解释选择性视觉注意相关的广泛经验现象,视觉识别的自由能例子拆解
解释选择性视觉注意相关的广泛经验现象,视觉识别的自由能例子拆解

Excitatory versus inhibitory feedback in Bayesian formulations of scene construction
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6544897/
相关自由能模型:

Abstract
选择性注意识别模型(SAIM selective attention for identification model)是选择性视觉注意的既定模型。 SAIM 使用并行分布式处理 (PDP parallel distributed processing ) 范例在具有多个对象的场景中实现平移不变对象识别。在这里,我们证明 SAIM 可以表述为贝叶斯推理。至关重要的是,SAIM 使用兴奋性反馈将自上而下的信息(即对象知识)与自下而上的感官信息结合起来。相比之下,贝叶斯推理的预测编码实现使用抑制反馈。通过将 SAIM 制定为预测编码方案,我们创建了使用抑制反馈的 SAIM 新版本。模拟研究表明,两种类型的架构都可以重现由多个对象引起的响应时间成本 正如视觉搜索实验中所发现的那样。然而,由于反馈的不同性质,两种 SAIM 方案对介导自上而下传入效应的微电路的基序做出了不同的预测。我们讨论经验(神经成像)方法来测试两种推理架构的预测。
关键词:选择性视觉注意,计算建模,主动推理,并行分布式处理,神经影像
1. Introduction
2003 年,Heinke 和 Humphreys [1] 引入了选择性注意识别模型 (SAIM),以对多个对象场景中的平移不变对象识别进行建模。 SAIM 的基本假设是大脑实现软约束满足,如并行分布式处理 (PDP) 范式 [2] 所实现的那样。这导致了具有反馈循环的神经网络架构,该反馈循环能够实现自上而下的信息(即关于存储在对象识别阶段的对象的知识)和自下而上的信息(即感觉信息)之间的交互。 Heinke 和 Humphreys 证明 SAIM 可以解释通常与选择性视觉注意相关的广泛经验现象,例如空间提示的影响、基于对象的选择以及识别多个对象的响应时间成本。此外,SAIM 可以解释选择性视觉注意的缺陷,例如视觉忽视、视觉消退以及知识对视觉忽视的影响。
简而言之,SAIM 认为许多“注意”现象可以解释为多个对象场景中对象识别(即感知推理)的新兴属性 In short, SAIM suggests that many ‘attentional’ phenomena can be explained as an emergent property of object identification (i.e. perceptual inference) in multiple object scenes。据我们所知,这种成功程度仍然是任何其他模式都无法比拟的。 Heinke 及其同事的后续工作[3?5] 证明 SAIM 的扩展可以重现视觉搜索实验的结果,处理自然彩色图像 [6] 和感知分组 [7]。最后,通过修改约束以反映动作可能性(即可供性),可以将可供性合并到多个对象场景中[8]。还值得注意的是,SAIM 的机制基于非线性动力学,其形式上类似于动态神经领域中使用的机制(例如[9?13])。后一个参考文献在当前上下文中特别相关,因为它考虑使用横向交互来设计神经动力学架构,以便在自上而下的预测下使用自下而上的识别来一次性学习视觉对象。这里的共同主题是对象识别中通用先验的动态实现;即,在任一时间只有一个对象(即获胜或选择的假设)可以引起感觉输入。这种基本先验通常是由神经元方案中的横向相互作用介导的。 SAIM 中隐含的赢者通吃 (WTA) 相互作用与神经场公式中的横向连接发挥着相同的作用。
超越BP,600样本96.6%准确率,hebbian learning 10篇最新论文
本文的目的是将 SAIM 与用于建模行动和感知的预测处理框架联系起来;即弗里斯顿等人的自由能原理。 (例如[14?17];参见[18,19])。初步检查表明,贝叶斯原理主张采用与 SAIM 所采用的计算架构类似的计算架构:两种架构都是分层的,并且都包含反馈循环。本文对这两种架构之间的关系进行了数学分析。简而言之,我们证明 SAIM 可以从第一原理(即自由能原理)导出。然而,与预测编码等方案中通常使用的模型相比,SAIM 假设了不同的“生成模型”。这种差异的一个重要结果是 SAIM 的反馈回路是兴奋性的,而预测编码方案会导致抑制性反馈回路(即从感觉输入中减去预测以形成预测误差)。为了便于直接比较这两种架构,我们推导出 SAIM 的新版本 (错误预测(EP)?SAIM )它使用预测编码中通常采用的生成模型。然后,我们提出比较这两种模型的刺激研究,并为未来(脑电图或功能磁共振成像)研究提供(定量)预测。简而言之,这项工作开发了一种形式主义来解决一个重要且长期存在的系统神经科学问题:大脑是否使用兴奋性或抑制性反馈将感觉信息与先验知识结合起来?
为了澄清这些论点,特别是对于那些不熟悉 SAIM 的人,我们首先介绍 SAIM 的稍微修改版本。为了强调有关反馈循环的对比假设,我们将这个版本称为兴奋性匹配 (EM)?SAIM。然后,我们复制了介绍 SAIM 的基础论文中的一项重要发现。通过模拟,我们展示了 EM?SAIM 在多个对象场景中执行对象识别的能力。此外,这些模拟表明 EM?SAIM 再现了众所周知的多对象成本;即,随着非目标对象数量的增加,检测目标对象所需的时间也随之增加。这一普遍存在的经验发现是 SAIM 的 WTA 机制的一个新兴特性。多对象成本的证据来自视觉搜索实验(例如[20];参见[21]的评论)。在这里,我们使用 SAIM 的 EM 版本重现这些结果。确定了该 EM 方案的有效性后,我们重新制定了 SAIM 中的软约束作为自由能最小化 产生预测误差(PE)?SAIM。然后,我们使用相同的(合成)刺激重复模拟研究,以确定其与 EM?SAIM 相关的构造有效性。最后,我们使用神经元证据积累的经验测量(例如脑电图或功能磁共振成像)来比较和对比模拟结果,以确定信念更新的关键方面,这可以消除两个版本的歧义。本文报告的模拟研究的 MatLab 代码可以在 Github 存储库https://github.com/SAIM?models/EMvPE 中找到。
本文的目的并不是增进我们对选择性视觉注意本身的理解;例如,通过比较预测编码和 SAIM 注意力公式(例如[22,23])。相反,我们希望为实证工作奠定基础,以消除这些趋同公式之间的歧义(参见一般讨论)。最后,我们试图让没有数学背景的读者也能理解数学。
2. The excitatory matching (EM)-SAIM
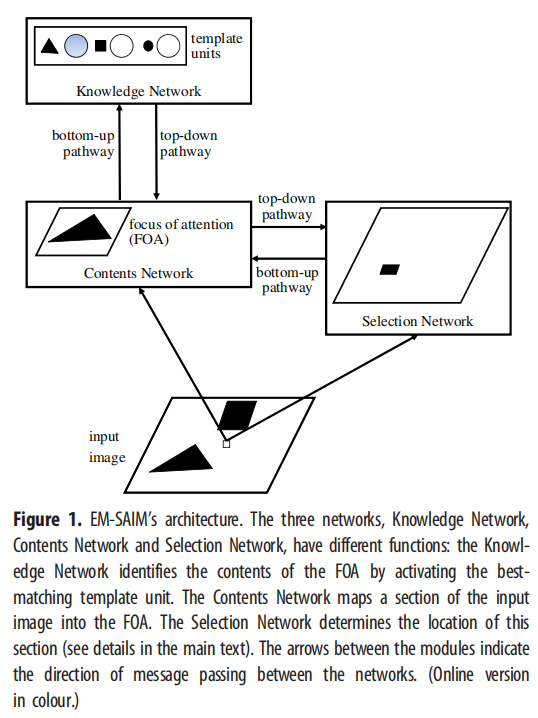
在介绍 EM?SAIM 的数学推导之前,我们先概述 EM?SAIM 架构(图 1;用于说明)。在考虑了数学细节之后,我们将重点介绍 EM?SAIM 与原始 SAIM 的不同之处。我们通过证明 EM?SAIM 可以重现多个对象成本来结束本节。
2.1. Overview
过将输入图像中的区域映射到“关注焦点”(FOA) 来选择对象(图 1)。映射是通过内容网络实现的并且是平移不变的。这意味着无论对象出现在输入场景中的哪个位置,它都可以映射到 FOA 中。选择网络决定了哪个区域输入图像被映射到 FOA 中。选择网络通过激活与输入图像中的位置相对应的层中的单元来识别该区域(图 1)。内容网络的输出被传递到知识网络。知识网络配备有存储已知(即可识别)对象的模板的模板单元。该网络通过简单的模板匹配来比较模板和内容网络的输入。给定模板匹配的结果,知识网络激活最佳匹配的模板单元。这反映了所选对象的身份 内容网络中的对象。
除了这些自下而上的路径之外,EM?SAIM还拥有自上而下的路径。请注意,这些自上而下的路径是由下面描述的软约束满足方法强制执行的。从知识网络到内容网络的自上而下的路径将模板的加权和添加到 FOA(兴奋性反馈)中的激活中。权重由模板单元的激活确定。换句话说,反馈引导 FOA 关注内容网络的内容。从内容网络到选择网络的自上而下的连接保证了内容网络与输入图像的相关性。相关的结果被输入选择网络。同样,就像从知识网络到内容网络的反馈一样,这种相关性依赖于兴奋性反馈。由于选择网络实现了 WTA 机制,因此该输入将选择网络的注意力引导到输入图像中与内容网络的内容最匹配的位置。
需要注意的是,EM?SAIM 并不能即时实现物体识别。相反,对象识别随着时间的推移而发展。最初(如果我们假设没有关于场景中的对象的预知),模板单元具有相同的激活;内容网络设置为模板单元的同等加权总和,并且选择网络在所有图像位置上具有相同的激活(即没有空间偏差)。随后,EM?SAIM 开始并行的选择过程和识别过程,最终收敛到一个点吸引子,其中没有单元改变其激活。此时,据说 EM?SAIM 已经选择并识别了一个物体。
2.2. Mathematical derivation
我们的 EM?SAIM 实现是基于 Hopfield 和 Tank [24] 引入的能量函数最小化方案。在该方案中,网络的期望输出用约束来表达;例如,模板匹配作为知识网络中对象识别的约束。然后,网络动力学可以表示为神经元输出活动 y 的能量函数 E(y) 的梯度下降。能量函数包括不同能量函数的混合,其中每个分量的最小值满足特定约束。这确保了网络动态实现某种形式的软约束满足。 EM?SAIM 的一般形式使用 Hopfield 和 Tank [24] 描述的梯度下降
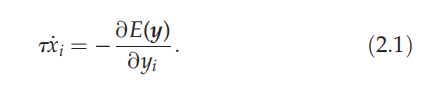

我在这;是第Ii 个神经元或神经元群体的输入。这种 WTA 能量函数会在神经元之间产生竞争,其中输入最大的神经元被激活,接近 1(即获胜单元),而所有剩余的神经元则趋向于 0。第一项对应于所有神经元活动的总和等于 1 的约束;而第二项(即输入项)意味着具有最大输入的神经元的响应是最大的约束。两者相加确保了 WTA 行为,其中 a 和 b对两个约束进行加权;允许任一约束占主导地位。接下来的 WTA 行为很好地说明了软约束满足。这种能量函数对于知识网络非常重要,其中最佳匹配模板由最高输入指示,对于选择网络也很重要,我们将在后面看到。同样重要的是要注意,输入项符号的变化会使 WTA 变成败者通吃,其中输入最小的神经元赢得竞争。该机制对于 PE-SAIM 很重要。
为了确保 EM-SAIM 满足其组成网络施加的所有约束,每个网络的能量函数被组合起来,为整个网络提供一个目标函数
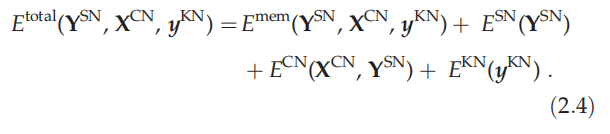
换句话说,每个网络都实现一个根据其独特的能量函数指定的约束,而每个神经元都试图最小化总能量函数:
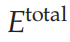
。这里,
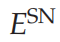
是选择网络的能量函数,
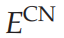
是内容网络的能量函数,
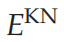
是知识网络的能量函数(即上标SN、CN和KN分别代表选择网络、内容网络和知识网络,分别)。
能量函数的参数
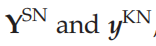
分别是选择网络和知识网络的输出,
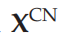
是内容网络的输出。这里使用 X 表明——与知识网络和选择网络相比——我们在内容网络中放弃了 sigmoid 函数。这是因为内容网络代表了连续有价值的感觉信号。另请注意内容网络和选择网络输出使用矩阵表示法,其中是二维矩阵。相比之下,知识网络的输出是一维向量。在下面的,我们将详细考虑每个单独的能量函数及其满足的约束。
2.2.1. Knowledge network
知识网络通过标量积实现基于模板的对象识别
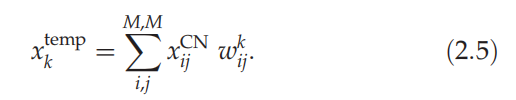

2.2.2. Contents network
内容网络接收来自 Sigma-pi 单元的输入(即调节性突触相互作用),该单元结合了选择网络和视野中的激活以实现平移不变映射
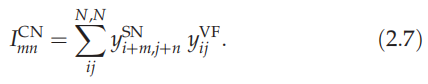
这里,N是输入图像的大小,而
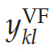
是输入图像。内容网络约束确保内容网络的输出单元反映了Sigma-pi单元的输出。
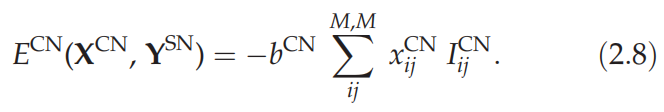
2.2.3. Selection network
选择网络实现了一个约束,确保只选择一个位置。在这里,我们使用了WTA能量函数的第一个术语。
我们对构成总能量的特定网络能量组成的描述到此结束。
为了模拟视觉输入的处理,使用等式(2.1)形式的梯度下降方案来最小化总能量。详细地说,我们使用了欧拉近似法,并添加了漂移扩散模型暗示的生物噪声(例如【25】)
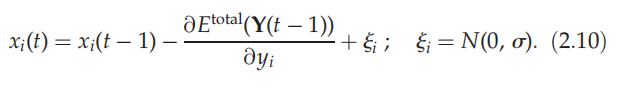

粗体字中的项(即方程(2.3)中的输入项)表示来自更高网络到更低网络的反馈;即来自知识网络到内容网络,以及从内容网络到选择网络。这些项是由梯度下降得出的,并表明反馈连接是软约束满足所必需的。至关重要的是,这些反馈连接构成了正向(即兴奋性)反馈(请参见表1以获取隐式消息传递和连接的电路图)。例如,内容网络中的响应
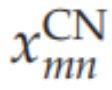
将遵循方程(2.12)中的梯度下降,并因此随着更高知识网络单元
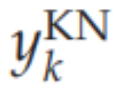
的活动而增加。类似地,选择网络单元
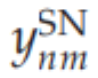
的响应随着来自内容网络
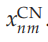
的下行投影源的增加而增加。
2.3. Comparing EM-SAIM with the original SAIM
EM-SAIM引入了两个变化,使其比原始实现更具生物学的合理性。第一个是包含布朗运动噪声。这不仅使EM-SAIM更具生物学合理性,而且使其能够模拟行为实验中常见的响应时间变化。第二个变化涉及反馈连接。在原始的SAIM中,来自知识网络的反馈直接传递到选择网络。在EM-SAIM中,知识网络现在投影到内容网络,而内容网络投影到选择网络。这个变化创建了一个更合理的架构,因为反馈倾向于针对输入脑区域(例如[26])。

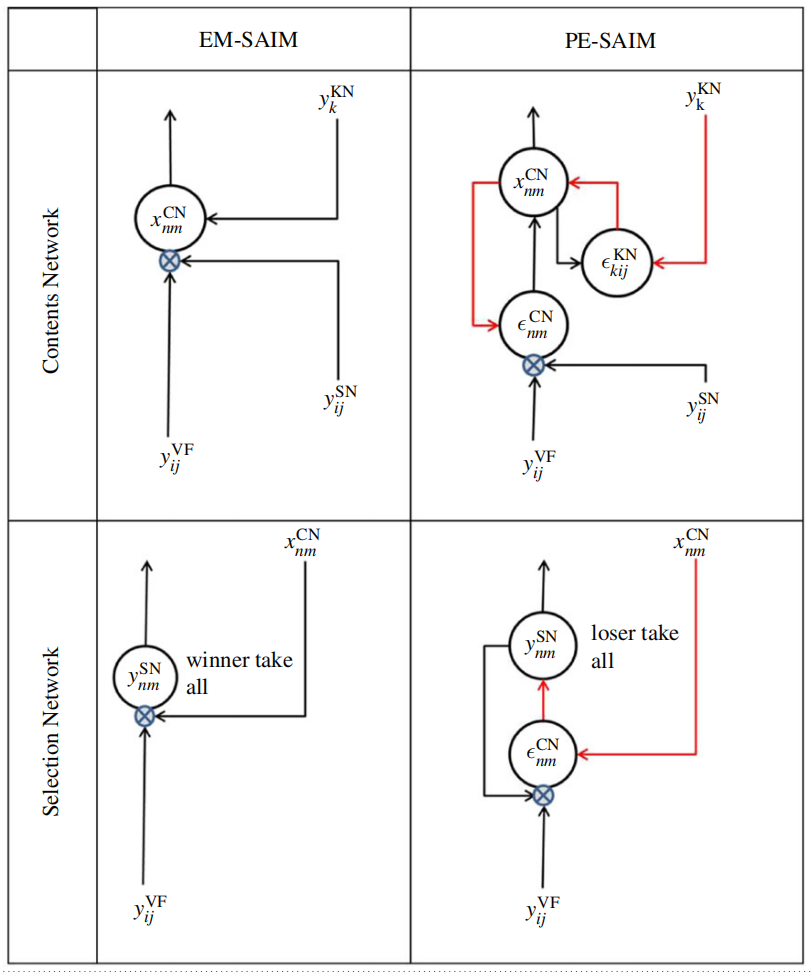
这种修订后的反馈架构保留了对选择过程的自上而下的调节,尽管以更间接的方式。要完全理解这个论点的神经生物学前提,值得注意的是,SAIM的网络可以与何路径和何路径相关联(详见[1]进行更详细的讨论)。根据这种解释,知识网络和内容网络对应于何路径(腹侧路径)中的脑区域,而选择网络对应于何路径(背侧路径)中的区域,即后部顶叶皮层。因此,如果知识网络和内容网络位于腹侧路径中,那么这两个网络之间的反馈连接更能反映已知的解剖连接(而不是像原始SAIM中那样反馈连接到选择网络)。
2.4. Simulation results
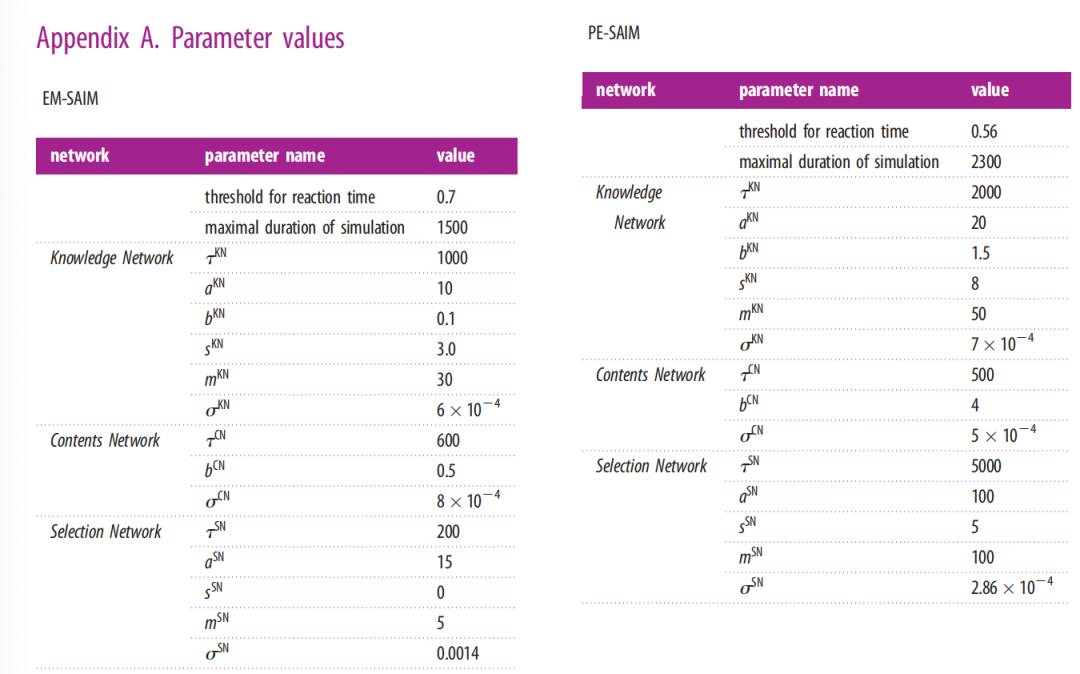
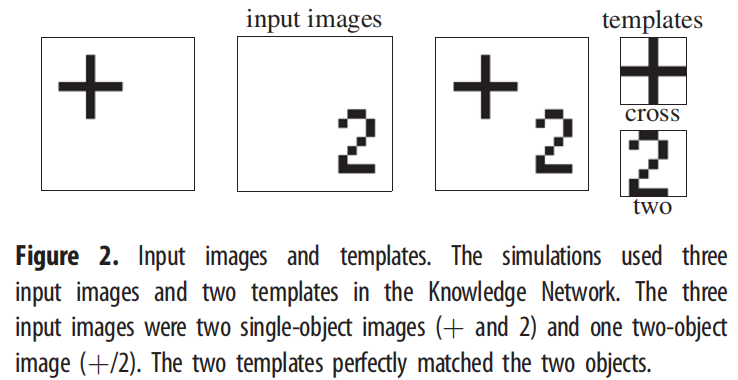
我们首先进行了验证模拟,以确保EM-SAIM能够复制Heinke&Humphreys [1]的研究中所报告的多个对象成本的反应时间模拟。与原始研究一样,我们使用了两个对象,2和?(十字)(见图2)。这些对象还构成了知识网络中的模板。通过测量模板单元通过阈值所需的时间步数来模拟反应时间(有关参数,请参见附录A)。多个对象成本是通过对具有一个对象(?或2)的输入图像的反应时间与具有两个对象(?和2)的输入图像的反应时间进行对比来模拟的。在实证实验中,如视觉搜索任务,多个对象成本是通过更多对象来证明的(例如[20];有关模拟研究,请参见[3])。然而,为了本文的目的,一个简单的设置足以表明EM-SAIM复制了SAIM的主要行为。图3显示了三个输入图像的典型模拟示例:?/2、单个2和单个?。
这些示例表明,EM-SAIM能够复制多对象成本。与原始的SAIM一样,EM-SAIM对?表现出自顶向下的偏向,因为组合模板与?的匹配要比与2的匹配更好。我们还进行了一项研究,对每个输入图像进行了20次模拟,以确定三种条件之间是否存在统计学上显著的差异(见图4)。我们对模拟结果应用了t检验,并发现?/2与单个?之间存在显著差异(t38 = 11.40; p < 0.001),以及?/2与单个2之间存在显著差异(t38 = 5.34; p < 0.001)(以及2与单个?之间存在显著差异(t38 = 27.85; p < 0.001))。至关重要的是,?/2的反应时间比单个?和单个2要慢。
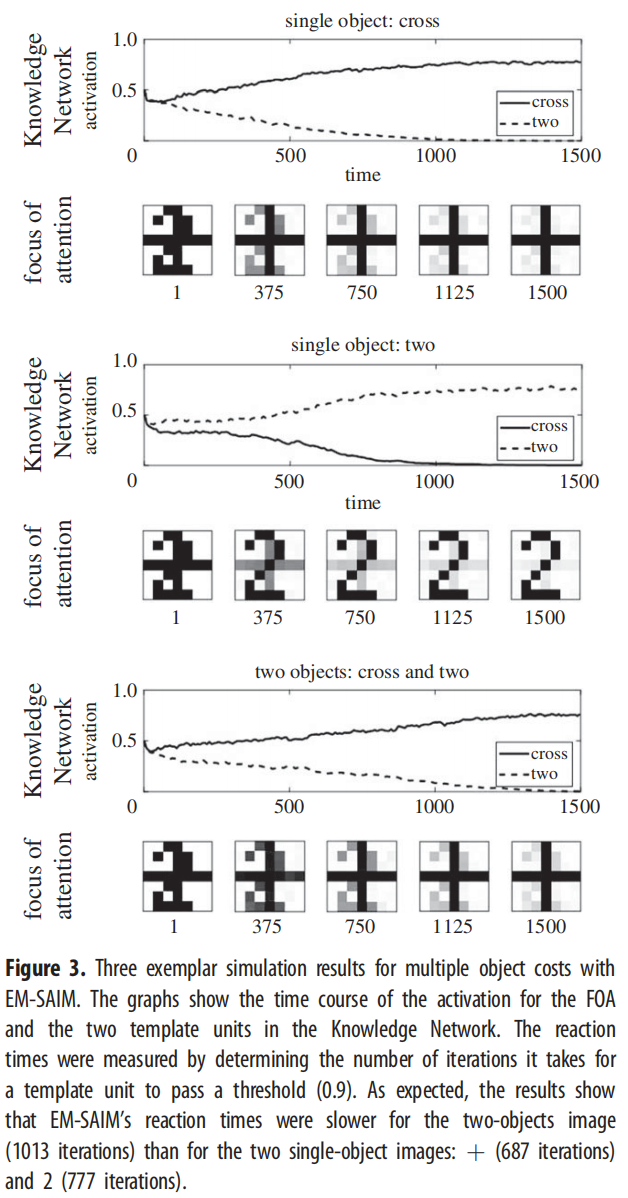
总之,这些模拟结果表明,EM-SAIM复制了原始SAIM模拟的关键结果。除了原始SAIM模拟之外,新版本(EM)还能够复制在与人类进行实验时发现的反应时间的自然变化。此外,尽管增加了神经元噪声,但40个单个刺激的模拟中没有一个出现错误,?/2的模拟总是识别出了十字。请注意,模拟的确切数值结果,例如反应时间的变化,取决于参数设置。然而,广泛的参数设置产生了本文所述的发现。我们将在PE-SAIM的讨论部分进一步讨论模型的数值评估问题。
2.5. Interpreting selective attention for identification model within the active inference framework
在本节中,我们考虑了PDP框架中视觉处理的上述表述与基于预测编码和贝叶斯大脑的当前表述之间的联系。简言之,我们将看到SAIM和近似贝叶斯推断都可以描述为最小化能量函数。贝叶斯表述中使用的特定能量函数对应于变分自由能(在机器学习中也称为“证据边界”)。变分自由能是数据和生成模型(即数据如何从原因生成的概率模型,例如视觉对象)的函数。接下来,我们将展示SAIM使用的能量函数可以解释为特定生成模型下的变分自由能。这意味着SAIM可以在特定的视觉数据生成模型下被表述为贝叶斯推断。此外,这意味着前一节描述的计算架构可以以正式的方式与贝叶斯方案中使用的架构进行比较。
将SAIM表述为变分自由能最小化比人们想象的要简单得多。自由能原理考虑了贝叶斯大脑假设(有关审查,请参阅[27])。根据自由能原理(与贝叶斯大脑假设一致),人们认为大脑使用生成模型来推断感觉信号的隐藏(即潜在)原因。这些模型被描述为“生成性”的,因为它们描述了潜在原因如何生成信号。在推理过程中,假定大脑通过最小化“自由能”来更新对潜在原因的表示(由后验概率密度编码)。这种信念更新、证据积累或推断过程可以用SAIM的对象识别来说明。
让我们假设对象识别的生成模型包括SAIM中使用的模板。因此,对于每个物理对象(例如数字二、十字等),模板代表了输入图像中感觉信号的潜在原因。给定这些感觉信号,最小化自由能产生每个模板的后验概率密度,反映了感觉信号由相应对象引起的概率。从这个角度来看,模板对应于对感觉信号潜在原因的先验信念,通过贝叶斯信念更新从感觉数据中恢复。这种信念更新可以表达为对变分自由能的梯度下降。
这里要注意的重要一点是,在推断过程中最小化的自由能是一个单一量(即后验概率密度和感觉输入的函数),由生成模型指定。换句话说,自由能是一个类似于SAIM总能量函数的全局客观函数,并且在两种方法中,能量必须被最小化。因此,SAIM实际上是自由能原理的一种实例。此外,通过对自由能泛函进行梯度下降来实现推断,优化后验分布(例如[16])。简而言之,SAIM的梯度下降在形式上与自由能原理一致。此外,人们可以将SAIM的软约束满足视为在某些先验信念下的概率推断的等价形式(即对生成视觉数据方式的约束)。
请注意,SAIM的推断过程并不产生不确定性的表示,而只是后验的点估计。在贝叶斯术语中,这相当于最大后验估计。从自由能原理的角度来看,SAIM反转了一个分层贝叶斯模型,其中内容网络、选择网络和知识网络编码了后验期望和分层(也称为经验)先验。有趣的是,SAIM中的WTA约束可以被视为执行一个先验信念,即一次只能有一个对象在一个地方。
在指出了SAIM的能量最小化方法与自由能原理之间的正式等价性之后,现在可以问:SAIM的基础生成模型是什么?在自由能方法中,概率生成模型通过一个Gibbs度量与能量相关联。

在这种情况下,来自知识网络的先验
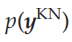
是一个完全的先验。
这些方程显示,SAIM的生成模型在形式上与预测编码中使用的模型有明显的区别,预测编码使用高斯先验以确保先验与近似(高斯)后验共轭(这在贝叶斯统计中被称为拉普拉斯假设)。在高斯假设下,上述似然和经验先验将具有二次形式。然而,很明显,SAIM中隐含的生成模型具有更丰富的形式。例如,在方程(2.18)和(2.20)中的完全先验表明,EM-SAIM的模型假设在选择和知识网络中具有稀疏的潜在原因的概率密度。这是因为当这些先验能量最小化时,其中一个潜在的(非负)原因为一,其余为零。这种非高斯先验在LASSO(最小绝对收缩和选择算子)回归分析中常被使用(见讨论部分)。我们现在将更详细地研究这种形式,并详细说明SAIM的一个变种,其经验先验可以用预测误差的平方来表示。
3. The PE-SAIM
在前一节中,我们根据一个特定的生成模型,将SAIM表述为自由能最小化,该模型包含非高斯经验先验,与通常假设高斯形式的预测编码模型形成对比。在本节中,我们通过采用生成模型中的高斯假设(称为PE-SAIM)来修改EM-SAIM,并检查这个新版本是否能够复制上述的多对象成本发现。在高斯假设下,自由能成分可以表达为预测误差的平方。在SAIM中,这适用于两个层次:内容网络,它通过Sigma-pi单元调制选择网络来预测输入图像中的激活。

如前所述,使用
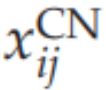
(而不是
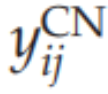
反映了内容网络使用线性输出函数的事实。最后,需要注意的是,在PE-SAIM中,两个WTA先验(即softmax)变成了一个loser-take-all(即softmin) - 因为选择网络和知识网络需要选择最佳的预测器;即最小化预测误差。为了最小化自由能,我们再次使用了欧拉方案进行梯度下降,保留了与EM-SAIM相同的生物噪声。可以通过直接计算从上述表达式中导出每个网络或层次的所需梯度:

这些方程可以映射到如表1所示的神经架构上。表1中神经信息传递的总结说明了为什么可以将EM-SAIM视为由兴奋性反馈介导,而PE-SAIM则使用抑制性反馈通过预测误差单元实现去抑制 illustrate why EM-SAIM can be seen as being mediated by excitatory feedback, while PE-SAIM uses inhibitory feedback to implement a disinhibition via prediction error units 。例如,
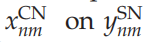
的影响由两个抑制连接(通过
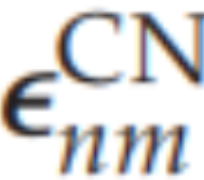
)介导;即抑制的抑制。与EM-SAIM方程中的情况类似,我们在指示网络之间的反馈项时使用了粗体。然而,与EM-SAIM相比,反馈项是由预测误差(即方程(3.1)和(3.2)中的

项)介导的,这些误差实现了高层对低层的抑制(即负影响)。这种抑制性反馈是由预测误差的形成所要求的。例如,方程(3.4)隐含的梯度下降意味着当预测误差
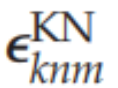
减少时,内容网络
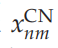
的单元增加。简而言之,通过引入预测误差,我们有效地改变了层次结构中连续级之间耦合的符号。
这种架构与通用的预测编码方案一致,在预测编码层次结构中的任何级别上,预测编码层次结构中的预测误差通过减去预测来形成预测误差或不匹配。在考虑其对大脑中神经信息传递的影响之前,我们首先需要建立PE-SAIM与多对象成本的建构效度。This architecture is consistent with generic predictive coding schemes, in which the prediction errors at any level in a predictive coding hierarchy are formed by subtracting predictions to create a prediction error or mismatch. Before considering the implications for neuronal message passing in the brain, we need to first establish the construct validity of the PE-SAIM in relation to the multiple object cost
3.1. Simulation results and discussion
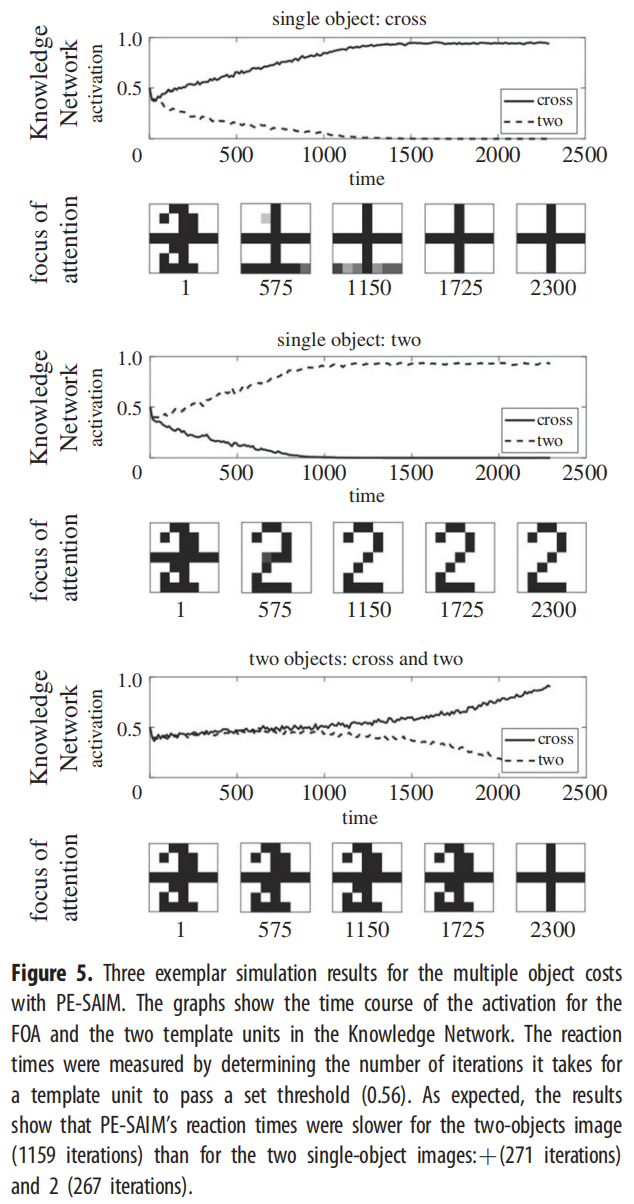
图5和图6显示了模拟结果,证明PE-SAIM也能复制两个对象的成本。t检验确认了?/2与单个?之间(t38 = 17.09; p < 0.001)以及?/2与单个2之间(t38 = 16.52; p < 0.001)的显著差异(以及2与单个?之间(t38 = 24.00; p < 0.001))。此外,40个单个刺激模拟中没有一个显示出错误,?/2模拟始终选择了十字架。因此,SAIM的两个变体都能够复制定性的多对象成本。从建构效度的角度来看,这是令人满意的,因为它确立了这两种方案的建构效度。换句话说,EM-SAIM和PE-SAIM都能以生物学上可信的方式复制在视觉场景中识别多个对象时的感知合成的精细(心理物理学)细节。然而,如果我们想要确定哪种方案提供了对真实视觉层次结构中神经信息传递的最佳解释,这将提出一个有趣的挑战。回想一下上面提到的,两种方案之间的一个关键架构差异是利用自上而下的预测以基本不同的方式选择感觉输入最可能的解释。EM方案使用兴奋性反馈来确保在较低级别满足自上而下的约束,而PE方案则利用抑制性反馈形成预测误差的自上而下预测。
4. Comparing PE-SAIM with EM-SAIM
需要注意的是,这些特定的模拟结果取决于我们特定的参数选择。对于两个网络,参数的选择是为了确保在识别错误不存在的情况下产生显著的反应时间成本效应。另一方面,也可以生成模拟结果,其中反应成本与识别错误相配对。即使这种观察对于说明原则上两种模型都能复制两个对象的成本并不是至关重要,但它表明参数选择可以以可测量的方式修改对象识别的性能。反过来,这为比较两种方案解释经验(例如心理物理学)数据的能力提供了机会。这种比较通常使用贝叶斯模型比较。贝叶斯模型比较已经用于澄清不同选择行为模型,并且通常依赖于计算贝叶斯因子,该因子评分给定相同数据情况下一个模型相对于另一个模型的证据[28](参见[29]进行审查)。简而言之,贝叶斯因子评估哪个模型更适合生成给定的数据集,考虑到所有合理的参数设置(在一些通常的对参数的先验假设下)。

为了评估SAIM的两种实现,贝叶斯模型比较可以利用识别准确性和反应时间成本之间的权衡(类似于我们模拟中观察到的效果),通过改变对象的数量和刺激的可辨识性来变化。在这种情况下,可能可以使用两种模型来拟合行为准确性和反应时间,通过优化模型参数。原则上,然后可以比较经验响应数据中两种方案的证据。
这些模拟还阐明了有关FOA中所选对象表示的有趣观点。尽管没有所选对象的完美表示,但两种SAIM都能做出正确的决定。这是因为“两”可以很容易地与“十字架”区分开。需要注意的是,任务并不需要完美的表示。此外,EM-SAIM的表示比PE-SAIM的表示不够准确。这种差异有可能区分这两种模型。例如,在一个经验研究中,参与者不仅可以被要求找到特定的对象,还可以被要求识别该对象的特定特征。我们的模拟预测,EM-SAIM下的推理会产生比PE-SAIM更多的错误。然而,如上所述,这可能取决于参数设置,这些参数设置必须针对任何给定的选择行为进行优化,从而使贝叶斯模型比较能够确定哪种模型是最能解释实验数据的。
除了这些行为评估之外,PE-SAIM和EM-SAIM还可以生成类似EEG或fMRI测量的类型的神经元响应。大多数当前的神经活动测量方法都是间接的,并且取决于各种生理过程(例如树突去极化、轴突放电、血液动力学等)以及相应方法(EEG、fMRI等)可以测量的过程。为了模拟神经元响应,我们省略了内容网络,因为它的激活取决于“像素化输入”。我们对选择网络和知识网络的输出激活和输入激活(由方程(2.11)、(2.13)、(3.3)和(3.5)定义)进行了求和。在这些计算中,我们排除了softmax/softmin方程中的激活。得到的神经元响应反映了树突和轴突的激活,同时忽略了抑制性间神经元的激活。
图 7 显示了两个模型的激活时间过程。他们认为区分这两种模型是可能的:对于 EM-SAIM,结果表明这两个区域的活动都减少了,而对于 PE-SAIM,结果表明这两个区域的活动都增加了。这些结果可能会让一些读者感到惊讶:鉴于 PE-SAIM 试图最大限度地减少预测误差,活动的减少可能是预料之中的;而对于 EM-SAIM,可能会出现相反的效果。EM-SAIM 的反直觉结果可以相对容易地解释。EM SAIM 的初始状态使用知识网络和内容网络中模板的加权组合。
该组合模板与输入图像中的两个对象匹配(但“交叉”的匹配比“两个”的匹配更好)。随着选择过程的进行,这种匹配会下降,因为仅匹配输入中的“十字”,而知识网络中的“两个”模板不再匹配。PE-SAIM 中激活的增加需要一些更详细的拆包。最初,组合模板产生自上而下的预测,该预测为“交叉”生成比“两个”更好的匹配。选择网络开始将 FOA 偏向“十字”。随后,这种偏差导致与自上而下的预测不匹配,从而导致激活增加(即预测误差)。当知识边缘网络开始通过选择交叉来生成改进的预测时,知识网络输入中预测误差的增加会下降。然而,由于“两个”模板产生不匹配的预测,因此总体误差不会回落到零。选择网络也可以观察到类似的效果。尽管 FOA 生成与输入中的“交叉”相匹配的预测,但与“两个”的不匹配会导致更高的激活。这些结果凸显了当预测误差和注意力选择同时发挥作用时诱发反应的复杂性(参见[30-32]了解功能磁共振成像和脑电图的经验例子)。
其他从经验上利用此类模拟的神经影像方法可以集中于消除对自上而下传入的兴奋性和去抑制性反应之间的歧义。人们可以考虑许多候选者。首先,人们可以使用前向和后向的层流特异性 (自下而上和自上而下)连接与层流特异性功能磁共振成像相结合,以预测注意力效应的神经元相关性[33]。另一种方法是使用频率标记来测量注意力对稳态电生理反应的影响(例如[34])。文献中还有几个例子使用动态因果模型来消除皮质层次结构中抑制性和兴奋性连接之间的歧义[35-41]。简而言之,动态因果建模需要使用具有层层特异性耦合的神经质量模型以诱发反应的形式拟合经验数据(通常是脑电图,但参见[42],例如,使用功能磁共振成像)数据[35,43]。然后,人们可以通过指定构成电磁源(即等效电流偶极子)的神经团内部和之间的不同连接模式来评估竞争架构的证据。模型拟合后,可以评估模型证据(即每个模型下的经验数据的概率)并用于在不同架构之间进行裁决。原则上,我们可以使用完全相同的技术来测试具有不同时间常数以及不同抑制或兴奋作用的模型(例如[35])。这将涉及在所讨论的突触时间常数或有效连接(即下降或反馈传入对主要视觉源的影响)上比较具有不同先验的等效模型。在在这种情况下,动态因果建模还必须考虑 PE-SAIM 不仅假设之间存在反馈循环区域内,而且也在层内(参见方程(3.4)和(3.5)中的误差项)。最近的侵入性数据,解决了预测编码的替代架构,也提供了测试有关反馈性质的替代预测的有趣可能性(参见[44]的示例)。
5. General discussion
本文的目的是研究 SAIM 的软约束满足(使用能量最小化)与近似贝叶斯推理的自由能最小化。为了便于进行比较,我们首先创建了 SAIM 的新版本:EM-SAIM 包含比原始 SAIM 稍微更合理的生物学特征,但最重要的是,就本文而言,它基于相同的架构和形式上相似的能量函数。然后我们确保 EM-SAIM 可以重现多对象成本。随后,我们证明 SAIM 的能量最小化可以用点估计器的贝叶斯推理(即最大后验估计)来解释。我们还注意到,随之而来的概率推理实现了软约束满足,其中经验和完整先验提供了必要的约束。通过对 EM-SAIM 的能量函数进行逆向工程,我们表明 EM-SAIM 的生成模型使用稀疏回归模型中常见的稀疏先验。值得注意的是,这种类型的先验被用于 LASSO 回归(例如[45])和独立成分分析(例如[46])等方法中。使用这种先验的结果是它有利于数据的稀疏表示。此外,在 EM-SAIM 中,WTA 强制代表成为本地代表。至关重要的是,这种生成模型不同于预测编码和相关视觉处理贝叶斯过滤公式中使用的生成模型。这些公式通常采用基于高斯假设的生成模型。因此,我们将 EM-SAIM 架构中的经验先验替换为高斯形式(即与预测误差平方成正比的对数概率),以表明 PE-SAIM 也能够模拟多对象成本。
我们的模拟表明,就行为(心理物理)反应的预测而言,EM-SAIM 和 PE-SAIM 在数量上是无法区分的。然而,通过合适的实验设计,这两个模型可以用于对经验数据进行定量建模。如果这是可行的,贝叶斯模型比较应该能够使用识别精度和反应时间来消除这两种方案的歧义(例如[28,29])。我们进一步观察到 EM-SAIM 和 PE-SAIM 对信念更新方面的神经元反应做出了截然不同的预测。EM-SAIM 表明兴奋性反馈回路介导我们已经说明的行为效应,而 PE-SAIM 意味着抑制性反馈回路。因此,这些模型似乎对反馈连接的生理学做出了不同的预测。
乍一看,EM-SAIM 似乎与众所周知的皮层兴奋性(谷氨酸)反馈连接的生理学更加一致(例如[47]) 。然而,这些反馈连接针对的是抑制性中间神经元。因此,反馈连接也可能调解预测误差的构建(详细参数请参见[16,43,48,49])。因此,我们目前的生理学知识并不能明确消除这两种结构的歧义。另一方面,正如上面所讨论的,可以根据经验区分这两种架构。
利用两个模型对自上而下传入的兴奋性或抑制性性质做出不同预测的事实。两种类型的反馈主题可能会产生不同的动态(具有不同的时间常数)。因此,可以想象,层流特异性功能磁共振成像、动态因果建模或频率标记脑电图,与贝叶斯相结合模型比较,可能允许我们使用人类非侵入性技术来消除两种架构的歧义(有关侵入性研究的经验预测的当代讨论,请参阅[50])。最后,值得注意的是,两种模型在对熟悉刺激和新刺激的偏好方面做出了不同的预测。4 EM-SAIM 更喜欢熟悉的刺激,而 PE-SAIM 更喜欢新刺激(这会引起更大的预测误差)。有趣的是,Park 等人最近的一项研究。[51]发现了特定于类别(即面部与自然场景)的偏好,可以提供一个有趣的范例来测试这两个模型。
表1中预测编码模式的微电路说明了去抑制作为生理机制对下行或反向连接的影响(在表1中由双红线表示)。关于这种类型的去抑制机制,有越来越多的兴趣和证据(见[32,48,50]进行了综述)。这些证据部分来自最近使用抑制性间神经元的光遗传学特征化进行的侵入性研究。已经在几个皮层区域发现了使用去抑制的微电路模式:简言之,认为血管活性肠肽阳性(VIP?)间神经元通过针对否则抑制目标兴奋性神经元的阿尔布明阳性(PV?)和生肌动蛋白阳性(SOM?)间神经元提供去抑制控制[53]。这种突触结构得到了啮齿动物研究的证据支持,该研究显示光遗传学抑制SOM?和PV?间神经元减少了来自扣带皮层的下行投射到V1的抑制作用。相反,VIP?间神经元的光遗传学抑制增强了来自扣带皮层的投射的作用。在人类中,当新皮层GABA减少时,可以观察到去抑制效应,无论是在生理上还是在功能上。简而言之,经验证据的平衡指向了类似PE-SAIM体系结构隐含的去抑制模式。
兴奋性和抑制性反馈之间的辩证法已经在文献中广泛讨论(参见[56–58])。例如,Kersten等人[57]已经用“闭嘴”与“停止闲聊”两种解释来阐述了贝叶斯物体感知的二分法。直观地说,闭嘴版本对应于抑制性的自上而下影响,以“解释掉”较低层次的任何表示,以减少预测误差活动水平。相反,当某些内容可以预测时,较低层次的活动抑制可能更好地由自上而下增强最佳表示来解释,以抑制所有竞争性预期。有时,这种二分法是由对比预测编码与Grossberg自适应共振理论(ART)(例如[59];另请参见Kay&Phillips的[60]关于相似观点的一致性INFOMAX,或Bowman等人的[61]关于显著性检测器)的对比所激发的。根据ART,兴奋性反馈回路在诱导强烈的“共振”以促进学习方面尤为重要。因此,ART在兴奋性反馈方面类似于EM-SAIM的架构。
在建立了SAIM与自由能原理下的层级贝叶斯推断之间的关系之后,值得回到SAIM所涉及的领域,对通常与选择性视觉注意力相关的现象进行建模。类似预测编码的注意力形式引入了一个必须进行优化的额外变量;即,感觉输入中随机波动的幅度或其倒数称为“精度”。在预测编码的工程化表述中,这是一个关键量(例如Kalman滤波器)。在这种情况下,精度对应于Kalman增益;即,在信念更新期间赋予预测误差的增益或权重。关键的是,精度本身可以被预测。根据Feldman&Friston[22]和Kanai等人[23]的观点,注意力是通过优化精度来实现的。简而言之,精度的自上而下预测可以选择哪些预测误差被有效增强,使它们对层次结构的更高层次的信念更新产生更大的影响。这被认为是预测编码中注意力的计算同源。关键的是,精度的自上而下预测具有兴奋性效应,与用于形成预测误差本身的抑制性自上而下反馈形成对比。当考虑到注意力的预测编码形式时,必须考虑到兴奋性和抑制性自上而下反馈。关键的是,调节精度的兴奋性自上而下影响是调制性或非线性的,因为它们调制了预测误差。有趣的是,这与PE-SAIM中固有的非线性相呼应。
总之,注意力与感知推断密切相关。有趣的是,这个假设与SAIM的选择网络使用Sigma-pi单元产生的影响非常相似。因此,修改PE-SAIM并让选择网络调节预测误差而不是感觉信息应该相对简单。我们无法预见这种新PE-SAIM的功能上会出现任何问题,并且预期它应该与上文描述的PE-SAIM行为方式类似。我们将在随后的论文中考虑精度与SAIM中选择网络角色之间的形式关系,并探讨对视觉注意力的功能解剖学的影响。