CVPR 2024 | 腾讯优图实验室20篇论文入选,含图文多模态大模型、高分辨视觉分割、跨模态生成、人脸识别等研究方向
CVPR 2024 | 腾讯优图实验室20篇论文入选,含图文多模态大模型、高分辨视觉分割、跨模态生成、人脸识别等研究方向

近日,CVPR 2024 (IEEE Conference on Computer Vision and Pattern Recognition) IEEE国际计算机视觉与模式识别会议公布了论文录用结果。
作为全球计算机视觉与模式识别领域的顶级会议,CVPR每年都吸引着全球众多研究者和企业的关注。入选CVPR的论文需要经过严格的评审流程,确保其创新性和实用性达到国际领先水平。
今年,腾讯优图实验室共有20篇论文入选,内容涵盖图文多模态大模型、高分辨视觉分割、跨模态生成、人脸识别等多个研究方向,展示了腾讯优图实验室在人工智能领域的长期技术积累和研究实力。
以下为入选论文概览:
01
在图文多模态大模型中使用对比学习来增强视觉文档理解
Enhancing Visual Document Understanding with Contrastive Learning in Large Visual-Language Models
Xin Li*, Yunfei Wu*, Xinghua Jiang, Zhihao Guo, Mingming Gong, Haoyu Cao, Yinsong Liu, Deqiang Jiang, Xing Sun
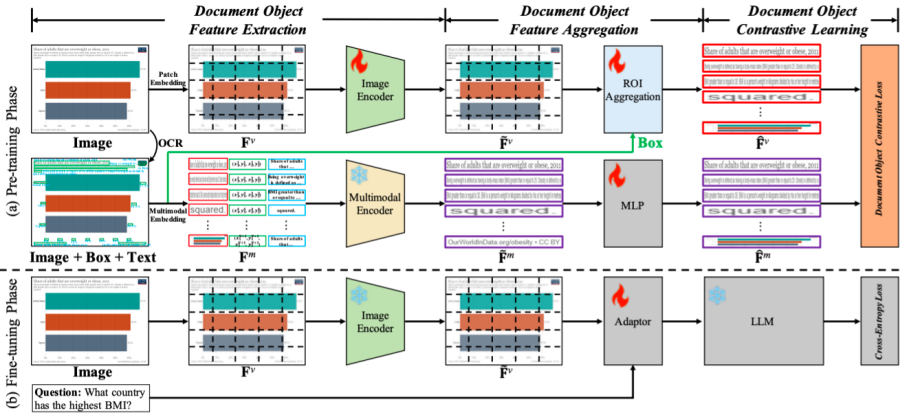
近期,图文多模态大模型(LVLMs)的出现在各个领域引起了越来越多的关注,特别是在视觉文档理解(VDU)领域。与传统的视觉-语言任务不同,VDU特别关注包含丰富文档元素的文本丰富场景。然而,细粒度特征的重要性在LVLMs社区内仍未被充分探索,导致在文本丰富场景中的性能不尽如人意。在这篇论文中,我们将其简称为细粒度特征崩溃问题。为了填补这个空白,我们提出了一个对比学习框架,名为文档对象对比学习(DoCo),专门为VDU的下游任务量身定制。DoCo利用一个辅助的多模态编码器获取文档对象的特征,并将它们与LVLM的视觉编码器生成的视觉特征对齐,从而在文本丰富场景中增强视觉表示。这可以表明,视觉整体表示和文档对象的多模态细粒度特征之间的对比学习可以帮助视觉编码器获取更有效的视觉线索,从而增强LVLMs对文本丰富文档的理解。我们还证明了所提出的DoCo可以作为一个即插即用的预训练方法,可以在各种LVLMs的预训练中使用,而不会在推理过程中增加任何计算复杂性。在多个VDU基准测试的广泛实验结果显示,配备我们提出的DoCo的LVLMs可以实现优越的性能,并缩小VDU和通用视觉-语言任务之间的差距。
论文链接:
https://arxiv.org/pdf/2402.19014
02
论文链接:
https://arxiv.org/pdf/2402.19014
02
基于可学习残差表示的隐私保护人脸识别方法
Privacy-Preserving Face Recognition Using
Trainable Feature Subtraction
Yuxi Mi (Fudan University), Zhizhou Zhong (Fudan University), Yuge Huang, Jiazhen Ji, Jianqing Xu, Jun Wang, ShaoMing Wang, Shouhong Ding, Shuigeng Zhou (Fudan University)
* 本文由腾讯优图实验室、腾讯微信支付33号实验室、复旦大学共同完成
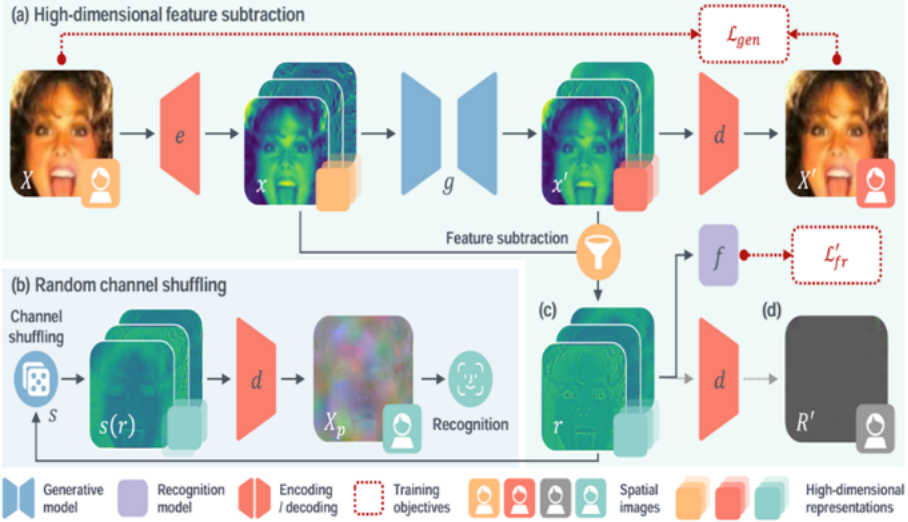
人脸面部图像中存在重要的视觉特征,在使用和共享中需加以保护。本文提出一种新的隐私保护人脸识别方法,MinusFace,将面部图像转换为隐藏外观、同时可识别的图像域保护表示。本文观察到图像有损压缩技术中,原始与压缩图像相减所得残差表示,具备不包含视觉特征,同时描述原始图像的性质。受此启发,本文提出了表示相减方法:训练一对生成和识别模型,将原始图像与其经生成模型重新合成的图像相减获得可学习的残差表示,作为识别模型输入。协同训练两个模型,减少残差表示中的视觉特征,同时保留识别信息。本文进一步采用高维空间映射和通道顺序变换技术,以改善残差表示的隐私性和识别效果。广泛实验表明MinusFace可以取得当前先进水平的人脸识别准确率和隐私保护效果,同时较既往方法显著压缩保护表示大小。
论文链接:http://arxiv.org/abs/2403.12457v1
03
高分辨率视觉文档助手
HRVDA: High-Resolution Visual Document Assistant
Chaohu Liu(USTC), Kun Yin,Haoyu Cao, Xinghua Jiang, Xin Li, Yinsong Liu, Deqiang Jiang, Xing Sun, Linli Xu(USTC )
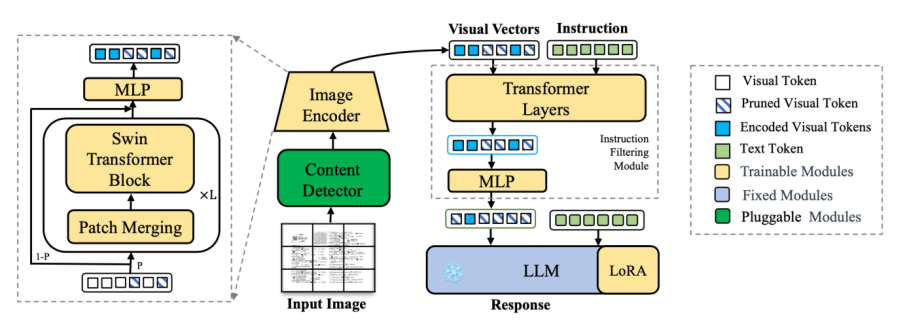
多模态大型语言模型(MLLMs)展示了强大的通用视觉理解能力,并在各种任务中取得了显著的性能,然后常见的多模态大预言模型只能处理低分辨率图片。低图像分辨率可能导致大量图像信息的丢失,从而导致模型性能下降。此外,通用的MLLMs在处理文档特定指令方面表现不佳。在本文中,我们提出了一种高分辨率视觉文档助手(HRVDA),它弥合了MLLMs和视觉文档理解之间的差距。该模型采用内容过滤机制和指令过滤模块,分别过滤出与内容无关的视觉标记和与指令无关的视觉标记,从而有效地实现模型的训练和推理。此外,我们构建了一个文档特定的指令调整数据集,并应用多阶段训练策略来增强模型的文档建模能力。大量实验证明,我们的模型在多个文档理解数据集上实现了最先进的性能,同时保持了与主流低分辨率模型相当的训练效率和推理速度。
论文链接:http://arxiv.org/abs/2404.06918v1
04
深度神经网络模型的数据可用性攻击方法
Re-thinking Data Availablity Attacks Against Deep Neural Networks
Bin Fang(Shanghai Jiao Tong University), Bo Li, Shuang Wu, Shouhong Ding, Ran Yi(Shanghai Jiao Tong University), Lizhuang Ma(Shanghai Jiao Tong University)

未经授权使用个人数据进行商业目的以及为训练机器学习模型而秘密获取私人数据的行为持续引发关注。为解决这些问题,业界提出了可用性攻击,旨在使数据不可被随便利用。然而,许多可用性攻击方法容易受到对抗性训练的干扰。尽管一些强大的方法可以抵抗对抗性训练,但其保护效果有限。在本文中,我们重新审视现有的可用性攻击方法,并提出一种新颖的两阶段最小-最大-最小优化范式来生成强大的不可学习噪声。内部最小阶段用于生成不可学习噪声,而外部最小-最大阶段模拟了被对抗攻击模型的训练过程。此外,我们对攻击效果进行了量化定义,并将其用于约束优化目标。综合实验表明,与现有技术相比,我们的方法生成的噪声可以使经过对抗性训练的被攻击的模型的测试精度降低约30%。我们的方法为该领域的未来研究奠定了基础。
论文链接:https://arxiv.org/abs/2305.10691
05
Real-IAD: 用于多种工业异常检测算法评估的多视角真实场景数据集
Real-IAD: A Real-World Multi-view Dataset for Benchmarking Versatile Industrial Anomaly Detection
Chengjie Wang, Wenbin Zhu (Fudan Univesity, Roogcheer Industrial Tech), Binbin Gao, Zhenye Gan, Jiangning Zhang, Zhihao Gu(Shanghai Jiao Tong University), Shuguang Qian (Roogcheer Industrial Tech), Mingang Chen (Shanghai Development Center of Computer Software Technology), Lizhuang Ma(Shanghai Jiao Tong University)

工业异常检测(IAD)已经引起了重大关注,并经历了快速的发展。然而,由于数据集限制,最近的IAD方法的发展遇到了一些困难。一方面,大多数最先进的方法在主流数据集(如MVTec)上已经达到了饱和(在AUROC中超过99%),方法之间的差异无法很好地区分,导致公共数据集与实际应用场景之间存在显著的差距。另一方面,由于数据集规模的限制,对各种新的实用异常检测设置的研究存在过拟合的风险。因此,我们提出了一个大规模、真实世界和多视角的工业异常检测数据集,名为Real-IAD,它包含了30种不同对象的150K高分辨率图像,比现有的数据集大一个数量级。它具有更大范围的缺陷面积和比例,使其比以前的数据集更具挑战性。为了使数据集更接近实际应用场景,我们采用了多视角拍摄方法,并提出了样本级评估指标。此外,除了一般的无监督异常检测设置,我们还根据观察到的工业生产中的良品率通常大于60%的情况,提出了一种全新的全无监督工业异常检测(FUIAD)设置,这具有更实际的应用价值。最后,我们报告了在Real-IAD数据集上流行的IAD方法的结果,为推动IAD领域的发展提供了一个高度具有挑战性的基准。
论文链接:https://arxiv.org/abs/2403.12580
06
用于参数高效网络堆叠的低秩残差结构
LORS: Low-rank Residual Structure for Parameter-Efficient Network Stacking
Jialin Li, Qiang Nie, Weifu Fu, Yuhuan Lin, Guangpin Tao, Yong Liu, Chengjie Wang
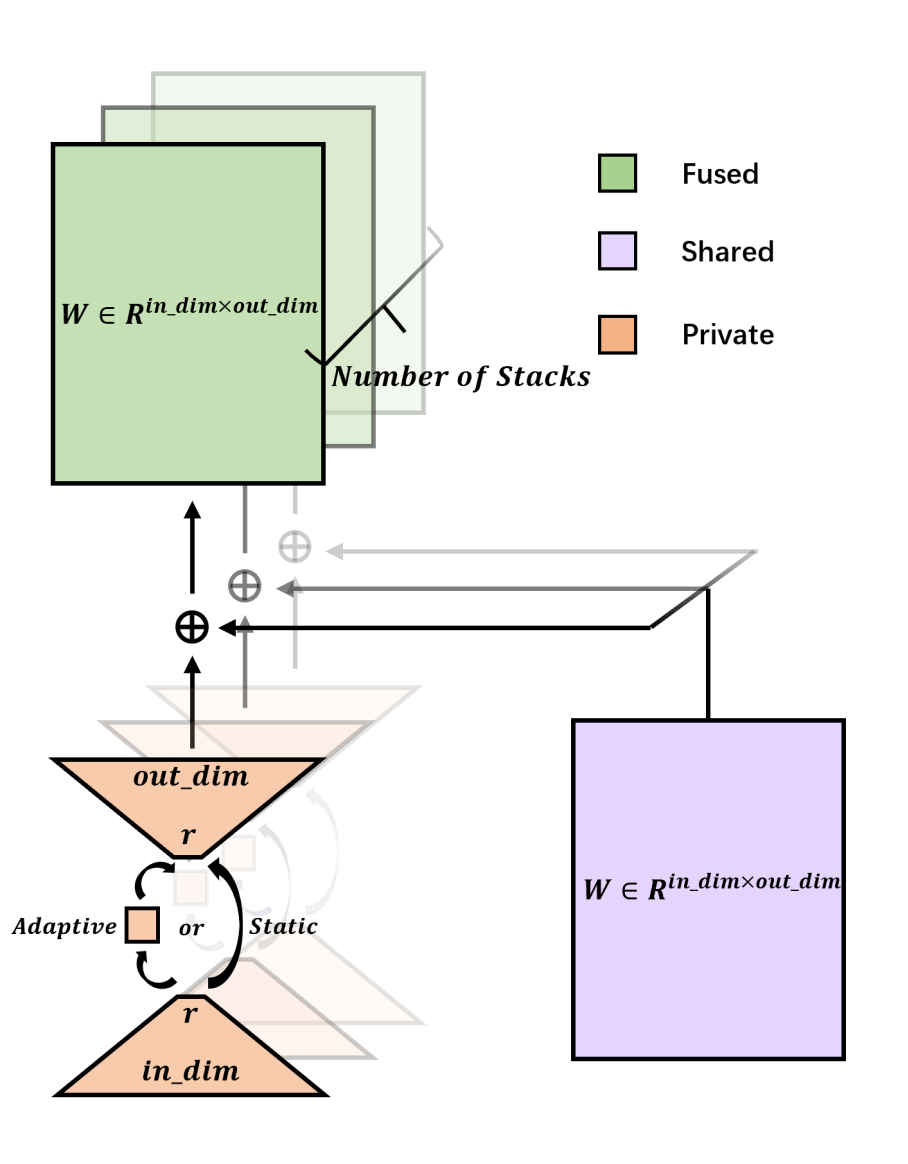
深度学习模型,尤其是基于transformer的模型,通常采用许多堆叠结构,这些结构具有相同的架构并执行类似的功能。尽管这种堆叠范式有效,但它导致参数数量大幅增加,给实际应用带来挑战。在如今越来越大的模型格局中,堆叠深度甚至可以达到几十层,进一步加剧了这个问题。为了缓解这个问题,我们引入了LORS(LOw-rank Residual Structure,低秩残差结构)。LORS允许堆叠模块共享大部分参数,每个模块只需要更少的私有参数即可达到甚至超过使用完全不同参数的性能,从而显著减少参数使用。我们通过将其应用于基于query的对象检测器的堆叠解码器来验证我们的方法,并在广泛使用的MS COCO数据集上进行大量实验。实验结果表明,我们的方法非常有效,即使在解码器参数减少70%的情况下,我们的方法仍然能使模型达到与原始模型相当甚至更好的性能。我们希望我们的工作能激发更多相关研究。
论文链接:https://arxiv.org/abs/2403.04303v1
07
一次对齐和提示所有内容的通用视觉感知
Aligning and Prompting Everything All at Once for Universal Visual Perception
Yunhang Shen, Chaoyou Fu, Peixian Chen, Mengdan Zhang, Ke Li, Xing Sun, Yunsheng Wu, Shaohui Lin (East China Normal University), Rongrong Ji (Xiamen University)

最近,人们已经开始探索视觉基础模型,以构建通用视觉系统。然而,主导的范式,通过将实例级任务视为对象-词对齐,带来了重度的跨模态交互,这在促进目标检测和视觉定位方面并不有效。另一种侧重于像素级任务的工作线经常遇到大量的可数前景和不可数背景的标注差距,并且前景目标和背景类别分割之间的相互干扰。与主流方法截然不同,我们提出了APE,一种通用的视觉感知模型,用于在图像中一次性对齐和提示所有事物,以执行多样化的任务,即,检测、分割和定位,作为一个实例级的句子-目标匹配范式。具体来说,APE通过将语言引导的定位重新定义为开放词汇检测,推进了检测和定位的融合,这有效地扩大了模型提示到数千个类别词汇和区域描述,同时保持了跨模态融合的有效性。为了弥补不同像素级任务的粒度差距,APE通过将任何孤立区域视为单个实例,将语义和全景分割等同于代理实例学习。APE在广泛的数据上对齐视觉和语言表示,一次性处理所有自然和具有挑战性的特征,而无需任务特定的微调。在超过160个数据集上的广泛实验表明,APE仅使用一套权重,就超过(或与)了最先进的模型,证明了一个有效且通用的感知任何对齐和提示的模型确实是可行的。
论文链接:
https://arxiv.org/pdf/2312.02153
08
基于令牌扩展的注意力模型的通用高效训练
A General and Efficient Training for Transformer via Token Expansion
Wenxuan Huang (East China Normal University), Yunhang Shen, Jiao Xie (Xiamen University), Baochang Zhang, Gaoqi He (East China Normal University), Ke Li, Xing Sun, Shaohui Lin (East China Normal University)

视觉注意力模型(ViTs)的卓越性能通常需要极大的训练成本。现有方法试图加速ViTs的训练,但通常会忽略方法的通用性,导致准确性下降。同时,他们破坏了原始注意力模型的训练一致性,包括超参数、架构和策略的一致性,这阻碍了它们被广泛应用于不同的注意力网络。在本文中,我们提出了一种新颖的令牌增长方案Token Expansion(简称ToE),以实现ViTs的一致性训练加速。我们引入了一个“初始化-扩展-合并”的流程,以保持原始注意力中间特征分布的完整性,防止训练过程中关键可学习信息的丢失。ToE不仅可以无缝地集成到注意力(例如DeiT和LV-ViT)的训练和微调过程中,而且对于高效训练框架(例如EfficientTrain)也是有效的,无需扭曲原始训练超参数、架构,并引入额外的训练策略。大量实验表明,ToE以无损方式实现了ViTs训练速度的约1.3倍提升,甚至在全令牌训练基线上取得了性能提升。
论文链接:https://arxiv.org/abs/2404.00672
代码链接:https://github.com/Osilly/TokenExpansion
09
广义范畴发现中灾难性遗忘问题的求解
Solving the Catastrophic Forgetting Problem in Generalized Category Discovery
XINZI CAO (Xiamen University), Xiawu Zheng (Xiamen University), Guanhong Wang (Zhejiang University), Weijiang Yu (SUN YAT-SEN UNIVERSITY), Yunhang Shen, Ke Li, Yutong Lu (SUN YAT-SEN UNIVERSITY), Yonghong Tian (Peking University)
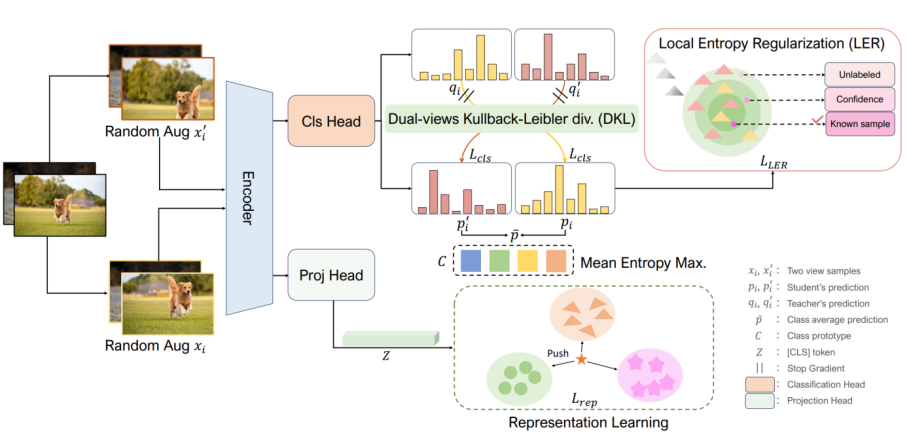
广义类别发现(GCD)旨在识别无标签数据集中已知和新颖类别的混合,为图像识别提供更现实的设置。本质上,GCD需要彻底记住现有模式以识别新颖类别。最近的最先进方法SimGCD通过去偏学习将已知类数据的知识转移到新类的学习中。然而,在适应过程中,一些模式被灾难性地遗忘,从而导致新类别分类的性能不佳。为了解决这个问题,我们提出了一种新颖的学习方法,LegoGCD,它可以无缝地整合到先前的方法中,以提高对新类别的辨别能力,同时保持对以前遇到的已知类别的性能。具体来说,我们设计了两种技术,称为局部熵正则化(LER)和双视图Kullback-Leibler散度约束(DKL)。LER优化了无标签数据中潜在已知类样本的分布,从而确保在学习新类时保留与已知类别相关的知识。同时,DKL引入Kullback-Leibler散度,鼓励模型对来自同一图像的两个视图样本产生类似的预测分布。通过这种方式,它成功地避免了不匹配的预测,并同时生成了更可靠的潜在已知类样本。大量实验证明,所提出的LegoGCD在所有数据集上有效地解决了已知类别遗忘问题,例如,在CUB上分别提高了7.74%和2.51%的已知类和新类的准确性。
10
用于快速保持身份的多功能肖像模型
PortraitBooth : A Versatile Portrait Model for Fast Identity-preserved Personalization
Xu Peng (Xiamen University), Junwei Zhu, Boyuan Jiang, Ying Tai (Nanjing University), Donghao Luo, Jiangning Zhang, Wei Lin(Xiamen University), Taisong Jin(Xiamen University), Chengjie Wang, Rongrong Ji (Xiamen University)

本文提出一种基于扩散模型的个性化图像生成方法(PortraitBooth),能够在满足高效率、鲁棒身份保持的条件下实现表情可编辑的文本到图像生成。首先,利用人脸识别模型获得的特征嵌入进行个性化图像生成,降低了计算开销并缓解了身份失真问题。其次,引入动态身份保护策略确保生成图像与原始图像高度相似。最后,融入情感感知的交叉注意力控制用于生成图像中的多样化面部表情,并支持文本驱动的表情编辑。实验结果表明:无论是在单一还是多目标图像生成场景,本文方法明显优于现有方法,获得更好的个性化图像生成效果。
论文链接:https://arxiv.org/abs/2312.06354
11
基于隐层重建特征的生成图像检测方法
LaRE^2: Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection
Yunpeng Luo, Junlong Du,Ke Yan, Shouhong Ding
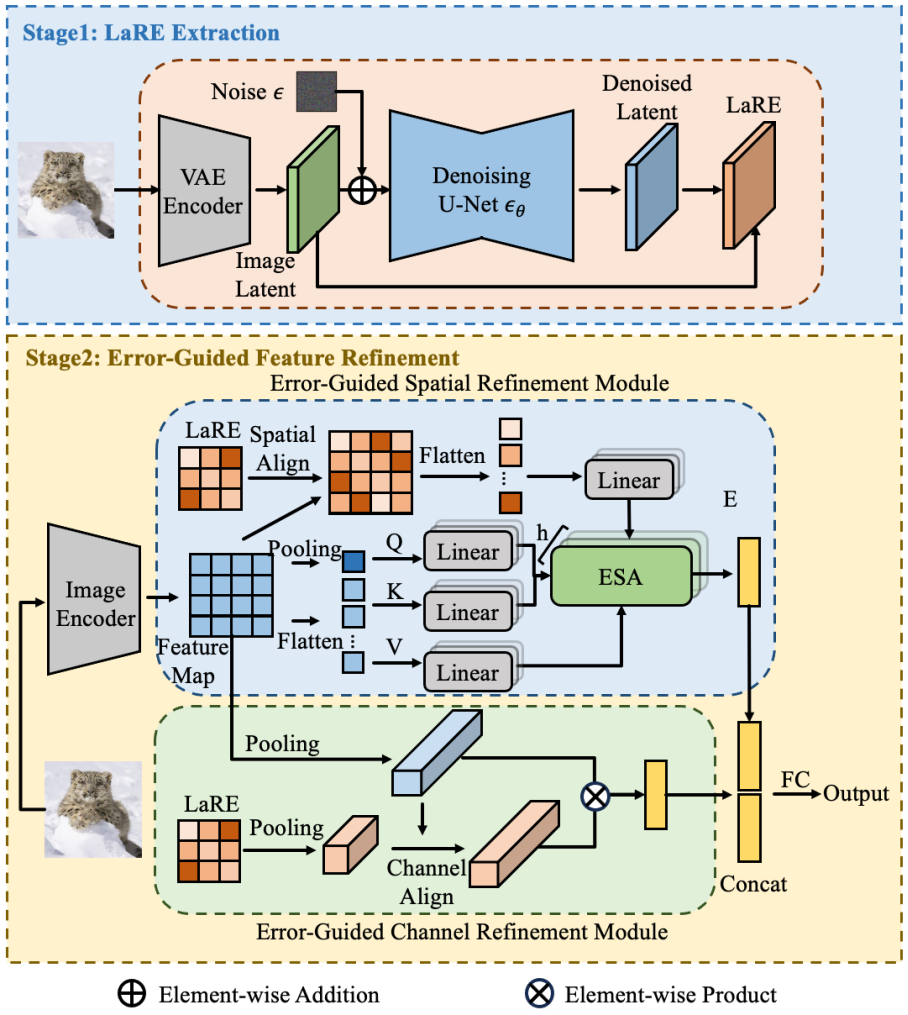
扩散模型的进步显著提升了图像生成质量,使得真实图像与生成图像的区分变得越来越难。这种进步虽然令人兴奋,但也带来了严重的隐私和安全问题。为了解决这个问题,我们提出了一种新颖的特征增强方法,名为基于隐层重建误差的特征增强(LaRE^2),用于检测扩散模型生成的图像。我们首次将基于重建误差的隐层空间特征(LaRE)用于生成图像检测。LaRE在特征提取效率上超越了现有方法,同时保留了区分真实和生成图像的关键信息。为了充分利用LaRE,我们设计了一个误差引导的特征增强模块(EGRE),通过LaRE增强图像特征,提高特征的区分度。EGRE采用对齐+增强的策略,从空间和通道两个维度有效地增强了图像特征。在GenImage基准测试中,我们进行了大量实验,证明了LaRE^2的有效性。具体来说,LaRE^2在8个不同的图像生成模型上,平均准确率/平均精度超过了最佳现有方法高达11.9%/12.1%。同时,LaRE在特征提取速度上也超过了现有方法,是其速度的8倍。
论文链接:http://arxiv.org/abs/2403.17465v1
12
自蒸馏人体姿态估计
SDPose: Tokenized Pose Estimation via Circulation-Guide Self-Distillation
Sichen Chen(SJTU/Tencent), Yingyi Zhang, Siming Huang, Ran Yi(SJTU), Ke Fan(SJTU), Ruixin Zhang, Peixian Chen, Jun Wang, Shouhong Ding, Lizhuang Ma(SJTU)
* 本文由腾讯优图实验室、腾讯微信支付33号实验室、上海交通大学共同完成

小型自注意力模型往往受到欠拟合问题影响,为了解决这个问题,我们提出了自注意力模型的潜在深度概念,并基于此设计了一种自蒸馏的训练方法,该方法在人体姿态估计任务上相同性能的情况下能够降低25%的参数量与33%的运算量,同时在图像分类与分割任务中也证实有效。
论文链接:https://arxiv.org/abs/2404.03518
代码链接:https://github.com/MartyrPenink/SDPose
13
基于测试阶段域泛化的人脸活体检测方法
Test-Time Domain Generalization for Face Anti-Spoofing
Qianyu Zhou (Shanghai Jiaotong University),Ke-Yue Zhang,Taiping Yao,Xuequan Lu (Deakin University),Shouhong Ding,Lizhuang Ma (Shanghai Jiaotong University)
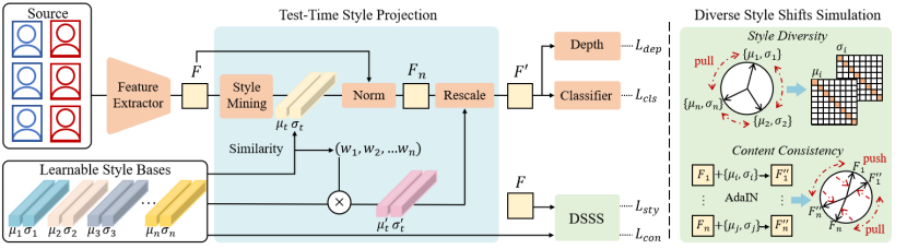
人脸活体检测旨在防止人脸识别系统免受各种人脸呈现攻击的干扰。现有的域泛化活体检测方法主要侧重于在训练过程中学习域不变特征,然而这可能无法保证在与源域分布具有巨大差异的未见目标域数据上的泛化性。本文的核心思想是,测试数据不仅仅是用于模型测试,还可以作为一种有价值的资源以提高对活体检测的泛化性。本文提出了一个新的测试阶段域泛化(TTDG)框架,该框架利用测试数据以提高模型的泛化能力。主要包括两个关键的组件:测试阶段风格投影(TTSP)和多样化风格偏移模拟(DSSS),以有效地将未见数据投影到可见的源域空间。其中,测试阶段风格投影将任意未知域的测试样本的风格投影到训练分布的已知源域空间。此外,本文设计了有效的多样化风格偏移模拟,通过两个特别设计的损失和可学习的风格基在超球面特征空间中合成不同的风格偏移。本方法不需要在测试时重新更新模型,并且不仅可以无缝集成到基于CNN的活体检测方法中,还可以集成到基于ViT主干的活体检测框架。在跨域活体检测基准的大量实验分析证明了所提方法的先进性和有效性。
论文链接:http://arxiv.org/abs/2403.19334v1
14
双曲空间中层级化原型引导分布建模的域泛化人脸活体检测方法
Rethinking Generalizable Face Anti-spoofing via Hierarchical Prototype-guided Distribution Refinement in Hyperbolic Space
Chengyang Hu (Shanghai Jiaotong University),Ke-Yue Zhang,Taiping Yao,Shouhong Ding,Lizhuang Ma (Shanghai Jiaotong University)

域泛化人脸活体检测方法因其对未见场景中的各种呈现攻击的鲁棒性而引起了越来越多的关注。大多数以前的域泛化方法总是通过将不同源域样本直接对齐到公共特征空间提升泛化能力。然而,这些方法忽略了活体攻击中的层次关系,直接对齐可能会阻碍泛化能力。为了解决这些问题,我们提出了一种新颖的层次化的原型引导分布细化框架在双曲空间中学习特征分布,这有利于构建层次关系。我们还引入原型学习,以实现双曲空间中的分层分布细化。具体来说,我们提出分层原型学习,通过约束双曲空间中原型和实例之间的多级关系来同时指导域对齐并提高判别能力。此外,我们设计一个面向原型的分类器,进一步考虑样本和原型之间的关系,以提高最终决策的稳健性。大量的实验和可视化证明了我们方法的有效性。
15
基于锚点的图文预训练模型鲁棒微调
Anchor-based Robust Finetuning of Vision-Language Models
Jinwei Han(Wuhan University), Zhiwen Lin, Zhongyi Sun, Yingguo Gao, Ke Yan, Shouhong Ding, Yuan Gao(Wuhan University), Guisong Xia(Wuhan University)

本文的目标是微调图文预训练模型并保持其在分布外(OOD)的泛化能力。本文解决了两种类型的OOD泛化问题,即i)领域偏移,例如从自然图像到草图图像,和ii)零样本识别能力,即识别未包含在训练数据中的类别。我们认为,图文预训练模型微调后OOD泛化能力的降低主要源于微调过程中监督信息过于简单,仅提供类别信息,如“a photo of a [CLASS]”。这与CLIP预训练过程不同,CLIP预训练过程中有丰富语义信息的文本监督。因此,我们提出使用具有丰富语义信息的辅助监督作为锚点来保留OOD泛化能力。具体而言,本文提出的方法使用了两种类型的锚点,包括i)文本补偿锚点,利用预训练好的captioner对训练数据集生成具有丰富语义信息的文本,ii)图像-文本对锚点,利用下游数据集作为查询集,从开源的图像-文本对数据集中检索而来。这些锚点被用作辅助语义信息,来保持CLIP的原始特征空间,进而保留OOD泛化能力。实验表明,我们的方法的分布内(ID)性能与传统微调方法基本持平,同时在领域偏移和零样本学习基准测试中取得了最优结果。
论文链接:https://arxiv.org/abs/2404.06244
16
基于可微分视觉提示的零样本目标指代理解
Tune-An-Ellipse: CLIP Has Potential to Find What You Want
Jinheng Xie(National University of Singapore),Songhe Deng(Shenzhen University), Bing Li(King Abdullah University of Science and Technology), Haozhe Liu(King Abdullah University of Science and Technology), Yawen Huang, Yefeng Zheng,Jürgen Schmidhuber(King Abdullah University of Science and Technology), Bernard Ghanem(King Abdullah University of Science and Technology), Linlin Shen(Shenzhen University), Mike Zheng Shou(National University of Singapore)

大型视觉语言模型(如CLIP)的视觉提示展示了有趣的零样本能力。常用于突出显示的手绘红圈可以引导CLIP的注意力到周围区域,以识别图像中的特定对象。然而,缺乏精确的对象提议,这种方法对于定位来说是不足够的。我们提出了一种新颖、简单而有效的方法,使CLIP能够进行零样本定位:给定一张图像和描述对象的文本提示,我们首先通过视觉提示从图像网格上均匀分布的锚点椭圆中选择一个初始椭圆,然后使用三个损失函数逐渐调整椭圆系数以包围目标区域。这为没有精确指定对象提议的指代表达理解提供了有希望的实验结果。此外,我们系统地介绍了CLIP中视觉提示固有的局限性,并讨论了改进的潜在途径。
17
多任务密集预测
Going Beyond Multi-Task Dense Prediction with Synergy Embedding Models
Huimin Huang (Zhejiang University), Yawen Huang, Lanfen Lin (Zhejiang University),Tong Ruofeng (Zhejiang University), Yen-wei Chen (Ritsumeikan University),Hao Zheng, Yuexiang Li (Guangxi Medical University), Yefeng Zheng

多任务视觉场景理解旨在利用一组相关任务之间的关系,通过将它们嵌入到一个统一的网络中来同时解决这些任务,以实现像素级预测。然而,大多数现有方法从任务层面上引发了两个主要问题:(1)不同任务缺乏任务独立的对应关系;(2)忽视了各种任务之间明确的共识依赖性。为了解决这些问题,我们提出了一种新颖的协同嵌入模型(SEM),它通过利用两种创新设计超越了多任务密集预测:任务内部的层级适应模块和任务间的EM交互模块。具体来说,构建的任务内部模块从多个阶段整合了层级适应的关键因素,使得能够以最佳的权衡高效学习专门的视觉模式。此外,开发的任务间模块从各种任务之间的紧凑共同基础中学习交互作用,受益于期望最大化(EM)算法。来自两个公共基准测试NYUD-v2和PASCAL-Context的广泛实证证据表明,SEM在一系列指标上始终优于最先进的方法。
18
全病理图像的癌症亚型分类
ViLa-MIL: Dual-scale Vision-Language Multiple Instance Learning for Whole Slide Image Classification
Jiangbo Shi (Xi'an Jiaotong University), Chen Li (Xi'an Jiaotong University), Tieliang Gong (Xi'an Jiaotong University), Yefeng Zheng, Huazhu Fu (A*STAR of Singapore)

基于多实例学习(Multiple Instance Learning, MIL)的框架已经成为处理数字病理学中具有千兆像素大小和层次化图像上下文的全幅图像(Whole Slide Image, WSI)的主流方法。然而,这些方法严重依赖于大量的包级别标签,并且仅从原始图片中学习,这很容易受到数据分布变化的影响。最近,基于视觉语言模型(Vision Language Model, VLM)的方法通过在大规模病理图像-文本对上进行预训练,引入语言先验。然而,之前的文本提示(Text Prompt)缺乏对病理先验知识的考虑,因此并未实质性地提升模型的性能。此外,这种图文对的收集和预训练过程非常耗时,消耗大量算力资源。为了解决上述问题,我们提出了一个双尺度视觉-语言多实例学习(ViLa-MIL)框架,用于全幅病理图像分类。具体来说,我们提出了一个基于冻结的大型语言模型(Large Language Model, LLM)的双尺度视觉描述性文本提示,以有效地提升VLM的性能。为了让VLM有效地处理WSI,对于图像分支,我们提出了一个原型(prototype)引导的图像块(patch)解码器,通过将相似的图像块分组到同一原型中,逐步聚合图像块特征;对于文本分支,我们引入了一个上下文引导的文本解码器,通过整合多粒度图像上下文来增强文本特征。在三个多癌种、多中心癌症亚型分类数据集上的广泛研究证明了ViLa-MIL的优越性。
19
SuperSVG:基于超像素的图像矢量化模型
SuperSVG: Superpixel-based Scalable Vector Graphics Synthesis
Teng Hu(Shanghai Jiao Tong University), Ran Yi(Shanghai Jiao Tong University), Baihong Qian(Shanghai Jiao Tong University), Jiangning Zhang, Paul L Rosin(Cardiff University), Yu-Kun Lai(Cardiff University)

SVG(可缩放矢量图形)是一种广泛使用的图形格式,具有出色的可扩展性和可编辑性。图像矢量化的目标是将栅格图像转换为SVG,这在计算机视觉和图形学中是一个重要但具有挑战性的问题。现有的图像矢量化方法要么在复杂图像的重建精度上表现不佳,要么需要长时间的计算。为了解决这个问题,我们提出了SuperSVG,一种基于超像素的矢量化模型,实现了快速和高精度的图像矢量化。具体来说,我们将输入图像分解为超像素,以帮助模型关注颜色和纹理相似的区域。然后,我们提出了一个两阶段的自我训练框架,其中粗阶段模型用于重建主要结构,而细化阶段模型用于丰富细节。此外,我们提出了一种新颖的动态路径扭曲损失,以帮助细化阶段模型从粗阶段模型中继承知识。大量的定性和定量实验表明,我们的方法在重建精度和推理时间方面相比于最先进的方法表现优越。
20
为通用三维大规模感知构建强预训练基线
Building a Strong Pre-Training Baseline for Universal 3D Large-Scale Perception
Haoming Chen(ECNU), Zhizhong Zhang(ECNU), Yanyun Qu(XMU), Ruixin Zhang, Xin Tan(ECNU), Yuan Xie(ECNU)
* 本文由华东师范大学、厦门大学、腾讯优图实验室共同完成
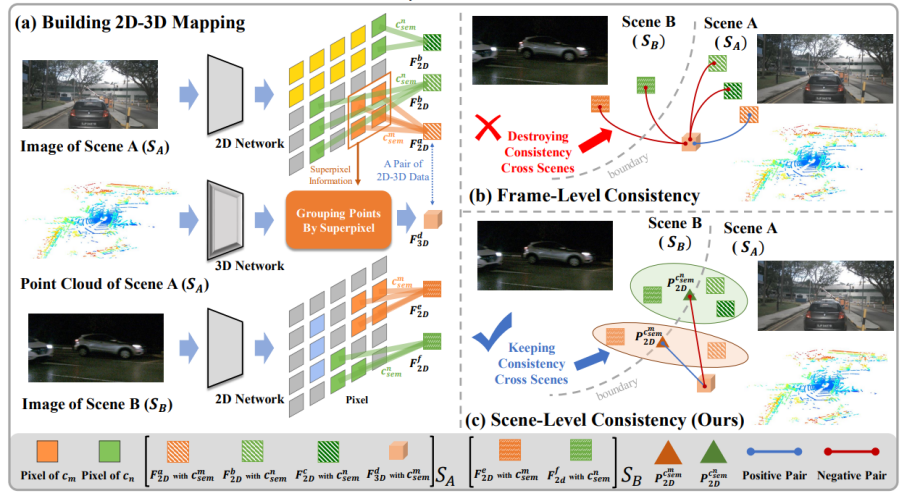
在感知大规模动态场景时,需要一个具有通用 3D 表示的有效预训练框架。然而当前的对比3D预训练方法通常遵循帧级一致性,重点关注每个分离图像中的 2D-3D 关系,没有考虑以下挑战(1)跨场景语义自冲突,即来自不同场景的相同语义的原始片段之间的强烈冲突;(2)缺乏将跨场景语义一致性推向3D表示学习的全局统一纽带。为了解决上述挑战,我们提出了一个CSC框架,该框架将场景级语义一致性放在核心位置,桥接不同场景中相似语义片段的连接。为了实现这一目标,我们结合了视觉基础模型提供的连贯语义线索和从互补的多模态信息派生的知识丰富的跨场景原型。 这些使我们能够训练通用的 3D 预训练模型,以更少的微调工作来促进各种下游任务。我们在语义分割、对象检测和全景分割均实现了对SOTA的改进。