CVPR 2024 | ConTex-HumanЈєОЖАнТ»ЦВµДµҐКУНјИЛМеЧФУЙКУНјдЦИѕ
CVPR 2024 | ConTex-HumanЈєОЖАнТ»ЦВµДµҐКУНјИЛМеЧФУЙКУНјдЦИѕ

ЧчХЯЈєXiangjun Gao, Xiaoyu Li, Chaopeng Zhang µИ АґФґЈєCVPR 2024 ВЫОДМвДїЈєConTex-Human: Free-View Rendering of Human from a Single Image with Texture-Consistent Synthesis ВЫОДБґЅУЈєhttps://github.com/gaoxiangjun/ConTex-Human ДЪИЭХыАнЈєНхоЈеы ХвПЧчЦРМбіцБЛТ»ЦЦТФЧФУЙКУЅЗµД·ЅКЅґУµҐёцНјПсдЦИѕ 3D ИЛМеµДМфХЅµД·Ѕ·ЁЎЈТ»Р©ПЦУРµД·Ѕ·ЁНЁ№эК№УГїЙ·є»ЇµДПсЛШ¶ФЖлТюКЅіЎАґЦШЅЁИЛМеµДОЖАнНшёс»тНЁ№эК№УГ 2D А©ЙўДЈРНЧчОЄ·ЦКэХфБуІЙСщ(Score Distillation Sampling, SDS)·Ѕ·ЁµДЦёµјАґКµПЦХвТ»µгЈ¬Ѕ« 2D НјПсМбЙэµЅ 3D їХјдЎЈИ»¶шїЙ·є»ЇµДТюКЅіЎНЁіЈ»бµјЦВОЖАніЎ№э¶ИЖЅ»¬Ј¬¶ш SDS ·Ѕ·ЁЗгПтУЪУлКдИлНјПсІъЙъОЖАнІ»Т»ЦВµДРВКУНјЎЈФЪ±ѕОДЦРЈ¬ОТГЗТэИлБЛТ»ёцОЖАнТ»ЦВµД·ґПтКУНјєПіЙДЈїйЈ¬ёГДЈїйїЙТФНЁ№эЙо¶ИєНОД±ѕТэµјµДЧўТвБ¦ЧўИлЅ«ІОїјНјПсДЪИЭЧЄТЖµЅ·ґПтКУНјЦРЎЈґЛНвЈ¬ОЄБЛ»єЅв·ўЙъФЪІаГжЗшУтµДСХЙ«К§ХжЈ¬ОТГЗЅбєПєПіЙµД·ґПтКУНјОЖАнМбіцБЛТ»ЦЦёРЦЄТ»ЦВРФХэФт»ЇУГУЪОЖАнУіЙдєНПё»ЇЎЈНЁ№эЙПКцјјКхЈ¬ОТГЗїЙТФґУµҐ·щНјПсЦРКµПЦёЯ±ЈХжєНОЖАнТ»ЦВµДИЛМедЦИѕЎЈФЪХжКµКэѕЭєНєПіЙКэѕЭЙПЅшРРµДКµСйЦ¤ГчБЛОТГЗ·Ѕ·ЁµДУРР§РФЈ¬Іў±нГчОТГЗµД·Ѕ·ЁУЕУЪЦ®З°µД»щПЯ·Ѕ·ЁЎЈ
ТэСФ
ЧФУЙКУЅЗИЛМеєПіЙ»тдЦИѕ¶ФУЪРйДвПЦКµЎўµзЧУУОП·єНµзУ°ЦЖЧчµИёчЦЦУ¦УГ¶јКЗ±ШІ»їЙЙЩµДЎЈґ«Ні·Ѕ·ЁНЁіЈРиТЄГЬјЇµДПа»ъ»тЙо¶Иґ«ёРЖчАґЦШЅЁјёєОРОЧґІўПё»ЇдЦИѕ¶ФПуµДОЖАнЈ¬ґУ¶шІъЙъ·±ЛцєНєДК±µД№эіМЎЈ
ФЪ±ѕОДЦРЈ¬ОТГЗµДДї±кКЗЅцК№УГµҐёцКдИлНјПсКµПЦёЯ±ЈХжЎўОЖАнТ»ЦВµДИЛАаЧФУЙКУНјдЦИѕЈ¬ИзНј 1 ЛщКѕЎЈОТГЗМбіцБЛТ»ёцГыОЄ Ў°ConTex-HumanЎ±µДґґРВїтјЬЎЈФЪґЛїтјЬПВЈ¬ОТГЗЅ«ЧоЦХДї±к·ЦЅвОЄБЅёц№ШјьЧУДї±кЎЈµЪТ»ёцЙжј°ЙъіЙѕЯУРѕ«ПёПёЅЪµДОЖАнТ»ЦВµД·ґПтКУНјЎЈµЪ¶юёцЧУДї±кКЗЅ«КдИлІОїјєН·ґПтКУНјУіЙдµЅЦШ№№јёєОНјРОєуЈ¬УГєПАнµДОЖАн»жЦЖІаГжєНІ»їЙјыЗшУтЎЈЧЬЦ®Ј¬±ѕОДµД№±ПЧИзПВЈє
- ОТГЗМбіцБЛТ»ЦЦіЖОЄ Ў°ConTexHumanЎ± µДґґРВїтјЬЈ¬ёГїтјЬїЙТФК№УГµҐ·щНјПсКµПЦѕЯУРТ»ЦВОЖАнµДёЯ±ЈХжЧФУЙКУНјИЛМедЦИѕЎЈ
- ОТГЗЙијЖБЛТ»ёцЙо¶ИєНОД±ѕМбКѕМхјю·ґПтКУНјєПіЙДЈїйЈ¬ёГДЈїйїЙТФ±ЈіЦУлІОїјНјПсТ»ЦВµДОЖАнСщКЅєНПёЅЪЎЈ
- ОТГЗМбіцБЛТ»ЦЦОЖАнУіЙдєНПё»ЇДЈїйЈ¬ёГДЈїйѕЯУРїЙјыРФµДёРЦЄТ»ЦВРФЛрК§Ј¬ТФєПіЙІ»їЙјыЗшУтµДТ»ЦВРФПсЛШЎЈ

Нј1 Ў°ConTex-HumanЎ±їЙТФФЪІ»Н¬КэѕЭјЇЙПЅцК№УГµҐКУНјАґКµПЦёЯ±ЈХжОЖАнТ»ЦВµДЧФУЙКУНјИЛМедЦИѕЎЈЧу±ЯБЅёцЅб№ыАґЧФКэѕЭјЇ SSHQЈ¬УТ±ЯБЅёцАґЧФ THuman2.0
·Ѕ·Ё
ёш¶ЁИЛАаµДµҐёц RGB НјПсЈ¬ОТГЗµДДї±кКЗЦШЅЁ 3D ±нКѕЈ¬їЙТФґУёчЦЦКУµгдЦИѕИЛАаёЯ±ЈХжНјПсЎЈОТГЗµД·Ѕ·ЁЦ»РиТЄТ»ёц RGB НјПсј°ЖдЗ°ѕ°СЪВлЎЈОТГЗµД·Ѕ·ЁИзНј 2 ЛщКѕЈ¬УЙИэёцЦчТЄЅЧ¶ОЧйіЙЈєКЧПИК№УГ 2D А©ЙўДЈРНЅ«КдИлµДИЛМеНјПсМбЙэµЅґЦВФЅЧ¶ОµД·шЙдіЎЈ»ЅУПВАґґУІОїјЦРТэИлЙо¶ИєНОД±ѕТэµјµДЧўТвЧўИлДЈїйЈ¬ФЪ·ґПтКУНјЦРєПіЙОЖАнТ»ЦВµДНјПсЈ¬ЧчОЄєуРшЅЧ¶ОµД»щ±ѕРЕПўЈ»ЧоєуЈ¬ОТГЗМбіцБЛТ»ЦЦїЙјыРФёРЦЄµД patch Т»ЦВРФЛрК§АґЦШЅЁ3DНшёсЈ¬ТФ±гФЪѕ«ПёЅЧ¶ОЅшРРёЯЦКБїµДдЦИѕ)ЎЈ

Нј2 Overview "ConTex-Human"
Course StageЈє·шЙдіЎЦШЅЁ
ЧоЅьЅ«µҐёцНјПсМбЙэµЅ3D¶ФПуЦРµДНјПсµЅ3DЙъіЙ·Ѕ·ЁНЁіЈІЙУГStable Diffusion ЈЁSDЈ©ЧчОЄА©ЙўПИСйЎЈИ»¶шSD ТэµјѕіЈµјЦВ·±ЛцµДУЕ»Ї№эіМЈ¬ЧоЦШТЄµДКЗЈ¬УЙУЪА©ЙўДЈРНµДСµБ·КэѕЭЦРµДКэѕЭЖ«ІоЈ¬»бµјЦВУЕ»ЇєуµД3D¶ФПуЦРіцПЦІ»Т»ЦВµД¶аН·ОКМвЎЈФЪ3DИЛМеµД±іѕ°ПВЈ¬ХвёцОКМвЙхЦБїЙТФОЄјтµҐµДЧЛКЖЙъіЙ¶аКЦ±ЫєН¶аМхНИµДјёєОНјРОЈ¬ёьІ»УГЛµґ¦АнёґФУ¶аСщµДИЛМеЧЛКЖБЛЎЈОЄБЛЅвѕцХвёцОКМвЈ¬ОТГЗК№УГ»щУЪZero-1-To-3ДЈРНµДSDSЛрК§ЧчОЄА©ЙўПИСйЎЈ
ОЄБЛУЕ»Ї3D±нКѕЈ¬ОТГЗКЧПИФЪґУКдИлНјПсЦРМбИЎµДMask
єНЗ°КУНјЦРµДдЦИѕ Mask
Ц®јдК№УГ
АґФјКш3DїХјдЦРµДИЛМеЗшУтЈє
ФЪЗ°КУНјЦРЈ¬јЖЛгRGBЛрК§АґіН·ЈКдИлНјПс
єНдЦИѕЅб№ы
Ц®јдµДІоТм:
ґЛНвЈ¬ОЄБЛФЪУЕ»Ї№эіМЦРјУЗїёьєГµДјёєОРОЧґІўјУїмСµБ·№эіМЈ¬ОТГЗ»№ОЄЗ°КУНјЦРіКПЦµД·ЁПЯУіЙдјУИлБЛІОїј·ЁПЯФјКшЎЈТтґЛЈ¬ІОїј·ЁПЯ
єНдЦИѕ·ЁПЯ
Ц®јдµДХэіЈЛрК§№«КЅОЄЈє
ЧЬµДЛрК§єЇКэїЙРґОЄЈє
,
,
and
ЎЈ
ОЖАнТ»ЦВµД·ґПтКУНјєПіЙ
ѕЎ№ЬДїЗ°µДНјПсµЅ3DНјПс·Ѕ·ЁїЙТФОЄКдИлНјПсµДІ»їЙјыЗшУтЙъіЙєПАнµДЅб№ыЈ¬µ«УЙУЪФЪєПіЙЖдЛыЗшУтК±И±·¦¶ФКдИлНјПсµДИПК¶Ј¬Ѕб№ыНщНщКЗ№э±ҐєНЎў№э¶ИЖЅ»¬Ўў·зёсІ»Т»ЦВєНµНЦКБїµДЎЈКЬЧоЅьµД2DНјПс±ај·Ѕ·ЁµДЖф·ўЈ¬ёГ·Ѕ·ЁїЙТФФЪєПіЙєН±ај№эіМЦР±ЈіЦФґНјПсµДДЪИЭєНПёЅЪЎЈОТГЗµД№ШјьЛјПлКЗґУКдИлІОїјНјПс
ЦРІйСЇНјПсДЪИЭЈ¬ІўјЇіЙЛьГЗАґєПіЙ·ґПтКУНјНјПс
Ј¬Н¬К±±ЈіЦТ»ЦВµДОЖАнПёЅЪЈ¬ёГ№эіМУЙОД±ѕМбКѕ
єНЙо¶ИНј
ЦёµјЎЈЙо¶ИНј
ДЬ№»Цёµј
µДІјѕЦЈ¬Хв¶ФУЪѕ«ПёЅЧ¶ОЅ«ОЖАнОЮ·мУіЙдµЅјёєОНјРОЦБ№ШЦШТЄЎЈОД±ѕМбКѕ
ГиКцБЛИЛМеРЕПў·зёсЈ¬ИзРФ±рЎўН··ўСХЙ«єН·зёсЎў·юЧ°СХЙ«єНАаРНµИЎЈФЪЦёµјµД»щґЎЙПЈ¬ОТГЗМбіцБЛТ»ЦЦЙо¶ИєНОД±ѕМхјюОЖАнТ»ЦВµД·ґПтКУНјєПіЙДЈїйЈ¬ёГДЈїйАыУГФ¤ПИСµБ·µДЙо¶ИМхјюОИ¶ЁА©ЙўДЈРНЈ¬Іў±ИТФЗ°µД·Ѕ·ЁєПіЙБЛёьПкПёµД·ґПтКУНјНјПсЎЈ
Нј 3
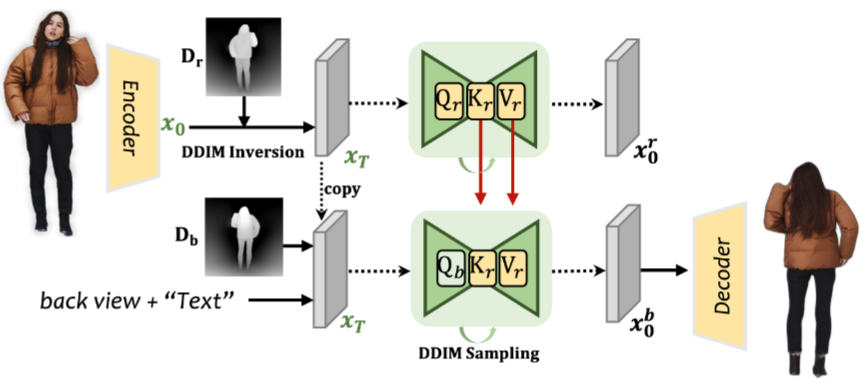
ОТГЗµДОЖАнТ»ЦВµД·ґПтКУНјєПіЙДЈїйИзНј 3 ЛщКѕЎЈОТГЗКЧПИНЁ№э SD ±аВлЖч¶ФФКјЗ°НјПс
±аВлОЄЗ±ФЪґъВл
ЎЈИ»єуФЪ
ЙПЅшРР DDIM ·ґСЭІЙСщЈ¬ёГІЙСщУлЗ°КУНјЙо¶И
µьґъБ¬ЅУТФ»сµГЖрКјФлЙщЗ±ФЪґъВл
ЎЈ¶ФУЪ·ґПтКУНјєПіЙЈ¬
±»ёґЦЖОЄєуКУНјНјПсµДЖрКјФлЙщЗ±ВлЈ¬ІўУлєуКУНјЙо¶И
Б¬ЅУЈ¬УГУЪєуРшµДDDIMІЙСщЎЈАыУГ
ЧчОЄМхјюРЕПўїШЦЖІјѕЦЈ¬ЙъіЙµД·ґПтКУНјУлґЦЅЧ¶ОNeRFєНПёЅЧ¶ОНшёсєЬєГµШ¶ФЖлЎЈґЛНвЈ¬ОТГЗЅ«¶МУпЎ°back viewЎ±єПІўµЅФКјОД±ѕМбКѕ
ЦРЈ¬НЁ№эФЪ SD ДЈРНЦРНЁ№эЅ»ІжЧўТвАґЦёµј·ґПтКУНјєПіЙЎЈ
іэБЛ·ґПтКУНјєПіЙНвЈ¬»№Н¬К±ЅшРРАґЧФ
єН
µДЗ°ПтКУНјєПіЙ№эіМЎЈФЪ·ґПтКУНјєНЗ°КУНјєПіЙЖЪјдЈ¬¶ФУЪМШ¶ЁµДК±јдІЅ
Ј¬ОТГЗІЙУГЧўТвБ¦ЧўИл·Ѕ·ЁЅ«ЧўТвБ¦ІгЦРµД№ШјьМШХч
єНЦµМШХч
ґУЗ°КУНј·ЦЦ§ЧЄТЖµЅєуКУНј·ЦЦ§ЎЈН¬К±Ј¬·ґПтКУНј·ЦЦ§ФЪЧўТвБ¦ІгЦР±ЈіЦЖдФКјІйСЇМШХч
ЎЈµьґъЦґРРЧўТвБ¦МШХчЧЄТЖТФєПіЙ·ґПтКУНјЎЈНЁ№эХвР©МбТйµДІЩЧчЈ¬АґЧФЗ°КУНјНјПсµДПкПёОЖАнїЙТФН¬К±ЧЄТЖµЅєуКУНјЈ¬±ЈіЦУлЗ°КУНјјёєОКУНјТ»ЦВµДєуКУНјЙо¶ИІјѕЦЈ¬ІўёщѕЭФКјОД±ѕГиКцєЬєГµШ¶ФЖлЎЈ
Fine StageЈєёЯ±ЈХжНшёсЦШЅЁ
ґЦЅЧ¶ОЦ»ЙъіЙТ»ёцґЦІЪµДјёєОРОЧґєНµНЦКБїµДОЖАнЈ¬УЙГЬ¶ИіЎєНСХЙ«іЎ±нКѕЎЈТтґЛЈ¬ОТГЗТэИлБЛТ»ёцѕ«ПёЅЧ¶ОЈ¬НЁ№эАыУГІОїјНјПсЦРµДДЪИЭПёЅЪІўґУОТГЗµД·Ѕ·ЁЦРЙъіЙ·ґПтКУНјНјПсЈ¬ґУґЦЅЧ¶ОПё»ЇјёєОєНОЖАнЎЈ
јёєОЦШЅЁ
ОТГЗІЙУГ DMTetКЗТ»ЦЦ»мєП SDF-Mesh ±нКѕЈ¬УГУЪѕ«ПёЅЧ¶ОµДЦШЅЁЈ¬ДЬ№»ЙъіЙёЯ·Ц±жВК 3D РОЧґІўФКРнУРР§µДїЙОўдЦИѕЎЈОЄБЛіхКј»Ї DMTetЈ¬ОТГЗК№УГАґЧФґЦВФЅЧ¶ОµДГЬ¶ИіЎЙиЦГГїёц¶Ґµг
µД SDF ЦµЈ¬±дРОПтБї Ўч
ЙиЦГОЄ 0ЎЈФЪјёєОУЕ»Ї№эіМЦРЈ¬ґУ DMTet ЦРМбИЎИэЅЗРОНшёсЎЈОТГЗІЙУГІо·Ц№вХ¤»ЇЖчґУёш¶ЁµДКУµгдЦИѕ·ЁПЯМщНјЎЈ
ОЄБЛФЪУЕ»Ї№эіМЦРХэФт»ЇјёєОНјРОЈ¬ОТГЗ»№ІЙУГБЛУлґЦВФЅЧ¶ОПаН¬µДХэіЈФјКшЎЈТ»ЦЦјтµҐµД·Ѕ·ЁКЗК№УГ ECON ЦРПЦУРµД·ЁПЯ№АјЖЖчЈ¬ґУІОїјНјПс№АјЖЗ°КУНјєНєуКУНјµДХэіЈУіЙдЧчОЄја¶ЅЎЈИ»¶шЈ¬УЙУЪПа»ъЙиЦГІ»Н¬Ј¬№АјЖµД±іКУНј·ЁПЯєНЦШЅЁјёєОНјРОЦ®јдґжФЪ¶ФЖлОКМвЎЈјшУЪґЛЈ¬ОТГЗґУЙъіЙµДєПіЙОЖАнТ»ЦВµД·ґПтКУНјЅ»Мж»сµГ·ґПт·ЁПЯ
ЎЈХвёц·ЁПЯУлОТГЗµДіхКј»ЇµДјёєОєНєПіЙ·ґПтКУНјєЬєГµШ¶ФЖлЎЈ
јшУЪІОїјКУНј·ЁПЯєН·ґПтКУНј·ЁПЯ°ьє¬ґуІї·ЦИЛМеЗшУтЈ¬ФЪУ¦УГНшёс·ЁПЯЖЅ»¬¶ИєНАЖХАЛ№ЖЅ»¬¶ИФјКшєуЈ¬їЙТФКµПЦІОїјКУНјєН·ґПтКУНјЦ®јдµДєПАнЧЄ»»ЎЈЧоєуЈ¬ѕ«ПёЅЧ¶ОµДјёєОЦШЅЁЛрК§їЙТФРґіЙИзПВЈє
ЖдЦР
єН
·Ц±рКЗК№УГNvdiffrastдЦИѕµДНшёс·ЁПЯНјЎЈ
єН
·Ц±рКЗК№УГІОїјНјПсєНЙъіЙµДєуКУНјПсµД ECON ·ЁПт№АјЖЖч№АјЖµДІОїјєНєуКУХжКµ·ЁПтНјЎЈ
ОЖАнУіЙдєНПё»Ї
ФЪѕ«ПёЅЧ¶ОµДјёєОЦШЅЁЦ®єуЈ¬ПВТ»ІЅКЗНЁ№эЅ«ІОїјЗ°НјПс
єНЙъіЙµДєуКУНјНјПс
УіЙдµЅѕ«»ЇјёєОНјРОАґЙъіЙОЖАнЎЈОТГЗІЙУГInstant-NGPАґ±нКѕ 3D ОЖАніЎЎЈ¶ФУЪІЙСщНјПсЦРµДГїёцПсЛШ
Ј¬ОТГЗКЧПИјЖЛгЖдЙдПЯНшёсЅ»µгµДИэО¬О»ЦГ
ЎЈИ»єуґУ Instant-NGP МШХчНшёсІеЦµЗ±ФЪМШХчЈ¬Іў±»АЎЛНµЅТ»ёцОўРЎµДІг MLP НшВзАґЅвВлСХЙ«ЦµЎЈКЧПИК№УГЗ°ІОїјНјПсIrєНЙъіЙµДєуКУНјНјПс
ЧчОЄја¶Ѕ¶ФОЖАніЎЅшРРХэФт»Ї:
ЖдЦРЈ¬
єН
·Ц±рКЗАґЧФОЖАніЎµДдЦИѕЗ°НјПсєНдЦИѕєуНјПсЎЈ
ѕЎ№ЬЗ°КУНјєНєуКУНјНјПсїЙТФёІёЗИЛАаµДґуІї·ЦОЖАнЈ¬µ«ФЪІаКУНјєНЧФХЪµІЗшУтИФИ»ґжФЪТ»Р©И±К§µДОЖАнЎЈОЄБЛНкіЙИ±К§µДОЖАнЈ¬ОТГЗІЙУГОИ¶ЁА©ЙўєН Zero-1-To-3 ДЈРНµД
ЧйєПАґУЕ»ЇОЖАніЎЈє
ЧйєПµД SDS ЛрК§їЙТФМоідОД±ѕМбКѕТэµјµДИ±К§ЗшУтЎЈИ»¶шЈ¬ФЪРн¶аЗйїцПВЈ¬З°єуКУНјНјПсЦ®јдµДМоідІї·ЦґжФЪГчПФµДОЖАнЧЄ»»єНІ»Т»ЦВµД·зёсЎЈОЄБЛЅвѕцХвёцОКМвЈ¬ОТГЗМбіцБЛТ»ЦЦїЙјыРФёРЦЄµДpatchТ»ЦВРФЛрК§ЅшРРПё»ЇЈ¬їЙТФ»єЅвІ»Т»ЦВµДІаКУНјОЖАнЈ¬ИзНј 4 ЛщКѕЎЈѕЯМеАґЛµЈ¬¶ФУЪЗ°КУНјНјПсєНєуКУНјНјПсЦРµДГїёцПсЛШЈ¬ОТГЗНЁ№эХ¤ёс»ЇХТµЅЛьУл¶ФУ¦µДНшёсИэЅЗРОГжµДЅ»µгЎЈЧоЅУЅьЅ»јЇµДИЛБіЙПµД¶ҐµгЙиЦГОЄ1Ј¬±нГчЛьГЗ¶Ф
»т
їЙјыЎЈ
єН
І»їЙјыµД¶ҐµгЙиЦГОЄ 0ЎЈ

Нј 4
ОТГЗИПОЄІ»їЙјыЗшУтЦРµДПсЛШУ¦ёГУлЛьГЗФЪ patch ДЪµДПаБЪїЙјыПсЛШѕЯУРТ»ЦВµДСХЙ«ЎЈОЄБЛКµПЦХвТ»µгЈ¬ОТГЗКЧПИФЪПа»ъїХјдЦРІЙСщТ»ёцЛж»ъКУµгЈ¬ІўдЦИѕRGBНјПс
ј°ЖдїЙјыРФНј
ЎЈИ»єуОТГЗ¶Ф
ЦРµДЛж»ъ patch
ј°ЖдФЪ
ЦРµДїЙјыРФНј
ЅшРРІЙСщЎЈФЪХвёцpatchЦРЈ¬І»їЙјыПсЛШ
їЙТФНЁ№э(
=
*
)јЖЛгЈ¬їЙјыПсЛШ
їЙУЙ(
=
*
)јЖЛгЎЈИ»єуОТГЗјЖЛгїЙјыРФёРЦЄµД patch Т»ЦВРФЛрК§ИзПВЈє
ОЖАнУіЙдєНПё»ЇµДХыМеЛрК§їЙТФ±нКцОЄ
Ўў
єН
µДЧйєПЎЈ
КµСй
¶ЁРФКµСй

Нј5
Нј5 КЗёчёц·Ѕ·ЁФЪ THuman2.0 єН SSHQ КэѕЭјЇЙПµД¶ЁРФ±ИЅПЅб№ыЎЈµЪ 1&2 РРКЗ THuman2.0 Сщ±ѕЈ¬µЪ 3&4 РРКЗ SSHQ Сщ±ѕЎЈPIFu єН PaMIR ЗгПтУЪФ¤ІвДЈєэµДдЦИѕЅб№ыЈ¬УИЖдКЗФЪ±іГжКУНјЦРЎЈMagic123 ДСТФФ¤ІвТ»ЦВµДОЖАнЎЈ
Нј6 THuman2.0єНSSHQЙПОЮОЖАнТ»ЦВµД·ґПтКУНјєПіЙДЈїйєННкХыДЈРНµД¶ЁРФЅб№ыЎЈ
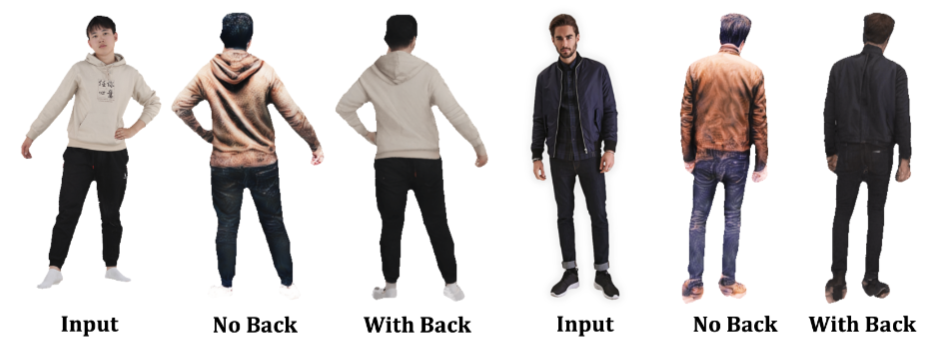
±ИЅПЅб№ыИзНј6ЛщКѕЎЈїЙТФ№ЫІмµЅЈ¬ФЪГ»УРОЖАнТ»ЦВµД·ґПтКУНјµДЗйїцПВЈ¬ОЖАнНщНщЦКБїЅПµНЈ¬ЧоЦШТЄµДКЗЈ¬УлКдИлКУНјИ±·¦Т»ЦВРФЎЈ

Нј7 THuman2.0 єН SSHQ ЙПОЮїЙјыРФёРЦЄpatchТ»ЦВРФЛрК§єННкХыДЈРНµД¶ЁРФЅб№ыЎЈ
Нј 7 ЦРПФКѕµДКУѕхКѕАэ±нГчЈ¬ФЪГ»УР VPC ЛрК§ЎўСПЦШµДСХЙ«К§ХжТФј°СХЙ«І»Т»ЦВµДЗйїцПВЈ¬Ѕ«іцПЦФЪІаГжЗшУтЎЈОТГЗЅ«ґЛІ»Т»ЦВ№йТтУЪ SDS УЕ»ЇОЮ·ЁТэµјДЈРНіЇПтЧојСВъЧгЗ°КУНјµДЧојСКХБІЅвѕц·Ѕ°ёЎЈ
¶ЁБїКµСй

±н1 ФЪSSIMЎўPSNRЎўLPIPSєНCLIP·ЅГжЈ¬ОТГЗµД·Ѕ·ЁУлPIFUЎўPaMIRЎўMagic123ФЪTHuman2.0єНSSHQКэѕЭјЇЙПµД¶ЁБї±ИЅПЎЈ(Ўь ±нКѕФЅёЯФЅєГЈ¬Ўэ ±нКѕФЅµНФЅєГЎЈЈ©

±н2 ОЮ·ґПтКУНјєПіЙ(w/o back)ЎўОЮїЙјыРФёРЦЄ patch Т»ЦВРФЛрК§(w/o VPC)єН THuman2.0 КэѕЭјЇЙПµДНкХыДЈРНЦ®јдµД±ИЅПЎЈ(Ўь ±нКѕФЅёЯФЅєГЈ¬Ўэ ±нКѕФЅµНФЅєГЎЈЈ©
ѕЦПЮРФ
Йо¶ИєНОД±ѕМхјю·ґПтКУНјєПіЙЈ¬ТФј°їЙјыРФёРЦЄµД patch Т»ЦВРФЛрК§Ј¬К№ОТГЗДЬ№»КµПЦѕЯУРТ»ЦВОЖАнµДПФЦшЧФУЙКУНјИЛМедЦИѕЎЈµ«КЗЈ¬УРТ»Р©ПЮЦЖЎЈ
- ОТГЗОЮ·ЁЙъіЙ·ЗіЈБоИЛУЎПуЙоїМµДёЯЦКБїјёєОНјРОЎЈЙъіЙµДНшёсФЪКЦєНЅЕЗшУт±нПЦіцґЦІЪµДјёєОРОЧґЎЈґЛНвЈ¬Из№ыґЦЅЧ¶ОІъЙъ°јЗшУт»тПФЦшІ»ХэИ·µДЧЛКЖµДјёєОРОЧґЈ¬ПёЅЧ¶ОНшёсПё»ЇІ»ДЬід·ЦІ№іҐХвР©ґнОуЎЈ
- ЛдИ»ІаГжєНІ»їЙјыЗшУт±нПЦіцСХЙ«Т»ЦВµДФ¤ІвЈ¬µ«ЛьГЗµДЦКБїІ»ИзЗ°КУНјєНєуКУНјёЯЈ¬ЛьГЗЕј¶ы»б°ьє¬Т»Р©ФлЙщЎЈ
- Ул NeRF АаЛЖЈ¬ОТГЗМбіцµД·Ѕ·ЁКЗФЪМШ¶ЁУЪИЛµДЙиЦГЦРЅшРРСµБ·µДЈ¬ХвРиТЄі¬№эТ»РЎК±ІЕДЬґпµЅСµБ·ЎЈ
ЅбВЫ
ФЪ±ѕОДЦРЈ¬ОТГЗЅйЙЬБЛТ»ЦЦУГУЪµҐ·щНјПсЧФУЙКУНј 3D ИЛМедЦИѕµДРВїтјЬЎЈОТГЗМбіцБЛТ»ёцОЖАнТ»ЦВєНёЯ±ЈХж·ґПтКУНјєПіЙДЈїйЈ¬ёГДЈїйУлКдИлІОїјНјПсєЬєГµШ¶ФЖлЎЈМбіцБЛѕЯУРїЙјыРФёРЦЄpatchТ»ЦВРФЛрК§µДОЖАнУіЙдДЈїйЈ¬УГУЪІаГжєНІ»їЙјыЗшУтРЮёґЎЈФЪTHuman2.0єНSSHQЙПµДКµСй±нГчЈ¬ёГДЈРНФЪЧФУЙКУЅЗНјПсєПіЙ·ЅГжґпµЅБЛЧоПИЅшµДРФДЬЎЈ
±ѕОД·ЦПнЧФ ГЅїу№¤і§ ОўРЕ№«ЦЪєЕЈ¬З°НщІйїґ
ИзУРЗЦИЁЈ¬ЗлБЄПµ cloudcommunity@tencent.com ЙѕіэЎЈ
±ѕОДІОУл?МЪС¶ФЖЧФГЅМе·ЦПнјЖ»®? Ј¬»¶УИИ°®РґЧчµДДгТ»ЖрІОУлЈЎ