Nat. Comput. Sci. | 人类般的直觉行为和推理偏见在大型语言模型中出现,但在ChatGPT中消失了
Nat. Comput. Sci. | 人类般的直觉行为和推理偏见在大型语言模型中出现,但在ChatGPT中消失了

今天为大家介绍的是来自Michal Kosinski团队的一篇论文。作者设计了一系列语义幻觉和认知反思测试,旨在诱发直觉性但错误的反应。作者将这些任务(传统上用于研究人类的推理和决策能力)应用于OpenAI的生成预训练变换器模型家族。结果显示,随着模型在规模和语言能力上的扩展,它们越来越多地显示出类似人类的直觉型思维和相关的认知错误。这一模式随着ChatGPT模型的引入而显著转变,这些模型倾向于正确响应,避免了任务中设置的陷阱。ChatGPT-3.5和4都利用输入输出上下文窗口进行思维链推理。作者的发现强调了将心理学方法应用于研究大型语言模型的价值,因为这可以揭示先前未被发现的突现特性。

随着大型语言模型(LLMs)应用范围的快速扩展,理解LLMs通过何种机制进行推理和决策变得极为重要。最近的研究揭示了随着LLMs复杂度的增加,它们展现出了多种技能和属性,其中一些是它们的创造者未曾预料或意图的。这些新发现的能力包括生成计算机代码、解决数学问题、通过示例学习、进行内省、执行多步推理、欺骗其他代理以及其他许多技能。在这项工作中,作者旨在探索OpenAI的生成预训练变换器(GPT)模型家族的推理能力,同时揭示它们认知过程的复杂性。在人类研究中,经常区分两大类推理或更广泛的认知过程:系统1和系统2。系统1的过程是快速的、自动的和本能的。它们经常涉及启发式,或心理简化,这使得人们能够快速做出判断和决策,无需有意识的努力。系统1对日常功能至关重要,因为它允许人类导航他们的环境并以最小的努力做出迅速决策。另一方面,系统2的过程是深思熟虑的,需要有意识的努力。这个系统被用于逻辑推理、批判性思维和解决问题。系统2的过程更慢且更消耗资源,但它们也更准确且不那么容易受到偏见的影响。
表面上,当前的大型语言模型(LLMs)似乎是系统1型的思考者:输入文本通过连续的神经元层处理,以产生所有可能的单标记(词)完成的概率分布。这个过程是自动的、单向的,并且涉及对每个连续预测的词通过神经网络的单次传播波。然而,过去的研究以及这里呈现的结果表明,像人类一样,LLMs也可以参与类似系统2的认知过程。在生成每个连续的词时,LLMs会重读它们的上下文窗口,包括用户提供的任务以及它们迄今为止生成的词。结果,LLMs可以利用它们的上下文窗口作为一种外部短期记忆来参与思维链推理,重新检查起始假设,估算部分解决方案或测试替代方法。这类似于人们使用笔记本解决数学问题或写论文以发展他们的论点。
在这项工作中,作者基于对人类推理和决策的心理学研究,探索LLMs中的系统1和系统2过程。作者检查了人类(n=455)和十个OpenAI LLMs(范围从GPT-1到ChatGPT-4)使用通常用于测试人类推理和决策的任务的表现:认知反射测试(CRT)任务和语义幻觉任务。CRT包括三种类型的数学任务,这些任务看起来比实际简单,因此触发了直觉性但不正确的系统1响应。CRT类型1任务,如广为人知的“蝙蝠和球”任务,使用“多于”短语来诱骗参与者减去两个数值而不是解决一个稍微复杂的方程。类型2任务利用人们完成数值三元组系列的倾向,例如五台机器五分钟制造五个小部件,因为两台机器两分钟内制造两个小部件。类型3任务描述了一个指数过程,但诱骗参与者将其视为线性过程。正确解决CRT任务需要进行深思熟虑的系统2推理或拥有良好的系统1直觉。语义幻觉是包含伪装错误的问题,旨在触发直觉性但不正确的系统1响应。例如,在著名的摩西幻觉中,参与者往往被诱导声称摩西带了每种两只动物上方舟(实际上是诺亚)。
实验部分
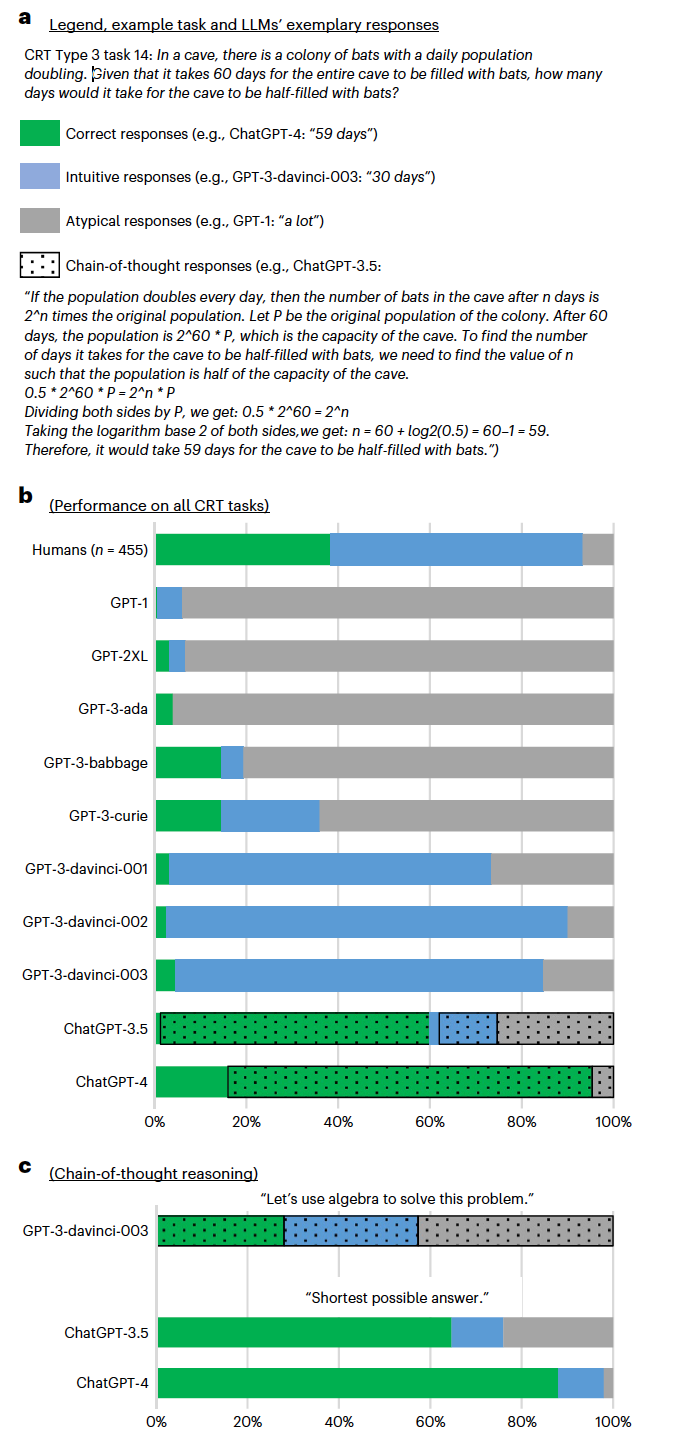
图 1
首先作者介绍了研究1的结果:认知反射测试(CRT)。为了帮助读者解释结果,作者在LLMs对其中一个CRT任务的示范性回答的背景下讨论它们(图1a)。这个任务的正确回答是“59天”,但它被设计得看起来比实际简单,诱使参与者简单地将总时间除以二,从而触发了直觉性(但不正确)的回答“30天”。人类和LLMs在150个CRT任务中的表现在图1b中呈现。有四个明显的趋势。首先,早期和较小的LLMs(直到GPT-3-curie)的大多数回答都是非典型的。这一类包括回避性回答,这表明它未能理解任务,或者以与任务设计触发的方式不同的方式错误。虽然GPT-3-babbage和GPT-3-curie的回答中有15%被认为是正确的,但这似乎是偶然的:除了一个之外,所有正确的回答都是对CRT类型2的任务,这类任务只要简单地重复题目中最常提到的数字就能解决——但是这些模型倾向于在这个和其他任务中天真地这样做。
其次,随着模型变得更大,它们理解任务的能力增强,非典型回答被设计来触发直觉性(但不正确)回答所取代。这类回答在早期模型中的比例低于5%,而在GPT-3-curie中增加到了21%,并且在GPT-3-davinci系列中增加到了70%–90%,这一比例远高于人类观察到的比例(55%)。在人类中,直觉性但不正确的回应被解释为系统1推理的证据以及未能启用系统2的失败,但它们也可能源自有意的——尽管是错误的——系统2推理。LLMs回应背后的生成过程则不那么含糊。当前的LLMs缺乏内部参与系统2过程所必需的内置认知基础架构。因此,它们的直觉响应只能源自一个类似系统1的过程。
第三,LLMs表现出强烈的直觉性回应倾向,在ChatGPT问世时突然停止。正确回应的比例对于ChatGPT-3.5是59%,对于ChatGPT-4是96%。这远高于GPT-3-davinci-003正确解决任务的5%,或者人类达到的38%。ChatGPT倾向于正确回应的同时,其直觉性回应的倾向显著下降:ChatGPT-3.5为15%,ChatGPT-4为0%,而GPT-3-davinci-003为80%,人类为55%。ChatGPT模型表现的显著提升伴随着一种新的回应风格。与ChatGPT之前的LLMs用简短的短语或单个句子回应不同,97%的ChatGPT-3.5回应和85%的ChatGPT-4的回应包含了某种形式的思维链推理(图1a)。ChatGPT-3.5和其他当前LLMs生成下一个词的方式并无任何深思熟虑的过程。然而,每次生成词汇时,LLM会重读任务和到目前为止生成的回应,将类似系统1的下一个词生成结合成类似系统2的过程:生成解决任务所需的策略,将任务分解为更易处理的子任务并逐一解决。这类似于人类使用笔记本解决数学任务,无需在短期记忆中处理它们。
思维推理
思维链推理不仅与系统2过程相似,而且实际上就是系统2过程,这些研究表明指导LLMs逐步思考能提高它们解决各种任务的能力。作者首先展示当指导GPT-3-davinci-003进行思维链推理时,它的准确率会提高。图1c展示的结果表明操作是成功的:思维链反应的比例从研究1的0%增加到了100%。模型似乎设计并执行了一个解决任务的策略。大多数情况下,这个策略构思或执行得不好,导致非典型反应的增加,从15%增加到了43%。然而,在其他情况下,策略是有效的,正确回应的比例从5%提高到了28%并且减少了模型落入任务陷阱的倾向:直觉性回应从80%降低到了29%。
由于ChatGPT模型已经似乎拥有了良好发展的直觉,作者尝试改善GPT-3-davinci-003的类似系统1的回应(研究3)。作者向它提出每个CRT任务,每次都在此之前用相同类型的剩余0到49个任务,每个任务都附带正确解答。同一类型的CRT任务在语义上非常相似,使得模型能够发展出类似于ChatGPT模型家族所表达的系统1直觉。结果显示,随着额外示例的增加,GPT-3-davinci-003正确回答的能力增加。对于CRT类型2任务观察到最快的增益,准确率在两个示例后从2%增加到92%。这是意料之中的,因为它们可以通过简单重复任务中列出的持续时间来正确解决。CRT类型3任务在七个训练示例后,准确率从12%增加到92%。解决CRT类型1任务的直觉需要最多的示例。然而,即使在这里,模型的准确率也在30个示例后从0%增加到78%。
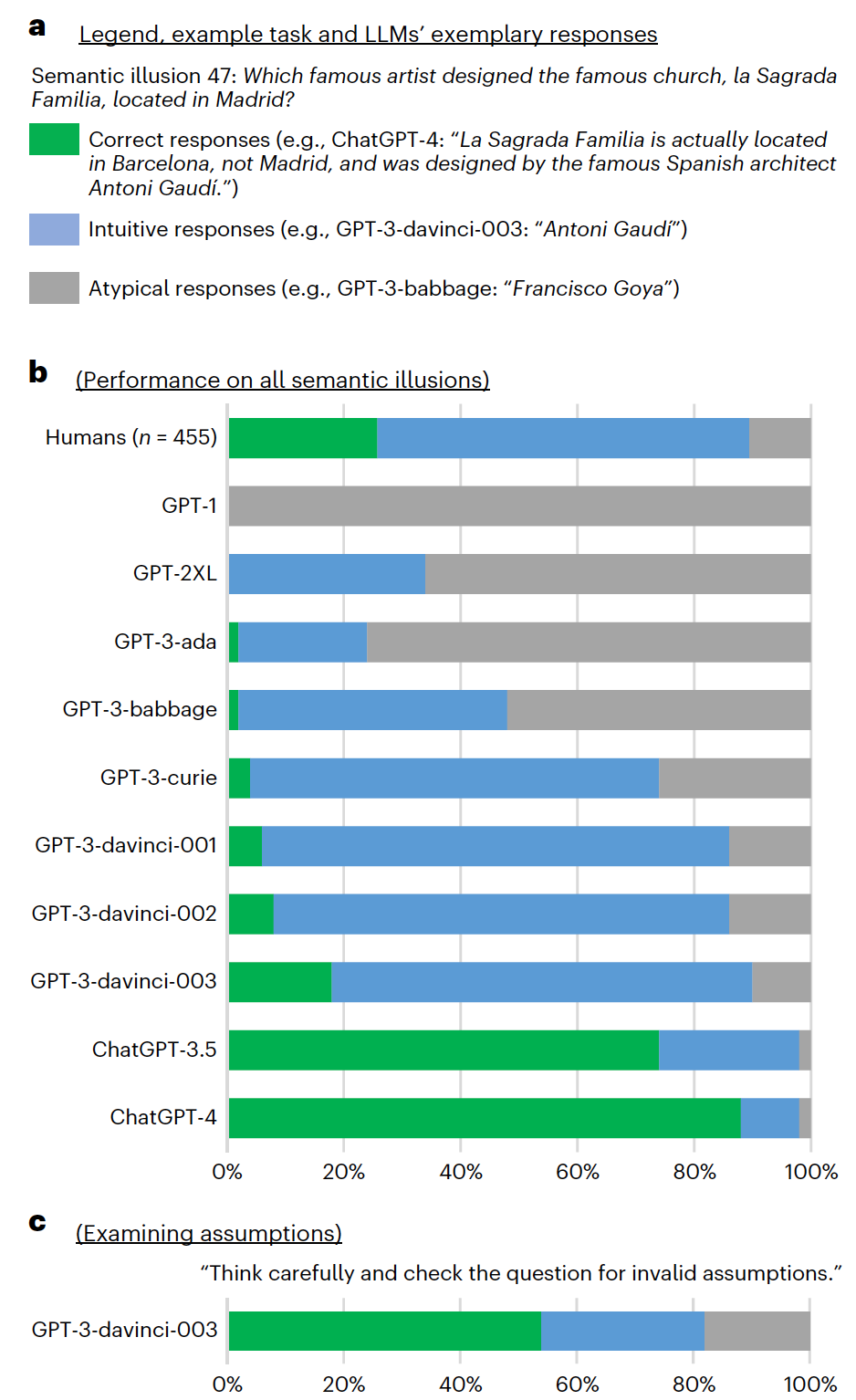
图 2
在研究1-3中使用的CRT任务严重依赖数学技能,并且在语义上高度一致。为了确保结果能够超越CRT任务的范畴,作者使用语义上更加多样化的语义幻觉(研究4)复制了研究1-3。与CRT任务类似,语义幻觉包含一个旨在触发直觉性但不正确的系统1响应的隐藏错误。与CRT任务不同,语义幻觉不需要数学技能,而是依赖于参与者的一般知识。图2b展示的结果显示了一个与研究1观察到的类似的模式。早期和较小的LLMs(直到GPT-3-babbage)的大多数回应是非典型的,因为它们难以理解问题或缺乏必要的知识。随着LLMs在规模和整体能力上的增长,非典型回应的比例从GPT-3-babbage的52%下降到GPT-3-davinci-003的10%。它们被直觉性回应所取代:GPT-3-davinci-003在72%的时间里陷入了语义幻觉。正如在CRT任务中,这一趋势随着ChatGPT的引入而明显改变。正确回应的比例从GPT-3-davinci-003的18%增加到ChatGPT-3.5的74%和ChatGPT-4的88%。
编译 | 曾全晨
审稿 | 王建民
参考资料
Hagendorff, T., Fabi, S., & Kosinski, M. (2023). Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT. Nature Computational Science, 3(10), 833-838.