985学历真好用,一面再差也不挂

接下来,继续给大家分享一个《Java 面试指南-字节跳动面经同学 7》的面试原题,来看看字节面试官都喜欢问哪些问题,好做到知彼知己百战不殆。

内容较长,建议正在冲刺 24 届春招和 25 届暑期实习、秋招的同学先收藏起来,面试的时候大概率会碰到,我会尽量用通俗易懂+手绘图的方式,让天下所有的面渣都能逆袭 ?
字节面经(详细)
有了解过布隆过滤器吗?
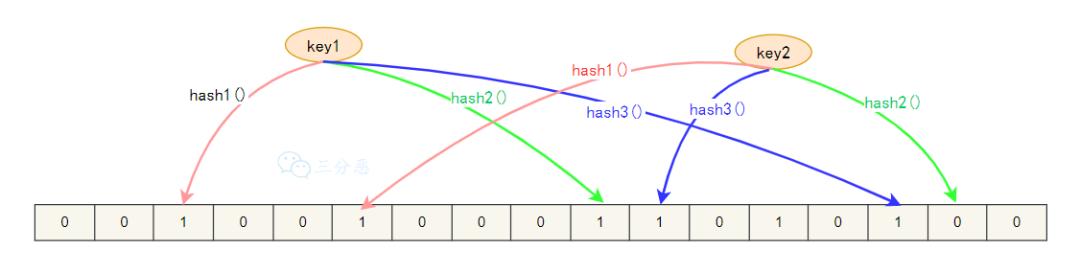
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,用于快速检查一个元素是否存在于一个集合中。
布隆过滤器由一个长度为 m 的位数组和 k 个哈希函数组成。
- 开始时,布隆过滤器的每个位都被设置为 0。
- 当一个元素被添加到过滤器中时,它会被 k 个哈希函数分别计算得到 k 个位置,然后将位数组中对应的位设置为 1。
- 当检查一个元素是否存在于过滤器中时,同样使用 k 个哈希函数计算位置,如果任一位置的位为 0,则该元素肯定不在过滤器中;如果所有位置的位都为 1,则该元素可能在过滤器中。
三分恶面渣逆袭:布隆过滤器
因为布隆过滤器占用的内存空间非常小,所以查询效率也非常高,所以在 Redis 缓存中,使用布隆过滤器可以快速判断请求的数据是否在缓存中。
但是布隆过滤器也有一定的缺点,因为是通过哈希函数计算的,所以存在哈希冲突的问题,可能会导致误判。
有了解过 MQ 吗?
消息队列(Message Queue, MQ)是一种非常重要的中间件技术,广泛应用于分布式系统中,以提高系统的可用性、解耦能力和异步通信效率。
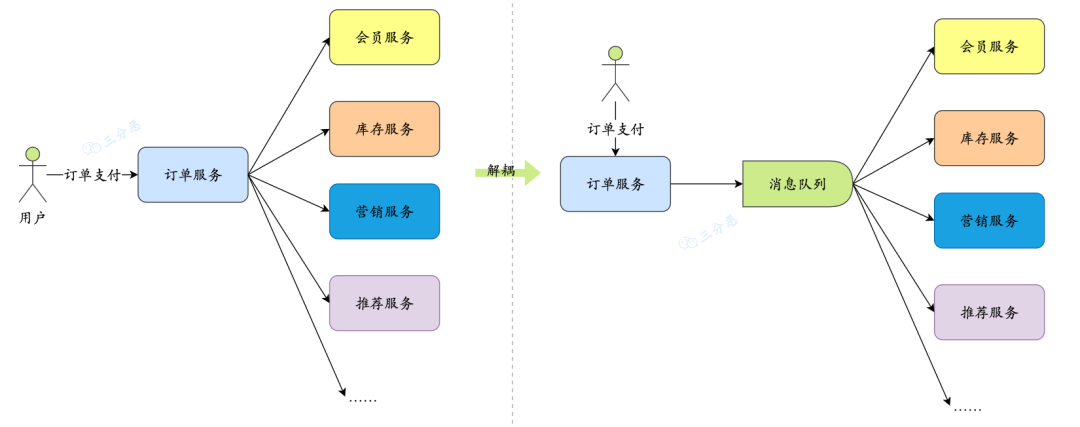
①、解耦
生产者将消息发生到队列,消费者从队列中取出消息,这样一来,生产者和消费者之间就不需要直接通信,生产者只管生产消息,消费者只管消费消息,这样就实现了解耦。
三分恶面渣逆袭:消息队列解耦
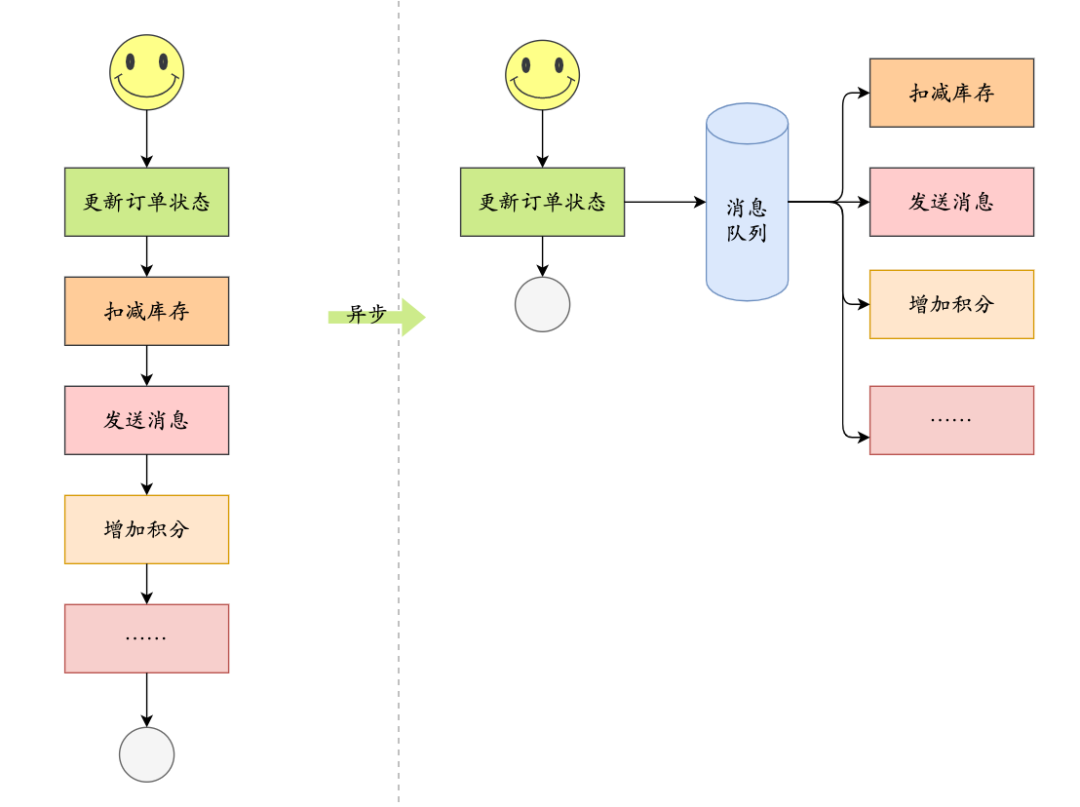
②、异步:
系统可以将那些耗时的任务放在消息队列中异步处理,从而快速响应用户的请求。
三分恶面渣逆袭:消息队列异步
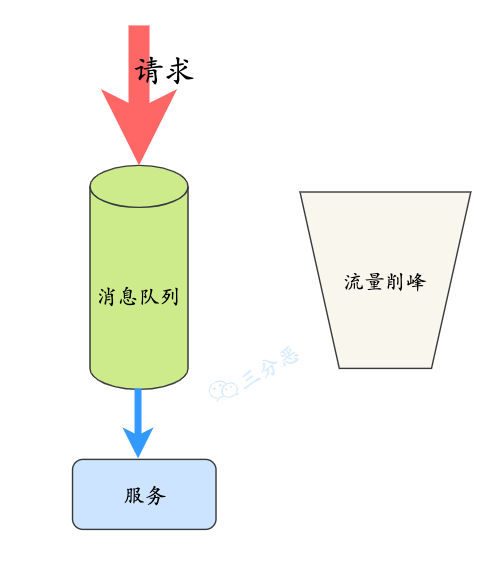
③、削峰:
在处理大量请求时,消息队列可以起到缓冲的作用,这样就能抗住短时间的大流量了。
三分恶面渣逆袭:消息队列削峰
讲一下数据准确性高是怎么保证的?
在金融计算中,保证数据准确性有两种方案,一种使用 BigDecimal,一种将浮点数转换为整数 int 进行计算。
肯定不能使用 float 和 double 类型,它们无法避免浮点数运算中常见的精度问题,因为这些数据类型采用二进制浮点数来表示,无法准确地表示,例如 0.1。
BigDecimal num1 = new BigDecimal("0.1");
BigDecimal num2 = new BigDecimal("0.2");
BigDecimal sum = num1.add(num2);
System.out.println("Sum of 0.1 and 0.2 using BigDecimal: " + sum); // 输出 0.3,精确计算
在处理小额支付或计算时,通过转换为较小的货币单位(如分),这样不仅提高了运算速度,还保证了计算的准确性。
int priceInCents = 199; // 商品价格199分
int quantity = 3;
int totalInCents = priceInCents * quantity; // 计算总价
System.out.println("Total price in cents: " + totalInCents); // 输出597分
讲一下为什么引入线程池?
线程池,简单来说,就是一个管理线程的池子。
三分恶面渣逆袭:管理线程的池子
①、频繁地创建和销毁线程会消耗系统资源,线程池能够复用已创建的线程。
②、提高响应速度,当任务到达时,任务可以不需要等待线程创建就立即执行。
③、线程池支持定时执行、周期性执行、单线程执行和并发数控制等功能。
线程池核心线程数你是怎么规划的,过程是怎么考量的?
首先,我会分析线程池中执行的任务类型是 CPU 密集型还是 IO 密集型?
①、对于 CPU 密集型任务,我的目标是尽量减少线程上下文切换,以优化 CPU 使用率。一般来说,核心线程数设置为处理器的核心数或核心数加一(以备不时之需,如某些线程因等待系统资源而阻塞时)是较理想的选择。
②、对于 IO 密集型任务,由于线程经常处于等待状态(等待 IO 操作完成),可以设置更多的线程来提高并发性(2 倍),从而增加 CPU 利用率。

常见线程池参数配置方案-来源美团技术博客
核心数可以通过 Java 的Runtime.getRuntime().availableProcessors()方法获取。
此外,每个线程都会占用一定的内存,因此我需要确保线程池的规模不会耗尽 JVM 内存,避免频繁的垃圾回收或内存溢出。
最后,我会根据业务需求和系统资源来调整线程池的参数,比如核心线程数、最大线程数、非核心线程的空闲存活时间、任务队列容量等。
ThreadPoolExecutor executor = new ThreadPoolExecutor(
cores, // 核心线程数设置为CPU核心数
cores * 2, // 最大线程数为核心数的两倍
60L, TimeUnit.SECONDS, // 非核心线程的空闲存活时间
new LinkedBlockingQueue<>(100) // 任务队列容量
);
线程可以被多核调度吗?
当然可以,在现代操作系统和多核处理器的环境中,线程的调度和管理是操作系统内核的重要职责之一。
操作系统的调度器负责将线程分配给可用的 CPU 核心,从而实现并行处理。
多核处理器提供了并行执行多个线程的能力。每个核心可以独立执行一个或多个线程,操作系统的任务调度器会根据策略和算法,如优先级调度、轮转调度等,决定哪个线程何时在哪个核心上运行。
讲一下为什么要用 Redis 去存权限列表?
Redis 最常见的用途就是作为缓存,由于所有数据都存储在内存中,所以 Redis 的读写速度非常快,远超基于磁盘存储的数据库。使用 Redis 缓存可以极大地提高应用的响应速度和吞吐量。
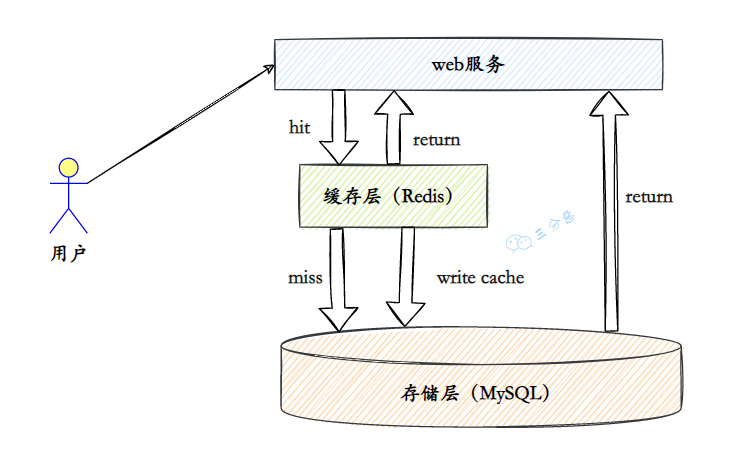
三分恶面渣逆袭:Redis缓存
权限列表几乎配置过一次后就很少改动,非常适合使用 Redis 来缓存。
Redis 宕机会不会对权限系统有影响?
会有影响,Redis 宕机通常会和缓存雪崩关联起来,缓存雪崩是指在某一个时间点,由于大量的缓存数据同时过期或缓存服务器突然宕机了,导致所有的请求都落到了数据库上(比如 MySQL),从而对数据库造成巨大压力,甚至导致数据库崩溃的现象。
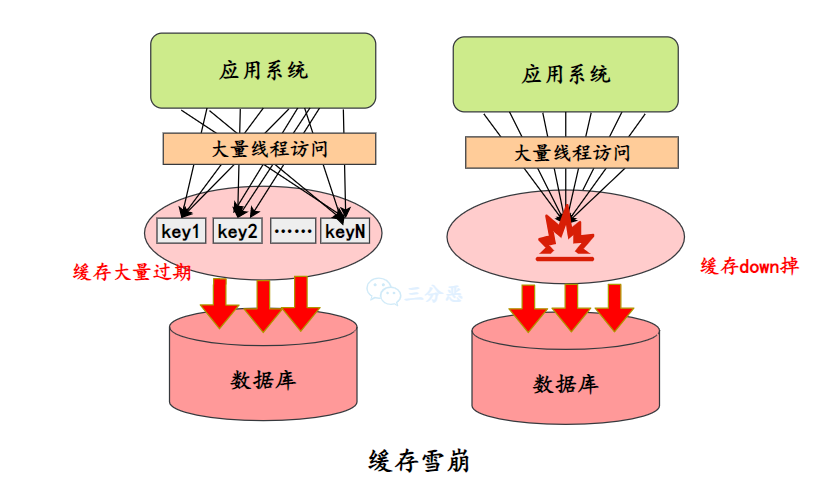
三分恶面渣逆袭:缓存雪崩
在技术派实战项目中,我们采用了多级缓存的策略,其中就包括使用本地缓存 Guava Cache 和 Caffeine 来作为二级缓存,在 Redis 出现问题时,系统会自动切换到本地缓存。
这个过程称为“降级”,意味着系统在失去优先级高的资源时仍能继续提供服务。
技术派教程
当从 Redis 获取数据失败时,尝试从本地缓存读取数据。
LoadingCache<String, UserPermissions> permissionsCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(this::loadPermissionsFromRedis);
public UserPermissions loadPermissionsFromRedis(String userId) {
try {
return redisClient.getPermissions(userId);
} catch (Exception ex) {
// Redis 异常处理,尝试从本地缓存获取
return permissionsCache.getIfPresent(userId);
}
}
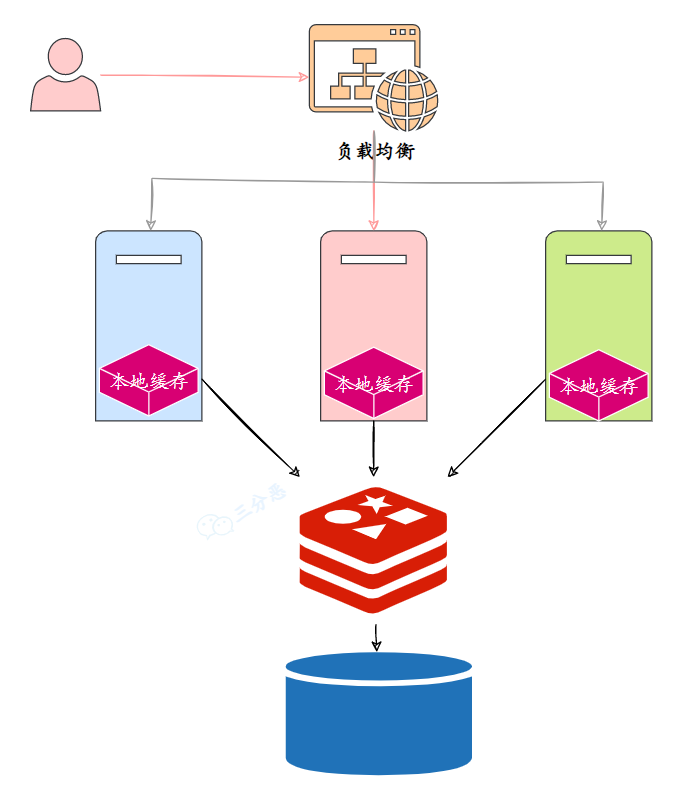
怎么保证二级缓存和 Redis 缓存的数据一致性?
在技术派实战项目中,就采用了本地缓存 Caffeine + Redis 缓存的策略。
三分恶面渣逆袭:延时双删
当数据库发生变化时,我们直接删除 Redis 缓存中的 key 就可以了,因为下一次请求会将数据库同步到 Redis 缓存中(如果没有二级缓存)。
三分恶面渣逆袭:本地缓存/分布式缓存保持一致
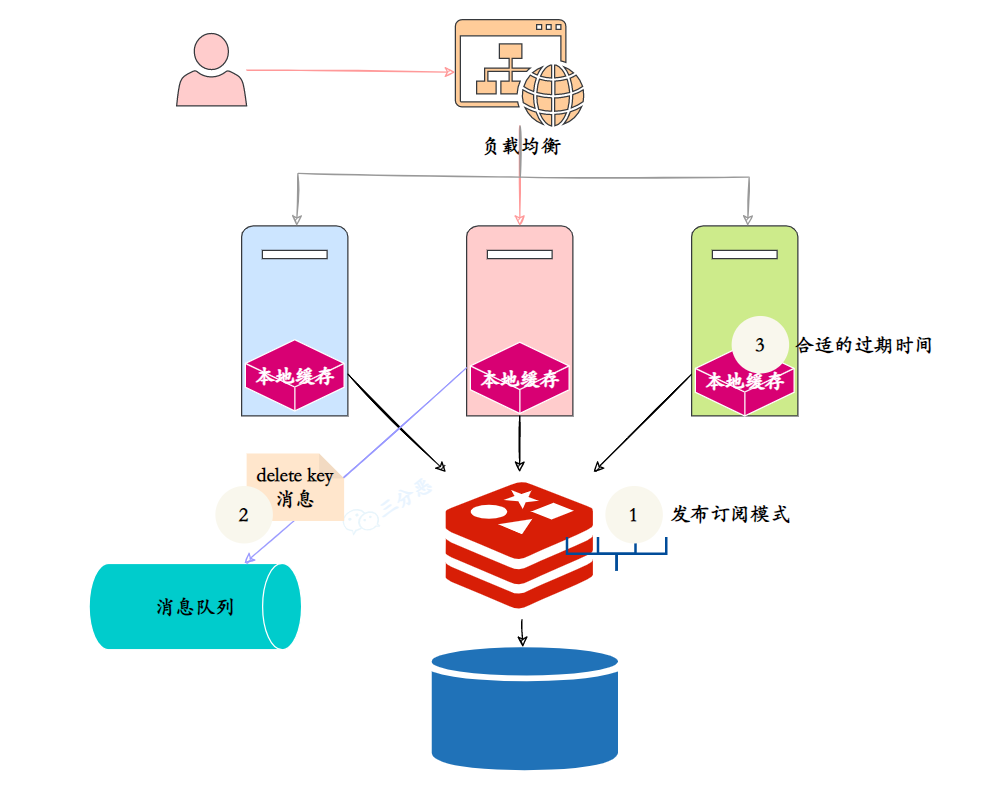
那为了保证本地缓存和 Redis 缓存的一致性,我们可以采用的策略有:
①、设置本地缓存的过期时间,这是最简单也是最直接的方法,当本地缓存过期时,就从 Redis 缓存中同步。
②、使用 Redis 的 Pub/Sub 机制,当 Redis 缓存发生变化时,发布一个消息,本地缓存订阅这个消息,然后删除对应的本地缓存。
③、Redis 缓存发生变化时,引入消息队列,比如 RocketMQ、RabbitMQ 去更新本地缓存。
说一下 Redis 雪崩、穿透、击穿等场景的解决方案
缓存穿透、缓存击穿和缓存雪崩是指在使用 Redis 做为缓存时可能遇到的三种问题。
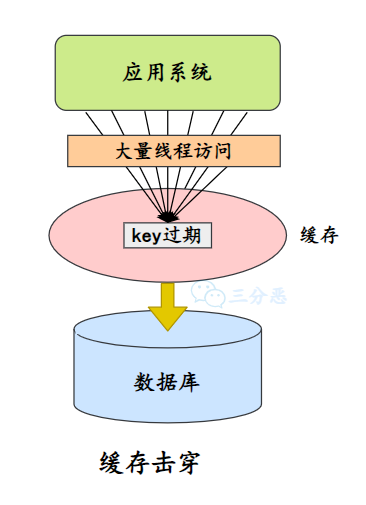
什么是缓存击穿?
缓存击穿是指某一个或少数几个数据被高频访问,当这些数据在缓存中过期的那一刻,大量请求就会直接到达数据库,导致数据库瞬间压力过大。
三分恶面渣逆袭:缓存击穿
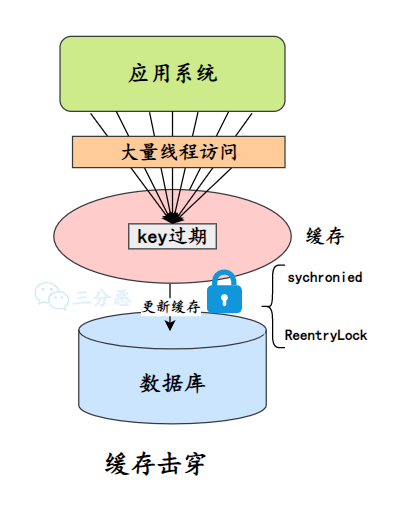
解决?案:
①、加锁更新,?如请求查询 A,发现缓存中没有,对 A 这个 key 加锁,同时去数据库查询数据,写?缓存,再返回给?户,这样后?的请求就可以从缓存中拿到数据了。
三分恶面渣逆袭:加锁更新
②、将过期时间组合写在 value 中,通过异步的?式不断的刷新过期时间,防?此类现象。
什么是缓存穿透?
缓存穿透是指查询不存在的数据,由于缓存没有命中(因为数据根本就不存在),请求每次都会穿过缓存去查询数据库。如果这种查询非常频繁,就会给数据库造成很大的压力。
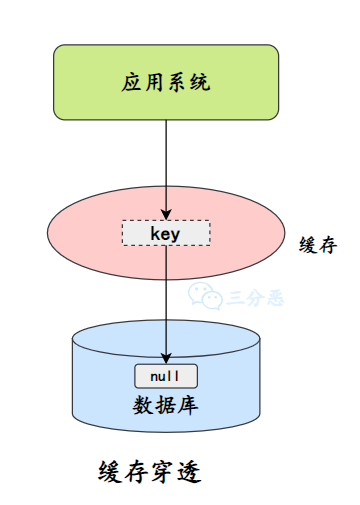
三分恶面渣逆袭:缓存穿透
缓存穿透意味着缓存失去了减轻数据压力的意义。
缓存穿透可能有两种原因:
- 自身业务代码问题
- 恶意攻击,爬虫造成空命中
它主要有两种解决办法:
①、缓存空值/默认值
一种方式是在数据库不命中之后,把一个空对象或者默认值保存到缓存,之后再访问这个数据,就会从缓存中获取,这样就保护了数据库。
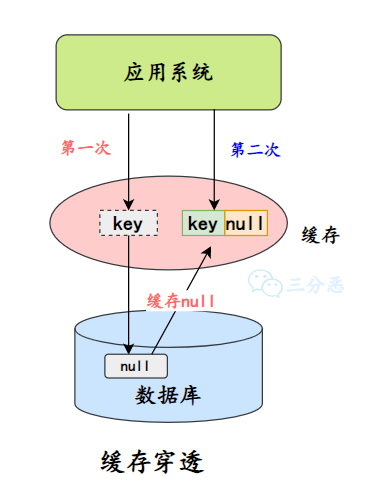
三分恶面渣逆袭:缓存空值/默认值
缓存空值有两大问题:
- 空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
- 缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。
例如过期时间设置为 5 分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致。
这时候可以利用消息队列或者其它异步方式清理缓存中的空对象。
②、布隆过滤器
除了缓存空对象,我们还可以在存储和缓存之前,加一个布隆过滤器,做一层过滤。
布隆过滤器里会保存数据是否存在,如果判断数据不不能再,就不会访问存储。
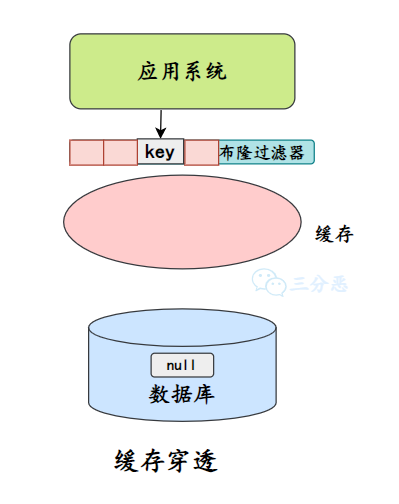
布隆过滤器
两种解决方案的对比:
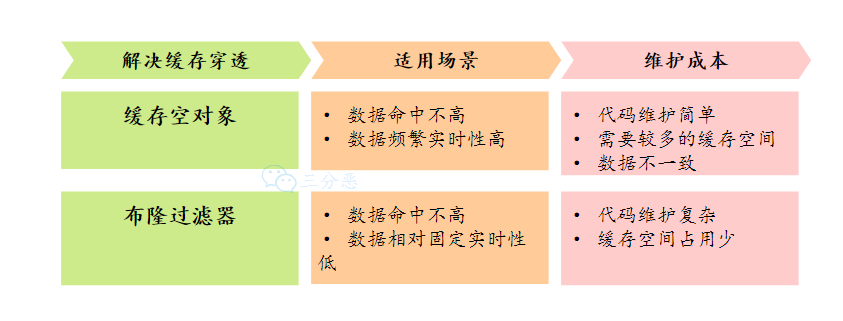
缓存空对象核布隆过滤器方案对比
什么是缓存雪崩?
缓存雪崩是指在某一个时间点,由于大量的缓存数据同时过期或缓存服务器突然宕机了,导致所有的请求都落到了数据库上(比如 MySQL),从而对数据库造成巨大压力,甚至导致数据库崩溃的现象。
总之就是,崩了,崩的非常严重,就叫雪崩了(电影电视里应该看到过,非常夸张)。
三分恶面渣逆袭:缓存雪崩
如何解决缓存雪崩呢?
第一种:提高缓存可用性
01、集群部署:采用分布式缓存而不是单一缓存服务器,可以降低单点故障的风险。即使某个缓存节点发生故障,其他节点仍然可以提供服务,从而避免对数据库的大量直接访问。
可以利用 Redis Cluster。
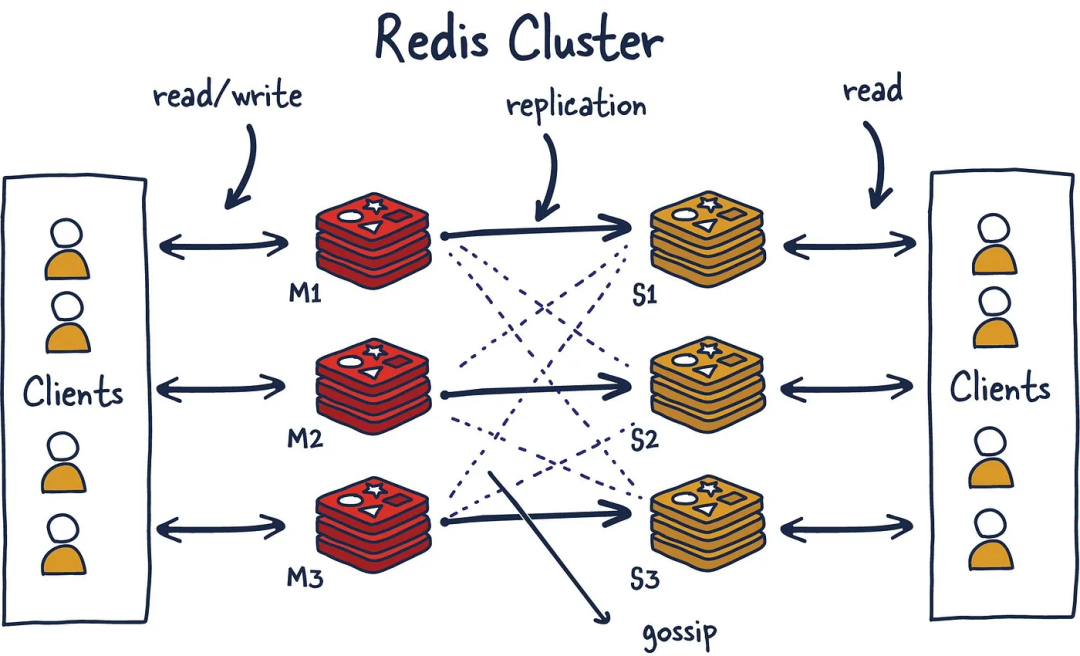
Rajat Pachauri:Redis Cluster
或者第三方集群方案 Codis。
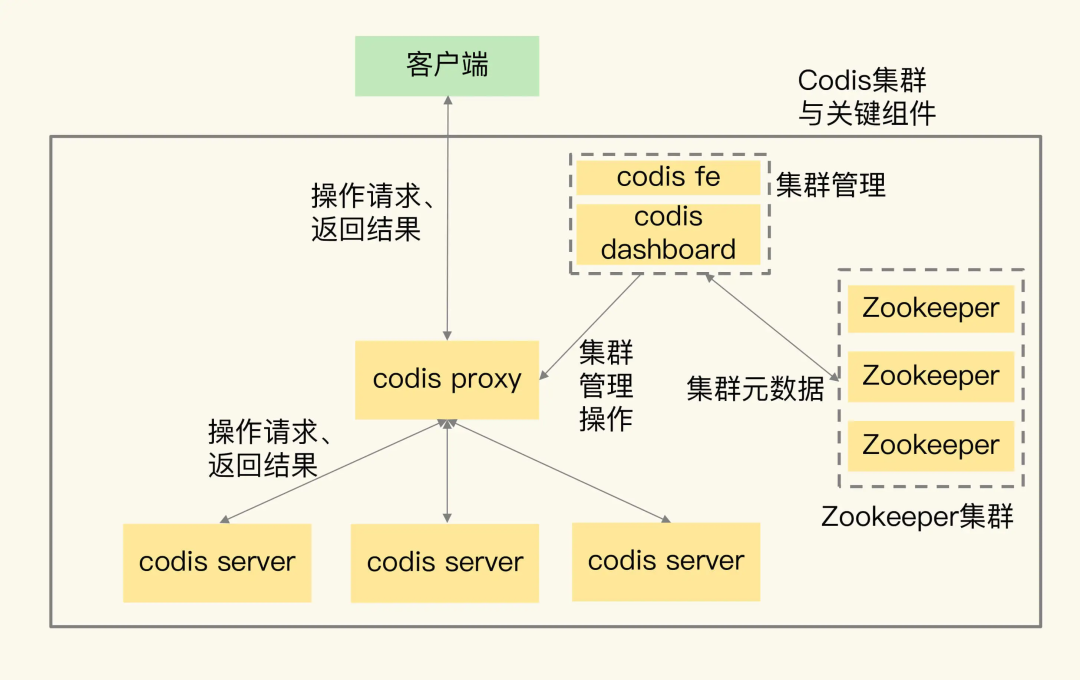
极客时间:Codis
第二种:过期时间
对于缓存数据,设置不同的过期时间,避免大量缓存数据同时过期。可以通过在原有过期时间的基础上添加一个随机值来实现,这样可以分散缓存过期时间,减少同一时间对数据库的访问压力。
第三种:限流和降级
通过设置合理的系统限流策略,如令牌桶或漏斗算法,来控制访问流量,防止在缓存失效时数据库被打垮。
此外,系统可以实现降级策略,在缓存雪崩或系统压力过大时,暂时关闭一些非核心服务,确保核心服务的正常运行。
参考链接
- 三分恶的面渣逆袭:https://javabetter.cn/sidebar/sanfene/nixi.html
- 二哥的 Java 进阶之路:https://javabetter.cn