微软 & 清华 | 提出LoRAs专家混合方法:MOLE,可动态、高效地组合多个LoRA!
微软 & 清华 | 提出LoRAs专家混合方法:MOLE,可动态、高效地组合多个LoRA!

引言
LoRA模块化架构让研究人员们开始探索组合多个LoRA方法,旨在实现学习特征的联合生成,增强各种任务的性能。当前线性算术组合和参数调优组合都存在一定的缺陷,为了能够动态、高效地组合多个训练后的 LoRA,本文作者提出了LoRA专家混合方法:MOLE,不仅在LoRA组合中提升了性能,还节约了计算开销,保证了LoRA的灵活性。
https://arxiv.org/pdf/2404.13628.pdf
背景介绍
随着大模型的发展,其已经应用至各个领域,例如教育、医疗、金融等。一开始为了能够让大模型适应下游任务,通常需要基于下游数据集进行微调,但是随着不断增加的模型参数量,对模型进行全微调越来越困难(时间长、成本高、迭代速度慢)。
为此,各种微调方法方法不断被研究人员提出,例如:Prefix-tuning、Adapter、P-tuning、LoRA等,其中LoRA是一种微调大型预训练模型的技术,通过冻结预训练模型的权重并注入可训练的低秩分解矩阵来实现,并被证明是计算资源受限场景中的一种有效的微调方法。
虽说LoRA是预训练模型的插件,可以实现即插即用。但是,最近研究开始探索组合单独训练的LoRA,旨在实现学习特征的联合生成。然而,在此过程中仍然会遇到一些问题。如下图所示,通过线性算术直接组合训练好的LoRA,这种组合多个LoRA的方式可能会影响预训练模型的生成性能。为了解决这个问题,研究人员提出在组合之前应用权重归一化,但是随着每个LoRA的组合权重的减少,可能可能会消除各个训练过的 LoRA 的独特特征。
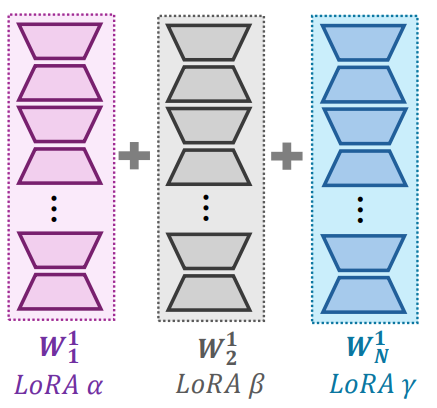
另外,一种方法是基于参数调优的组合,该方法专注视觉语言(V&L)领域,如下图所示。但是该方法需要手动设计的mask,在 LoRA 灵活性方面受到限制,需要大量的训练资源。
基于以上两种方法分析,我们应该如何动态、高效地组合多个训练后的 LoRA,同时保留其所有各自的特征呢?在 V&L 领域观察到 LoRA 的不同层编码了不同的特征,例如狗的毛色和面部特征。在 NLP 领域,当在包含 ANLI-R1、ANLI-R2 和 QNLI 数据集的综合数据集上训练单个 LoRA 时,不同层的 LoRA 在这些子数据集上的评估表现出现了显著差异。这表明可以根据定义的领域目标动态优化层特定权重,增强所需的特性,同时抑制较不利的特性,从而实现更有效的训练 LoRA 的组合。
为此,本文作者提出LoRA专家混合(Mixture of LoRA Experts,MOLE),MOLE它不仅在LoRA组合中提升了性能,而且还保留了以最小的计算开销,有效组合经过训练的LoRA所必需的基本灵活性。
MOLE
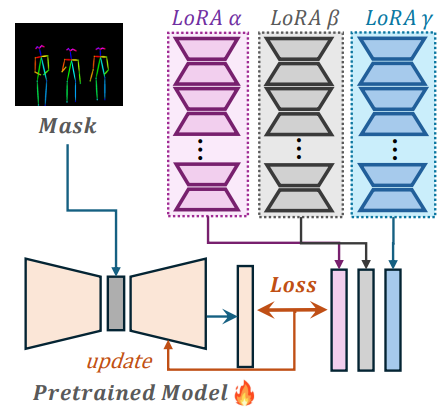
「MOLE的核心思想」 将每个训练好的 LoRA 层视为一个独立的“专家”,并通过在每层集成一个可学习的门控函数来实现层次化的权重控制。这样,MOLE 可以根据给定领域的目标学习最优的组合权重,从而在不损失单个 LoRA 特性的情况下,实现更有效的 LoRA 组合。如下图所示:
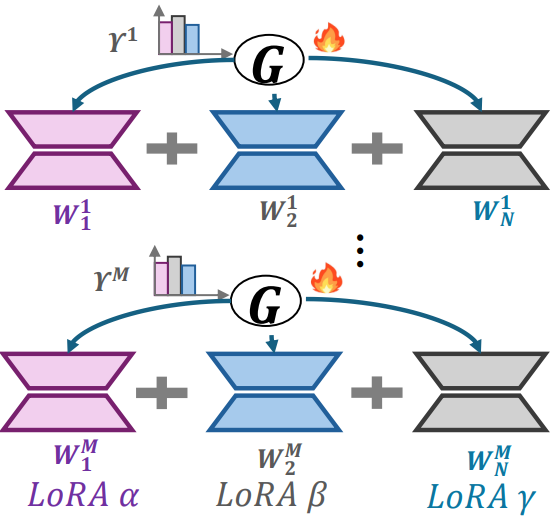
「MOLE工作流」 主要包括训练和推理两个阶段。如下图所示:
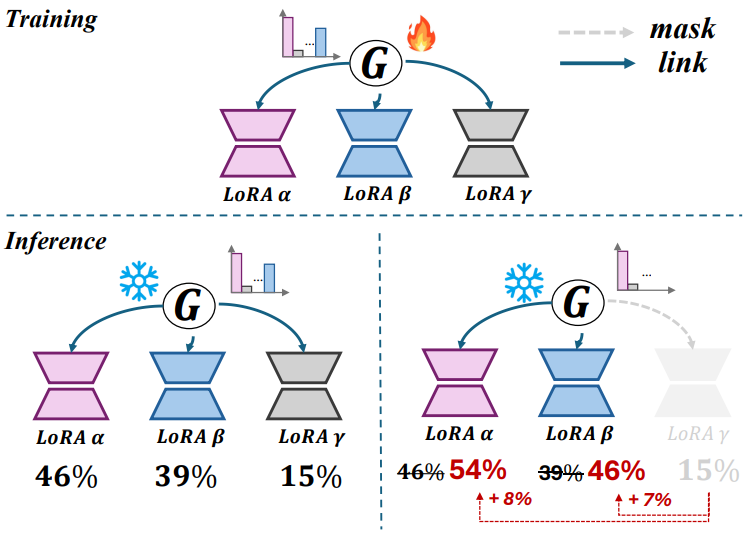
1、训练阶段
- 「预测权重 (Predicting Weights)」: 在训练阶段,MOLE 的目标是为多个训练好的 LoRAs 预测权重。这是通过学习一个可训练的门控函数来实现的,该门控函数在每个层内确定如何组合不同 LoRAs 的输出。
- 「冻结其他参数 (Freezing Other Parameters)」: 除了门控函数的参数外,所有其他训练好的 LoRA 参数以及预训练模型的参数都保持冻结,这样可以保留 LoRA 专家的特性,特别是在训练数据有限的情况下。
- 「最小化计算成本 (Minimizing Computational Cost)」: 由于只优化门控函数的参数,MOLE 能够以最小的计算成本完成训练。
2、推理阶段
- 「使用所有训练好的 LoRAs (Using All Trained LoRAs)」: 在第一种推理模式下,MOLE 利用所有训练好的 LoRAs 和学习的门控函数,为每个 LoRA 分配权重,同时保留它们各自的特性。
- 「手动Mask不需要的 LoRAs (Manually Masking Unwanted LoRAs)」: 在第二种推理模式下,MOLE 允许用户手动Mask不需要的 LoRAs。然后,MOLE 将重新计算和按比例分配权重,而无需重新训练模型。
- 「灵活适应不同场景 (Adapting to Different Scenarios)」: 这两种模式使 MOLE 能够适应不同的场景,为有效的 LoRA 组合提供了一种多功能和灵活的方法。
实验结果
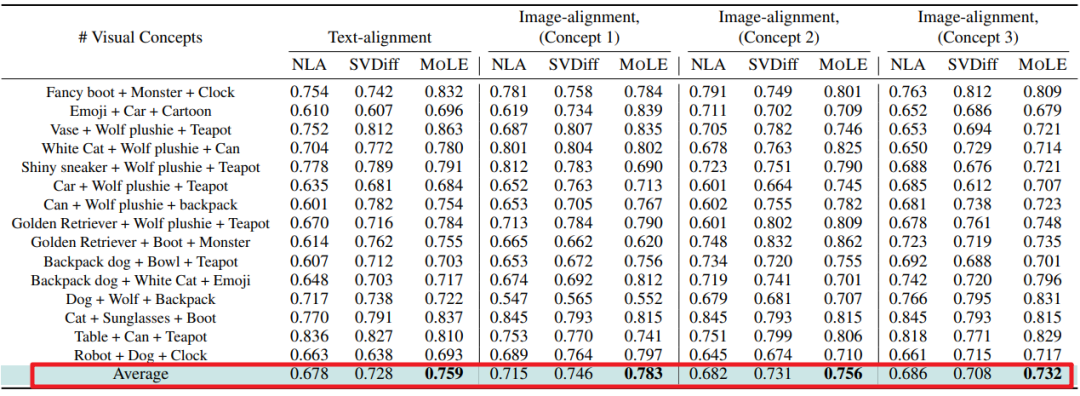
「在视觉语言领域」 MOLE 应用于多主题文本到图像生成任务,使用 DreamBooth(基于 Stable Diffusion V2.1)作为基础生成器。下表展示了 15 种不同的三个视觉主题组合的实验结果。MOLE 在 Text-alignment 分数上显著优于其他比较方法,与 SVDiff 相比平均提高了 0.031,在与三个视觉概念相关的 Image-alignment 分数上平均提高了 0.037。
「在NLP领域」 使用 Flan-T5 作为选择的大模型(LLM),并基于 FLAN 数据集创建了几个 LoRAs。将 MOLE 与最近发布的最先进的 LoRA 组合方法 LoRAhub 和 PEMs 进行了比较。MOLE 在五个不同的数据集上超越了现有的 LoRA 组合方法。如下图所示: