如何理解分布式系统下的CAP理论?
原创
如何理解分布式系统下的CAP理论?
原创
前言
曾经有一段时间对CAP理论感到非常困惑,不理解“一个分布式系统无法同时满足一致性、可用性和分区容错性”的说法。尤其是在网上看到一些误导性的说法,就更是不理解了。
如果有同样困惑的,希望通过本文的表述能够为你提供解答。
为什么对CAP理论感到困惑
理论表述的不完整性
在网上经常可以看到一些CAP理论的文章,大多数都是简单地列出了CAP三个要素的定义,然后开启“一致性、可用性和分区容错性为什么不能同时成立”的解释。
CAP理论,指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性),不能同时成立。 C(consistency)一致性:访问所有节点得到的结果是一致的。
A(Availability)可用性:请求在一定时间内可以得到正确的响应。
P(Partition tolerance)分区容错性:在网络分区的情况下,系统仍能提供服务。
分布式系统不能保证同时使用C、A和P,只能选择CP或AP。
这样缺乏上下文的表述理解起来就很抽象。
存在的疑惑点
在看完这些没有前言后语的概念以及解释后还是会有一些疑惑:
- “CAP说的不是分布式吗?为什么总有集群的影子?”
- "为什么不能保证CA?"
CAP理论背景
后面去了解了下CAP理论的背景,得知作者Eric Brewer写了2个版本来阐述CAP,在后续的版本中写道:
In a distributed system(a collection of interconnected nodes that share data),you can only have two out of the following three guarantees across a write/read pair: Consistency,Availability,and Partition Tolerance
翻译过来是:在分布式系统(共享数据的互连节点的集合)中,在写/读对中只能有以下三种保证中的两种:一致性、可用性和分区容错。
可以看到,真正的CAP理论明确指出了其适用于的场景:共享数据的互连节点的集合和写/读。而不是分布式系统中某几个子系统或服务。
对CAP理论的正确理解
CAP理论针对的不是整个分布式系统
“共享数据的互连节点的集合”证实了我第一个疑惑,这里的“集合”不就是集群吗?
比如Redis、Kafka的副本机制就属于集群,副本之间的数据同步这一功能也符合分布式的特性(分布在不同位置的节点通过网络连接协同完成同一个工作)。所以Redis、Kafka属于分布式架构也就不难理解了。
在读写操作中,无法保证CA同时成立
第二个疑惑就属于场景问题了(读写)。
在向“共享数据的互连节点的集合”中读写数据时,自然无法同时保证一致性和可用性。
当出现网络分区后,如果要满足一致性,意味着集合的数据同步一致后,数据才能被访问,但是这期间需要等待网络恢复或其他操作,自然也就无法保证可用性了(在一定时间内可以得到正确的响应)。反过来,如果要在一定时间内得到正确响应,一致性必然也满足不了了。
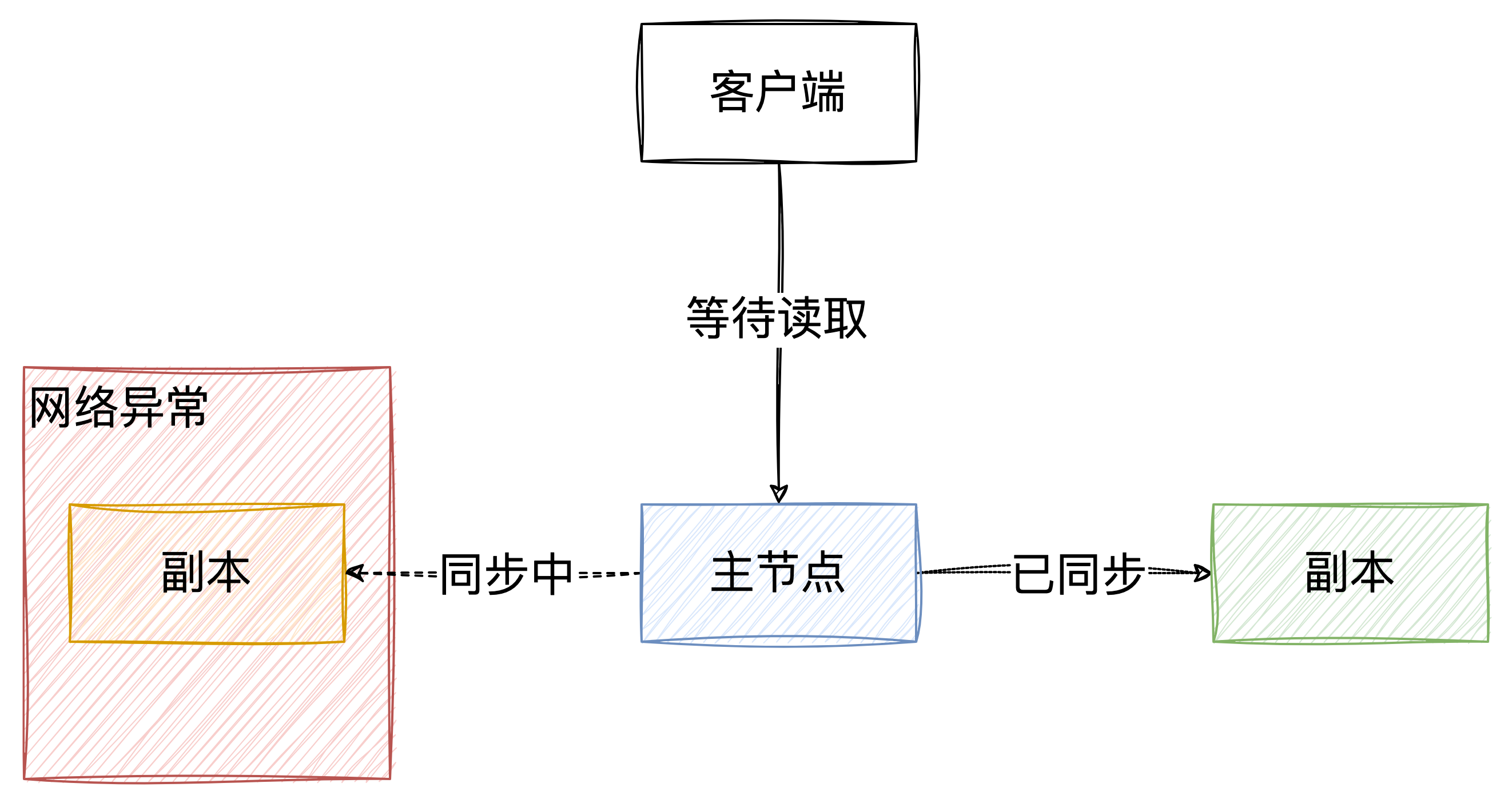
但是,当不存在网络分区时,CAP还是可以同时保证的。
直观的CAP理论
所以,CAP理论应该是这样的:分布式系统中存在共享数据的互连节点,当出现网络分区时,不能保证同时保证可用性和一致性。
CAP中的C(consistency)是指:在任何时刻,无论用户从哪个节点读取数据,都应该得到相同的结果。
CAP中的A(Availability)是指:即使网络中的某些节点出现了故障,系统仍然可以继续处理请求。
CAP中的P(Partition tolerance)是指:由于网络延迟、故障或其他原因,分布式系统中的节点可能会被分割成不同的网络分区,系统需要能够容忍这种分区情况。
需要关注的是,A和P都是为了保证服务的质量,但两者的侧重点不同,可用性主要关注系统能否及时响应请求并提供服务,而分区容错性则更关注系统在遇到网络分区故障时的表现。
CP、AP架构应用
如果你经常被问到什么....是CP架构还是AP架构,现在就不难回答了。
比如 Zookeeper 和 Eureka。这两个组件都符合 CAP 中的(共享数据的互连节点的集合)。
Zookeeper 集群是 Leader 在过半节点同意成功写入后,客户端才会读取到这个值,所以说 Zookeeper 是 CP 架构。
Eureka 集群是不论哪个节点在写数据时都会立即刷新本地数据然后再同步给其他节点,所以 Eureka 是 AP 架构。
总结
探讨CAP理论是有明确对象和场景的,CA同时满足是有前提的:
- CAP理论探讨对象:共享数据的互连节点的集合。
- CAP特定场景:共享数据的互连节点的集合的读写场景。
- CA同时满足前提:不存在网络分区的情况下。
原创声明:本文系作者授权便宜云服务器开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权便宜云服务器开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。