面试商汤,效率太恐怖了。。。
面试商汤,效率太恐怖了。。。

Hi,我是Johngo~
今天看到一个帖子,说是商汤面试的氛围很好,面试的内容很仔细,而且整体下来的效率非常高。
大家经历过的商汤是不是这样?~

整个过程聊下来,就感觉算法岗,对于论文非常的看重。
把研究生期间读过的、复现过的,发表过的,大概问了一遍。
论文这块非常的重要。
咱们先来介绍经典的5篇论文~
A Simple Framework for Contrastive Learning of Visual Representations
该论文介绍了一种名为柔性通讯引擎(SimCLR)的对比学习框架,该框架用于学习图像的视觉表示。对比学习是一种无监督学习方法,它使我们可以从未标记的数据中学习特征表示。在现实世界中,获得大量标记样本是非常困难和昂贵的,而对比学习则可以解决这个问题。
柔性通讯引擎是一个简单的框架,由两个关键组件组成:对比损失和数据增强。论文介绍了如何通过这两个组件来学习良好的图像表示。
论文的主要贡献包括:
- 提出了柔性通讯引擎(SimCLR)框架,该框架通过对比损失和数据增强来学习图像的视觉表示。该框架的设计简单且清晰,可以在大规模数据集上实现更好的性能。
- 提出了一种新的对比损失函数,称为评估剩余噪声(NT-Xent)损失。与传统的对比损失函数相比,NT-Xent损失可以更好地处理大规模数据集和大数量级的样本。
- 通过大量实验证明了柔性通讯引擎在图像分类任务上的优越性能。实验证明,SimCLR框架在大规模数据集上实现了与有标签数据训练相当的结果,这证明了对比学习的潜力。

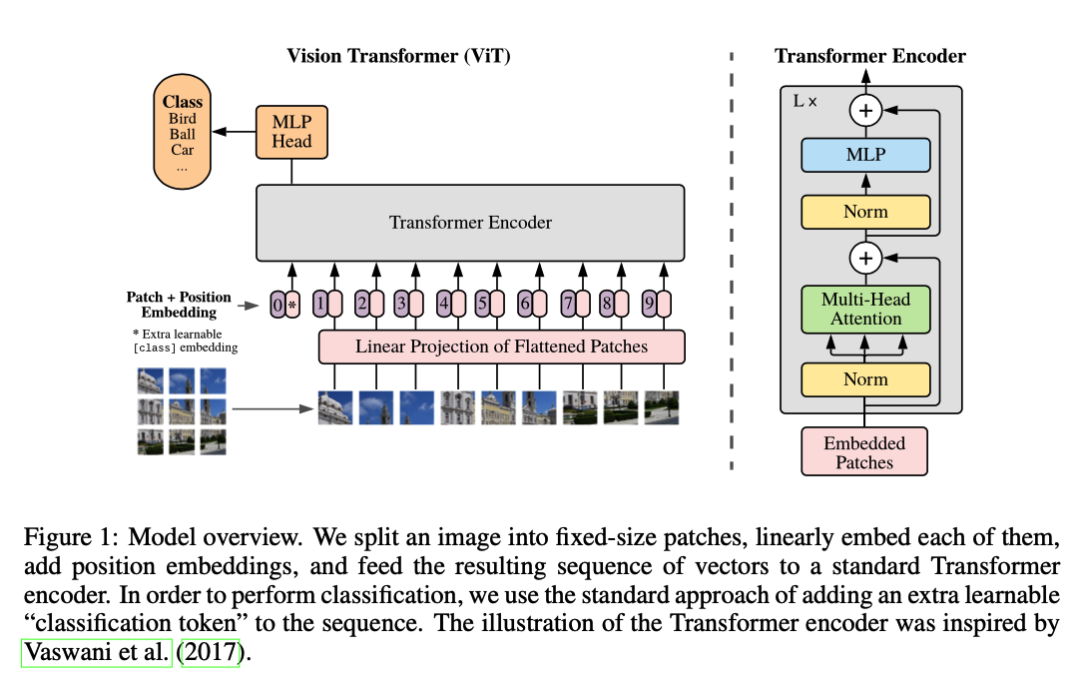
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
使用Transformer模型将图像划分为一个个固定大小的patch,然后将这些patch转化为序列输入,通过对这些序列进行预测来进行图像分类。这一基于Transformer的图像分类方法被称为ViT(Vision Transformer)。
在传统的卷积神经网络(CNN)中,图像通常被直接作为输入进行处理。相比之下,ViT将图像划分为较小的patch,然后将这些patch作为序列输入送入Transformer模型进行分类任务。这种方法的一个优势是能够处理不同大小的图像,而不需要调整网络结构。
本文的主要贡献可以总结:
- 提出了基于Transformer的图像分类方法ViT。通过将图像划分成patch,并将其作为序列输入,可以在不调整网络结构的情况下对不同大小的图像进行分类。
- 引入了一种新的预训练方法:ImageNet-21K。该预训练方法使用了一个庞大的图像数据集,包含2.1百万张图像,可以提升模型的性能。
- 在多个标准的图像分类基准数据集上进行了实验评估,包括ImageNet、CIFAR-100和Oxford Flowers 102。实验表明,ViT在这些数据集上取得了与传统CNN相媲美的甚至更好的性能。
Application of Quantum Pre-Processing Filter for Binary Image Classification with Small Samples
该论文主要研究了在小样本情况下,使用量子预处理滤波器进行二值图像分类的应用。传统的图像分类方法在小样本问题上存在一定的限制,而该论文提出了一种基于量子计算理论的新方法,旨在解决小样本分类问题。具体而言,该论文介绍了量子预处理滤波器的设计原理,并将其应用于二值图像分类任务中。
论文的主要贡献包括:
- 提出了一种基于量子计算理论的新方法,即量子预处理滤波器,用于解决小样本图像分类问题;
- 详细介绍了量子预处理滤波器的设计原理,包括其核心思想、计算公式以及实现步骤;
- 在经典图像分类数据集上进行了一系列实验,验证了量子预处理滤波器在小样本分类任务中的有效性;
- 与传统方法进行了对比实验,证明了量子预处理滤波器相比于传统方法在小样本分类问题上的优越性。

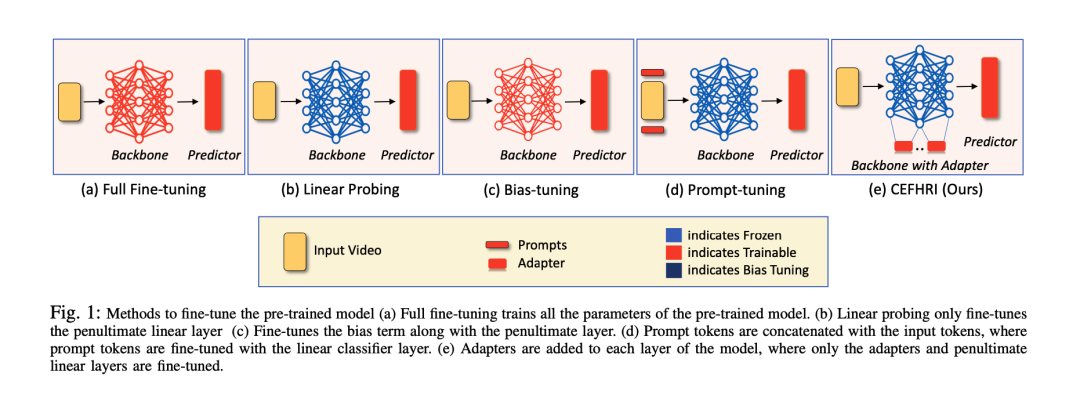
CEFHRI: A Communication Efficient Federated Learning Framework for Recognizing Industrial Human-Robot Interaction
CEFHRI框架旨在通过在工业设施中本地化和分布式地训练模型,从而在保护数据隐私的同时,实现工业HRI图像分类任务。该框架结合了联邦学习的概念和通信效率优化技术,以实现高效的模型训练和通信。作者采用了基于CNN(卷积神经网络)的模型来处理工业HRI图像,并通过联邦学习来实现模型的分布式训练。为了减少通信开销,作者还提出了一种基于差异压缩和聚合的通信优化技术。
主要贡献包括:
- 提出了CEFHRI框架,这是一种用于工业HRI图像分类的通信高效的联邦学习框架。
- 结合了CNN模型和联邦学习技术,以在保护数据隐私的前提下实现模型训练。
- 引入了基于差异压缩和聚合的通信优化技术,以减少通信开销并提高通信效率。
- 在多个工业数据集上进行了实验验证,证明了CEFHRI框架在工业HRI图像分类任务中的有效性和性能优势。
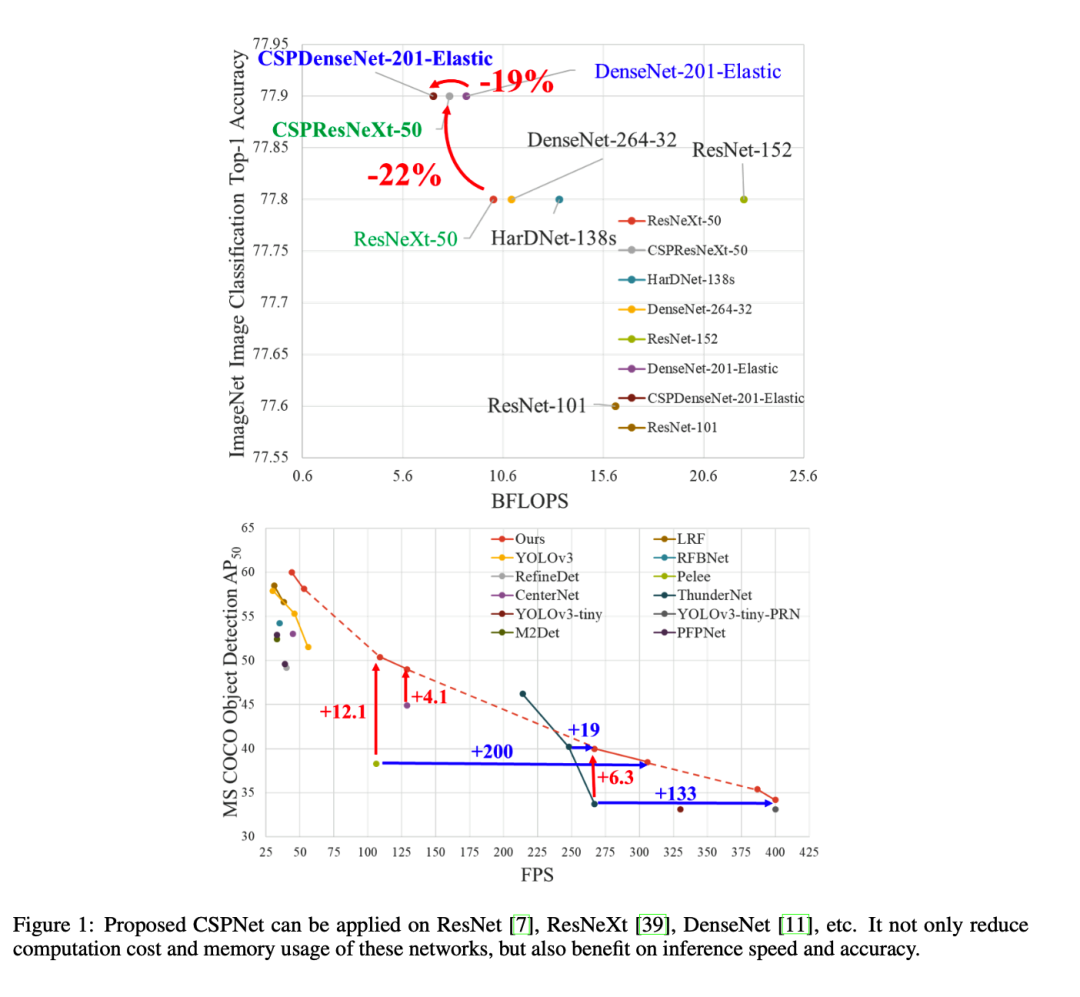
CSPNet A New Backbone that can Enhance Learning Capability of CNN。该论文
该论文提出了一种新的卷积神经网络(CNN)的主干结构——CSPNet(Cross Stage Partial Network),旨在增强CNN的学习能力,从而提高图像分类任务的性能。
论文中指出,传统的CNN网络往往在网络底层和顶层之间存在一种信息传递不畅的问题。为了解决这个问题,CSPNet采用了一种称为“Cross Stage Partial”的模块结构,通过在CNN的不同阶段引入部分连接来加强底层和顶层之间的信息流动。
具体来说,CSPNet的主体结构由两个关键组件组成:CSP组件和残差组件。CSP组件包括一个卷积层和一个跨阶段部分连接层,用于引导底层特征与顶层特征的融合。残差组件则负责实现网络层与网络层之间的残差学习,以进一步提升特征的表达能力。
论文的主要贡献包括:
- 提出了一种新的CNN网络结构CSPNet,通过引入Cross Stage Partial模块来增强网络的学习能力和改善信息传递效果。
- 在多个经典的图像分类数据集上进行了实验,并与其他流行的网络结构进行了对比,证明了CSPNet具有显著的性能提升。