云原生实践总结

云原生实践总结
? 作为一名SRE,在运维云原生过程中的实践总结、沉淀,以便自己回顾和他人查阅,希望能帮助你在云原生领域的平稳落地。 ? 全文字数:1.6k+ ? 阅读时长:4min
企业落地云原生的目的
一句话概括:在保证稳定性的前提下,降本增效
目标拆解:
- 保障稳定性
- 建设高可用性:基础组件(Master三大件/Etcd等)高可用、多机房、多集群、Pod 高可用
- 持续进行风险治理:耦合度、故障发现、容量、容灾、变更及可运维性、安全性
- 建设可观测性:Metrics、Logging、Tracing、Events、Chaos、Dashboard、Inspection
- 故障演练:Apiserver 高可用故障演练、Etcd 高可用故障演练、双机房切换故障演练
- 预案建设:Etcd 备份恢复、Velero 备份恢复、Master 节点紧急扩容、Etcd 节点紧急扩容、多集群故障迁移
- 性能/容量评估:物理机性能压测、Master 组件性能压测、Etcd 性能压测、应用性能压测
- 节约成本
- 推进无状态应用容器化
- 推进无状态应用接入弹性伸缩
- K8s 调度能力增强:预选、优选、重调度(使资源分配均匀、提高装箱率、提高资源使用率)
- 持续进行应用容量治理:横向缩容(降副本数)、纵向缩容(降规格 CPU/MEM)
- 建立资源画像:调度和容量治理依赖资源画像
- 提高效率(平台能力建设)
- 自动化运维平台(面向开发):容器生命周期管理、Ingress 生命周期管理、HPA 生命周期管理、扩缩容&升降配、容器资源预留、Java Dump & GCLog、屏蔽/恢复告警
- 发布系统(面向开发):Java/Nodejs/静态资源模版、自定义镜像、自定义模版、滚动发布、灰度发布、启动日志查看
- 堡垒机(面向开发):Web 终端、文件管理、日志审计
- SRE 平台(面向运维):集群安装、集群扩缩容、集群升级、插件安装、Ingress 节点扩缩容、Web Kubectl、集群自动化巡检、多集群迁移
总结为下图,拿走不谢?
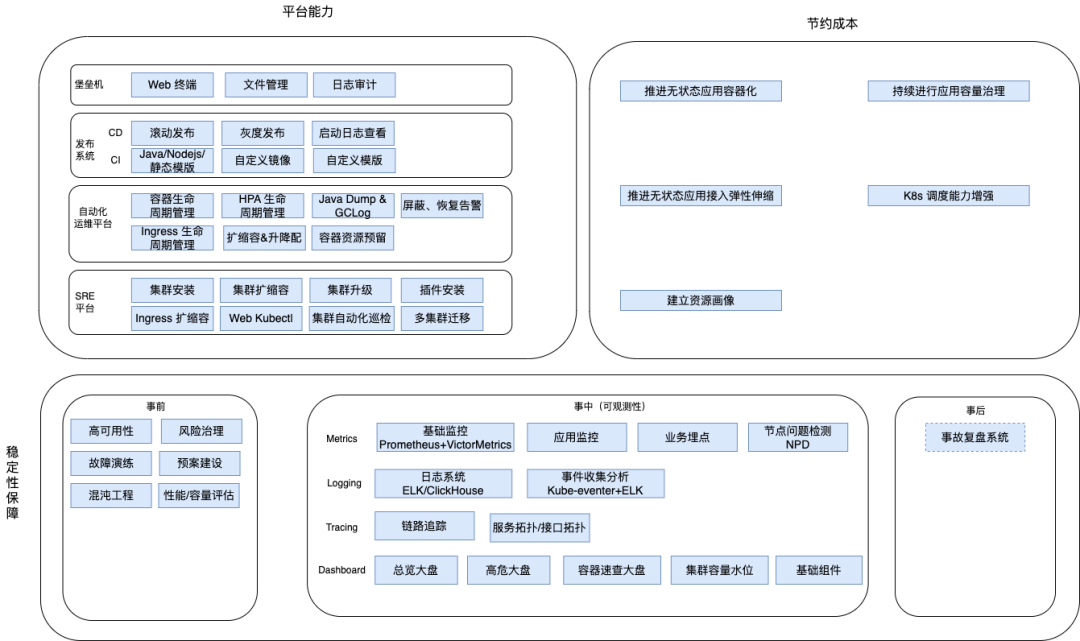
sre-k8s (2)
实践中使用到的 CNCF Landscape 项目

image-20240107175222642
按用途和熟悉度分类:
深度使用 | 轻度使用或测试环境试用 | 准备使用 | |
|---|---|---|---|
调度与编排 | Kubernetes、KEDA | Karmada、Volcano | |
协调与服务发现 | etcd、CoreDNS | ||
应用程序定义与镜像构建 | Helm、KubeVirt、Operator Framework | ||
持续集成与交付 | Argo | OpenKruise | |
Service Mesh | Istio | ||
云原生网络 | Calico | Cilium | |
云原生存储 | Rook、Longhorn | ||
可观测性 | Prometheus、VictoriaMetrics、Fluentd、Grafana、Chaosblade | OpenTelemetry | |
容器运行时 | Docker | containerd | |
镜像仓库 | JFrog Artifactory | Harbor | Dragonfly |
实践中遇到的问题&故障
? 问题 :
- 如何提高资源可见性?容器内 top free 命令看到的是宿主机资源使用情况
- 应用从 KVM 迁移到 容器 后,资源利用率为何发生变化?有增高的,有降低的
- 流量洪峰时,个别应用为啥容器比虚拟RT长?
- 新增 Ingress 后导致 RedirectUri 不一致?
- 自动注入service变量导致 Nodejs 负载变高?
- grpc 应用负载均衡问题,使用 service 和 Ingress 无效?
- 接入容器后,域名访问异常?
? 故障:
- Calico 异常重启?
- kubelet pleg ?
- Node 被清空?
- 什么?相同型号物理机 容器性能不如虚拟机?
文章更新预告
根据本期文章总结,后续会先更新以下文章,文章预告:
保障稳定性:
- 高可用性
- ? 既要稳也要省,容器资源该怎么分配(Qos 设置篇)?
- ? 巧用
shell-operator为核心应用自动注入 pdb - (已发表)? 容器化后无损上下线解决方案
- ? 多集群管理方案
- ? K8s 多机房高可用方案
- ? 建设 Pod 高可用性(优先级、Qos、打散、hpa、无损发布、pdb)
- ? Prometheus 高可用设计
- ? 风险治理篇琐碎整理(临时存储限制、告警与 AppID 负责人如何关联、审计日志重要性、Node 资源预留)
- 可观测性
- ? kube-prometheus 使用实践
- ? 使用 Fluentd 收集 K8s 日志
- ? K8s 组件改监控哪些核心指标?
- ? 自定义 K8s Dashboard 分享
- ? K8s 自动化巡检设计思路
- 故障演练
- ? Apiserver 高可用故障演练
- ? Etcd 高可用故障演练
- 预案建设
- ? Etcd 物理备份 + Velero 逻辑备份 & 恢复详解
- ? 多集群迁移设计思路
- 性能/容量评估
- ? 物理机性能压测方法详解(附 Github 源码)
- ? Master 组件性能压测
- ? Etcd 性能压测
- ? 物理机 MaxPod 到底设多少合适?
节约成本:
提高效率
- ? GitOps - ArgoCD 方案调研
- ? Argo Rollout 使用分享
- ? Argo Workflow 使用分享
- ? Jumpserver 二开实现容器 Web 终端、文件管理、日志审计(附 Github 源码)
CNCF 项目使用介绍
- ? Etcd 概述及使用实践
- ? Coredns 概述及使用实践
- ? Calico 概述及使用实践
- ? Helm 概述及使用实践
- ? KubeVirt 概述及使用实践
- ? Docker 概述及使用实践
问题故障汇总
- ? 容器化后常见 FAQ
- ? Calico 异常重启根因分析
参考链接:
CLOUD NATIVE LANDSCAPE https://cncf.landscape2.io/?group=projects-and-products
本文参与?腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-01-07,如有侵权请联系?cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读