Pandas 2.2 中文官方教程和指南(一)
Pandas 2.2 中文官方教程和指南(一)

安装
安装 pandas 的最简单方法是作为Anaconda发行版的一部分安装,这是一个用于数据分析和科学计算的跨平台发行版。Conda包管理器是大多数用户推荐的安装方法。
还提供了从源代码安装(#install-source)、从 PyPI 安装(#install-pypi)或安装开发版本(#install-dev)的说明。
Python 版本支持
官方支持 Python 3.9、3.10、3.11 和 3.12。
安装 pandas
使用 Anaconda 安装
对于新手用户,安装 Python、pandas 和构成PyData堆栈(SciPy、NumPy、Matplotlib等)的包的最简单方法是使用Anaconda,这是一个跨平台(Linux、macOS、Windows)的 Python 发行版,用于数据分析和科学计算。Anaconda 的安装说明在这里。 ### 使用 Miniconda 安装
对于有经验的 Python 用户,推荐使用Miniconda安装 pandas。Miniconda 允许您创建一个相对于 Anaconda 更小、独立的 Python 安装,并使用Conda包管理器安装其他包并为您的安装创建虚拟环境。Miniconda 的安装说明在这里。
下一步是创建一个新的 conda 环境。conda 环境类似于一个允许您指定特定版本的 Python 和一组库的虚拟环境。从终端窗口运行以下命令。
conda create -c conda-forge -n name_of_my_env python pandas 这将创建一个仅安装了 Python 和 pandas 的最小环境。要进入这个环境,请运行。
source activate name_of_my_env
# On Windows
activate name_of_my_env
```### 从 PyPI 安装
可以通过 pip 从[PyPI](https://pypi.org/project/pandas)安装 pandas。
```py
pip install pandas 注意
您必须拥有pip>=19.3才能从 PyPI 安装。
注意
建议从虚拟环境中安装和运行 pandas,例如,使用 Python 标准库的venv
pandas 也可以安装带有可选依赖项集以启用某些功能。例如,要安装带有读取 Excel 文件的可选依赖项的 pandas。
pip install "pandas[excel]" 可以在依赖部分找到可以安装的全部额外功能列表。
处理 ImportError
如果遇到 ImportError,通常意味着 Python 在可用库列表中找不到 pandas。Python 内部有一个目录列表,用于查找软件包。您可以通过以下方式获取这些目录。
import sys
sys.path 您可能遇到此错误的一种方法是,如果您的系统上安装了多个 Python,并且您当前使用的 Python 安装中没有安装 pandas,则可能会遇到此错误。在 Linux/Mac 上,您可以在终端上运行 which python,它将告诉您当前正在使用哪个 Python 安装。如果是类似“/usr/bin/python”的东西,则表示您正在使用系统中的 Python,这是不推荐的。
强烈建议使用 conda,以便快速安装和更新软件包和依赖项。您可以在此文档中找到有关 pandas 的简单安装说明。
从源代码安装
请参阅贡献指南以获取有关从 git 源代码树构建的完整说明。此外,如果您希望创建 pandas 开发环境,请参阅创建开发环境。 ### 安装 pandas 的开发版本
安装开发版本是最快的方法:
- 尝试一个新功能,该功能将在下一个发布中发布(即,从最近合并到主分支的拉取请求中提取的功能)。
- 检查您遇到的错误是否在上次发布之后修复。
开发版本通常每天上传到 anaconda.org 的 PyPI 注册表的 scientific-python-nightly-wheels 索引中。您可以通过运行以下命令进行安装。
pip install --pre --extra-index https://pypi.anaconda.org/scientific-python-nightly-wheels/simple pandas 请注意,您可能需要卸载现有版本的 pandas 才能安装开发版本。
pip uninstall pandas -y 运行测试套件
pandas 配备有一套详尽的单元测试。运行测试所需的软件包可以使用 pip install "pandas[test]" 进行安装。要从 Python 终端运行测试。
>>> import pandas as pd
>>> pd.test()
running: pytest -m "not slow and not network and not db" /home/user/anaconda3/lib/python3.9/site-packages/pandas
============================= test session starts ==============================
platform linux -- Python 3.9.7, pytest-6.2.5, py-1.11.0, pluggy-1.0.0
rootdir: /home/user
plugins: dash-1.19.0, anyio-3.5.0, hypothesis-6.29.3
collected 154975 items / 4 skipped / 154971 selected
........................................................................ [ 0%]
........................................................................ [ 99%]
....................................... [100%]
==================================== ERRORS ====================================
=================================== FAILURES ===================================
=============================== warnings summary ===============================
=========================== short test summary info ============================
= 1 failed, 146194 passed, 7402 skipped, 1367 xfailed, 5 xpassed, 197 warnings, 10 errors in 1090.16s (0:18:10) = 注意
这只是显示的信息示例。测试失败并不一定表示 pandas 安装有问题。
依赖项
必需的依赖项
pandas 需要以下依赖项。
软件包 | 最低支持版本 |
|---|---|
NumPy | 1.22.4 |
python-dateutil | 2.8.2 |
pytz | 2020.1 |
| tzdata | 2022.7 | ### 可选依赖项
pandas 有许多可选依赖项,仅用于特定方法。例如,pandas.read_hdf() 需要 pytables 包,而 DataFrame.to_markdown() 需要 tabulate 包。如果未安装可选依赖项,则在调用需要该依赖项的方法时,pandas 将引发 ImportError。
如果使用 pip,可选的 pandas 依赖项可以作为可选额外项(例如 pandas[performance, aws])安装或在文件中管理(例如 requirements.txt 或 pyproject.toml)。所有可选依赖项都可以通过 pandas[all] 安装,特定的依赖项集在下面的各节中列出。
性能依赖项(推荐)
注意
鼓励您安装这些库,因为它们提供了速度改进,特别是在处理大型数据集时。
可通过 pip install "pandas[performance]" 进行安装。
依赖项 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
numexpr | 2.8.4 | 性能 | 通过使用多个核心以及智能分块和缓存来加速某些数值运算 |
bottleneck | 1.3.6 | 性能 | 通过使用专门的 cython 程序加速某些类型的 nan,从而实现大幅加速。 |
numba | 0.56.4 | 性能 | 用??接受 engine="numba" 的操作的替代执行引擎,使用 JIT 编译器将 Python 函数转换为优化的机器代码,使用 LLVM 编译器实现大幅优化。 |
可视化
可通过 pip install "pandas[plot, output-formatting]" 进行安装。
依赖项 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
matplotlib | 3.6.3 | 绘图 | 绘图库 |
Jinja2 | 3.1.2 | 输出格式化 | 与 DataFrame.style 一起使用的条件格式化 |
tabulate | 0.9.0 | 输出格式化 | 以 Markdown 友好的格式打印(参见 tabulate) |
计算
可通过 pip install "pandas[computation]" 进行安装。
依赖项 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
SciPy | 1.10.0 | 计算 | 各种统计函数 |
xarray | 2022.12.0 | 计算 | 用于 N 维数据的类似于 pandas 的 API |
Excel 文件
可通过 pip install "pandas[excel]" 进行安装。
依赖项 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
xlrd | 2.0.1 | excel | 读取 Excel |
xlsxwriter | 3.0.5 | excel | 写入 Excel |
openpyxl | 3.1.0 | excel | 读取/写入 xlsx 文件 |
pyxlsb | 1.0.10 | excel | 读取 xlsb 文件 |
python-calamine | 0.1.7 | excel | 读取 xls/xlsx/xlsb/ods 文件 |
HTML
可通过 pip install "pandas[html]" 进行安装。
依赖 | 最低版本 | pip 额外组件 | 注释 |
|---|---|---|---|
BeautifulSoup4 | 4.11.2 | html | 用于 read_html 的 HTML 解析器 |
html5lib | 1.1 | html | 用于 read_html 的 HTML 解析器 |
lxml | 4.9.2 | html | 用于 read_html 的 HTML 解析器 |
使用顶层 read_html() 函数,需要以下库组合之一:
- BeautifulSoup4 和 html5lib
- BeautifulSoup4 和 lxml
- BeautifulSoup4 和 html5lib 和 lxml
- 只需要 lxml,尽管请查看 HTML 表解析 了解为什么你可能 不 应该采用这种方法。
警告
- 如果你安装了 BeautifulSoup4,你必须安装 lxml 或者 html5lib,或者两者都安装。只有安装了 BeautifulSoup4,
read_html()才会 不 起作用。 - 强烈建议阅读 HTML 表解析陷阱。它解释了上述三个库的安装和使用相关问题。
XML
通过 pip install "pandas[xml]" 安装。
依赖 | 最低版本 | pip 额外组件 | 注释 |
|---|---|---|---|
lxml | 4.9.2 | xml | read_xml 的 XML 解析器和 to_xml 的树生成器 |
SQL 数据库
传统驱动可以通过 pip install "pandas[postgresql, mysql, sql-other]" 安装。
依赖 | 最低版本 | pip 额外组件 | 注释 |
|---|---|---|---|
SQLAlchemy | 2.0.0 | postgresql, mysql, sql-other | 除 sqlite 外其他数据库的 SQL 支持 |
psycopg2 | 2.9.6 | postgresql | 用于 sqlalchemy 的 PostgreSQL 引擎 |
pymysql | 1.0.2 | mysql | 用于 sqlalchemy 的 MySQL 引擎 |
adbc-driver-postgresql | 0.8.0 | postgresql | PostgreSQL 的 ADBC 驱动程序 |
adbc-driver-sqlite | 0.8.0 | sql-other | SQLite 的 ADBC 驱动程序 |
其他数据源
通过 pip install "pandas[hdf5, parquet, feather, spss, excel]" 安装。
依赖 | 最低版本 | pip 额外组件 | 注释 |
|---|---|---|---|
PyTables | 3.8.0 | hdf5 | 基于 HDF5 的读取 / 写入 |
blosc | 1.21.3 | hdf5 | HDF5 压缩;仅适用于 conda |
zlib | hdf5 | HDF5 压缩 | |
fastparquet | 2022.12.0 | Parquet 读取 / 写入(pyarrow 是默认) | |
pyarrow | 10.0.1 | parquet, feather | Parquet、ORC 和 feather 读取 / 写入 |
pyreadstat | 1.2.0 | spss | SPSS 文件(.sav)读取 |
odfpy | 1.4.1 | excel | Open document format (.odf, .ods, .odt) 读取 / 写入 |
警告
- 如果你想使用
read_orc(),强烈建议使用 conda 安装 pyarrow。如果 pyarrow 是从 pypi 安装的,可能会导致read_orc()失败,并且read_orc()与 Windows 操作系统不兼容。
访问云端数据
使用 pip install "pandas[fss, aws, gcp]" 可安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
fsspec | 2022.11.0 | fss, gcp, aws | 处理除简单本地和 HTTP 外的文件(s3fs、gcsfs 的必需依赖)。 |
gcsfs | 2022.11.0 | gcp | 谷歌云存储访问 |
pandas-gbq | 0.19.0 | gcp | 谷歌大数据查询访问 |
s3fs | 2022.11.0 | aws | 亚马逊 S3 访问 |
剪贴板
使用 pip install "pandas[clipboard]" 可安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
PyQt4/PyQt5 | 5.15.9 | clipboard | 剪贴板 I/O |
qtpy | 2.3.0 | clipboard | 剪贴板 I/O |
注意
根据操作系统的不同,可能需要安装系统级软件包。在 Linux 上,要使剪贴板正常工作,必须安装其中一个命令行工具 xclip 或 xsel。
压缩
使用 pip install "pandas[compression]" 可安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
Zstandard | 0.19.0 | compression | Zstandard 压缩 |
联盟标准
使用 pip install "pandas[consortium-standard]" 可安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|
| dataframe-api-compat | 0.1.7 | consortium-standard | 基于 pandas 的联盟标准兼容实现 | ## Python 版本支持
官方支持 Python 3.9、3.10、3.11 和 3.12。
安装 pandas
使用 Anaconda 安装
对于新手用户,安装 Python、pandas 以及构成 PyData 栈(SciPy、NumPy、Matplotlib 等)的软件包最简单的方法是使用 Anaconda,这是一个跨平台(Linux、macOS、Windows)的数据分析和科学计算 Python 发行版。Anaconda 的安装说明 可在此找到。 ### 使用 Miniconda 安装
对于有 Python 经验的用户,推荐使用Miniconda安装 pandas。Miniconda 允许您创建一个最小的、独立的 Python 安装,与 Anaconda 相比,并使用Conda包管理器安装其他包并为您的安装创建虚拟环境。有关 Miniconda 的安装说明可以在这里找到。
下一步是创建一个新的 conda 环境。conda 环境类似于一个允许您指定特定 Python 版本和一组库的虚拟环境。从终端窗口运行以下命令。
conda create -c conda-forge -n name_of_my_env python pandas 这将创建一个只安装了 Python 和 pandas 的最小环境。要进入此环境,请运行。
source activate name_of_my_env
# On Windows
activate name_of_my_env
```### 从 PyPI 安装
可以通过 pip 从[PyPI](https://pypi.org/project/pandas)安装 pandas。
```py
pip install pandas 注意
您必须拥有pip>=19.3才能从 PyPI 安装。
注意
建议安装并从虚拟环境中运行 pandas,例如,使用 Python 标准库的venv。
pandas 也可以安装一组可选依赖项,以启用某些功能。例如,要安装带有可选依赖项以读取 Excel 文件的 pandas。
pip install "pandas[excel]" 可以在依赖部分找到可以安装的全部额外内容列表。
处理 ImportErrors
如果遇到ImportError,通常意味着 Python 在可用库列表中找不到 pandas。Python 内部有一个目录列表,用于查找包。您可以通过以下方式获取这些目录。
import sys
sys.path 您可能遇到此错误的一种方式是,如果您的系统上有多个 Python 安装,并且您当前使用的 Python 安装中没有安装 pandas。在 Linux/Mac 上,您可以在终端上运行which python,它会告诉您正在使用哪个 Python 安装。如果类似于“/usr/bin/python”,则您正在使用系统中的 Python,这是不推荐的。
强烈建议使用conda进行快速安装和包和依赖项更新。您可以在此文档中找到有关 pandas 的简单安装说明。
从源代码安装
请查看贡献指南以获取有关从 git 源代码树构建的完整说明。此外,如果您希望创建 pandas 开发环境,请查看创建开发环境。 ### 安装 pandas 的开发版本
安装开发版本是最快的方法:
- 尝试一个将在下一个发布中提供的新功能(即,最近合并到主分支的拉取请求中的功能)。
- 检查您遇到的错误是否在上一个版本中已修复。
开发版本通常每天上传到 anaconda.org 的 PyPI 注册表的 scientific-python-nightly-wheels 索引中。您可以通过运行来安装它。
pip install --pre --extra-index https://pypi.anaconda.org/scientific-python-nightly-wheels/simple pandas 请注意,您可能需要卸载现有版本的 pandas 才能安装开发版本。
pip uninstall pandas -y
```### 使用 Anaconda 安装
对于新手用户,安装 Python、pandas 和构成[PyData](https://pydata.org/)堆栈([SciPy](https://scipy.org/)、[NumPy](https://numpy.org/)、[Matplotlib](https://matplotlib.org/)等)的包最简单的方法是使用[Anaconda](https://docs.continuum.io/free/anaconda/),这是一个跨平台(Linux、macOS、Windows)的用于数据分析和科学计算的 Python 发行版。有关 Anaconda 的安装说明[请参见此处](https://docs.continuum.io/free/anaconda/install/)。
### 使用 Miniconda 安装
对于有 Python 经验的用户,推荐使用[Miniconda](https://docs.conda.io/en/latest/miniconda.html)安装 pandas。Miniconda 允许您创建一个最小、独立的 Python 安装,与 Anaconda 相比,使用[Conda](https://conda.io/en/latest/)包管理器安装额外的包并为您的安装创建虚拟环境。有关 Miniconda 的安装说明[请参见此处](https://docs.conda.io/en/latest/miniconda.html)。
下一步是创建一个新的 conda 环境。conda 环境类似于一个允许您指定特定 Python 版本和一组库的虚拟环境。从终端窗口运行以下命令。
```py
conda create -c conda-forge -n name_of_my_env python pandas 这将创建一个只安装了 Python 和 pandas 的最小环境。要进入此环境,请运行。
source activate name_of_my_env
# On Windows
activate name_of_my_env 从 PyPI 安装
可以通过pip从 PyPI 安装 pandas。
pip install pandas 注意
您必须拥有pip>=19.3才能从 PyPI 安装。
注意
建议在虚拟环境中安装和运行 pandas,例如,使用 Python 标准库的venv。
pandas 也可以安装带有可选依赖项集合以启用某些功能。例如,要安装带有可选依赖项以读取 Excel 文件的 pandas。
pip install "pandas[excel]" 可以在依赖部分找到可以安装的全部额外功能列表。
处理 ImportErrors
如果遇到ImportError,通常意味着 Python 在可用库列表中找不到 pandas。Python 内部有一个目录列表,用于查找包。您可以通过以下方式获取这些目录。
import sys
sys.path 您可能遇到此错误的一种方式是,如果您的系统上有多个 Python 安装,并且您当前使用的 Python 安装中没有安装 pandas。在 Linux/Mac 上,您可以在终端上运行which python,它会告诉您当前使用的 Python 安装。如果显示类似“/usr/bin/python”的内容,则表示您正在使用系统中的 Python,这是不推荐的。
强烈建议使用conda,以快速安装和更新包和依赖项。您可以在此文档中找到 pandas 的简单安装说明。
从源代码安装
查看贡献指南以获取有关从 git 源代码树构建的完整说明。此外,如果您希望创建一个 pandas 开发环境,请查看创建开发环境。
安装 pandas 的开发版本
安装开发版本是最快的方式:
- 尝试一个将在下一个版本中发布的新功能(即,最近合并到主分支的拉取请求中的功能)。
- 检查您遇到的错误是否自上次发布以来已修复。
开发版本通常每天上传到 anaconda.org 的 PyPI 注册表的 scientific-python-nightly-wheels 索引中。您可以通过运行以下命令来安装。
pip install --pre --extra-index https://pypi.anaconda.org/scientific-python-nightly-wheels/simple pandas 请注意,您可能需要卸载现有版本的 pandas 才能安装开发版本。
pip uninstall pandas -y 运行测试套件
pandas 配备了一套详尽的单元测试。运行测试所需的包可以通过pip install "pandas[test]"安装。要从 Python 终端运行测试。
>>> import pandas as pd
>>> pd.test()
running: pytest -m "not slow and not network and not db" /home/user/anaconda3/lib/python3.9/site-packages/pandas
============================= test session starts ==============================
platform linux -- Python 3.9.7, pytest-6.2.5, py-1.11.0, pluggy-1.0.0
rootdir: /home/user
plugins: dash-1.19.0, anyio-3.5.0, hypothesis-6.29.3
collected 154975 items / 4 skipped / 154971 selected
........................................................................ [ 0%]
........................................................................ [ 99%]
....................................... [100%]
==================================== ERRORS ====================================
=================================== FAILURES ===================================
=============================== warnings summary ===============================
=========================== short test summary info ============================
= 1 failed, 146194 passed, 7402 skipped, 1367 xfailed, 5 xpassed, 197 warnings, 10 errors in 1090.16s (0:18:10) = 注意
这只是显示的信息示例。测试失败并不一定表示 pandas 安装有问题。
依赖关系
必需依赖
pandas 需要以下依赖项。
包 | 最低支持版本 |
|---|---|
NumPy | 1.22.4 |
python-dateutil | 2.8.2 |
pytz | 2020.1 |
| tzdata | 2022.7 | ### 可选依赖
pandas 有许多可选依赖项,仅用于特定方法。例如,pandas.read_hdf()需要pytables包,而DataFrame.to_markdown()需要tabulate包。如果未安装可选依赖项,则在调用需要该依赖项的方法时,pandas 将引发ImportError。
如果使用 pip,可以将可选的 pandas 依赖项安装或管理到文件中(例如 requirements.txt 或 pyproject.toml),作为可选的额外功能(例如 pandas[performance, aws])。所有可选依赖项均可使用 pandas[all] 安装,具体的依赖项集合列在下面的各个部分中。
性能依赖项(推荐)
注意
强烈建议您安装这些库,因为它们提供了速度改进,特别是在处理大数据集时。
使用 pip install "pandas[performance]" 进行安装
依赖项 | 最低版本 | pip extra | 注释 |
|---|---|---|---|
numexpr | 2.8.4 | performance | 通过使用多个核心以及智能分块和缓存来加速某些数值运算。 |
bottleneck | 1.3.6 | performance | 通过使用专门的 cython 程序加速某些类型的 nan,以实现大幅加速。 |
numba | 0.56.4 | performance | 用于接受 engine="numba" 的操作的替代执行引擎,使用 JIT 编译器将 Python 函数转换为优化的机器码,使用 LLVM 编译器实现大幅度优化。 |
可视化
使用 pip install "pandas[plot, output-formatting]" 进行安装。
依赖项 | 最低版本 | pip extra | 注释 |
|---|---|---|---|
matplotlib | 3.6.3 | plot | 绘图库 |
Jinja2 | 3.1.2 | output-formatting | 使用 DataFrame.style 进行条件格式化 |
tabulate | 0.9.0 | output-formatting | 以 Markdown 友好的格式打印(参见 tabulate) |
计算
使用 pip install "pandas[computation]" 进行安装。
依赖项 | 最低版本 | pip extra | 注释 |
|---|---|---|---|
SciPy | 1.10.0 | computation | 杂项统计函数 |
xarray | 2022.12.0 | computation | 用于 N 维数据的类似 pandas API |
Excel 文件
使用 pip install "pandas[excel]" 进行安装。
依赖项 | 最低版本 | pip extra | 注释 |
|---|---|---|---|
xlrd | 2.0.1 | excel | 读取 Excel |
xlsxwriter | 3.0.5 | excel | 写入 Excel |
openpyxl | 3.1.0 | excel | 用于读取 / 写入 xlsx 文件 |
pyxlsb | 1.0.10 | excel | 用于读取 xlsb 文件 |
python-calamine | 0.1.7 | excel | 用于读取 xls/xlsx/xlsb/ods 文件 |
HTML
使用 pip install "pandas[html]" 进行安装。
依赖项 | 最低版本 | pip extra | 注释 |
|---|---|---|---|
BeautifulSoup4 | 4.11.2 | html | 用于 read_html 的 HTML 解析器 |
html5lib | 1.1 | html | 用于 read_html 的 HTML 解析器 |
lxml | 4.9.2 | html | 用于 read_html 的 HTML 解析器 |
若要使用顶层 read_html() 函数,需要以下其中一种组合的库:
- BeautifulSoup4 和 html5lib
- BeautifulSoup4 和 lxml
- BeautifulSoup4 和 html5lib 和 lxml
- 只有 lxml,尽管参阅 HTML 表格解析 可了解为什么您可能 不应该 采用这种方法。
警告
- 如果安装了 BeautifulSoup4,您必须安装 lxml 或 html5lib 或两者都安装。只安装 BeautifulSoup4 将 不会 使
read_html()正常工作。 - 强烈建议阅读 HTML 表格解析注意事项。它解释了关于上述三个库的安装和使用的问题。
XML
可通过 pip install "pandas[xml]" 进行安装。
依赖 | 最低版本 | pip extra | 注释 |
|---|---|---|---|
lxml | 4.9.2 | xml | 用于 read_xml 的 XML 解析器,用于 to_xml 的树构建器 |
SQL 数据库
传统驱动程序可通过 pip install "pandas[postgresql, mysql, sql-other]" 进行安装。
依赖 | 最低版本 | pip extra | 注释 |
|---|---|---|---|
SQLAlchemy | 2.0.0 | postgresql, mysql, sql-other | 除 sqlite 外的数据库的 SQL 支持 |
psycopg2 | 2.9.6 | postgresql | SQLAlchemy 的 PostgreSQL 引擎 |
pymysql | 1.0.2 | mysql | SQLAlchemy 的 MySQL 引擎 |
adbc-driver-postgresql | 0.8.0 | postgresql | 用于 PostgreSQL 的 ADBC 驱动程序 |
adbc-driver-sqlite | 0.8.0 | sql-other | 用于 SQLite 的 ADBC 驱动程序 |
其他数据源
可通过 pip install "pandas[hdf5, parquet, feather, spss, excel]" 进行安装。
依赖 | 最低版本 | pip extra | 注释 |
|---|---|---|---|
PyTables | 3.8.0 | hdf5 | 基于 HDF5 的读取/写入 |
blosc | 1.21.3 | hdf5 | HDF5 的压缩;仅在 conda 上可用 |
zlib | hdf5 | HDF5 的压缩 | |
fastparquet | 2022.12.0 | Parquet 的读取/写入(pyarrow 是默认值) | |
pyarrow | 10.0.1 | parquet, feather | Parquet、ORC 和 feather 的读取/写入 |
pyreadstat | 1.2.0 | spss | SPSS 文件(.sav)的读取 |
odfpy | 1.4.1 | excel | Open document format (.odf, .ods, .odt) 读取/写入 |
警告
- 如果您想使用
read_orc(),强烈建议使用 conda 安装 pyarrow。如果从 pypi 安装了 pyarrow,read_orc()可能会失败,并且read_orc()不兼容 Windows 操作系统。
访问云中的数据
可通过 pip install "pandas[fss, aws, gcp]" 进行安装。
依赖 | 最低版本 | pip extra | 注释 |
|---|---|---|---|
fsspec | 2022.11.0 | fss, gcp, aws | 处理除简单本地和 HTTP 之外的文件(s3fs、gcsfs 的必需依赖)。 |
gcsfs | 2022.11.0 | gcp | 谷歌云存储访问 |
pandas-gbq | 0.19.0 | gcp | 谷歌 Big Query 访问 |
s3fs | 2022.11.0 | aws | 亚马逊 S3 访问 |
剪贴板
可通过 pip install "pandas[clipboard]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
PyQt4/PyQt5 | 5.15.9 | clipboard | 剪贴板 I/O |
qtpy | 2.3.0 | clipboard | 剪贴板 I/O |
注意
根据操作系统的不同,可能需要安装系统级软件包。在 Linux 上,剪贴板要正常运行,系统必须安装 xclip 或 xsel 中的一个 CLI 工具。
压缩
可通过 pip install "pandas[compression]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
Zstandard | 0.19.0 | compression | Zstandard 压缩 |
联盟标准
可通过 pip install "pandas[consortium-standard]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|
| dataframe-api-compat | 0.1.7 | consortium-standard | 基于 pandas 的联盟标准兼容实现 | ### 必需依赖
pandas 需要以下依赖。
包 | 最低支持版本 |
|---|---|
NumPy | 1.22.4 |
python-dateutil | 2.8.2 |
pytz | 2020.1 |
tzdata | 2022.7 |
可选依赖
pandas 有许多仅用于特定方法的可选依赖。例如,pandas.read_hdf() 需要 pytables 包,而 DataFrame.to_markdown() 需要 tabulate 包。如果未安装可选依赖,当调用需要该依赖的方法时,pandas 将引发 ImportError。
如果使用 pip,可选的 pandas 依赖可以作为可选额外项(例如 pandas[performance, aws])安装或管理在文件中(例如 requirements.txt 或 pyproject.toml),所有可选依赖可以通过 pandas[all] 进行安装,特定的依赖集在下面的部分中列出。
性能依赖(推荐)
注意
强烈建议安装这些库,因为它们提供了速度改进,特别是在处理大数据集时。
可通过 pip install "pandas[performance]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
numexpr | 2.8.4 | performance | 通过使用多核心、智能分块和缓存来加速某些数值操作 |
bottleneck | 1.3.6 | performance | 通过使用专门的 cython 程序加速某些类型的 nan,实现大幅加速。 |
numba | 0.56.4 | performance | 用于接受 engine="numba" 的操作的替代执行引擎,使用 JIT 编译器将 Python 函数转换为优化的机器码,使用 LLVM 编译器。 |
可视化
可通过 pip install "pandas[plot, output-formatting]" 进行安装。
依赖 | 最低版本 | pip 额外 | 备注 |
|---|---|---|---|
matplotlib | 3.6.3 | plot | 绘图库 |
Jinja2 | 3.1.2 | output-formatting | 使用 DataFrame.style 进行条件格式化 |
tabulate | 0.9.0 | output-formatting | 以 Markdown 友好格式打印(参见 tabulate) |
计算
可通过 pip install "pandas[computation]" 进行安装。
依赖 | 最???版本 | pip 额外 | 备注 |
|---|---|---|---|
SciPy | 1.10.0 | computation | 各种统计函数 |
xarray | 2022.12.0 | computation | 用于 N 维数据的类似 pandas API |
Excel 文件
可通过 pip install "pandas[excel]" 进行安装。
依赖 | 最低版本 | pip 额外 | 备注 |
|---|---|---|---|
xlrd | 2.0.1 | excel | Excel 读取 |
xlsxwriter | 3.0.5 | excel | Excel 写入 |
openpyxl | 3.1.0 | excel | 用于 xlsx 文件的读取/写入 |
pyxlsb | 1.0.10 | excel | 用于 xlsb 文件的读取 |
python-calamine | 0.1.7 | excel | 用于 xls/xlsx/xlsb/ods 文件的读取 |
HTML
可通过 pip install "pandas[html]" 进行安装。
依赖 | 最低版本 | pip 额外 | 备注 |
|---|---|---|---|
BeautifulSoup4 | 4.11.2 | html | 用于 read_html 的 HTML 解析器 |
html5lib | 1.1 | html | 用于 read_html 的 HTML 解析器 |
lxml | 4.9.2 | html | 用于 read_html 的 HTML 解析器 |
使用顶层 read_html() 函数需要以下库中的一种或多种组合:
- BeautifulSoup4 和 html5lib
- BeautifulSoup4 和 lxml
- BeautifulSoup4 和 html5lib 和 lxml
- 仅 lxml,尽管请参阅 HTML 表格解析 了解为什么您可能应该 不要 采用这种方法。
警告
- 如果安装了 BeautifulSoup4,则必须安装 lxml 或 html5lib 或两者都安装。仅安装 BeautifulSoup4 不会 使
read_html()起作用。 - 强烈建议阅读 HTML Table Parsing gotchas。它解释了关于安装和使用上述三个库的问题。
XML
使用 pip install "pandas[xml]" 可以安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
lxml | 4.9.2 | xml | 用于 read_xml 的 XML 解析器和用于 to_xml 的树生成器 |
SQL 数据库
传统驱动程序可以使用 pip install "pandas[postgresql, mysql, sql-other]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
SQLAlchemy | 2.0.0 | postgresql, mysql, sql-other | 除了 sqlite 外其他数据库的 SQL 支持 |
psycopg2 | 2.9.6 | postgresql | SQLAlchemy 的 PostgreSQL 引擎 |
pymysql | 1.0.2 | mysql | SQLAlchemy 的 MySQL 引擎 |
adbc-driver-postgresql | 0.8.0 | postgresql | 用于 PostgreSQL 的 ADBC 驱动程序 |
adbc-driver-sqlite | 0.8.0 | sql-other | 用于 SQLite 的 ADBC 驱动程序 |
其他数据源
使用 pip install "pandas[hdf5, parquet, feather, spss, excel]" 可以安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
PyTables | 3.8.0 | hdf5 | 基于 HDF5 的读取 / 写入 |
blosc | 1.21.3 | hdf5 | HDF5 的压缩;仅在 conda 上可用 |
zlib | hdf5 | HDF5 的压缩 | |
fastparquet | 2022.12.0 | Parquet 的读取 / 写入(pyarrow 是默认的) | |
pyarrow | 10.0.1 | parquet, feather | Parquet、ORC 和 feather 的读取 / 写入 |
pyreadstat | 1.2.0 | spss | SPSS 文件(.sav)读取 |
odfpy | 1.4.1 | excel | 读取 / 写入开放文档格式(.odf、.ods、.odt) |
警告
- 如果您想要使用
read_orc(),强烈建议使用 conda 安装 pyarrow。如果使用 pypi 安装了 pyarrow,可能会导致read_orc()失败,并且read_orc()不兼容 Windows 操作系统。
云端数据访问
使用 pip install "pandas[fss, aws, gcp]" 可以安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
fsspec | 2022.11.0 | fss, gcp, aws | 处理除了简单本地和 HTTP 之外的文件(s3fs、gcsfs 的必需依赖) |
gcsfs | 2022.11.0 | gcp | 谷歌云存储访问 |
pandas-gbq | 0.19.0 | gcp | 谷歌大查询访问 |
s3fs | 2022.11.0 | aws | 亚马逊 S3 访问 |
剪贴板
使用 pip install "pandas[clipboard]" 可以安装。
依赖 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
PyQt4/PyQt5 | 5.15.9 | clipboard | 剪贴板 I/O |
qtpy | 2.3.0 | clipboard | 剪贴板 I/O |
注意
根据操作系统的不同,可能需要安装系统级包。在 Linux 上,要使剪贴板正常工作,您的系统必须安装其中一个 CLI 工具 xclip 或 xsel。
压缩
使用 pip install "pandas[compression]" 可以安装。
依赖 | 最低版本 | pip 额外 | 注意 |
|---|---|---|---|
Zstandard | 0.19.0 | 压缩 | Zstandard 压缩 |
联盟标准
可以使用 pip install "pandas[consortium-standard]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注意 |
|---|---|---|---|
dataframe-api-compat | 0.1.7 | 联盟标准 | 基于 pandas 的联盟标准兼容实现 |
性能依赖(推荐)
注:
强烈建议您安装这些库,因为它们可以提供速度改进,特别是在处理大型数据集时。
可以使用 pip install "pandas[performance]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注意 |
|---|---|---|---|
numexpr | 2.8.4 | 性能 | 通过使用多核心以及智能分块和缓存来加速某些数值操作,从而实现大幅加速 |
bottleneck | 1.3.6 | 性能 | 通过使用专门的 cython 程序例程来加速某些类型的 nan,从而实现大幅加速 |
numba | 0.56.4 | 性能 | 对于接受 engine="numba" 的操作,使用将 Python 函数转换为优化的机器代码的 JIT 编译器执行引擎。 |
可视化
可以使用 pip install "pandas[plot, output-formatting]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注意 |
|---|---|---|---|
matplotlib | 3.6.3 | 绘图 | 绘图库 |
Jinja2 | 3.1.2 | 输出格式化 | 使用 DataFrame.style 进行条件格式化 |
tabulate | 0.9.0 | 输出格式化 | 以 Markdown 友好格式打印(参见 tabulate) |
计算
可以使用 pip install "pandas[computation]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注意 |
|---|---|---|---|
SciPy | 1.10.0 | 计算 | 各种统计函数 |
xarray | 2022.12.0 | 计算 | 用于 N 维数据的类似 pandas 的 API |
Excel 文件
可以使用 pip install "pandas[excel]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注意 |
|---|---|---|---|
xlrd | 2.0.1 | excel | 读取 Excel |
xlsxwriter | 3.0.5 | excel | 写入 Excel |
openpyxl | 3.1.0 | excel | 用于 xlsx 文件的读取/写入 |
pyxlsb | 1.0.10 | excel | 读取 xlsb 文件 |
python-calamine | 0.1.7 | excel | 读取 xls/xlsx/xlsb/ods 文件 |
HTML
可以使用 pip install "pandas[html]" 进行安装。
依赖 | 最低版本 | pip 额外 | 注意 |
|---|---|---|---|
BeautifulSoup4 | 4.11.2 | html | 用于 read_html 的 HTML 解析器 |
html5lib | 1.1 | html | 用于 read_html 的 HTML 解析器 |
lxml | 4.9.2 | html | 用于 read_html 的 HTML 解析器 |
使用以下组合之一的库来使用顶层 read_html() 函数:
- BeautifulSoup4 和 html5lib
- BeautifulSoup4 和 lxml
- BeautifulSoup4 和 html5lib 和 lxml
- 只有 lxml,但是请参阅 HTML 表解析,了解为什么您可能 不 应采用这种方法。
警告
- 如果您安装了BeautifulSoup4,您必须安装lxml或者html5lib,或者两者都安装。只安装BeautifulSoup4 将无法使
read_html()工作。 - 非常鼓励阅读 HTML 表解析陷阱。它解释了围绕上述三个库的安装和使用的问题。
XML
可通过 pip install "pandas[xml]" 安装。
依赖项 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
lxml | 4.9.2 | xml | read_xml 的 XML 解析器和 to_xml 的树构建器 |
SQL 数据库
使用 pip install "pandas[postgresql, mysql, sql-other]" 可以安装传统驱动程序。
依赖项 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
SQLAlchemy | 2.0.0 | postgresql, mysql, sql-other | 除 SQLite 外的其他数据库的 SQL 支持 |
psycopg2 | 2.9.6 | postgresql | sqlalchemy 的 PostgreSQL 引擎 |
pymysql | 1.0.2 | mysql | sqlalchemy 的 MySQL 引擎 |
adbc-driver-postgresql | 0.8.0 | postgresql | PostgreSQL 的 ADBC 驱动程序 |
adbc-driver-sqlite | 0.8.0 | sql-other | SQLite 的 ADBC 驱动程序 |
其他数据源
使用 pip install "pandas[hdf5, parquet, feather, spss, excel]" 可以安装。
依赖项 | 最低版本 | pip 额外 | 注释 |
|---|---|---|---|
PyTables | 3.8.0 | hdf5 | 基于 HDF5 的读取/写入 |
blosc | 1.21.3 | hdf5 | HDF5 的压缩;只在 conda 上可用 |
zlib | hdf5 | HDF5 的压缩 | |
fastparquet | 2022.12.0 | Parquet 读取/写入(pyarrow 是默认的) | |
pyarrow | 10.0.1 | parquet, feather | Parquet、ORC 和 feather 读取/写入 |
pyreadstat | 1.2.0 | spss | SPSS 文件(.sav)读取 |
odfpy | 1.4.1 | excel | Open document format(.odf, .ods, .odt)读取/写入 |
警告
- 如果你想要使用
read_orc(),强烈建议使用 conda 安装 pyarrow。如果从 pypi 安装了 pyarrow,read_orc()可能会失败,并且read_orc()不兼容 Windows 操作系统。
访问云端数据
使用pip install "pandas[fss, aws, gcp]"进行安装。
依赖 | 最低版本 | pip 额外 | 备注 |
|---|---|---|---|
fsspec | 2022.11.0 | fss, gcp, aws | 处理除简单本地和 HTTP 之外的文件(s3fs、gcsfs 的必需依赖)。 |
gcsfs | 2022.11.0 | gcp | 谷歌云存储访问 |
pandas-gbq | 0.19.0 | gcp | 谷歌大查询访问 |
s3fs | 2022.11.0 | aws | 亚马逊 S3 访问 |
剪贴板
使用pip install "pandas[clipboard]"进行安装。
依赖 | 最低版本 | pip 额外 | 备注 |
|---|---|---|---|
PyQt4/PyQt5 | 5.15.9 | clipboard | 剪贴板 I/O |
qtpy | 2.3.0 | clipboard | 剪贴板 I/O |
注意
根据操作系统的不同,可能需要安装系统级软件包。在 Linux 上,剪贴板要操作,系统上必须安装xclip或xsel中的一个 CLI 工具。
压缩
使用pip install "pandas[compression]"进行安装。
依赖 | 最低版本 | pip 额外 | 备注 |
|---|---|---|---|
Zstandard | 0.19.0 | compression | Zstandard 压缩 |
联盟标准
使用pip install "pandas[consortium-standard]"进行安装。
依赖 | 最低版本 | pip 额外 | 备注 |
|---|---|---|---|
dataframe-api-compat | 0.1.7 | consortium-standard | 基于 pandas 的符合联盟标准的实现 |
包概述
pandas 是一个Python包,提供快速、灵活和表达性强的数据结构,旨在使处理“关系”或“标记”数据变得简单和直观。它旨在成为在 Python 中进行实际、现实世界数据分析的基本高级构建块。此外,它还有更广泛的目标,即成为任何语言中最强大和灵活的开源数据分析/操作工具。它已经在这个目标的道路上取得了很大进展。
pandas 非常适合许多不同类型的数据:
- 具有异构类型列的表格数据,如 SQL 表或 Excel 电子表格
- 有序和无序(不一定是固定频率)的时间序列数据
- 具有行和列标签的任意矩阵数据(同质或异质类型)
- 任何其他形式的观测/统计数据集。数据不需要被标记,也可以放入 pandas 数据结构中。
pandas 的两个主要数据结构,Series(1 维)和DataFrame(2 维),处理金融、统计学、社会科学和许多工程领域的绝大多数典型用例。对于 R 用户,DataFrame提供了 R 的data.frame提供的一切,以及更多。pandas 建立在NumPy之上,旨在与许多其他第三方库在科学计算环境中很好地集成。
以下是 pandas 擅长的一些事情:
- 处理浮点和非浮点数据中的缺失数据(表示为 NaN)非常容易
- 大小可变性:可以从 DataFrame 和更高维对象中插入和删除列
- 自动和显式的数据对齐:对象可以显式地与一组标签对齐,或者用户可以简单地忽略标签,让
Series、DataFrame等在计算中自动为您对齐数据 - 强大、灵活的分组功能,可以对数据集执行分割-应用-合并操作,用于聚合和转换数据
- 使将其他 Python 和 NumPy 数据结构中的不规则、具有不同索引的数据轻松转换为 DataFrame 对象变得容易
- 对大型数据集进行智能基于标签的切片、高级索引和子集操作
- 直观的合并和连接数据集
- 灵活的数据集重塑和透视
- 轴的分层标签(每个刻度可能有多个标签)
- 用于从平面文件(CSV 和分隔符)、Excel 文件、数据库加载数据以及从超快速HDF5 格式保存/加载数据的强大 IO 工具
- 时间序列特定功能:日期范围生成和频率转换,滑动窗口统计,日期移动和滞后。
这些原则中的许多都是为了解决在使用其他语言/科学研究环境时经常遇到的缺点。对于数据科学家来说,处理数据通常分为多个阶段:整理和清理数据,分析/建模,然后将分析结果组织成适合绘图或表格显示的形式。pandas 是所有这些任务的理想工具。
其他一些注意事项
- pandas 速度快。许多底层算法部分在Cython代码中已经得到了大量调整。但是,与其他任何事物一样,一般化通常会牺牲性能。因此,如果您专注于应用程序的某一特性,您可能能够创建一个更快的专业工具。
- pandas 是statsmodels的依赖项,使其成为 Python 统计计算生态系统中的重要部分。
- pandas 已在金融应用程序中广泛使用。
数据结构
维度 | 名称 | 描述 |
|---|---|---|
1 | Series | 一维标记同构类型数组 |
2 | DataFrame | 通用的二维标记、可变大小的表格结构,列的类型可能异构 |
为什么需要多个数据结构?
最好将 pandas 数据结构视为适用于低维数据的灵活容器。例如,DataFrame 是 Series 的容器,而 Series 是标量的容器。我们希望能够以类似字典的方式向这些容器中插入和删除对象。
另外,我们希望常见 API 函数的默认行为能够考虑到时间序列和横截面数据集的典型方向。当使用 N 维数组(ndarrays)存储二维和三维数据时,用户在编写函数时需要考虑数据集的方向;轴被认为是更或多或少等效的(除非 C- 或 Fortran-连续性对性能很重要)。在 pandas 中,轴旨在为数据提供更多的语义含义;即,对于特定的数据集,很可能有一种“正确”的方式来定位数据。因此,目标是减少编写下游函数中的数据转换所需的心理努力。
例如,对于表格数据(DataFrame),更有语义的方法是考虑索引(行)和列,而不是轴 0 和轴 1。因此,通过 DataFrame 的列进行迭代将产生更可读的代码:
for col in df.columns:
series = df[col]
# do something with series 数据的可变性和复制
所有 pandas 数据结构都是值可变的(它们包含的值可以被改变),但不总是大小可变的。Series 的长度不能改变,但是,例如,可以在 DataFrame 中插入列。然而,绝大多数方法会产生新对象并保持输入数据不变。通常情况下,我们喜欢偏向不可变性。
获取支持
pandas 问题和想法的第一站是GitHub Issue Tracker。如果您有一般问题,pandas 社区专家可以通过Stack Overflow回答。
社区
今天,pandas 得到全球志同道合的个人社区的积极支持,他们贡献了宝贵的时间和精力,帮助使开源 pandas 成为可能。感谢所有贡献者。
如果您有兴趣贡献,请访问贡献指南。
pandas 是NumFOCUS赞助的项目。这将有助于确保 pandas 作为世界一流开源项目的成功,并使捐赠给该项目成为可能。
项目治理
pandas 项目自 2008 年成立以来一直在非正式使用的治理流程在项目治理文件中得到了正式化。这些文件澄清了决策的方式以及我们社区的各个元素如何互动,包括开源协作开发与可能由营利性或非营利性实体资助的工作之间的关系。
Wes McKinney 是终身仁慈独裁者(BDFL)。
开发团队
核心团队成员列表和更详细信息可在pandas 网站上找到。
机构合作伙伴
关于当前机构合作伙伴的信息可在pandas 网站页面上找到。
许可证
BSD 3-Clause License
Copyright (c) 2008-2011, AQR Capital Management, LLC, Lambda Foundry, Inc. and PyData Development Team
All rights reserved.
Copyright (c) 2011-2023, Open source contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
* Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. 数据结构
维度 | 名称 | 描述 |
|---|---|---|
1 | Series | 1D 标记同质类型数组 |
2 | DataFrame | 通用的二维标记,大小可变的表格结构,列可能具有异构类型 |
为什么需要多个数据结构?
最好将 pandas 数据结构视为低维数据的灵活容器。例如,DataFrame 是 Series 的容器,而 Series 是标量的容器。我们希望能够以类似字典的方式插入和删除这些容器中的对象。
此外,我们希望常见 API 函数有合理的默认行为,考虑到时间序列和横截面数据集的典型方向。当使用 N 维数组(ndarrays)存储 2 维和 3 维数据时,用户需要考虑数据集的方向来编写函数;轴被认为是更或多或少等价的(除非 C 或 Fortran 连续性对性能有影响)。在 pandas 中,轴旨在为数据提供更多语义意义;即,对于特定数据集,可能有一种“正确”的方式来定位数据。因此,目标是减少编写下游函数中数据转换所需的心智努力量。
例如,对于表格数据(DataFrame),更有语义的方式是考虑索引(行)和列,而不是轴 0 和轴 1。因此,通过 DataFrame 的列进行迭代会导致更易读的代码:
for col in df.columns:
series = df[col]
# do something with series 为什么会有多个数据结构?
最好的方式是将 pandas 数据结构视为低维数据的灵活容器。例如,DataFrame 是 Series 的容器,而 Series 是标量的容器。我们希望能够以类似字典的方式向这些容器中插入和移除对象。
此外,我们希望常见 API 函数有合理的默认行为,考虑到时间序列和横截面数据集的典型方向。当使用 N 维数组(ndarrays)存储 2 维和 3 维数据时,用户需要考虑数据集的方向来编写函数;轴被认为是更或多或少等价的(除非 C 或 Fortran 连续性对性能有影响)。在 pandas 中,轴旨在为数据提供更多语义意义;即,对于特定数据集,可能有一种“正确”的方式来定位数据。因此,目标是减少编写下游函数中数据转换所需的心智努力量。
例如,对于表格数据(DataFrame),更有语义的方式是考虑索引(行)和列,而不是轴 0 和轴 1。因此,通过 DataFrame 的列进行迭代会导致更易读的代码:
for col in df.columns:
series = df[col]
# do something with series 可变性和数据的复制
所有的 pandas 数据结构都是值可变的(它们包含的值可以被改变),但并非总是大小可变的。Series 的长度不能被改变,但是,例如,可以在 DataFrame 中插入列。然而,绝大多数方法会产生新对象,并保持输入数据不变。一般来说,我们喜欢偏向不可变性,在合适的情况下。
获取支持
pandas 的问题和想法的第一站是GitHub Issue Tracker。如果您有一般问题,pandas 社区专家可以通过Stack Overflow回答。
社区
今天,pandas 受到全球志同道合的个人社区的积极支持,他们贡献了宝贵的时间和精力来帮助使开源 pandas 成为可能。感谢我们所有的贡献者。
如果您有兴趣贡献,请访问贡献指南。
pandas 是一个NumFOCUS赞助的项目。这将有助于确保 pandas 作为一个世界一流的开源项目的成功,并使捐赠给该项目成为可能。
项目治理
pandas 项目自 2008 年成立以来一直使用的治理流程已在项目治理文件中正式规范化。这些文件澄清了如何做出决策以及我们社区各个元素之间的互动方式,包括开源协作开发与可能由营利性或非营利性实体资助的工作之间的关系。
Wes McKinney 是终身仁慈独裁者(BDFL)。
开发团队
核心团队成员列表和更详细的信息可以在pandas 网站上找到。
机构合作伙伴
当前机构合作伙伴的信息可以在pandas 网站页面上找到。
许可证
BSD 3-Clause License
Copyright (c) 2008-2011, AQR Capital Management, LLC, Lambda Foundry, Inc. and PyData Development Team
All rights reserved.
Copyright (c) 2011-2023, Open source contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
* Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. 入门教程
原文:
pandas.pydata.org/docs/getting_started/intro_tutorials/index.html
- pandas 处理什么类型的数据?
- 如何读取和写入表格数据?
- 如何选择
DataFrame的子集? - 如何在 pandas 中创建图表?
- 如何从现有列派生新列
- 如何计算摘要统计信息
- 如何重新设计表格布局
- 如何合并来自多个表的数据
- 如何轻松处理时间序列数据
- 如何操作文本数据
pandas 处理什么类型的数据?
原文:
pandas.pydata.org/docs/getting_started/intro_tutorials/01_table_oriented.html
我想开始使用 pandas
In [1]: import pandas as pd 要加载 pandas 包并开始使用它,请导入该包。 社区约定的 pandas 别名是pd,因此假定将 pandas 加载为pd是所有 pandas 文档的标准做法。
pandas 数据表表示
我想存储泰坦尼克号的乘客数据。 对于许多乘客,我知道姓名(字符),年龄(整数)和性别(男/女)数据。
In [2]: df = pd.DataFrame(
...: {
...: "Name": [
...: "Braund, Mr. Owen Harris",
...: "Allen, Mr. William Henry",
...: "Bonnell, Miss. Elizabeth",
...: ],
...: "Age": [22, 35, 58],
...: "Sex": ["male", "male", "female"],
...: }
...: )
...:
In [3]: df
Out[3]:
Name Age Sex
0 Braund, Mr. Owen Harris 22 male
1 Allen, Mr. William Henry 35 male
2 Bonnell, Miss. Elizabeth 58 female 要手动将数据存储在表中,请创建一个DataFrame。 使用 Python 字典列表时,字典键将用作列标题,每个列表中的值将用作DataFrame的列。
一个DataFrame是一个可以在列中存储不同类型数据(包括字符、整数、浮点值、分类数据等)的二维数据结构。 它类似于电子表格、SQL 表或 R 中的data.frame。
- 表格有 3 列,每列都有一个列标签。 列标签分别是
Name、Age和Sex。 - 列
Name由文本数据组成,每个值都是一个字符串,列Age是数字,列Sex是文本数据。
在电子表格软件中,我们的数据的表格表示看起来会非常相似:
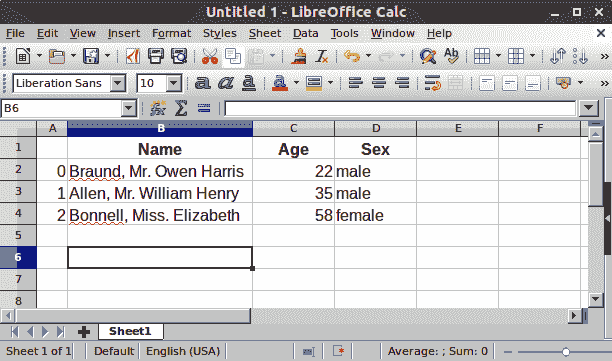
DataFrame中的每一列都是一个Series
我只对在Age列中的数据感兴趣
In [4]: df["Age"]
Out[4]:
0 22
1 35
2 58
Name: Age, dtype: int64 当选择 pandas DataFrame的单个列时,结果是一个 pandas Series。 要选择列,请在方括号[]之间使用列标签。
注意
如果您熟悉 Python dictionaries,选择单个列与基于键选择字典值非常相似。
你也可以从头开始创建一个Series:
In [5]: ages = pd.Series([22, 35, 58], name="Age")
In [6]: ages
Out[6]:
0 22
1 35
2 58
Name: Age, dtype: int64 pandas 的Series没有列标签,因为它只是DataFrame的单列。 Series 确实有行标签。
对 DataFrame 或 Series 执行某些操作
我想知道乘客的最大年龄
我们可以通过选择Age列并应用max()在DataFrame上执行此操作:
In [7]: df["Age"].max()
Out[7]: 58 或者到Series:
In [8]: ages.max()
Out[8]: 58 正如 max() 方法所示,您可以使用 DataFrame 或 Series 执行 操作。pandas 提供了许多功能,每个功能都是您可以应用于 DataFrame 或 Series 的 方法。由于方法是函数,不要忘记使用括号 ()。
我对我的数据表的数值数据进行一些基本统计感兴趣
In [9]: df.describe()
Out[9]:
Age
count 3.000000
mean 38.333333
std 18.230012
min 22.000000
25% 28.500000
50% 35.000000
75% 46.500000
max 58.000000 describe() 方法提供了对 DataFrame 中数值数据的快速概述。由于 Name 和 Sex 列是文本数据,默认情况下不会被 describe() 方法考虑在内。
许多 pandas 操作会返回一个 DataFrame 或一个 Series。describe() 方法就是一个返回 pandas Series 或 pandas DataFrame 的 pandas 操作的示例。
转至用户指南
在用户指南的关于 使用 describe 进行汇总的部分中查看更多选项
注意
这只是一个起点。与电子表格软件类似,pandas 将数据表示为具有列和行的表格。除了表示外,还有您在电子表格软件中进行的数据操作和计算,pandas 也支持。继续阅读下一篇教程,开始使用!
记住
- 导入包,即
import pandas as pd - 数据表以 pandas 的
DataFrame形式存储 -
DataFrame中的每一列都是一个Series - 您可以通过将方法应用于
DataFrame或Series来执行操作
转至用户指南
关于 DataFrame 和 Series 的更详细解释在数据结构简介中提供。
pandas 数据表表示
我想存储 Titanic 的乘客数据。对于许多乘客,我知道他们的姓名(字符)、年龄(整数)和性别(男性/女性)数据。
In [2]: df = pd.DataFrame(
...: {
...: "Name": [
...: "Braund, Mr. Owen Harris",
...: "Allen, Mr. William Henry",
...: "Bonnell, Miss. Elizabeth",
...: ],
...: "Age": [22, 35, 58],
...: "Sex": ["male", "male", "female"],
...: }
...: )
...:
In [3]: df
Out[3]:
Name Age Sex
0 Braund, Mr. Owen Harris 22 male
1 Allen, Mr. William Henry 35 male
2 Bonnell, Miss. Elizabeth 58 female 要手动存储数据到表格中,创建一个 DataFrame。当使用 Python 字典的列表时,字典的键将被用作列标题,每个列表中的值将作为 DataFrame 的列。
DataFrame 是一种二维数据结构,可以在列中存储不同类型的数据(包括字符、整数、浮点值、分类数据等)。它类似于电子表格、SQL 表或 R 中的 data.frame。
- 表格有 3 列,每列都有一个列标签。列标签分别是
Name、Age和Sex。 - 列
Name包含文本数据,每个值为字符串,列Age是数字,列Sex是文本数据。
在电子表格软件中,我们的数据的表格表示看起来会非常相似:
每个DataFrame中的列都是一个Series
我只对Age列中的数据感兴趣
In [4]: df["Age"]
Out[4]:
0 22
1 35
2 58
Name: Age, dtype: int64 当选择 pandas DataFrame的单个列时,结果是一个 pandas Series。要选择列,请在方括号[]之间使用列标签。
注意
如果你熟悉 Python dictionaries,选择单个列与基于键选择字典值非常相似。
你也可以从头开始创建一个Series:
In [5]: ages = pd.Series([22, 35, 58], name="Age")
In [6]: ages
Out[6]:
0 22
1 35
2 58
Name: Age, dtype: int64 一个 pandas Series没有列标签,因为它只是一个DataFrame的单列。一个 Series 有行标签。
对DataFrame或Series执行一些操作
我想知道乘客的最大年龄
我们可以通过选择Age列并应用max()来对DataFrame进行操作:
In [7]: df["Age"].max()
Out[7]: 58 或对Series进行操作:
In [8]: ages.max()
Out[8]: 58 正如max()方法所示,你可以对DataFrame或Series执行操作。pandas 提供了许多功能,每个功能都是可以应用于DataFrame或Series的方法。由于方法是函数,请不要忘记使用括号()。
我对我的数据表的数值数据感兴趣的一些基本统计信息
In [9]: df.describe()
Out[9]:
Age
count 3.000000
mean 38.333333
std 18.230012
min 22.000000
25% 28.500000
50% 35.000000
75% 46.500000
max 58.000000 describe()方法提供了DataFrame中数值数据的快速概述。由于Name和Sex列是文本数据,默认情况下不会被describe()方法考虑在内。
许多 pandas 操作会返回一个DataFrame或一个Series。describe()方法就是一个返回 pandas Series或 pandas DataFrame的 pandas 操作的示例。
转到用户指南
在用户??南的关于使用 describe 进行聚合部分查看更多关于describe的选项
注意
这只是一个起点。与电子表格软件类似,pandas 将数据表示为具有列和行的表格。除了表示,pandas 还支持电子表格软件中的数据操作和计算。继续阅读下一个教程以开始!
记住
- 导入包,即
import pandas as pd - 数据表以 pandas
DataFrame的形式存储 - 每个
DataFrame中的列都是一个Series - 你可以通过将方法应用于
DataFrame或Series来完成任务。
前往用户指南
关于 DataFrame 和 Series 的更详细解释可在数据结构介绍中找到。
如何读取和写入表格数据?
原文:
pandas.pydata.org/docs/getting_started/intro_tutorials/02_read_write.html
我想分析泰坦尼克号乘客数据,该数据以 CSV 文件的形式提供。
In [2]: titanic = pd.read_csv("data/titanic.csv") pandas 提供read_csv()函数,将存储为 csv 文件的数据读取到 pandas 的DataFrame中。pandas 支持许多不同的文件格式或数据源(csv、excel、sql、json、parquet 等),每个都带有前缀read_*。
在读取数据后,务必始终检查数据。显示DataFrame时,默认会显示前后 5 行:
In [3]: titanic
Out[3]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
.. ... ... ... ... ... ... ...
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
888 889 0 3 ... 23.4500 NaN S
889 890 1 1 ... 30.0000 C148 C
890 891 0 3 ... 7.7500 NaN Q
[891 rows x 12 columns] 我想看一下 pandas DataFrame 的前 8 行。
In [4]: titanic.head(8)
Out[4]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
6 7 0 1 ... 51.8625 E46 S
7 8 0 3 ... 21.0750 NaN S
[8 rows x 12 columns] 要查看DataFrame的前 N 行,请使用head()方法,并将所需的行数(在本例中为 8)作为参数。
注意
对最后 N 行感兴趣吗?pandas 还提供了tail()方法。例如,titanic.tail(10)将返回 DataFrame 的最后 10 行。
通过请求 pandas 的dtypes属性,可以检查 pandas 如何解释每列的数据类型:
In [5]: titanic.dtypes
Out[5]:
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object 对于每列,列出了使用的数据类型。此DataFrame中的数据类型为整数(int64)、浮点数(float64)和字符串(object)。
注意
请求dtypes时,不使用括号!dtypes是DataFrame和Series的属性。DataFrame或Series的属性不需要括号。属性表示DataFrame/Series的特征,而方法(需要括号)在第一个教程中介绍了DataFrame/Series的操作。
我的同事请求将泰坦尼克号数据作为电子表格。
In [6]: titanic.to_excel("titanic.xlsx", sheet_name="passengers", index=False) 而read_*函数用于将数据读取到 pandas 中,to_*方法用于存储数据。to_excel()方法将数据存储为 excel 文件。在此示例中,sheet_name命名为passengers,而不是默认的Sheet1。通过设置index=False,行索引标签不会保存在电子表格中。
等效的读取函数read_excel()将重新加载数据到DataFrame中:
In [7]: titanic = pd.read_excel("titanic.xlsx", sheet_name="passengers") In [8]: titanic.head()
Out[8]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns] 我对DataFrame的技术摘要感兴趣
In [9]: titanic.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB info()方法提供有关DataFrame的技术信息,让我们更详细地解释输出:
- 确实是一个
DataFrame。 - 有 891 个条目,即 891 行。
- 每行都有一个行标签(又称
index),其值范围从 0 到 890。 - 表格有 12 列。大多数列在每一行都有一个值(所有 891 个值都是
non-null)。一些列确实有缺失值,少于 891 个non-null值。 - 列
Name、Sex、Cabin和Embarked由文本数据(字符串,又称object)组成。其他列是数值数据,其中一些是整数(又称integer),另一些是实数(又称float)。 - 不同列中的数据类型(字符、整数等)通过列出
dtypes进行总结。 - 提供了用于保存 DataFrame 的大致 RAM 使用量。
记住
- 通过
read_*函数支持从许多不同文件格式或数据源将数据导入 pandas。 - 通过不同的
to_*方法提供了将数据导出到 pandas 的功能。 -
head/tail/info方法和dtypes属性对于初步检查很方便。
到用户指南
有关从 pandas 到输入和输出的完整概述,请参阅有关读取器和写入器函数的用户指南部分。
如何选择 DataFrame 的子集?
原文:
pandas.pydata.org/docs/getting_started/intro_tutorials/03_subset_data.html
如何从DataFrame中选择特定列?
我对泰坦尼克号乘客的年龄感兴趣。
In [4]: ages = titanic["Age"]
In [5]: ages.head()
Out[5]:
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
Name: Age, dtype: float64 要选择单个列,请使用方括号[]与感兴趣的列名。
每个DataFrame中的列都是一个Series。当选择单个列时,返回的对象是一个 pandas Series。我们可以通过检查输出的类型来验证这一点:
In [6]: type(titanic["Age"])
Out[6]: pandas.core.series.Series 并查看输出的shape:
In [7]: titanic["Age"].shape
Out[7]: (891,) DataFrame.shape 是一个属性(记住读写教程中不要对属性使用括号), 用于包含行数和列数的 pandas Series 和 DataFrame:(nrows, ncolumns)。pandas Series 是一维的,只返回行数。
我对泰坦尼克号乘客的年龄和性别感兴趣。
In [8]: age_sex = titanic[["Age", "Sex"]]
In [9]: age_sex.head()
Out[9]:
Age Sex
0 22.0 male
1 38.0 female
2 26.0 female
3 35.0 female
4 35.0 male 要选择多个列,请在选择括号[]内使用列名列表。
注意
内部方括号定义了一个Python 列表,其中包含列名,而外部方括号用于从 pandas DataFrame 中选择数据,就像在前面的示例中看到的那样。
返回的数据类型是一个 pandas DataFrame:
In [10]: type(titanic[["Age", "Sex"]])
Out[10]: pandas.core.frame.DataFrame In [11]: titanic[["Age", "Sex"]].shape
Out[11]: (891, 2) 选择返回了一个具有 891 行和 2 列的DataFrame。记住,DataFrame 是二维的,具有行和列两个维度。
转到用户指南
有关索引的基本信息,请参阅用户指南中关于索引和选择数据的部分。
如何从DataFrame中过滤特???行?
我对年龄大于 35 岁的乘客感兴趣。
In [12]: above_35 = titanic[titanic["Age"] > 35]
In [13]: above_35.head()
Out[13]:
PassengerId Survived Pclass ... Fare Cabin Embarked
1 2 1 1 ... 71.2833 C85 C
6 7 0 1 ... 51.8625 E46 S
11 12 1 1 ... 26.5500 C103 S
13 14 0 3 ... 31.2750 NaN S
15 16 1 2 ... 16.0000 NaN S
[5 rows x 12 columns] 要基于条件表达式选择行,请在选择括号[]内使用条件。
选择括号内的条件titanic["Age"] > 35检查Age列的值是否大于 35 的行:
In [14]: titanic["Age"] > 35
Out[14]:
0 False
1 True
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Age, Length: 891, dtype: bool 条件表达式的输出(>,但也可以是 ==,!=,<,<=,…)实际上是一个具有与原始DataFrame相同行数的布尔值(True 或 False)的 pandas Series。这样的布尔值Series可以通过将其放在选择括号[]之间来过滤DataFrame。只有值为True的行才会被选择。
我们之前知道原始泰坦尼克号DataFrame由 891 行组成。让我们通过检查结果DataFrame above_35的shape属性来查看满足条件的行数:
In [15]: above_35.shape
Out[15]: (217, 12) 我对泰坦尼克号的 2 和 3 舱位乘客感兴趣。
In [16]: class_23 = titanic[titanic["Pclass"].isin([2, 3])]
In [17]: class_23.head()
Out[17]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
2 3 1 3 ... 7.9250 NaN S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
7 8 0 3 ... 21.0750 NaN S
[5 rows x 12 columns] 与条件表达式类似,isin() 条件函数会对提供的列表中的每一行返回True。要基于这样的函数过滤行,请在选择括号[]内使用条件函数。在这种情况下,选择括号内的条件titanic["Pclass"].isin([2, 3])检查Pclass列为 2 或 3 的行。
上述操作等同于按照舱位为 2 或 3 的行进行筛选,并使用|(或)运算符将两个语句组合在一起:
In [18]: class_23 = titanic[(titanic["Pclass"] == 2) | (titanic["Pclass"] == 3)]
In [19]: class_23.head()
Out[19]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
2 3 1 3 ... 7.9250 NaN S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
7 8 0 3 ... 21.0750 NaN S
[5 rows x 12 columns] 注意
在组合多个条件语句时,每个条件必须用括号()括起来。此外,不能使用or/and,而是需要使用or运算符|和and运算符&。
到用户指南
请查看用户指南中关于布尔索引或 isin 函数的专门部分。
我想处理已知年龄的乘客数据。
In [20]: age_no_na = titanic[titanic["Age"].notna()]
In [21]: age_no_na.head()
Out[21]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns] notna() 条件函数会对值不是Null值的每一行返回True。因此,可以将其与选择括号[]结合使用来过滤数据表。
你可能会想知道实际发生了什么变化,因为前 5 行仍然是相同的值。验证的一种方法是检查形状是否发生了变化:
In [22]: age_no_na.shape
Out[22]: (714, 12) 到用户指南
有关缺失值的更多专用函数,请参阅用户指南中关于处理缺失数据的部分。
如何从DataFrame中选择特定的行和列?
我对 35 岁以上的乘客姓名感兴趣。
In [23]: adult_names = titanic.loc[titanic["Age"] > 35, "Name"]
In [24]: adult_names.head()
Out[24]:
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
6 McCarthy, Mr. Timothy J
11 Bonnell, Miss. Elizabeth
13 Andersson, Mr. Anders Johan
15 Hewlett, Mrs. (Mary D Kingcome)
Name: Name, dtype: object 在这种情况下,一次性对行和列进行子集操作,仅使用选择括号[]已经不够了。在选择括号[]前面需要使用loc/iloc运算符。使用loc/iloc时,逗号前面的部分是你想要的行,逗号后面的部分是你想要选择的列。
当使用列名、行标签或条件表达式时,请在选择括号[]前面使用loc运算符。对于逗号前后的部分,可以使用单个标签、标签列表、标签切片、条件表达式或冒号。使用冒号指定你想选择所有行或列。
我对第 10 到 25 行和第 3 到 5 列感兴趣。
In [25]: titanic.iloc[9:25, 2:5]
Out[25]:
Pclass Name Sex
9 2 Nasser, Mrs. Nicholas (Adele Achem) female
10 3 Sandstrom, Miss. Marguerite Rut female
11 1 Bonnell, Miss. Elizabeth female
12 3 Saundercock, Mr. William Henry male
13 3 Andersson, Mr. Anders Johan male
.. ... ... ...
20 2 Fynney, Mr. Joseph J male
21 2 Beesley, Mr. Lawrence male
22 3 McGowan, Miss. Anna "Annie" female
23 1 Sloper, Mr. William Thompson male
24 3 Palsson, Miss. Torborg Danira female
[16 rows x 3 columns] 再次,一次性对行和列的子集进行选择,仅使用选择括号[]已经不再足够。当特别关注表中位置的某些行和/或列时,请在选择括号[]前使用iloc运算符。
使用loc或iloc选择特定行和/或列时,可以为所选数据分配新值。例如,为第四列的前 3 个元素分配名称anonymous:
In [26]: titanic.iloc[0:3, 3] = "anonymous"
In [27]: titanic.head()
Out[27]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns] 转到用户指南
查看用户指南关于索引选择的不同选择部分,以更深入了解loc和iloc的用法。
记住
- 在选择数据子集时,使用方括号
[]。 - 在这些括号内,您可以使用单个列/行标签、列/行标签列表、标签切片、条件表达式或冒号。
- 使用
loc选择特定行和/或列时,请使用行和列名称。 - 使用
iloc选择特定行和/或列时,请使用表中的位置。 - 您可以基于
loc/iloc分配新值给选择。
转到用户指南
用户指南页面提供了有关索引和选择数据的完整概述。
如何从DataFrame中选择特定列?
我对泰坦尼克号乘客的年龄感兴趣。
In [4]: ages = titanic["Age"]
In [5]: ages.head()
Out[5]:
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
Name: Age, dtype: float64 要选择单列,使用方括号[]和感兴趣的列的列名。
DataFrame中的每一列都是一个Series。当选择单列时,返回的对象是一个 pandas Series。我们可以通过检查输出的类型来验证这一点:
In [6]: type(titanic["Age"])
Out[6]: pandas.core.series.Series 并查看输出的shape:
In [7]: titanic["Age"].shape
Out[7]: (891,) DataFrame.shape是一个属性(请记住读写教程,对于属性不要使用括号),包含行数和列数:(nrows, ncolumns)。pandas Series 是 1 维的,只返回行数。
我对泰坦尼克号乘客的年龄和性别感兴趣。
In [8]: age_sex = titanic[["Age", "Sex"]]
In [9]: age_sex.head()
Out[9]:
Age Sex
0 22.0 male
1 38.0 female
2 26.0 female
3 35.0 female
4 35.0 male 要选择多列,使用选择括号[]内的列名列表。
注意
内部方括号定义了一个Python 列表,其中包含列名,而外部方括号用于从 pandas DataFrame中选择数据,就像在前面的示例中看到的那样。
返回的数据类型是一个 pandas DataFrame:
In [10]: type(titanic[["Age", "Sex"]])
Out[10]: pandas.core.frame.DataFrame In [11]: titanic[["Age", "Sex"]].shape
Out[11]: (891, 2) 选择返回了一个具有 891 行和 2 列的DataFrame。请记住,DataFrame是二维的,具有行和列两个维度。
转到用户指南
有关索引的基本信息,请参阅用户指南中关于索引和选择数据的部分。
如何从DataFrame中筛选特定行?
我对 35 岁以上的乘客感兴趣。
In [12]: above_35 = titanic[titanic["Age"] > 35]
In [13]: above_35.head()
Out[13]:
PassengerId Survived Pclass ... Fare Cabin Embarked
1 2 1 1 ... 71.2833 C85 C
6 7 0 1 ... 51.8625 E46 S
11 12 1 1 ... 26.5500 C103 S
13 14 0 3 ... 31.2750 NaN S
15 16 1 2 ... 16.0000 NaN S
[5 rows x 12 columns] 要基于条件表达式选择行,请在选择括号[]内使用条件。
选择括号内条件titanic["Age"] > 35检查Age列数值大于 35 的行:
In [14]: titanic["Age"] > 35
Out[14]:
0 False
1 True
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Age, Length: 891, dtype: bool 条件表达式的输出(>, 也可以是 ==, !=, <, <=,…)实际上是一个布尔值的 pandas Series(True 或 False)与原始 DataFrame 行数相同。这样的布尔值 Series 可以用于通过将其放在选择括号[]之间来过滤 DataFrame。只有值为True的行将被选中。
我们之前知道原始泰坦尼克DataFrame由 891 行组成。让我们通过检查above_35的结果DataFrame的shape属性来查看满足条件的行数:
In [15]: above_35.shape
Out[15]: (217, 12) 我对泰坦尼克号 2 和 3 舱位的乘客感兴趣。
In [16]: class_23 = titanic[titanic["Pclass"].isin([2, 3])]
In [17]: class_23.head()
Out[17]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
2 3 1 3 ... 7.9250 NaN S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
7 8 0 3 ... 21.0750 NaN S
[5 rows x 12 columns] 与条件表达式类似,isin()条件函数对于每一行数值在提供的列表中时返回True。要基于此类函数过滤行,请在选择括号[]内使用条件函数。在这种情况下,选择括号内条件titanic["Pclass"].isin([2, 3])检查Pclass列数值为 2 或 3 的行。
上述等同于按照舱位为 2 或 3 的行进行过滤,并使用|(或)运算符将两个语句组合:
In [18]: class_23 = titanic[(titanic["Pclass"] == 2) | (titanic["Pclass"] == 3)]
In [19]: class_23.head()
Out[19]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
2 3 1 3 ... 7.9250 NaN S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
7 8 0 3 ... 21.0750 NaN S
[5 rows x 12 columns] 注意
当组合多个条件语句时,每个条件必须用括号()括起来。此外,不能使用 or/and,而是需要使用 or 运算符 | 和 and 运算符 &。
转到用户指南
请查看用户指南中关于布尔索引或 isin 函数的专门部分。
我想处理已知年龄的乘客数据。
In [20]: age_no_na = titanic[titanic["Age"].notna()]
In [21]: age_no_na.head()
Out[21]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns] notna()条件函数对于每一行数值不是Null值时返回True。因此,可以与选择括号[]结合使用来过滤数据表。
你可能想知道实际发生了什么变化,因为前 5 行仍然是相同的值。验证的一种方法是检查形状是否发生了变化:
In [22]: age_no_na.shape
Out[22]: (714, 12) 转到用户指南
想要了解更多关于处理缺失值的专用功能,请查看用户指南中关于处理缺失数据的部分。
如何从DataFrame中选择特定的行和列?
我对年龄大于 35 岁的乘客的姓名感兴趣。
In [23]: adult_names = titanic.loc[titanic["Age"] > 35, "Name"]
In [24]: adult_names.head()
Out[24]:
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
6 McCarthy, Mr. Timothy J
11 Bonnell, Miss. Elizabeth
13 Andersson, Mr. Anders Johan
15 Hewlett, Mrs. (Mary D Kingcome)
Name: Name, dtype: object 在这种情况下,一次性选择行和列的子集,并且仅使用选择括号[]已经不再足够。需要在选择括号[]前使用loc/iloc运算符。在使用loc/iloc时,逗号前面的部分是您想要的行,逗号后面的部分是您要选择的列。
当使用列名称、行标签或条件表达式时,请在选择括号[]前使用loc运算符。对于逗号前后的部分,您可以使用单个标签、标签列表、标签切片、条件表达式或冒号。使用冒号指定您要选择所有行或列。
我对第 10 到 25 行和第 3 到 5 列感兴趣。
In [25]: titanic.iloc[9:25, 2:5]
Out[25]:
Pclass Name Sex
9 2 Nasser, Mrs. Nicholas (Adele Achem) female
10 3 Sandstrom, Miss. Marguerite Rut female
11 1 Bonnell, Miss. Elizabeth female
12 3 Saundercock, Mr. William Henry male
13 3 Andersson, Mr. Anders Johan male
.. ... ... ...
20 2 Fynney, Mr. Joseph J male
21 2 Beesley, Mr. Lawrence male
22 3 McGowan, Miss. Anna "Annie" female
23 1 Sloper, Mr. William Thompson male
24 3 Palsson, Miss. Torborg Danira female
[16 rows x 3 columns] 再次,一次性选择行和列的子集,并且仅使用选择括号[]已经不再足够。当特别关注表中位置的某些行和/或列时,请在选择括号[]前使用iloc运算符。
在使用loc或iloc选择特定行和/或列时,可以为所选数据分配新值。例如,要将名称anonymous分配给第四列的前 3 个元素:
In [26]: titanic.iloc[0:3, 3] = "anonymous"
In [27]: titanic.head()
Out[27]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns] 前往用户指南
查看用户指南中关于索引的不同选择以获取有关loc和iloc用法的更多见解。
记住
- 在选择数据子集时,使用方括号
[]。 - 在这些括号内,您可以使用单个列/行标签、列/行标签列表、标签切片、条件表达式或冒号。
- 使用
loc选择特定行和/或列时,请使用行和列名称。 - 使用
iloc选择特定行和/或列时,请使用表中的位置。 - 您可以根据
loc/iloc的选择分配新值。
前往用户指南
用户指南页面提供了有关索引和选择数据的完整概述。