揭秘Robinhood扩展和管理PB级规模Lakehouse架构
揭秘Robinhood扩展和管理PB级规模Lakehouse架构

Robinhood 团队成员高级工程师 Balaji Varadarajan 和技术主管 Pritam Dey 描述了他们公司的数据Lakehouse的实现,Robinhood 的数据团队如何基于 Apache Hudi 和相关 OSS 服务来处理数 PB 规模的指数级增长。
关键要点包括分层架构实施的细节;如何应用相同的架构来跟踪元数据并满足相关的 SLA(例如数据新鲜度);以及如何大规模有效地实施 GDPR 合规性和其他数据治理流程。
实施 Robinhood 数据Lakehouse架构
Robinhood 数据 Lakehouse 生态系统支持超过一万个数据源,处理数 PB 数据集,并处理数据新鲜度模式(从近实时流到静态)、数据关键性、流量模式和其他因素方面差异很大的用例。
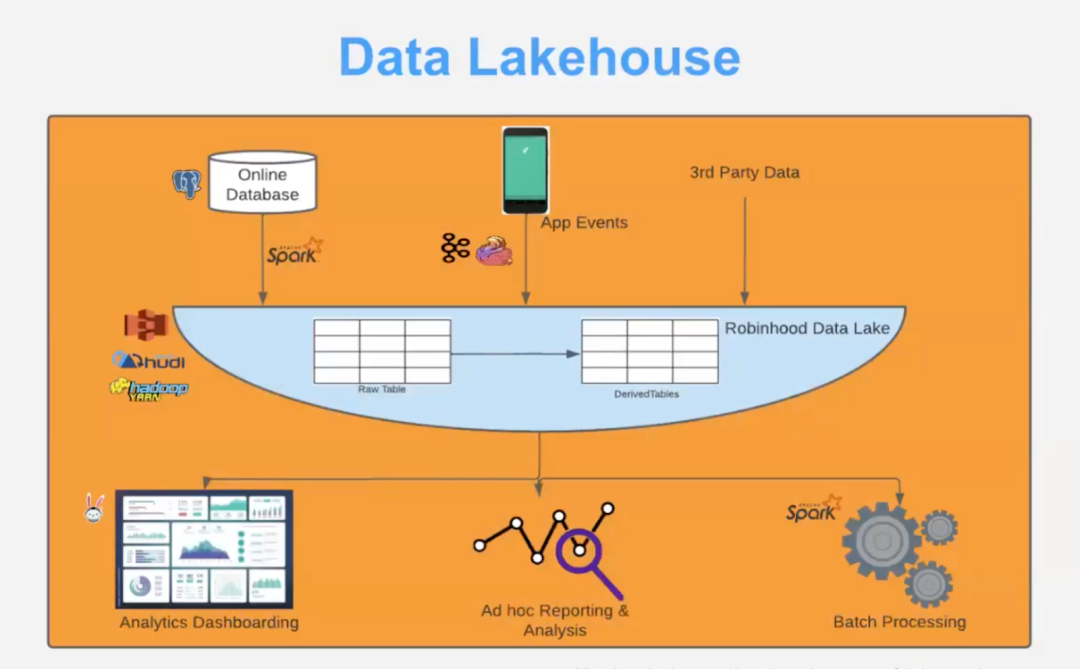
Robinhood 数据 Lakehouse 从许多不同的来源获取数据:实时应用程序事件和实验流、通过 API 按不同计划提供的第三方数据以及 Postgres 等在线 RDBMS。然后必须将这些数据提供给许多消费者类型和用例,包括高关键性用例(例如欺诈检测和风险评估)以及低关键性用例(例如分析、报告和监控)。
Robinhood 对所有各种用例的支持是建立在多层架构之上的,关键性最高的数据在第 0 层进行处理,后续层用于处理具有较低约束的数据,该 Lakehouse架构满足 Robinhood 的需求
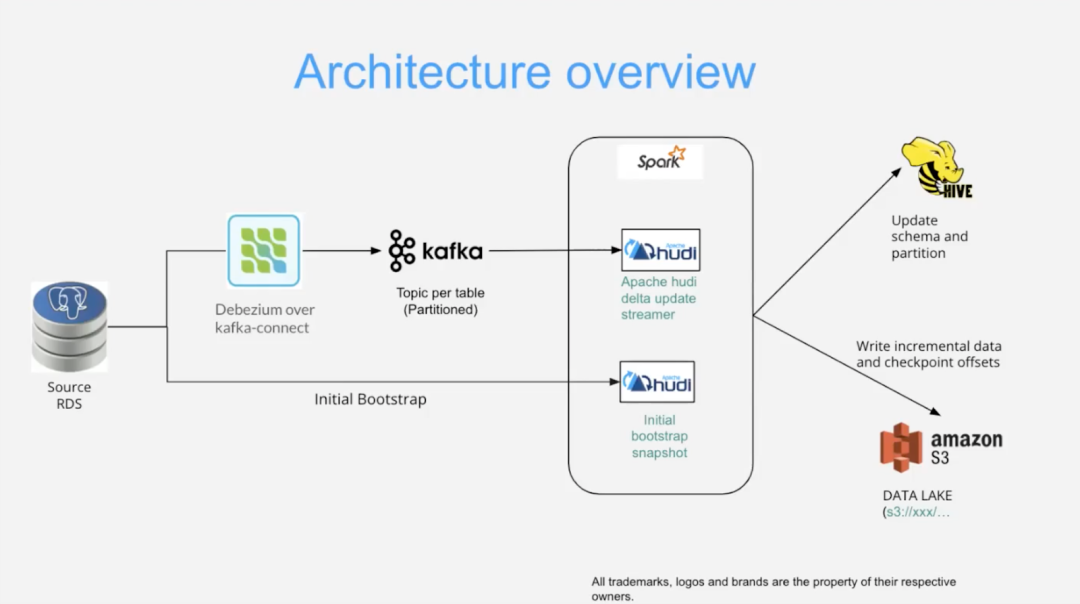
每层中的数据处理都从数据源开始——在本例中 Debezium 正在监视关系数据库服务 (RDS),例如 Postgres。在启动之前会完成一次性引导过程,确保在数据Lakehouse中定义初始目标表和架构 - 预期 Debezium 驱动的变更数据捕获 (CDC) 流。一旦表就位就会启动一个多步骤过程,并在该层的生命周期内保持活动状态:
- ? 数据从任何上游应用程序、API 或其他数据源写入 RDS,可能是实时且大量的。
- ? Debezium 使用众多预定义连接器之一来监视 RDS 并检测数据更改(写入和更新)。然后它将数据更改打包到 CDC 包中,并将其发布到 Kafka 流或主题。
- ? Apache Hudi 的 DeltaStreamer 应用程序实例(由 Spark 提供支持)处理 CDC 包 - 根据需要对它们进行批处理或流式处理。
- ? 作为其操作的副作用,DeltaStreamer 会生成 Hive 架构和元数据更新 - 跟踪数据新鲜度、存储和处理成本、访问控制等。
- ? 处理后,增量数据更新和检查点将写入数据湖或对象存储(例如 Amazon S3)。
大规模关键元数据的新鲜度跟踪
以下架构维护了关键的元数据属性(新鲜度)。
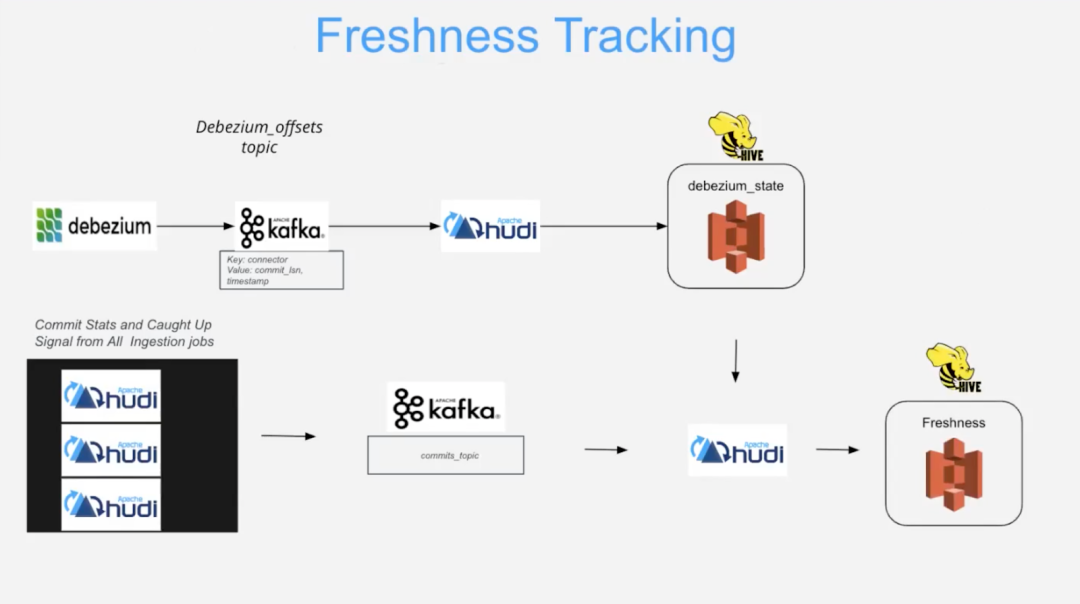
用于跟踪数据新鲜度的内部生成的元数据(来自 Debezium 和 Apache Hudi 源)通过上述过程中步骤 2 和 3 中提到的基础设施(即 Debezium + Kafka + DeltaStreamer)进行循环,然后进入到步骤 4。也就是说 Hive 元数据存储会根据 Debezium 状态和 DeltaStreamer 生成的其他新鲜度指标的变化进行更新。
对这种分层架构的支持是建立在 Apache Hudi 的核心功能和 Lakehouse 的其他 OSS 组件的混合之上的。分层架构所依赖的主要功能包括:
- ? 基于元数据区分不同层表的能力,Hudi 通过其存储层抽象支持元数据
- ? 通过 Debezium 连接器隔离实现资源隔离、Hudi RDBMS 功能支持的计算和存储以及 Postgres 对复制槽的支持
- ? 各种 SLA 保证,包括以关键新鲜度为中心的保证,这些保证由 Apache Hudi 内置的各种灵活功能提供支持,例如事务的 ACID 保证、近实时数据摄取、管道中各个点的灵活/增量数据摄取,以及极其高效的下游 ETL 流程
- ? 解耦存储和处理,支持自动扩展,由 Apache Hudi 支持
- ? Apache Hudi 强大的无服务器事务层可跨数据湖使用,支持高级抽象操作,例如写入时复制和读取时合并。
大规模数据治理和 GDPR 合规性
Robinhood 使用其数据湖站的分层架构来解决数据治理和 GDPR 相关要求。
大规模数据治理非常复杂,具有多个目标:
- ? 跟踪数据及其流向
- ? 让 Lakehouse 紧跟新的和不断变化的法规
- ? 维护对数据资产的访问控制和监督
- ? 根据需要混淆和更新个人身份信息 (PII)
- ? 随着时间的推移提高数据质量
Robinhood 通过将 Lakehouse 组织成不同的区域,大规模地实现了这些目标 - Robinhood 的 Lakehouse 存储了 50,000 多个数据集。
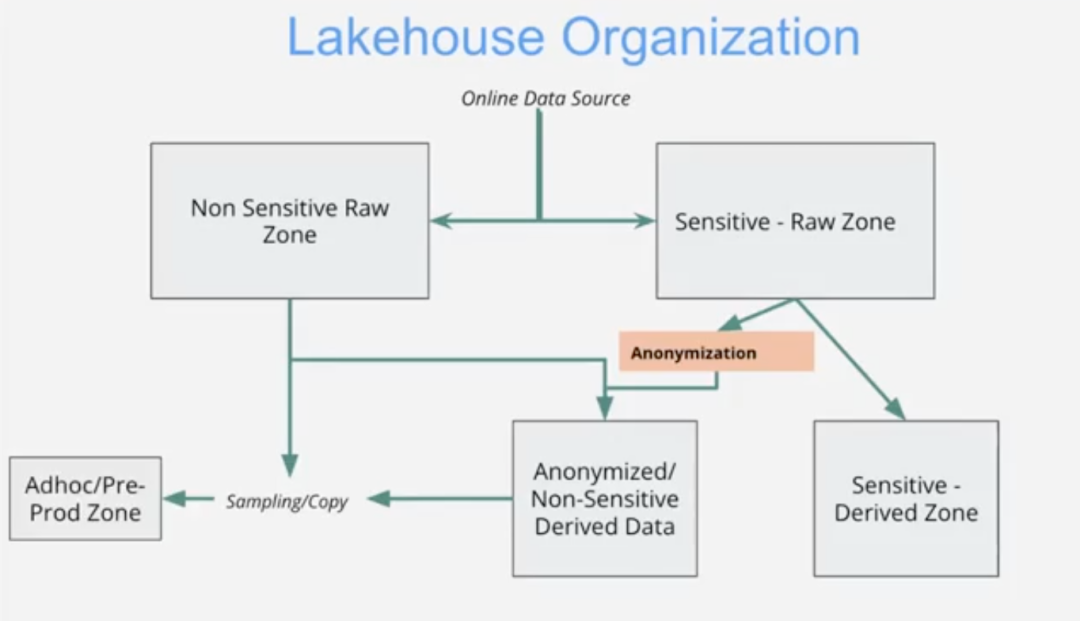
区域标签和相关元数据用于跟踪和传播有关整个Lakehouse不同区域的信息。Robinhood 的团队实施了中央元数据服务来支持这些区域。该服务建立在我们上面看到的新鲜度元数据相同的分层架构之上。
而标记是在系统中手动和自动完成的(包括在源代码级别以编程方式),标记创建与模式管理工作位于同一位置。对标签的任何更改都会通过系统中的 Lint 检查以及自动数据分类工具来强制执行、跟踪和监控,这有助于交叉检查标签并检测任何数据泄漏或异常。
高效且可扩展的 PII 掩码和删除
Robinhood 有效实施了 PII 删除操作,这是 GDPR 的“被遗忘权”所必需的——欧洲通用数据保护条例 (GDPR) 和加州消费者法案所要求的隐私法 (CCPA)。
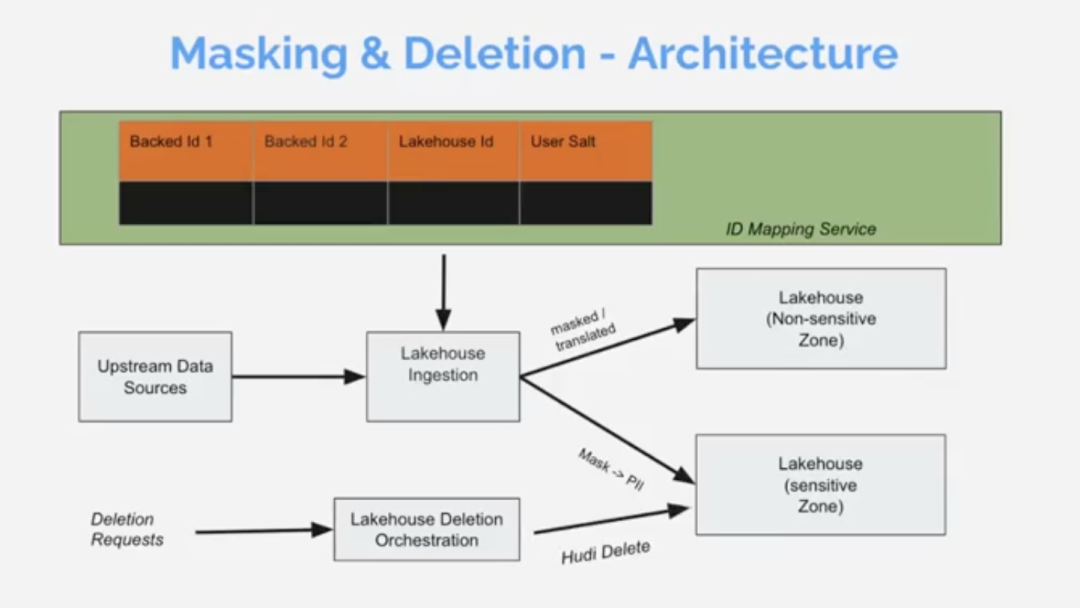
在像 Robinhood 这样庞大而复杂的 Lakehouse 中,很难支持 PII 跟踪和掩码,但这是高效、符合 GDPR 的实施 PII 删除所需的。需要能够根据需要删除整个 PB 级数据湖库中单个用户的所有 PII。这必须快速、高效地完成,并且不能影响其他用户。Varadarajan 解释说,Robinhood 的实现仅依赖于两个(实现起来很棘手)元数据服务:
- ? ID 映射服务,使用唯一的、用户特定的 Lakehouse ID 对系统中的所有用户标识符进行复杂的替换
- ? 掩码到 PII 服务,将 PII 映射到每个用户一致的掩码(关联的映射数据存储在 Lakehouse 的敏感区域中)
这两种元数据(ID 和掩码)在整个 Lakehouse 中得到普遍应用和跟踪。因此,PII 删除操作可以通过标准的 Apachi Hudi 删除操作来实现,该操作高效、快速,并且在整个 Lakehouse 上运行。
"Apache Hudi 是我们数据湖站的核心组件。它使我们能够高效运营、满足 SLA 并实现 GDPR 合规性。" — Balaji Varadarajan,Robinhood 高级工程师, Apache Hudi PMC成员
结论
在 Apache Hudi 驱动、OSS 支持的数据Lakehouse之上构建分层架构的许多好处。具体来说:
- ? 基于 CDC 的分层管道是在 Apache Hudi 之上使用 Debezium 构建的,可有效扩展以支持 10,000 多个数据源,并在指数增长的情况下处理多 PB 数据流。
- ? Apache Hudi 和相关 OSS 项目(Debezium、Postgres、Kafka、Spark)支持有效的资源隔离、存储和计算分离以及在数据湖中构建分层处理管道的其他核心技术要求。
- ? 该系统可扩展性良好,因此生产系统可以由团队构建、扩展和管理。
- ? Robinhood 的分层架构具有概括性。除了大规模数据处理之外,它还支持关键元数据用例,例如数据新鲜度、成本管理、访问控制、数据隔离和相关 SLA。
- ? 数据治理和 GDPR 用例得到相同架构的良好支持。
- ? Robinhood 的实施可以轻松支持重要的合规行动(例如删除 PII),并且大规模执行效果良好。
Robinhood Lakehouse 利用其对 Apache Hudi 和相关 OSS 项目的依赖来获得相对于竞争对手的战略优势。他们实施了可靠的数据治理机制,有效且大规模地了解 GDPR 合规性,并且能够处理指数级数据和处理增长。它们还可以支持各种元数据、跟踪和其他 SLA,例如数据新鲜度。