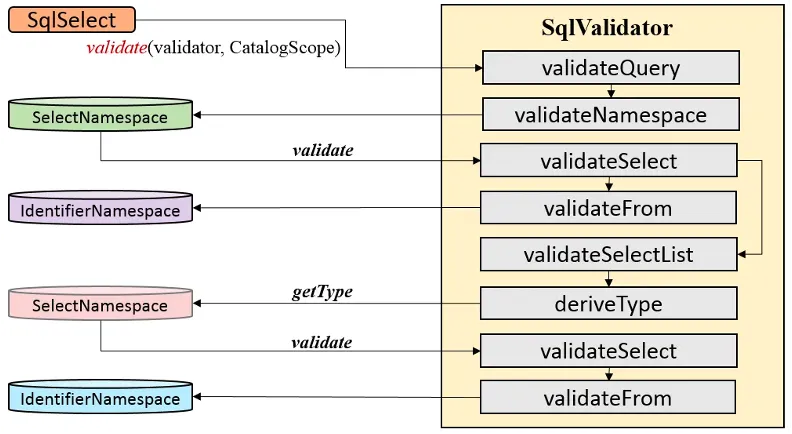
аЃбщЪОР§
Бэ/зжЖЮаЃбщ
ЛљгкCalciteSchema(дЊЪ§ОнЖЈвх)ЛёШЁБэЖЈвхЃЌаЃбщЃК(1).БэЪЧЗёДцдкЃЛ(2).зжЖЮРраЭЪЧЗёЦЅХфЁЃаЃбщСїГЬШчЯТЭМЫљЪО
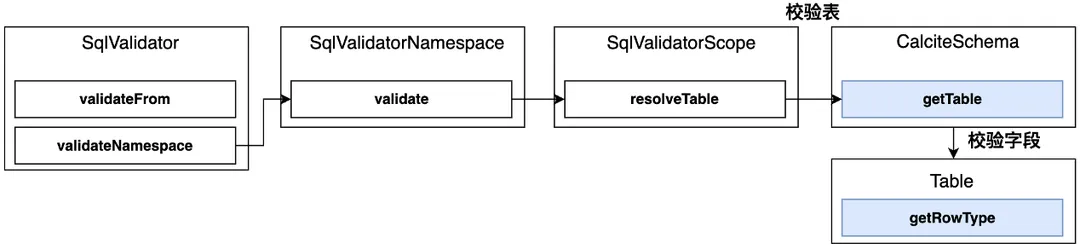
FunctionаЃбщ
CalciteжЇГжСНжжКЏЪ§РраЭЃК
- БъзМФкжУКЏЪ§(SqlStdOperatorTable)ЃКЖЈвхЭЈгУЕФFunctionКЏЪ§СаБэ
- ЬиЖЈв§ЧцЯрЙиЕФздЖЈвхКЏЪ§(SqlLibraryOperators)ЃКЖЈвхИїИіжДаав§ЧцРЉеЙЕФЬиадКЏЪ§
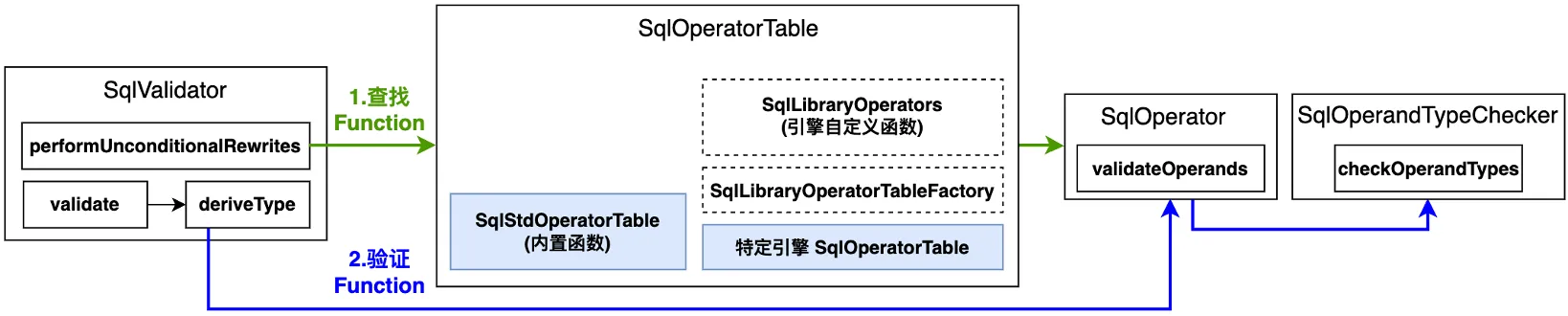
дкКЯЗЈадаЃбщНзЖЮЛсЖдЪЙгУЕФFunctionКЏЪ§ж№ИібщжЄЃЌжївЊЗжЮЊСНВНЃК
- FunctionВщевЃКИљОнУћГЦЦЅХфВщевFunctionЃЌЛљгкSqlOperatorTable#lookupOperatorOverloads ЪЕЯж
- FunctionаЃбщЃКЛљгкВщевЕНЕФFunctionЖЈвхЃЌаЃбщКЏЪ§ШыВЮИіЪ§ЁЂШыВЮРраЭЁЂЗЕЛиРраЭЕШаХЯЂ
вўЪНзЊЛЛ
ЮЊШЗБЃЪ§ОнВйзїЕФСщЛюадКЭМцШнадЃЌSQLв§ЧцЛсЬсЙЉЪ§ОнзЊЛЛЙІФмЃЌЪ§ОнзЊЛЛПЩЗжЮЊЯдЪНзЊЛЛКЭвўЪНзЊЛЛСНРрЃК
- ЯдЪНзЊЛЛЃКдкSQLгяОфжаУїШЗжИЖЈЕФзЊЛЛЃЌЭЈГЃгаCASTКЏЪ§ЭъГЩЃЌШчЃКCAST(str_column AS INT)
- вўЪНзЊЛЛЃКЪ§ОнПт(МЦЫув§Чц)ЯЕЭГздЖЏНјаазЊЛЛЃЌЖјЮоашдкSQLгяОфжаУїШЗжИЖЈ
ИїРрМЦЫув§ЧцЫљОпБИЕФвўЪНзЊЛЛФмСІОиеѓИїВЛЯрЭЌЃЌвўЪНзЊЛЛФмСІдНЧПЃЌдђв§ЧцдкаЃбщНзЖЮЃЌЖдзжЖЮРраЭЕФаЃбщдНПэЫЩЁЃР§ШчЃЌSparkЕФвўЪНзЊЛЛФмСІдЖЪЄгкPrestoЃЌЯрЭЌЕФSQLгяОфдкSparkжаПЩвджДааГЩЙІЃЌЕЋдкPrestoжаПЩФмЛсжБНгХзГіРраЭВЛЦЅХфЕФДэЮѓЁЃ
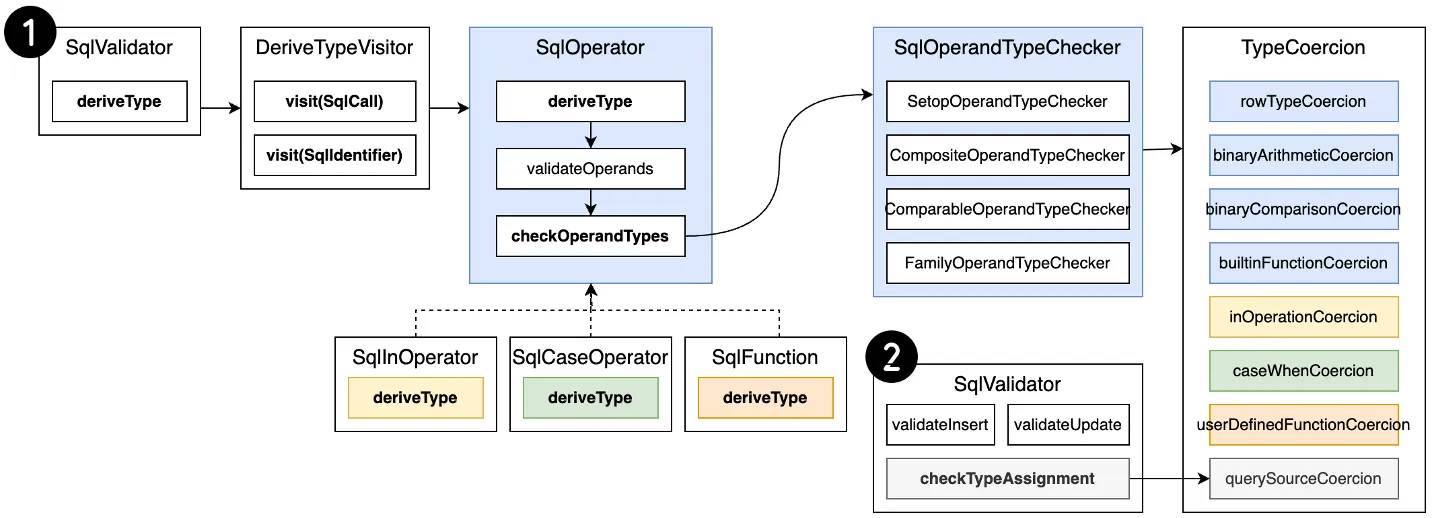
ЮЊНтОіЕзВуИїРрМЦЫув§ЧцвўЪНзЊЛЛФмСІВЛЭЌЕФЮЪЬтЃЌОЁПЩФмШУЯрЭЌгявхЕФSQLПЩвддкВЛЭЌв§ЧцжДааГЩЙІЁЃCalciteдкvalidateНзЖЮЪЕЯжСЫвЛЬзЭЈгУЕФвўЪНзЊЛЛДІРэЛњжЦЃЌжївЊДІРэАќРЈЃК
- РраЭДиаЃбщЃКЛљгкРраЭаЃбщЃЌХаЖЯSQLжаФПБъРраЭгыдДРраЭЪЧЗёЪєгкЯрЭЌЕФРраЭДи
- ЯдЪНзЊЛЛИФаДЃКШєФПБъРраЭгыдДРраЭЕФРраЭДиВЛЯрЭЌЃЌЧветСНжжРраЭДижЎМфдЪаэвўЪНзЊЛЛЃЌдђЛљгкCASTКЏЪ§ДІРэЯдЪНзЊЛЛИФаД
CalciteвўЪНзЊЛЛШчЯТЭМЫљЪОЃК
- РраЭДиЃКNUMERICЁЂSTRINGЁЂDATETIMEЁЂBOOLEAN
- зЊЛЛШыПкЃК1. DQLаЃбщЃКSqlValidator#deriveTypeЃЛ2. DMLаЃбщЃКSqlValidator#checkTypeAssignmentЃЛ
- зЊЛЛДІРэЃКЛљгкTypeCoercionЪЕЯжВЛЭЌЕФдЫЫуЗћРраЭЕФвўЪНзЊЛЛДІРэ
Юве§дкВЮгы2024ЬкбЖММЪѕДДзїЬибЕгЊзюаТеїЮФЃЌПьРДКЭЮвЙЯЗжДѓНБЃЁ
дДДЩљУїЃКБОЮФЯЕзїепЪкШЈЬкбЖдЦПЊЗЂепЩчЧјЗЂБэЃЌЮДОаэПЩЃЌВЛЕУзЊдиЁЃ
ШчгаЧжШЈЃЌЧыСЊЯЕ cloudcommunity@tencent.com ЩОГ§ЁЃ
дДДЩљУїЃКБОЮФЯЕзїепЪкШЈЬкбЖдЦПЊЗЂепЩчЧјЗЂБэЃЌЮДОаэПЩЃЌВЛЕУзЊдиЁЃ
ШчгаЧжШЈЃЌЧыСЊЯЕ cloudcommunity@tencent.com ЩОГ§ЁЃ