[系统安全] 五十七.恶意软件分析 (9)利用MS Defender实现恶意样本家族批量标注(含学术探讨)
[系统安全] 五十七.恶意软件分析 (9)利用MS Defender实现恶意样本家族批量标注(含学术探讨)

感谢2023年的陪伴,2024年继续加油^_^
该系列文章将系统整理和深入学习系统安全、逆向分析和恶意代码检测,文章会更加聚焦,更加系统,更加深入,也是作者的慢慢成长史。漫漫长征路,偏向虎山行。享受过程,一起奋斗~
前文介绍了IDA Python配置过程和基础用法,然后尝试提取恶意软件的控制流图(CFG)。这篇文章将讲解如何利用MS Defender实现恶意样本家族批量标注,在通过VS、VT采集批量样本后,通常需要样本家族标注,如何准确识别家族类别至关重要,其将为后续的恶意软件家族分类或溯源提供帮助。在此感谢李师弟热心的指导和帮助,基础性基础,希望您喜欢,且看且珍惜。
作者的github资源:
- 逆向分析:
- https://github.com/eastmountyxz/ SystemSecurity-ReverseAnalysis
- 网络安全:
- https://github.com/eastmountyxz/ NetworkSecuritySelf-study
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是关于安全工具和实践操作的在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习网络安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔!

声明:本人坚决反对利用教学方法进行犯罪的行为,一切犯罪行为必将受到严惩,绿色网络需要我们共同维护,更推荐大家了解它们背后的原理,更好地进行防护。(参考文献见后)
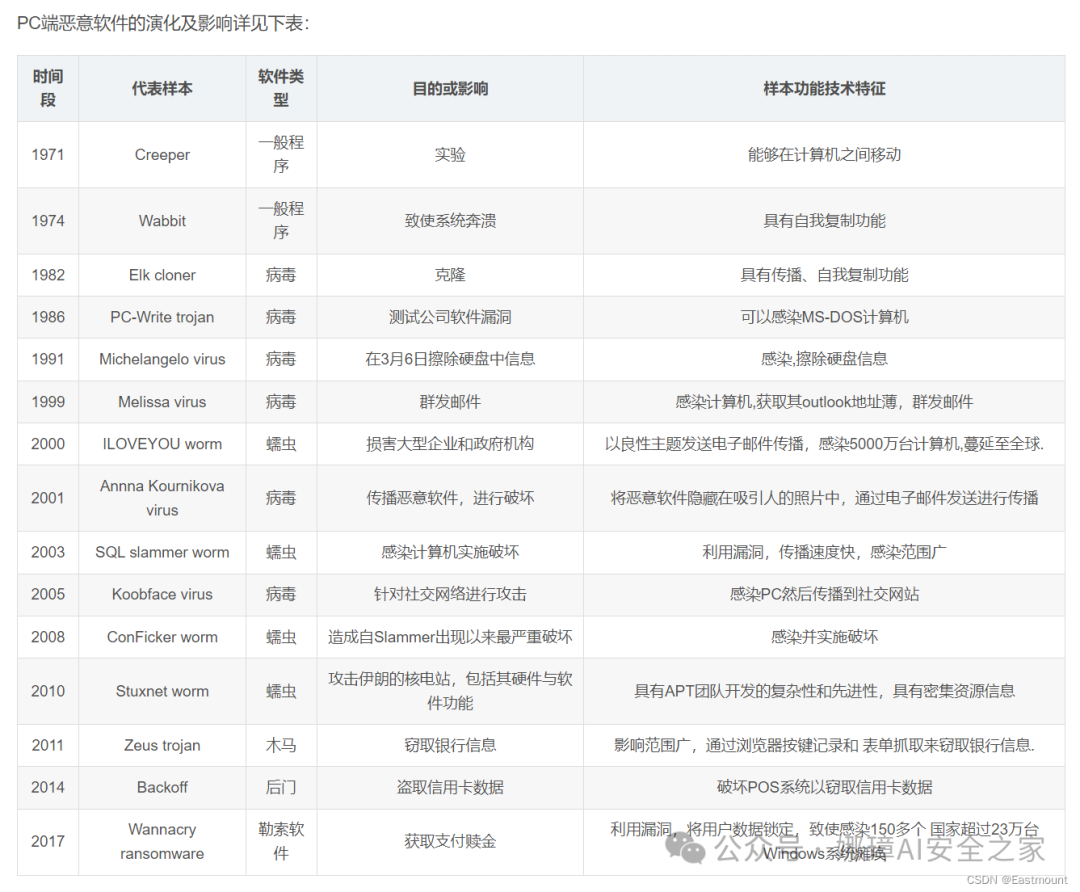
一.恶意软件概念
恶意软件是一种具有恶意目的的计算机程序或代码。它在未明确提示用户或未经用户许可的情况下,在用户计算机或其他终端上安装运行,侵犯用户合法权益。恶意软件通常会在用户不知情的情况下,通过植入或篡改系统、应用程序或文件来进行安装和传播,以实现对计算机系统和用户信息的非法获取、利用或破坏。这是网络安全领域中一种常见的威胁形式,对个人、企业和组织的网络安全产生巨大的威胁。
恶意软件通常具有自动执行的特点,即无需用户手动启动,就可以进行各种恶意活动。根据行为特性和目的,恶意软件可分为多种类型,包括病毒、蠕虫、木马、间谍软件、勒索软件等。这些软件可能会破坏计算机系统、窃取敏感信息、勒索财产或进行其他恶意活动。
代表性恶意软件如下表所示:
恶意代码溯源是指通过分析恶意代码生成、传播的规律以及恶意代码之间衍生的关联性,基于目标恶意代码的特性实现对恶意代码源头的追踪。
因此,如何有效检测恶意软件,溯源恶意软件至关重要。那么,当我们从VS、VT、微步在线等网站采集海量样本,如何对恶意软件的家族进行标注呢?这就是本文需要研究的问题。
二.利用MS Defender批量标注恶意软件
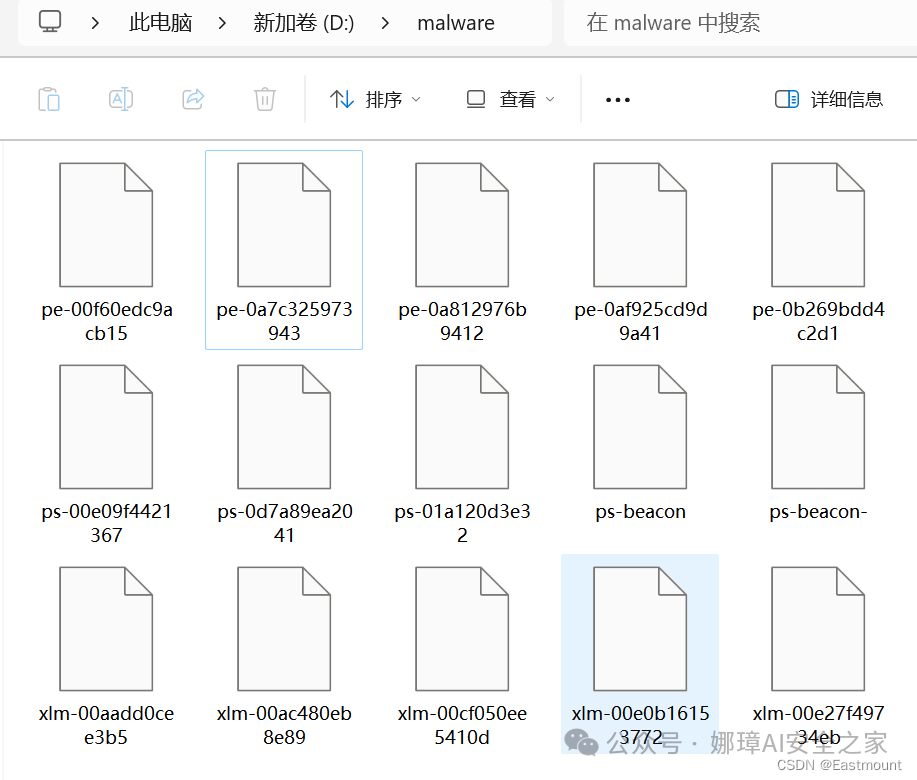
假设存在如下所示的恶意软件,包括PE样本、Powershell样本和XLM样本,MD5仅给出部分。我们需要利用MS Defender软件识别恶意家族,其是Windows自带的杀毒软件。
温馨提示:建议所有安全相关的实验均要在虚拟机中完成,本机的重要数据要养成及时备份的好习惯,尤其是做学术研究。
1.构建恶意软件样本白名单
通常,我们会遇到的第一个问题是:这些病毒样本会被杀毒软件查杀,如何解决呢? 一种方式是手动恢复,另一种是设置白名单,比如将上述文件夹“malware”设置为白名单,复制样本后再进行后续实验。
第一步,开启MS Defender防病毒扫描选项。
第二步,在打开后的页面,点击“病毒和威胁防护”设置中的“管理设置”。
第三步,在“排除项”中点击“添加或删除排除项”。
- Microsoft Defender 防病毒不会扫描已排除的项目。排除的项目可能包含使你的设备易受攻击的威胁。
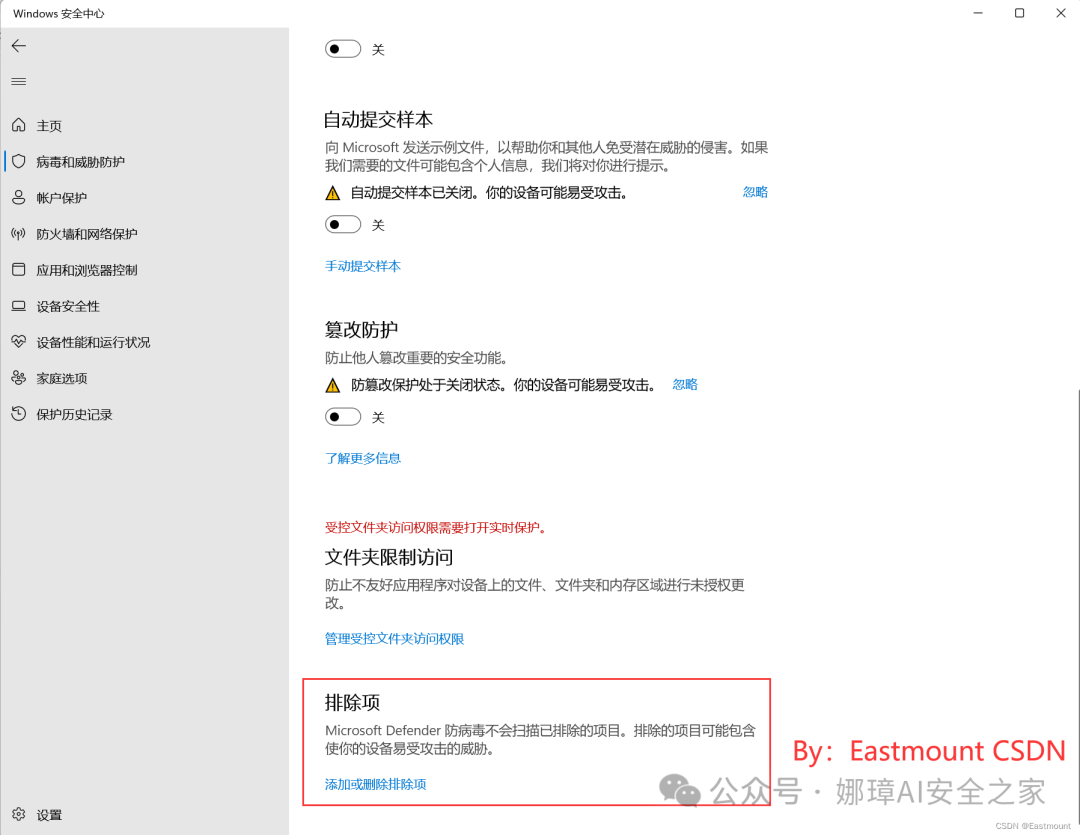
第四步,点击“添加排除项”,添加要从Microsoft Defender防病毒扫描中排除的项目。
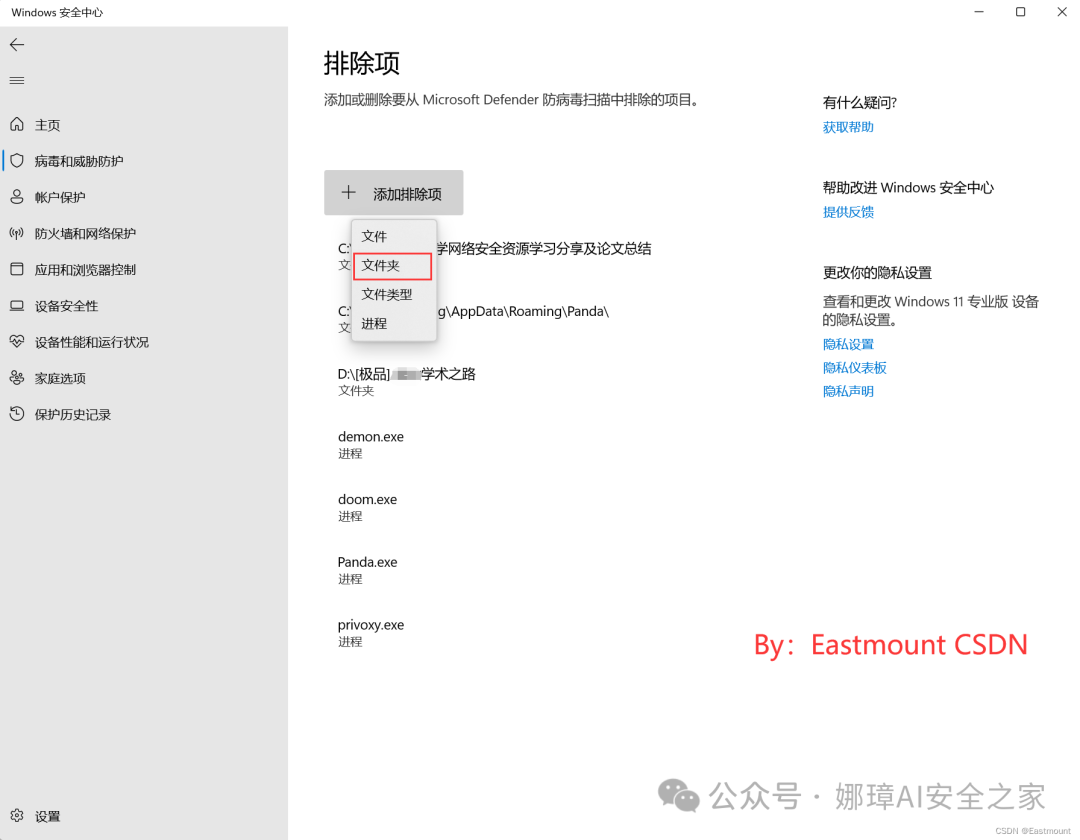
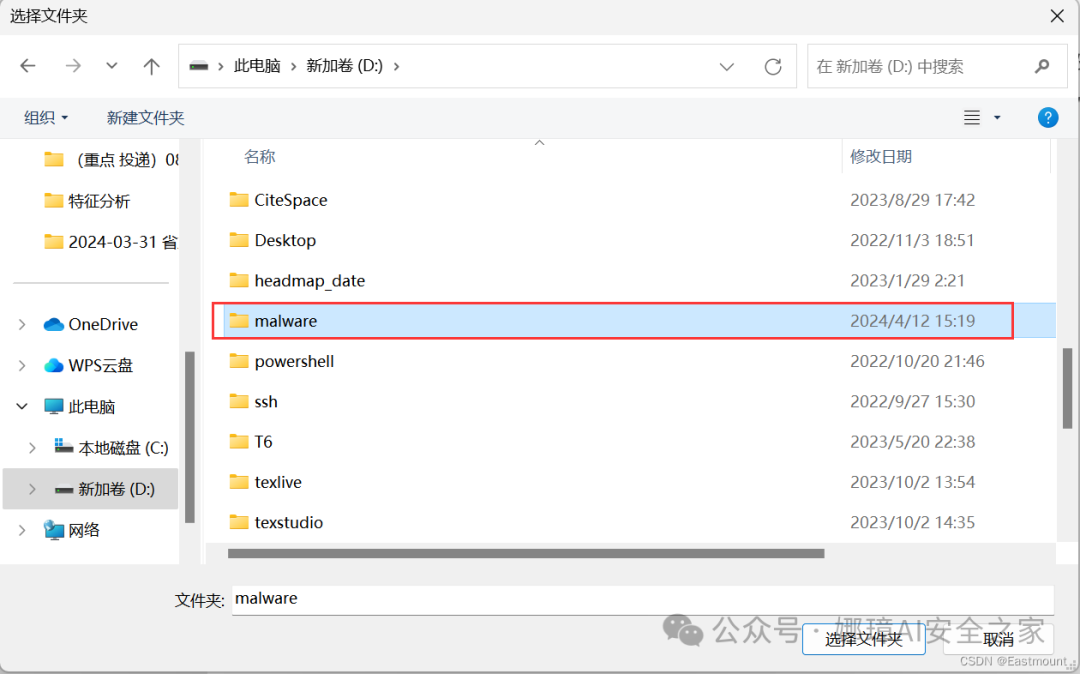
第五步,选择包含恶意软件的“malware”文件夹,自此设置好白名单。
2.恶意软件家族标注
接下来我们利用MS Defender进行病毒扫描,然后扫描如果是恶意软件会为每个样本生成一个结果描述,通过这些结果描述即可对恶意软件家族进行标注。整个原理是利用MS Defender病毒库进行关键特征匹配实现。具体如下:
第一步,在Windows安全中心中,点击“当前威胁”下的“扫描选项”按钮。
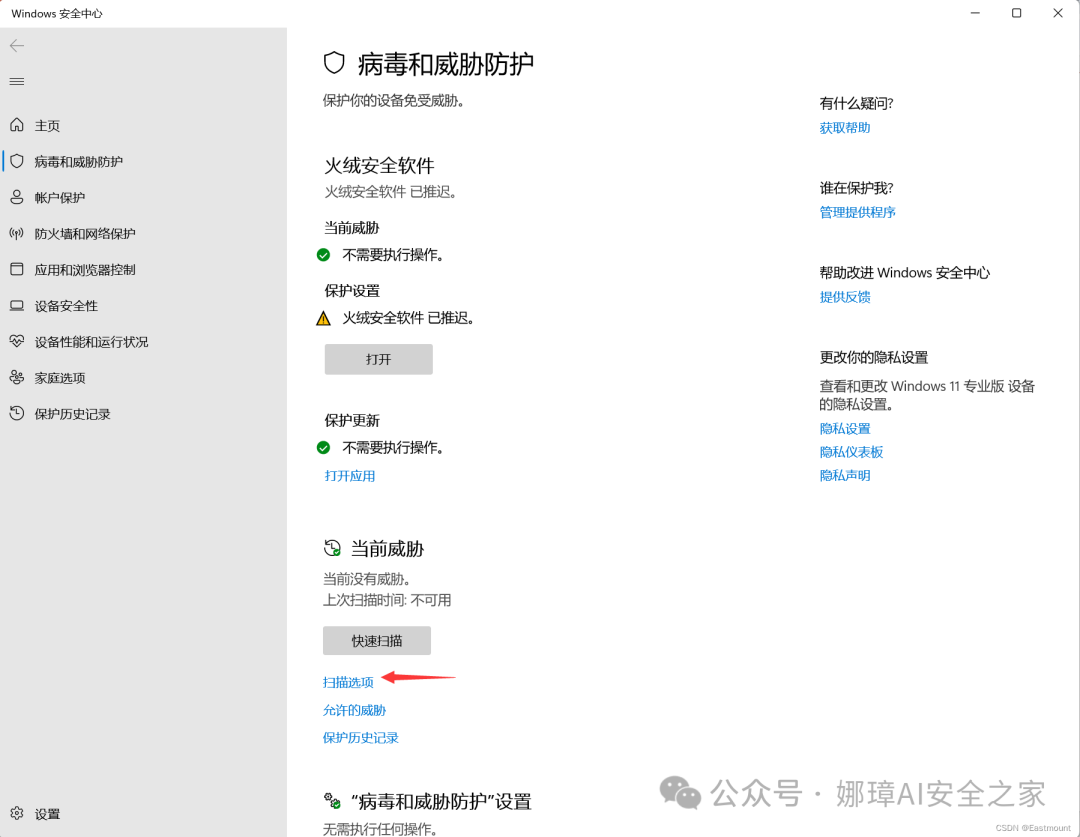
第二步,点击“自定义扫描”,并选择对应需要扫描的“malware”文件夹。
需要注意,您的计算机可能会因之前添加白名单而无法识别,提示如下信息。因此,我们可以再将白名单删除即可,此时删除不会立刻删除我们的恶意样本。
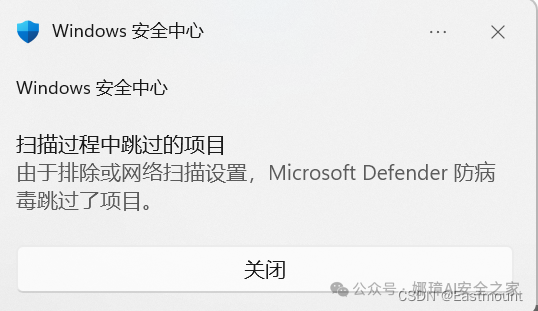

第三步,通过自定义扫描指定目录,我们得到如下图所示的结果。可以发现8个恶意软件被识别,大家也可以借助其它软件进行扫描。
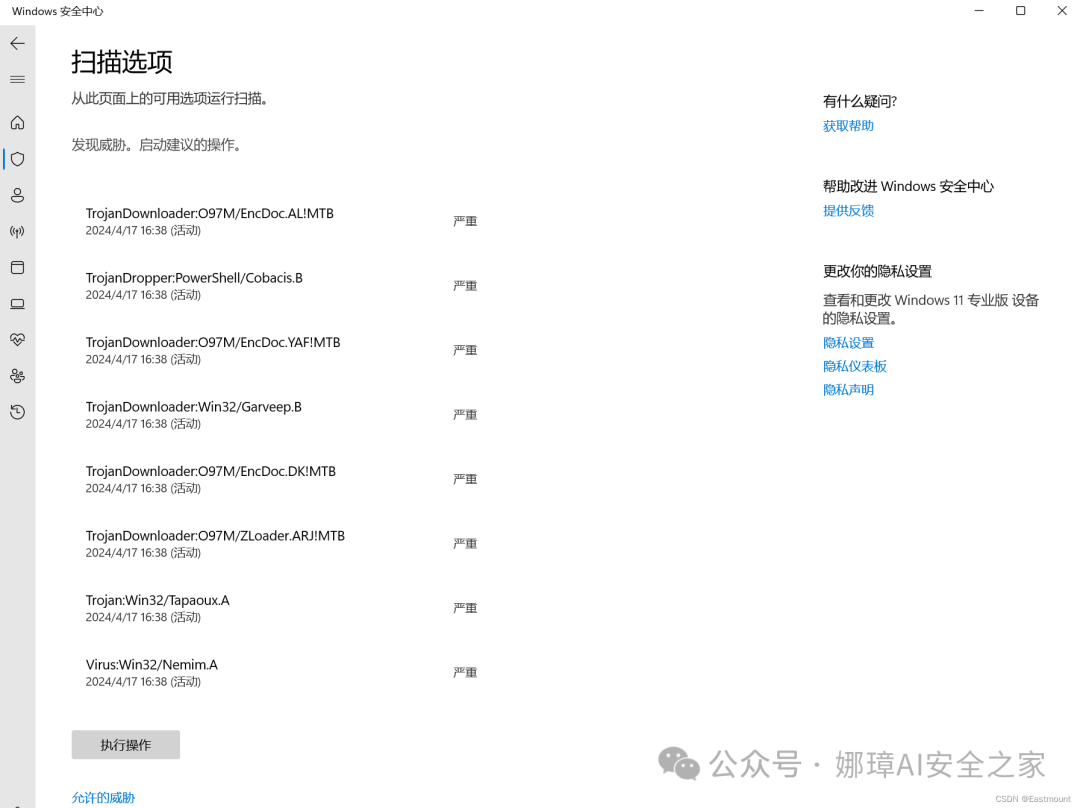
当我们点击具体的信息,可以看到恶意软件被识别的类型,如下图所示是个特洛伊木马程序。
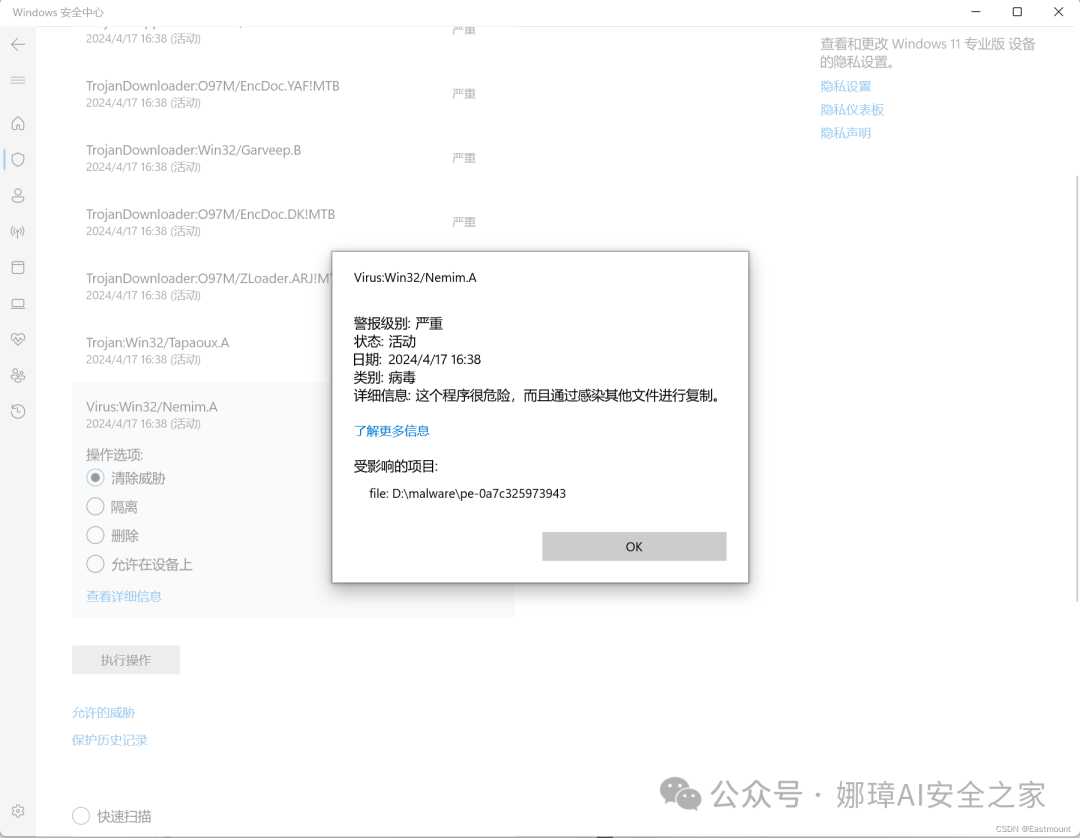
那么,如果样本数很多的时候,难道我们需要一个个手动记录这些信息吗? 事实上,Windows系统有完整的安全日志记录了所有操作,包括我们设置白名单、开启某种功能等,恶意软件扫描结果同样被记录在相应日志中。我们可以通过提取日志信息来批量获取扫描的结果,从而实现恶意软件的批量标注。
第四步,查看扫描结果所存在的MPLog文件,其位置如下:
- C:\ProgramData\Microsoft\Windows Defender\Support\
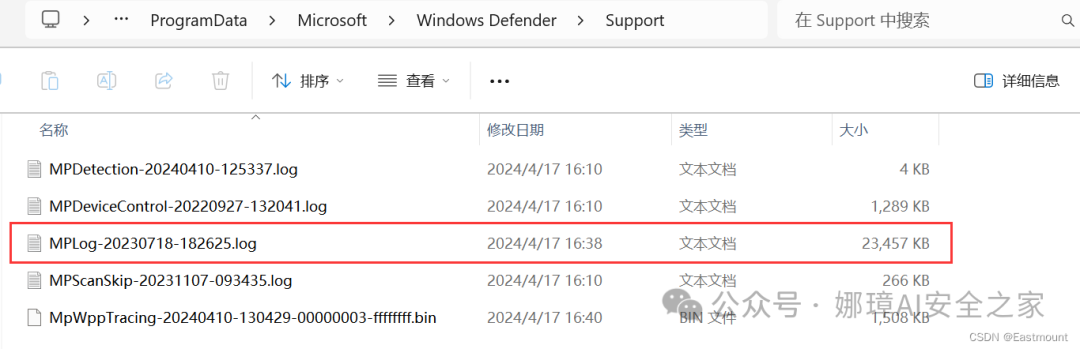
打开该文件可以看到对应的扫描信息。
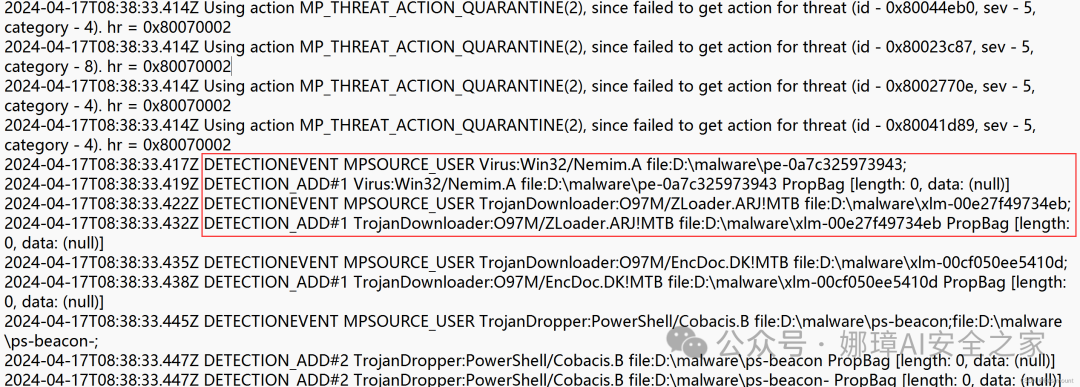
详细信息如下,包括开始扫描对应的目录、时间信息,以及扫描结果“Result Count”显示发现7个结果。接着是,每个样本被Defender扫描生成的详细威胁信息,包括:
- Threat Name:威胁名称
- ID:序号
- Severity:安全等级
- Number of Resources:该威胁类别数量
- Resource Path:恶意样本路径来源
- 扩展信息
温馨提示:大家在虚拟机中进行扫描,可以上一次扫描完成就恢复虚拟机,从而使得每次扫描前日志信息干净,更好地解析结果,而本机通常会记录大量信息。
3.样本家族名称提取
下面给出一个Python脚本,用于解析MS Defender的日志信息,即下面的文件。在此,感谢李师弟的热心指导和帮助。
- C:\ProgramData\Microsoft\Windows Defender\Support\MPLog-[…]-[…].txt
# By: Li YXZ 2024-04-17
import argparse
import os
import pandas as pd
def print_and_export(parse_result):
output_path = 'parse_result1.csv'
if os.path.exists(output_path):
os.remove(output_path)
malware_families_samples = []
for malware_family, malware_family_samples in parse_result.items():
malware_family_samples = set(malware_family_samples)
for malware_family_sample in malware_family_samples:
malware_families_samples.append([malware_family, malware_family_sample])
malware_samples = pd.DataFrame(malware_families_samples, columns=['Malware_Family', 'Sample'])
malware_samples.to_csv(output_path, index=False)
print('Finished!')
def get_line_value(line: str):
line = line.strip().rstrip('\n')
first_colon_index = line.index(':')
return line[first_colon_index + 1:]
def get_subpart_info_of_threat(sub_block: list):
# 在Threat Name引导的数据块中,Threat Name开头信息为4行,每个文件的信息也为4行,正好可用同一函数获取数据
threat_name_or_resource_schema = get_line_value(sub_block[0])
id_value_or_resource_path = get_line_value(sub_block[1])
severity_or_sigseq = get_line_value(sub_block[2])
resources_number_or_sigsha = get_line_value(sub_block[3])
return threat_name_or_resource_schema, id_value_or_resource_path, severity_or_sigseq, resources_number_or_sigsha
def parse_resource_scan_results(scan_results):
"""
Resource Scan开头:
Begin Resource Scan
Scan ID:{79739BA1-802B-4F5C-9FAD-FC0C19DC3A3C}
Scan Source:
Start Time:
End Time:
Explicit resource to scan
Resource Schema:folder
Resource Path:
Result Count: (威胁类型数量,即扫描的所有文件分为多少种类型/多少Threat Name)
每组威胁信息:
Threat Name:
ID:
Severity:
Number of Resources: (可能有多个文件属于该类威胁Threat Name)
[每个文件包含4行信息:Resource Schema、Resource Path、两个Extended Info(SigSeq、SigSha),多个文件则每组信息不断排列]
Resource Schema:file
Resource Path:
Extended Info - SigSeq:
Extended Info - SigSha:
Resource Schema:containerfile
Resource Path:
Extended Info - SigSeq:
Extended Info - SigSha:
...
"""
resource_scan_attributes = ['Scan ID', 'Scan Source', 'Start Time', 'End Time']
threat_name_sig = 'Threat Name'
resource_scan_sig = {}
for index, line in enumerate(scan_results):
if ':' not in line:
continue
line = line.strip().rstrip('\n')
first_colon_index = line.index(':')
sig = line[: first_colon_index]
if sig in resource_scan_attributes:
resource_scan_sig[sig] = line[first_colon_index + 1:]
elif sig == threat_name_sig:
scan_results = scan_results[index:] # 去掉Resource Scan开头信息部分
break
parse_result = {}
line_num = 0
while line_num < len(scan_results):
threat_name, id_value, severity, resources_number = \
get_subpart_info_of_threat(scan_results[line_num: line_num + 4])
# Threat Name如:TrojanDownloader:O97M/Donoff.PAB!MTB 、 Virus:X97M/Mailcab.B
# 可以看出Threat Name有一个固定的结构 具体的恶意家族写在'/'和'.'之前需要对此进行提取
# print(threat_name)
forward_slash_index = threat_name.index('/')
try:
try:
end_index = threat_name.index('.', forward_slash_index)
except ValueError:
end_index = threat_name.index('!', forward_slash_index)
threat_name = threat_name[forward_slash_index + 1: end_index]
except ValueError:
threat_name = threat_name[forward_slash_index + 1:]
threat_name = threat_name.lower()
line_num += 4
samples = []
resources_number = int(float(resources_number))
for _ in range(resources_number):
schema, path, sigseq, sigsha = get_subpart_info_of_threat(scan_results[line_num: line_num + 4])
# 对于xlsx、xlsb、xlsm,Microsoft Defender能够识别出其中具体哪个表是恶意的
# 从而出现'...\er-1303209212.xlsb->xl/worksheets/sheet3.bin'这样的路径
if '->' in path:
path = path[: path.index('->')]
file_name = os.path.basename(path)
samples.append(file_name)
line_num += 4
if threat_name in parse_result:
parse_result[threat_name].extend(samples)
else:
parse_result[threat_name] = samples
# 返回结果为一个字典 每一threat_name项的值为一个列表 包含了该类threat_name的所有文件
# 如{'Gozi': [1.xls, 2.xlsm, ...], ...}
return parse_result
def main():
arg_parser = argparse.ArgumentParser()
arg_parser.add_argument('-f', '--file', type=str, help='The path of MPLog', metavar='FILE_PATH')
args = arg_parser.parse_args()
# MPLog在系统中所在位置:C:\ProgramData\Microsoft\Windows Defender\Support\MPLog-[...]-[...].txt
if args.file:
mplog_path = os.path.abspath(args.file)
else:
mplog_path = os.path.abspath('MPLog-20230718-182625.log')
with open(mplog_path, 'r', encoding='utf-16') as mplog:
mplog_content = mplog.readlines()
resource_scan_begin = 'Begin Resource Scan'
resource_scan_begin_indexes = []
resource_scan_end = 'End Scan'
resource_scan_end_indexes = []
for line_num, line in enumerate(mplog_content):
line = line.strip()
if line.startswith(resource_scan_begin):
resource_scan_begin_indexes.append(line_num)
elif line.startswith(resource_scan_end):
resource_scan_end_indexes.append(line_num)
latest_scan_begin_index = resource_scan_begin_indexes[-1]
latest_scan_end_index = resource_scan_end_indexes[-1]
latest_scan_results = mplog_content[latest_scan_begin_index + 1: latest_scan_end_index]
samples_classification = parse_resource_scan_results(latest_scan_results)
# 将家族类别与样本文件名写入parse_result.csv中
print_and_export(samples_classification)
if __name__ == '__main__':
main()输出结果将存储至本地CSV文件,包括恶意家族和样本名称(MD5),如下图所示:
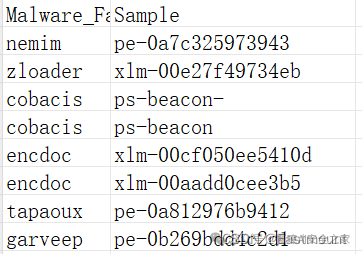
需要注意,识别结果“TrojanDropper:PowerShell/Cobacis.B”包括2个样本,并且会注明其恶意样本来源。日志中的详细结果如下:
Begin Resource Scan
Resource Path:D:\malware
Result Count:7
Threat Name:Virus:Win32/Nemim.A
Resource Path:D:\malware\pe-0a7c325973943
Threat Name:TrojanDownloader:O97M/ZLoader.ARJ!MTB
Resource Path:D:\malware\xlm-00e27f49734eb
Number of Resources:2
Threat Name:TrojanDropper:PowerShell/Cobacis.B
Resource Path:D:\malware\ps-beacon-
Resource Path:D:\malware\ps-beacon
Threat Name:TrojanDownloader:O97M/EncDoc.DK!MTB
Resource Path:D:\malware\xlm-00cf050ee5410d
Threat Name:Trojan:Win32/Tapaoux.A
Resource Path:D:\malware\pe-0a812976b9412
Threat Name:TrojanDownloader:Win32/Garveep.B
Resource Path:D:\malware\pe-0b269bdd4c2d1
Threat Name:TrojanDownloader:O97M/EncDoc.YAF!MTB
Resource Path:D:\malware\xlm-00aadd0cee3b5
End Scan自此,通过上述实验我们将成功识别大部分恶意软件的家族。为后续实验提供支撑,当然读者可以借助开源有名的数据集进行对比实验,后续有机会总结下这些数据集。
4.Defender恶意家族命名规则解析
此时,您可能又有一个疑问,“TrojanDropper:PowerShell/Cobacis.B”样本的家族究竟是什么呢? 我们通过微软官方命名规则对其进行解析。根据计算机防病毒研究组织(CARO)的恶意软件命名方案,Defender检测到的恶意软件命名如下。官方网址如下:
- https://docs.microsoft.com/en-us/windows/security/threat-protection/intelligence/malware-naming
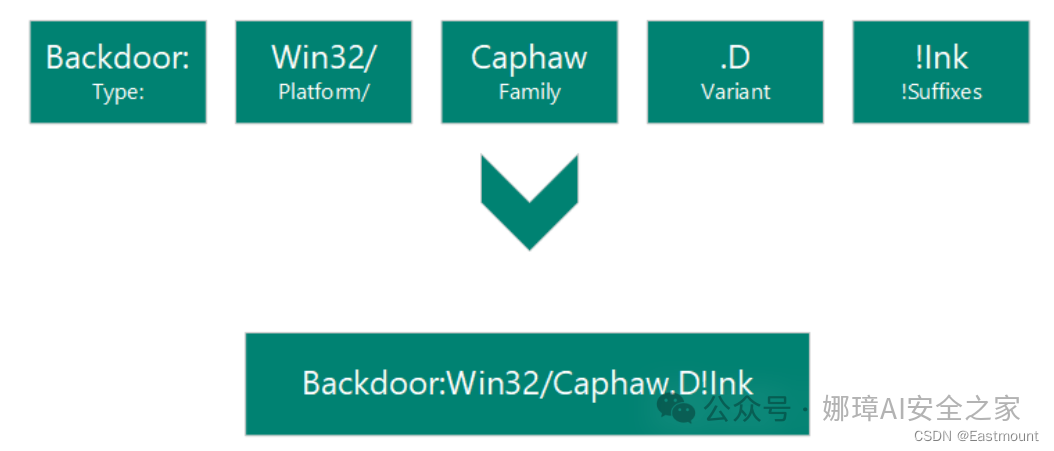
核心包括:
- Type:类型
- Platform:平台
- Family:家族
- Variant:变体
- Suffixes:后缀
因此,上述代码是提取的家族类型,即“TrojanDropper:PowerShell/Cobacis.B”样本的恶意家族为“Cobacis”。
(1) 类型 描述恶意软件在计算机上做了什么。蠕虫、病毒、木马、后门和勒索软件是最常见的恶意软件类型。
* Adware
* Backdoor
* Behavior
* BrowserModifier
* Constructor
* DDoS
* Exploit
* HackTool
* Joke
* Misleading
* MonitoringTool
* Program
* Personal Web Server (PWS)
* Ransom
* RemoteAccess
* Rogue
* SettingsModifier
* SoftwareBundler
* Spammer
* Spoofer
* Spyware
* Tool
* Trojan
* TrojanClicker
* TrojanDownloader
* TrojanNotifier
* TrojanProxy
* TrojanSpy
* VirTool
* Virus
* Worm(2) 平台 指示恶意软件要针对的操作系统(如Windows、Mac OS X和Android),该平台还用于指示编程语言和文件格式。
Operating systems
* AndroidOS: Android operating system
* DOS: MS-DOS platform
* EPOC: Psion devices
* FreeBSD: FreeBSD platform
* iOS: iPhone operating system
* Linux: Linux platform
* macOS: MAC 9.x platform or earlier
* macOS_X: macOS X or later
* OS2: OS2 platform
* Palm: Palm operating system
* Solaris: System V-based Unix platforms
* SunOS: Unix platforms 4.1.3 or lower
* SymbOS: Symbian operating system
* Unix: general Unix platforms
* Win16: Win16 (3.1) platform
* Win2K: Windows 2000 platform
* Win32: Windows 32-bit platform
* Win64: Windows 64-bit platform
* Win95: Windows 95, 98 and ME platforms
* Win98: Windows 98 platform only
* WinCE: Windows CE platform
* WinNT: WinNTScripting languages
* ABAP: Advanced Business Application Programming scripts
* ALisp: ALisp scripts
* AmiPro: AmiPro script
* ANSI: American National Standards Institute scripts
* AppleScript: compiled Apple scripts
* ASP: Active Server Pages scripts
* AutoIt: AutoIT scripts
* BAS: Basic scripts
* BAT: Basic scripts
* CorelScript: Corelscript scripts
* HTA: HTML Application scripts
* HTML: HTML Application scripts
* INF: Install scripts
* IRC: mIRC/pIRC scripts
* Java: Java binaries (classes)
* JS: JavaScript scripts
* LOGO: LOGO scripts
* MPB: MapBasic scripts
* MSH: Monad shell scripts
* MSIL: .NET intermediate language scripts
* Perl: Perl scripts
* PHP: Hypertext Preprocessor scripts
* Python: Python scripts
* SAP: SAP platform scripts
* SH: Shell scripts
* VBA: Visual Basic for Applications scripts
* VBS: Visual Basic scripts
* WinBAT: Winbatch scripts
* WinHlp: Windows Help scripts
* WinREG: Windows registry scriptsMacros
* A97M: Access 97, 2000, XP, 2003, 2007, and 2010 macros
* HE: macro scripting
* O97M: Office 97, 2000, XP, 2003, 2007, and 2010 macros - those that affect Word, Excel, and PowerPoint
* PP97M: PowerPoint 97, 2000, XP, 2003, 2007, and 2010 macros
* V5M: Visio5 macros
* W1M: Word1Macro
* W2M: Word2Macro
* W97M: Word 97, 2000, XP, 2003, 2007, and 2010 macros
* WM: Word 95 macros
* X97M: Excel 97, 2000, XP, 2003, 2007, and 2010 macros
* XF: Excel formulas
* XM: Excel 95 macros(3) 家族 恶意软件的分组基于共同的特征,包括归属于相同的作者。安全软件供应商有时对同一个恶意软件家族使用不同的名称,从而定义恶意软件家族。
(4) 变体 每个不同版本的恶意软件都有一个顺序。例如,对变量的检测。“.AF”将在检测到变体“. AE”之后创建。
(5) 后缀 提供有关恶意软件的额外详细信息,包括如何将其用作多组件威胁的一部分。在“Win32/Reveton.T.”例子中,“!lnk”指示威胁组件是木马使用的快捷方式文件。
* .dam: damaged malware
* .dll: Dynamic Link Library component of a malware
* .dr: dropper component of a malware
* .gen: malware that is detected using a generic signature
* .kit: virus constructor
* .ldr: loader component of a malware
* .pak: compressed malware
* .plugin: plug-in component
* .remnants: remnants of a virus
* .worm: worm component of that malware
* !bit: an internal category used to refer to some threats
* !cl: an internal category used to refer to some threats
* !dha: an internal category used to refer to some threats
* !pfn: an internal category used to refer to some threats
* !plock: an internal category used to refer to some threats
* !rfn: an internal category used to refer to some threats
* !rootkit: rootkit component of that malware
* @m: worm mailers
* @mm: mass mailer worm三.恶意样本家族构造方法
问题:不同杀毒引擎或安全公司会有自己特有的病毒库及恶意家族定义方式,那么,如何能更准确地标注这些家族呢?或者,如何将这些家族名称对齐呢?尤其是Virusshare和Virustotal对每个样本有多重标注结果。
首先,我能想到的是做一个投票器,来更准确的标注信息。当然,有时为了实验需要,以某个病毒引擎或某安全公司的标准来实施也可以,但需要标注清楚。
接着,我们参考ADog老师在先知社区的文章,他提到了文本相似度计算方式。在此感谢作者,并推荐大家阅读原文。
- https://xz.aliyun.com/t/5666

总之,通过相似度计算和摩尔投票确实可以更准确地标注恶意家族。
关于如何提取标签,ADog老师首先想到的是按照前面所得到的的厂商排名列表顺序取标签,通过构建一个标签字典,其类似于2.4小节描述的方式提取。比如以Kaspersky厂商的命名方式为例,其提供了一个具体的标签列表:

四.Usenix Sec20恶意软件标注工作
下面给出Usenix Sec20恶意软件标注工作的核心思想,主要以恶意软件在线分析平台 VirusTotal 为对象。具体地址如下:
- Measuring and Modeling the Label Dynamics of Online Anti-Malware Engines
- 测量和建模恶意软件在线分析平台的标签动态
- https://www.usenix.org/system/files/sec20-zhu.pdf
- 参考文章:https://zhuanlan.zhihu.com/p/359121003

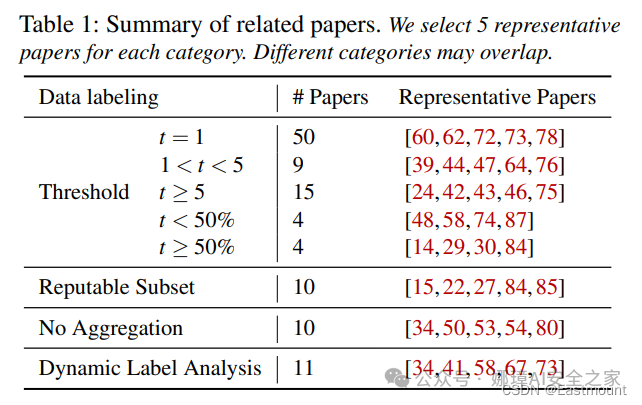
本文的核心工作: 作者采用数据驱动(data-driven)的策略来对研究者们常用的标签方法进行分类、解释和验证。
- 首先调研了 115 篇和 VirusTotal 相关的学术论文,并且在一年内从 65 个 VirusTotal 采用的引擎中收集了超过 14000 个文件的标签动态。作者验证了基于阈值(threshold)的标签整合分析结果的稳定性,并指出了阈值对结论的影响。
- 通过对数据集的测试,本文发现一些广泛使用且被认为“可信”的反恶意软件引擎的表现并不理想,并且许多引擎的测试结果非常近似,可以认为这些引擎组是紧密相关的,在参考它们的分析结论时应该作为整体综合考虑。
- 最后,作者为将来使用 VirusTotal 进行数据标注、恶意软件标注提供了建设性建议。
VirusTotal 是目前最大的在线恶意软件扫描平台,应用了 70 多种反恶意软件引擎,并且能提供详细的分析报告和丰富的数据源,在安全界被研究者们广泛应用于恶意软件注释和系统评估。当前存在的问题如下:
- VirusTotal 标签动态何时可信赖?
- 如何整合从不同引擎得到的标签?
- 不同的引擎之间参考权值是相等的吗?
(1)首先,开展标签动态测量分析,测量同一个引擎对给定文件的标签动态反转(flip)频率。
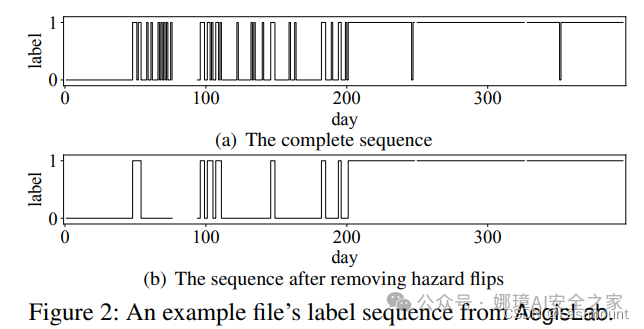
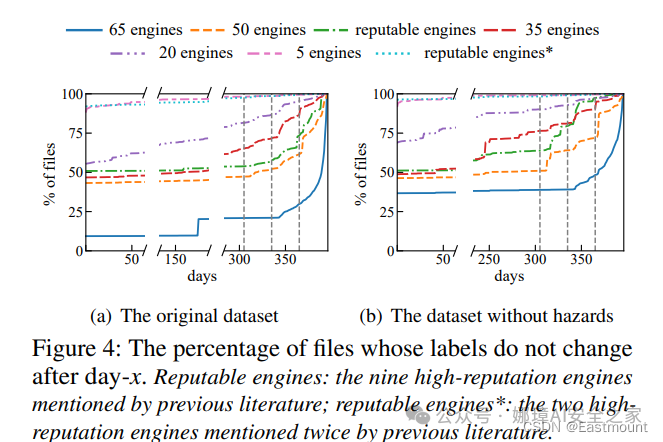
结论:引进阈值有助于标签动态整合结果趋于稳定,提高测试结果对标签动态变化的适应性与耐受性。但这并不意味着这个检测结果就一定正确,即准确性无法通过阈值分析得到保证。
(2)开展不同引擎间标签动态的关联分析。 本文对不同引擎间得到标签序列之间的关联进行分析,并得到了每个系统的易受影响程度。为了比较不同引擎对同一文件的标签序列,本文引进了两个序列间距离 distance 的概念,并提出了两种引擎间关联模型。
- 主动影响模型(Active Influence Model)
- 被动模型(Passive Model)

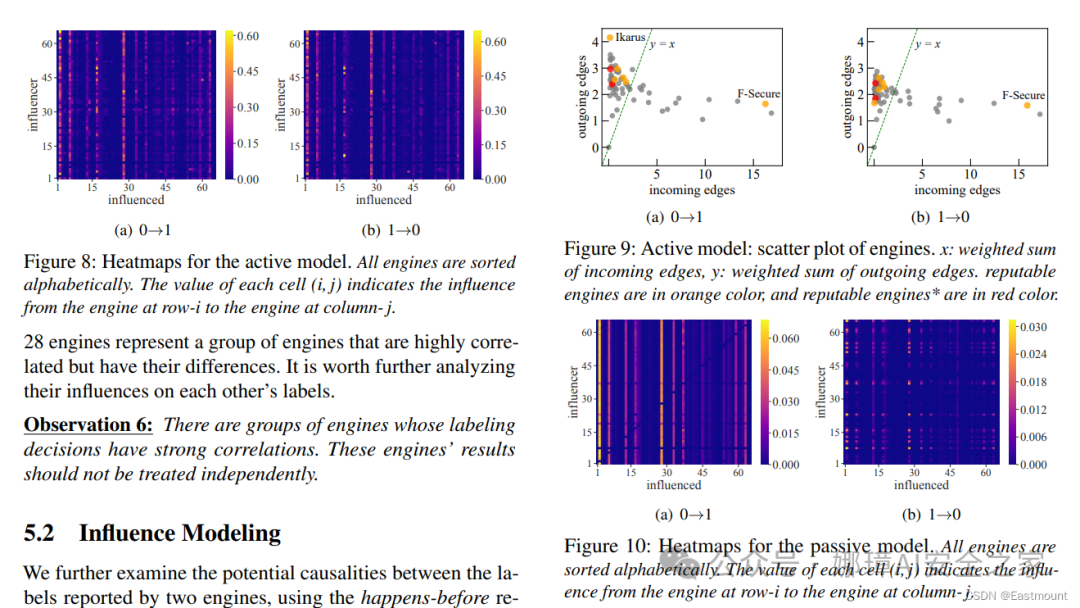
结论:系统检测结果由恶意到良性的 flips 更容易受到最近发生相同 flips 的系统影响,而不是保持良性标签的系统。
(3)开展Ground-Truth数据集的验证分析
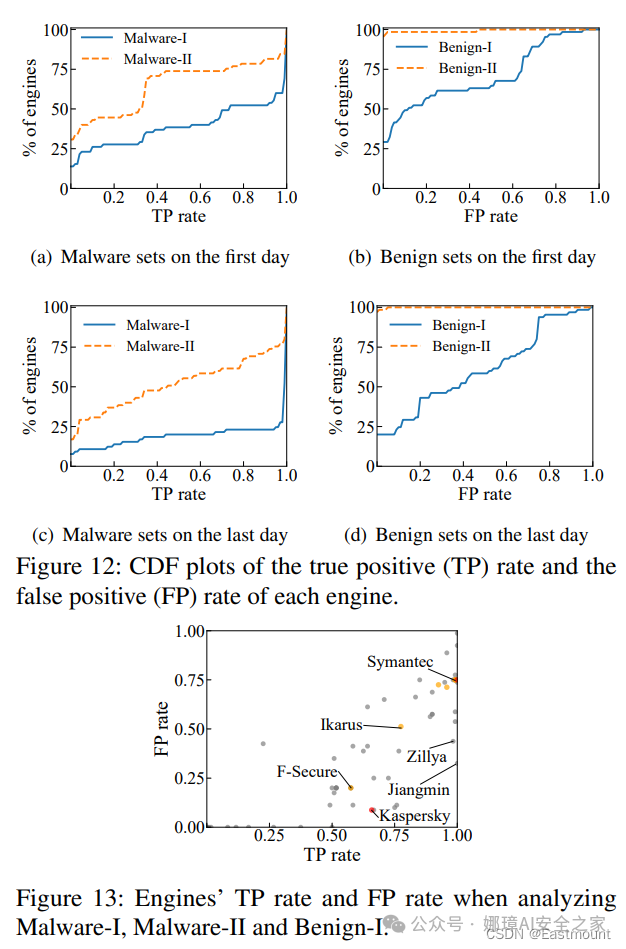
最终结论:针对VirusTotal恶意软件在线分析平台当前存在的问题,本文基于数据驱动的模型,指出采信结果时应去除频繁反转的部分,探索选取合适的阈值应用于标签动态整合最终测试结果。同时,通过建立不同引擎间的关联证明了其中一些引擎存在紧密联系,部分系统易受其他系统影响,推翻了所有引擎平权综合的假设。最后用正确标注好的参考数据来检验结论的正确性。
五.总结
写到这里,这篇文章就介绍完毕,下一篇会介绍火绒软件。基础性文章,希望对您有所帮助。
行路难,多歧路。感谢家人的陪伴,小珞最近长大了很多,调皮又可爱,走路都在唱歌,希望她也一样。感谢大家2023年的支持和关注,让我们在2024年继续加油!分享更多好文章,感恩,娜璋白首。
(By:Eastmount 2024-01-22 夜于火星)
欢迎大家订购Eastmount的知识星球,其会更系统地分享网络安全、系统安全、人工智能及科研实践的文章,共勉。
参考文献,再次感谢这些大佬。
- [1] 作者前文恶意软件博客&李师弟指导
- [2] https://docs.microsoft.com/en-us/windows/security/threat-protection/intelligence/malware-naming
- [3] https://xz.aliyun.com/t/5666
- [4] https://www.usenix.org/system/files/sec20-zhu.pdf
- [5] 深入了解 VirusTotal 的数据与文件聚类
- [6] 【论文学习】测量和建模恶意软件在线分析平台的标签动态