如何免费用 Llama 3 70B 帮你做数据分析与可视化?


Llama 3 的发布,真可谓一石激起千层浪。前两天,许多人还对「闭源模型能力普遍大于开源模型」的论断表示赞同。但是,最新的 LLM 排行榜(https://chat.lmsys.org/?leaderboard),已经把新的趋势变化凸显在所有人面前。
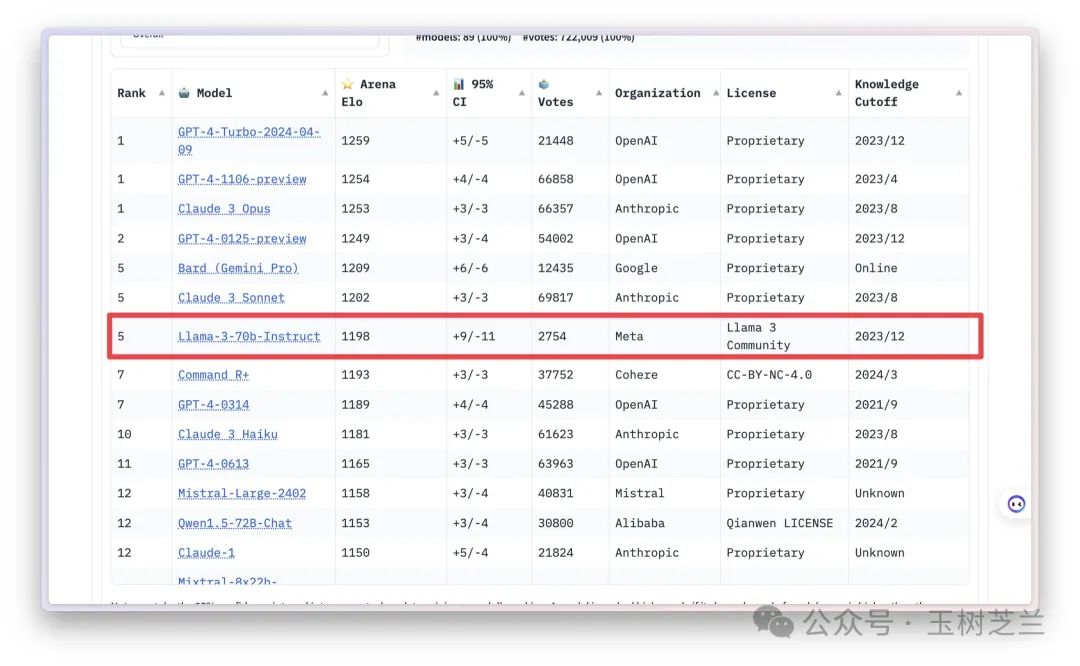
Llama 3 70B 的能力,已经可以和 Claude 3 Sonnet 与 Gemini 1.5 Pro 等量齐观,甚至都已经超过了去年的两款 GPT-4 。
更有意思的,就是价格了。实际上,不论是 8B 和 70B 的 Llama 3 ,你都可以在本地部署了。后者可能需要使用量化版本,而且要求一定显存支持。但是这对于很多人来说已经是非常幸福了,因为之前在本地想跑个 GPT-4 级别的模型是可望不可及的事儿。
我找到了一个 大语言模型性价比排行榜(https://llmpricecheck.com/),你可以参考一下。
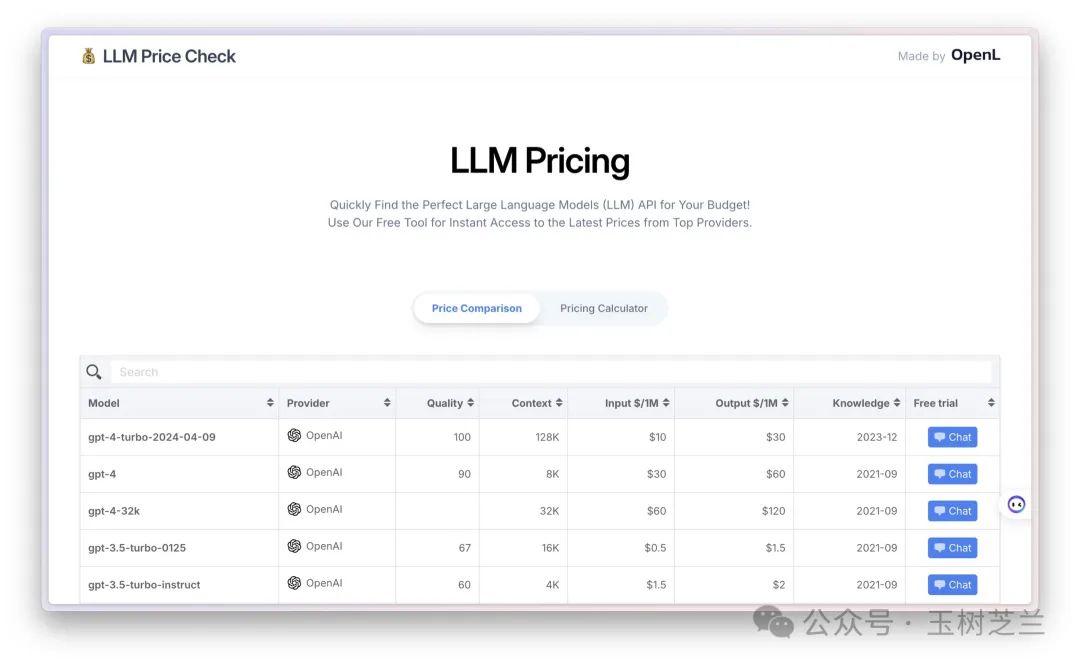
如果你只看模型能力,Llama 3 70B 目前还只能屈居第六,但是你对比一下价格,就会明白恐怖在哪里了。
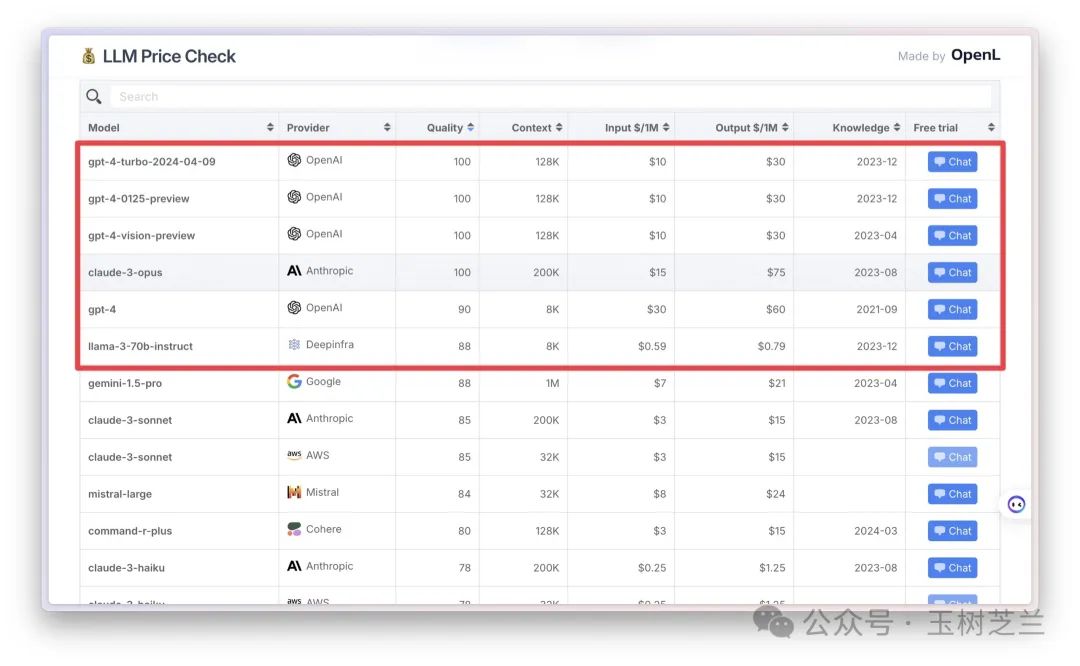
同样是 1M token 输入 + 1M token 输出,前 5 名里面最便宜的 GPT-4 Turbo ,也要 30 美金;而 Llama 3 70B 成本连 1 美金都不到。
Llama 3 70B 到底好不好用呢?
我第一时间就做了测试。
顺便说一下,目前能够使用 Llama 3 70B 对话的地方很多,包括但不限于 Meta 官方的 meta.ai,Huggingface 的 Huggingchat,Perplexity Lab,以及 GroqChat。
我使用的是 Huggingchat ,让它给我编写一个 pong 游戏。代码生成速度很快。
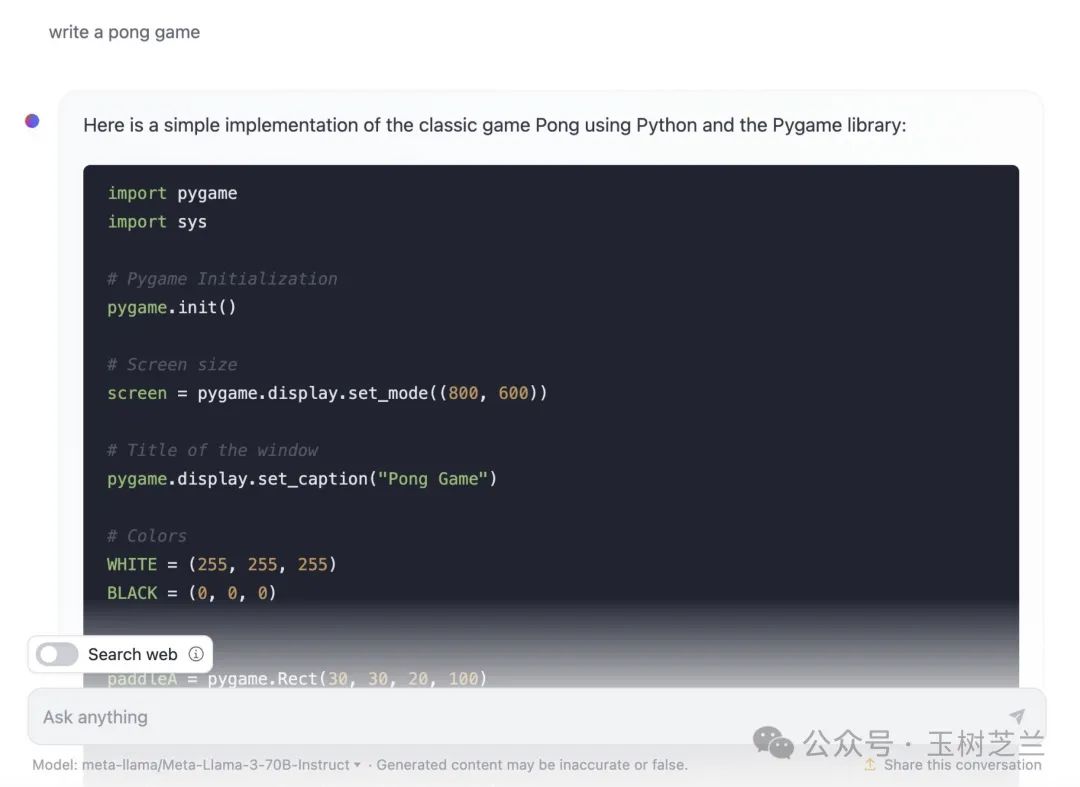
之后,我把代码直接贴到了 Visual Studio Code 里面,然后运行。
结果是毫无报错,直接顺利运行。

左手 W, S 按键,右手上下按键。左右互搏,我玩儿了个不亦乐乎,哈哈。
我一下子来了灵感 —Llama 3 70B 这东西的编程能力既然这么好,为什么不用它和 Open Interpreter 结合,帮我做数据分析呢?
哦,对了,到哪儿调用它的 API 呢?
别忘了,咱们有 Openrouter 啊!
Openrouter 几乎第一时间,就把 Llama 3 70B 和 8B 两个 Instruct 模型加了进去,而且定价非常便宜。

运行起来,只需要把原先调用 Haiku 时候的命令
interpreter --model openrouter/anthropic/claude-3-haiku -y --context_window 200000 --max_tokens 8196 --max_output 8196替换成:
interpreter --model openrouter/meta-llama/llama-3-70b-instruct -y --context_window 200000 --max_tokens 8196 --max_output 8196具体的安装配置方式,请参考《如何用 Claude 3 Haiku 帮你低成本快速自动分析数据?》这篇文章。
所以你看,Openrouter 真是个大语言模型的自选超市,方便啊。
可惜,运行的效果并不理想。Llama 3 70B 非得在编程的时候开头儿多加一些表示代码段的反引号,然后就一直在运行代码时挣扎纠结,最后干脆退出了。

我很失望,不过阴差阳错居然想到,应该 Llama 3 8B 也拿出来试试看。
interpreter --model openrouter/meta-llama/llama-3-8b-instruct -y --context_window 200000 --max_tokens 8196 --max_output 8196结果呢?一开始一样,也是在代码开头儿有反引号,但是我只是在提示词里告诉它一下,不要加,然后…… 它居然就解决,并且顺利运行成功了!
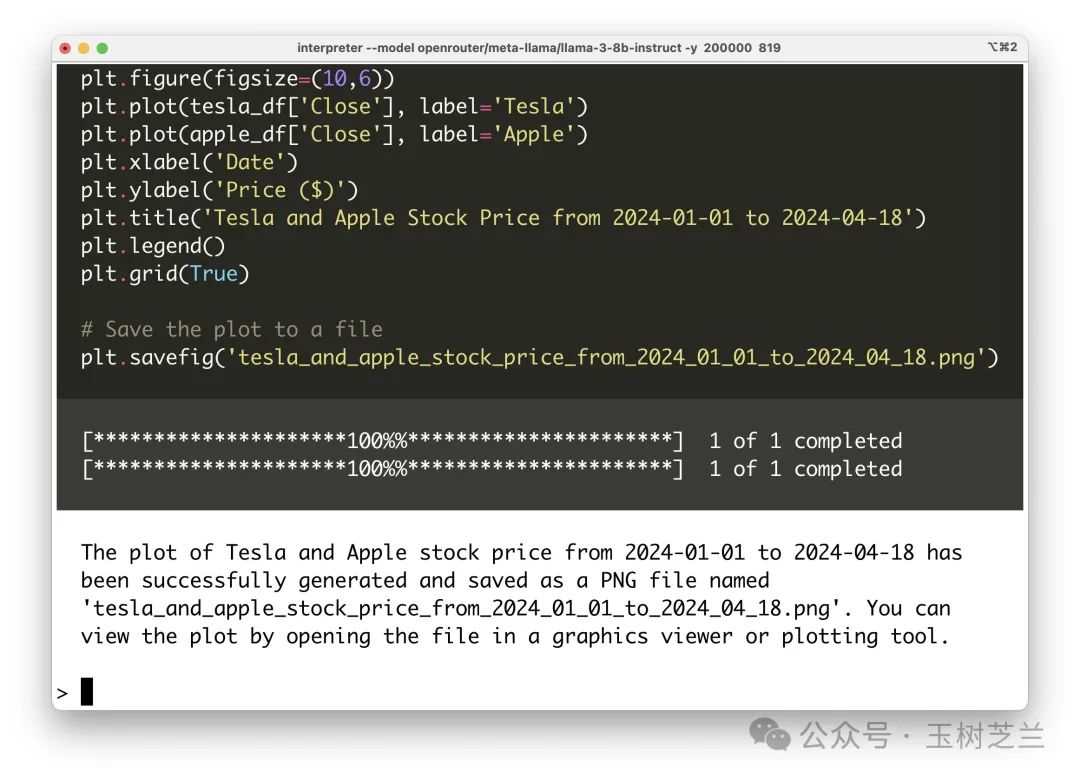
这是 Open Interpreter + Llama 3 8B 根据我的提示,绘制的特斯拉和苹果公司年初至今的股价变动。
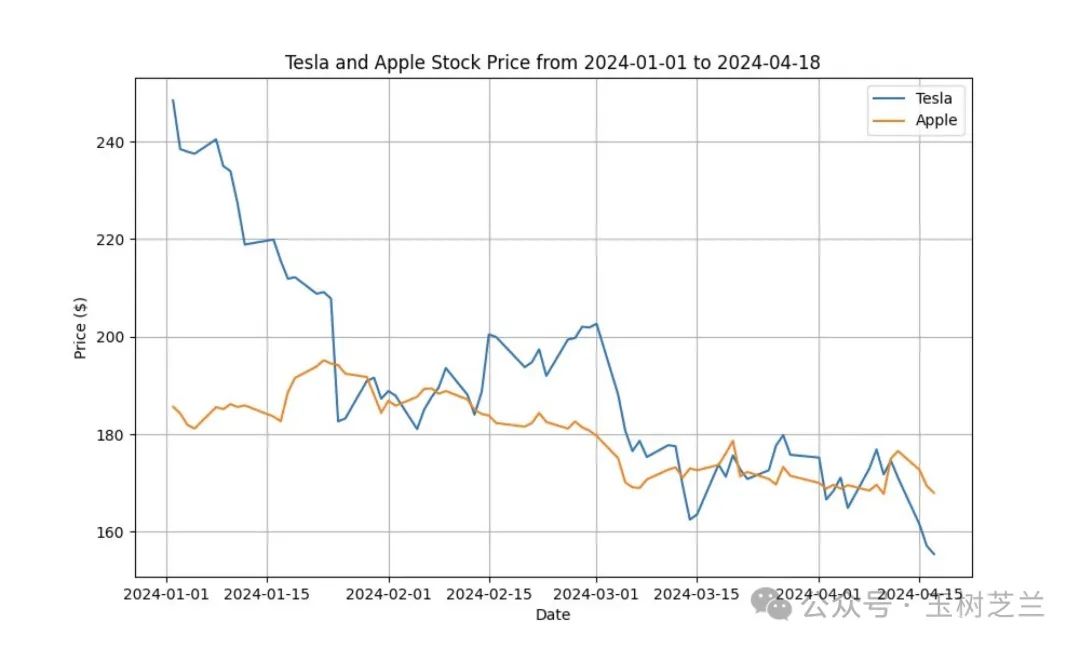
我得出来的结论,是 8B 这个小模型没有 Llama 3 70B 那么「拧」,哈哈。
但是,我显然心有不甘。毕竟比起来,我更喜欢使用能力强 Llama 3 70B。
好在转机很快就来了。
转机发生在 Groq 上。
如果说其他 AI 大语言模型公司和团队在拼的是模型答题准确率、上下文长度之类的指标,那么 Groq 就非常有意思了。它专注于提供服务,把其他家做出来的模型变得更快。
你看看它提供的模型列表:
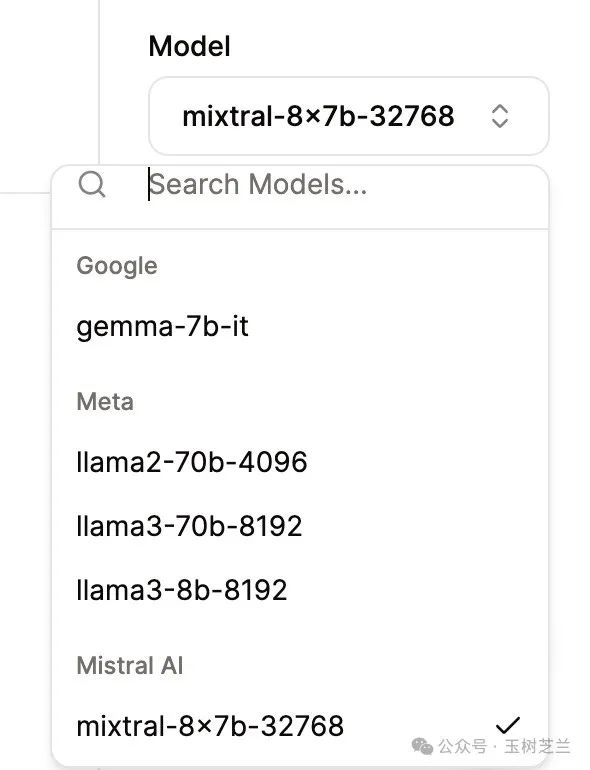
没有一个模型是它原创,但是它就是能够把模型推理速度提升到令人不可思议的地步。
在 Groq 里面,用流式输出没啥意义,因为你能体会到「唰啦」一下子结果就输出完毕了。

更有意思的是,它提供了一个 Free Beta 模式,目前你使用上面的模型,包括其中最强的Llama 3 70B,都是免费的。
下面咱们试试,用它来结合 Open Interpreter 进行数据分析。
interpreter --model groq/llama3-70b-8192 -y --context_window 200000 --max_tokens 8192 --max_output 8192我把完整的运行过程录制了下来。请注意,我没有进行任何的剪辑或者加速。
没错,就是这么行云流水,从计划到编程直到输出,全都快速搞定。
然后,这是生成并保存在本地的结果图。

当然,我也尝试了用它来做词云,一样是飞快搞定。这里就不赘述了。你可以用这个新的开源模型,加上 Groq 快速推理机制,把之前的 9 大数据分析与可视化样例免费重做一遍,看看比起 Claude 3 Haiku 来 Llama 3 70B 是不是有很大的进步。