华为又招一名天才少年。。。
华为又招一名天才少年。。。

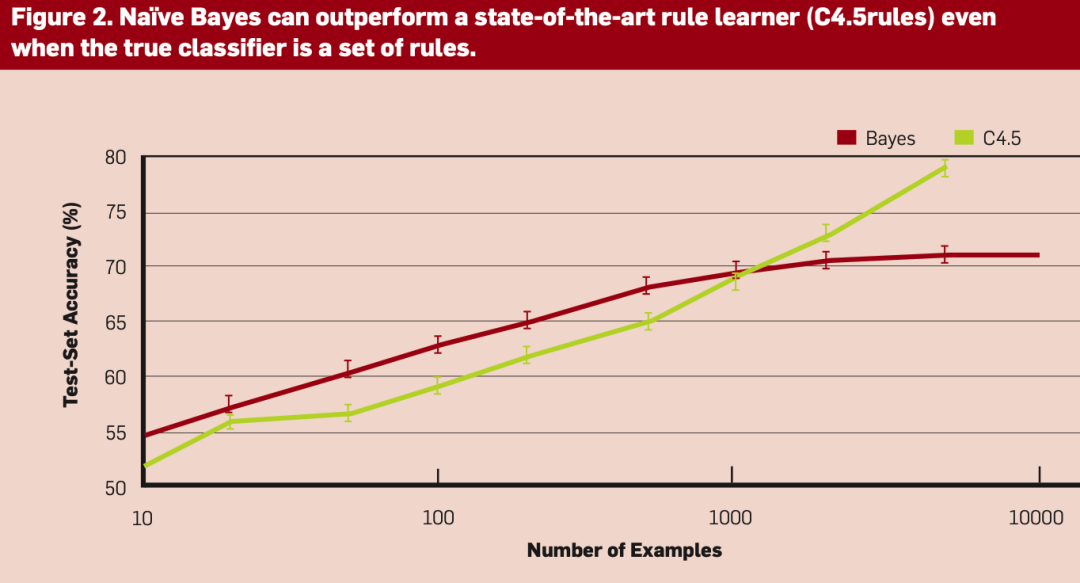
A Few Useful Things to Know About Machine Learning
这篇论文的主要贡献 可能包括但不限于以下几点:
- 机器学习实践的启示:提供了机器学习项目实施过程中的实用建议和最佳实践。
- 通用误区辟谣:明确了一系列新手和有时即使是经验丰富的从业者也可能落入的误区。
- 实践与理论的桥梁:尝试将机器学习理论与实际应用相结合,以加深读者对算法背后直觉的理解。
- 案例研究:通过分析特定案例来展示如何在现实世界的问题中应用这些原则和技巧。
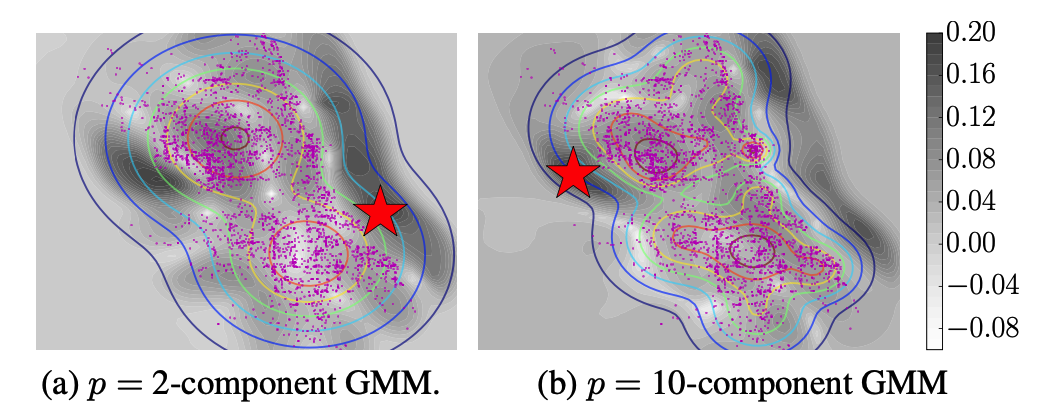
A Linear-Time Kernel Goodness-of-Fit Test
在机器学习和统计学中,经常需要评估样本数据是否来自于某个已知分布。传统的方法往往需要在非常大的数据集上进行计算,导致计算成本高昂,尤其是在高维数据的情况下。为了解决这个问题,本文提出了一种线性时间复杂度的核拟合度检验方法,可以有效地在大规模数据上进行检验。
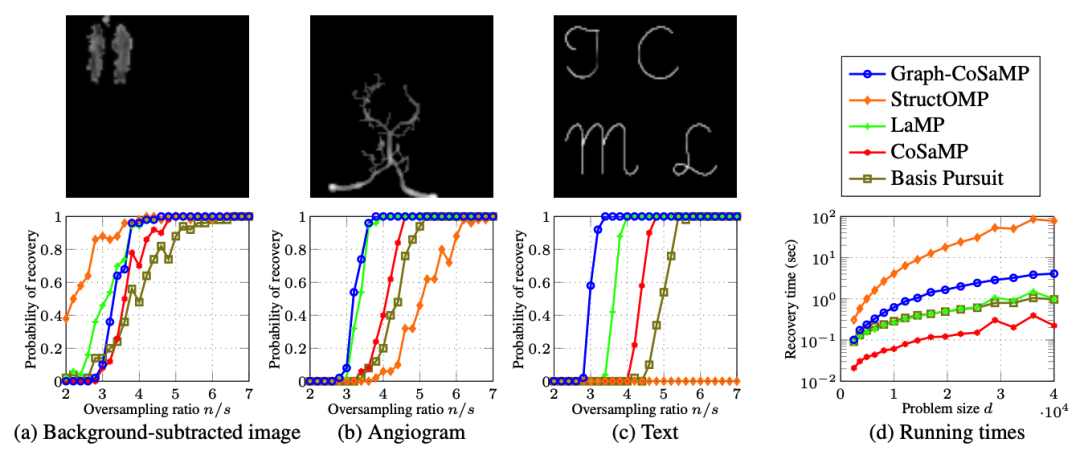
A Nearly-Linear Time Framework for Graph-Structured Sparsity
大规模图数据在许多领域中都是普遍存在的,如社交网络、互联网和生物信息学等。图结构稀疏性是指在大规模图中存在许多局部稀疏的子图结构,这些结构在数据分析和任务建模中具有重要的作用。传统的处理方法往往在大规模图上面临计算和存储的挑战。因此,本文提出了一种近线性时间复杂度的图结构稀疏性框架,以解决这一问题。
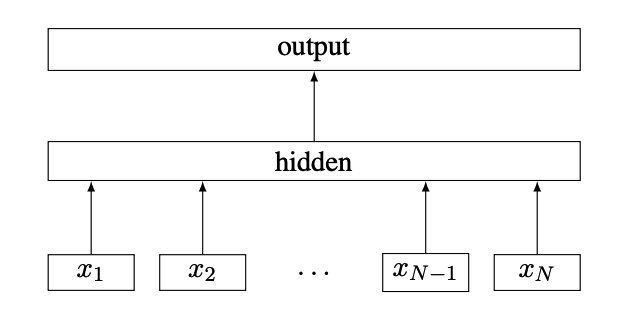
Bag of Tricks for Efficient Text Classification
这篇论文是由Joulin, Armand, et al.于2016年发表在ACL(Association for Computational Linguistics)上的。它的主要内容是介绍了一系列用于提高文本分类效率的技巧,这些技巧可以在大规模文本数据集上提高分类模型的性能并减少计算资源的使用。
文本分类是自然语言处理领域的重要任务,涵盖了许多应用领域,如情感分析、垃圾邮件过滤和文档归档等。然而,随着数据规模的不断增长,传统的文本分类方法面临着计算和存储资源消耗的挑战。因此,本文提出了一系列“技巧”,旨在提高文本分类的效率,并且保持或提升分类模型的性能。
Bag of Tricks for Image Classification with Convolutional Neural Networks
这篇论文是由Tianyu Guo, Qingyao Wu, Sheng Tang, and Yunhe Wang于2019年发表在CVPR(Computer Vision and Pattern Recognition)上的。它的主要内容是介绍了一系列用于提高使用卷积神经网络(CNN)进行图像分类的技巧,这些技巧可以提高模型的性能并减少训练时间。
随着深度学习的发展,卷积神经网络已经成为图像分类任务的主要工具。然而,训练深度神经网络仍然需要大量的计算资源和时间。为了解决这一问题,本文提出了一系列“技巧”,旨在提高CNN模型的训练速度和性能。
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
这篇论文是由Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Raetsch, Sylvain Gelly, Bernhard Sch?lkopf于2019年发表在ICML(International Conference on Machine Learning)上的。它的主要内容是对无监督学习中分解表示的常见假设进行挑战,并提出了一种新的方法来更好地学习分解表示。
在机器学习领域,无监督学习的目标是从数据中学习到有用的表示,而不需要标签信息。分解表示是无监督学习中的一种重要概念,它将数据表示为多个相互独立的因素,从而使得这些因素更容易理解和操作。然而,现有的方法通常依赖于一些假设,例如独立同分布(IID)数据假设等。这篇论文旨在挑战这些常见假设,并提出一种新的方法来更好地学习分解表示。
