国产黑马砸来百万算力福利,Llama 3微调快去冲!H800点击就送,1.99元玩转4090
国产黑马砸来百万算力福利,Llama 3微调快去冲!H800点击就送,1.99元玩转4090

编辑:编辑部
Llama 3诞生整整一周后,直接将开源AI大模型推向新的高度。
Meta官方统计显示,模型下载量已突破120万次,在最大开源平台HF上已经有600+微调的Llama 3变体。
可见,Llama 3已经成为AI应用的最新优选。
问题来了,想要动手微调测试Llama 3,如何用?
最新安利来了!
最近,小编无意发现潞晨云上的算力价格非常便宜,比如H800-80GB-NVLINK只需5.99元/卡时,而4090甚至低至1.99元/卡时。
与此同时,还会附赠免费的测试代金券。


一通测试下来,小编们发现不仅便宜,而且非常方便好用和功能丰富。
最关键的是,它还有配套的从推理到微调和预训练的实践教程。
体验地址在这里:https://cloud.luchentech.com/
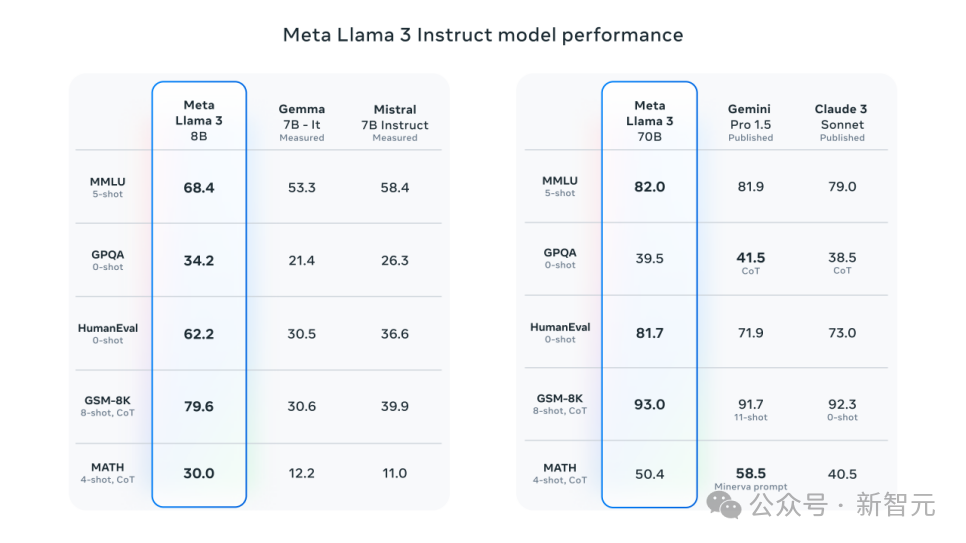
据介绍,在64卡H100集群上,经过潞晨Colossal-AI优化,相比微软+英伟达方案,可提升Llama 3 70B的训练性能近20%,推理性能也优于vLLM等方案。
不仅好用还便宜
想体验Llama 3等AI任务,还需要有GPU等算力支持。目前主流的AI云主机有AWS、AutoDL、阿里云等。但GPU资源不仅昂贵稀缺,供应商普遍还要求使用者必须预先进行高额投入,按年或提前数个月预付定金。
潞晨云不仅提供了便捷易用的AI解决方案,还为力求为广大AI开发者和其他提供了随开随用的廉价算力:
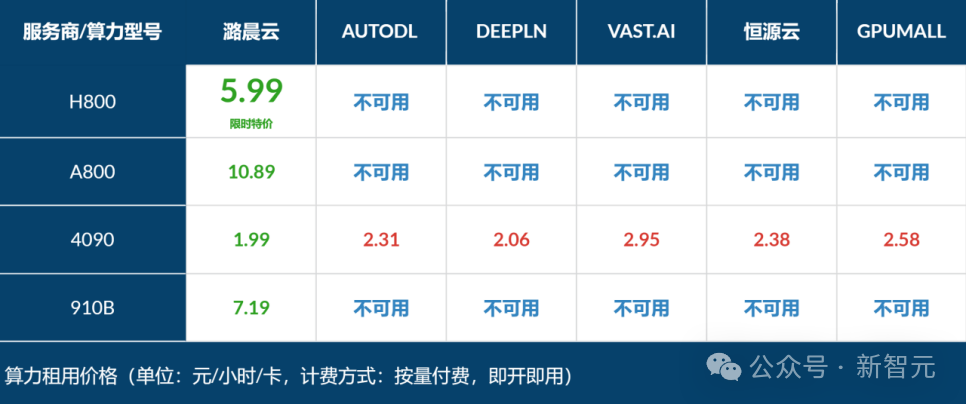
价格信息统计于2024年4月16日,普通账号可按需按量开启的价格及可用性,大型云厂商一般仅支持老旧型号算力(Nvdia V100/P100等)按需按量使用,美元-人民币汇率换算为1:7.2368
原价19.99元/卡时的H800-80GB-NVLINK,限时特供低至5.99元/卡时!
对于使用较稳定的长期需求,在潞晨云还可以按月、按年租用,获得进一步折扣。
潞晨云还为新用户准备了多种形式的优惠代金券活动,注册即可白嫖H800、A800、4090、910B等高端算力,构建属于自己的AI大模型!(新注册用户自动获得代金券额度)
手把手教你部署和训练Llama 3
创建云主机
打开算力市场,按照筛选目标算力。

可以看到如图所示的控制台页面,右边是两台可用的服务器,每台上有8块可租用的GPU,我们选择一个,点击「8卡可租」按钮,进入算力市场界面。

在租用配置选择界面,为自己的云主机取一个名字并选择任务所需数量的显卡,Llama 3 8B推理可以在单卡H800上完成),因此,此处选择1卡H800。
推理
Colossal-Inference现已适配支持了Llama 3推理加速。在潞晨云,你可以选择推理镜像,使用Colossal-Inference进行推理优化提速,体验Llama 3的自然语言生成能力。
前期准备
Llama 3模型权重已准备好,无需额外安装步骤。
推理生成
运行生成脚本
PRETRAINED_MODEL_PATH="/root/notebook/common_data/Meta-Llama-3-8B" # huggingface or local model path
cd ColossalAI/examples/inference/
colossalai run --nproc_per_node 1 llama_generation.py -m $PRETRAINED_MODEL_PATH --max_length 80进行多卡TP推理,如下例使用两卡生成
colossalai run --nproc_per_node 2 llama_generation.py -m $PRETRAINED_MODEL_PATH --max_length 80 --tp_size 2吞吐脚本
运行吞吐Benchmark测试
PRETRAINED_MODEL_PATH="/root/notebook/common_data/Meta-Llama-3-8B"
git pull # update example benchmark from branch feature/colossal-infer
cd ColossalAI/examples/inference/
python benchmark_llama3.py -m llama3-8b -b 32 -s 128 -o 256 -p $PRETRAINED_MODEL_PATH单卡H100对Llama 3-8B进行Benchmark结果与vLLM对比(例:输入序列长度128,输出长度256)

微调与继续预训练
潞晨云在原有 Llama 2 汉化项目中,支持了 Llama 3 的继续预训练与微调。在这里,你可以通过选择训练镜像,快速对 Llama 3 进行继续预训练与微调。

前期准备
1. 编译安装 Colossal-AI
cd /root/ColossalAI
BUILD_EXT=1 pip install .2. 创建训练需要的文件夹
mkdir /root/training_outputs
mkdir /root/training_outputs/checkpoints
mkdir /root/training_outputs/configs
mkdir /root/training_outputs/tensorboards3. 修改 hostfile
cd /root/ColossalAI/applications/Colossal-LLaMA/
cp hostfile.example hostfile注:可通过 apt install iproute2 -y 在镜像中安装 ip addr 指令查看镜像内 ip 地址
数据准备
当前路径:/root/ColossalAI/applications/Colossal-LLaMA/
1. 继续预训练
{"source": "", "target": "Lionel Andrés Messi(Spanish pronunciation: [ljo?nel an?d?es ?mesi] (i); born 24 June 1987), also known as Leo Messi, is an Argentine professional footballer who plays as a forward for and captains both Major League Soccer club Inter Miami and the Argentina national team.", "category": "sports"}
{"source": "猜谜语:一身卷卷细毛,吃的青青野草,过了数九寒冬,无私献出白毛。(打一动物)", "target": "白羊", "category": "riddle"}python prepare_pretrain_dataset.py \
--data_input_dirs "Directory that contains one or more JSONL file(s)>" \
--tokenizer_dir "Tokenizer directory" \
--data_output_dirs "Spliced tokenized output" \
--max_length 8192 \
--num_spliced_dataset_bins 102. 微调
{"messages": [{"from": "human", "content": "What are the three primary colors?"}, {"from": "assistant", "content": "The three primary colors are red, blue, and yellow."}]}
{"messages": [{"from": "human", "content": "解释个人电脑和服务器之间的区别。"}, {"from": "assistant", "content": "个人电脑和服务器是两种不同类型的计算机系统,它们的主要区别在于用途、硬件配置和性能。个人电脑,顾名思义,是为个人使用而设计的计算机。它们通常用于日常的工作、娱乐和学习,可以运行各种各样的应用程序和游戏。个人电脑的硬件配置一般是按照标准配置来设计的,不过也可以根据个人需求进行定制。而服务器是为了满足大量用户的需求而设计的计算机系统,它们通常用于为用户提供各种网络服务,如网站、电子邮件和文件传输等。服务器通常需要高性能的硬件配置,并且可以承受高负载和长时间的运行。由于服务器需要支持大量用户的访问,它们通常配备多核处理器、大容量内存和大容量硬盘驱动器,以提高系统的运行速度和稳定性。总之,个人电脑和服务器之间的主要区别在于它们的用途、硬件配置和性能。个人电脑用于个人使用,而服务器用于支持大量用户的访问。服务器的硬件配置通常比个人电脑更高,以保证系统的性能和稳定性。"}]}python prepare_sft_dataset.py \
--data_input_dirs "Directory that contains one or more JSONL file(s)>" \
--tokenizer_dir "Tokenizer directory" \
--data_output_dirs "Spliced tokenized output" \
--max_length 8192 \
--num_spliced_dataset_bins 10 \
--llama_version 3运行成功后,data_output_dirs 文件夹内会自动生成 3 个子文件夹,其中,arrow 文件夹中的数据可用来直接训练。
此外,潞晨云还提供了简单数据集以供测试,处理好数据集可见:/root/notebook/common_data/tokenized-cpt-data
训练脚本
当前路径:/root/ColossalAI/applications/Colossal-LLaMA/
1. 修改 config 文件
cp train.example.sh train.sh
#更新训练脚本2. 参考训练脚本
PROJECT_NAME="LLaMA-3-8B-cpt"
PARENT_SAVE_DIR="/root/training_outputs/checkpoints/" # Path to a folder to save checkpoints
PARENT_TENSORBOARD_DIR="/root/training_outputs/tensorboards/" # Path to a folder to save logs
PARENT_CONFIG_FILE="/root/training_outputs/configs/" # Path to a folder to save training config logs
PRETRAINED_MODEL_PATH="/root/notebook/common_data/Meta-Llama-3-8B" # huggingface or local model path
# 以预置已处理数据集为例
declare -a dataset=(
/root/notebook/common_data/tokenized-cpt-data/arrow/part-00000
/root/notebook/common_data/tokenized-cpt-data/arrow/part-00001
/root/notebook/common_data/tokenized-cpt-data/arrow/part-00002
)
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
SAVE_DIR="${PARENT_SAVE_DIR}${FULL_PROJECT_NAME}"
CONFIG_FILE="${PARENT_CONFIG_FILE}${FULL_PROJECT_NAME}.json"
colossalai run --nproc_per_node 8 --hostfile hostfile --master_port 31312 train.py \
--pretrained $PRETRAINED_MODEL_PATH \
--dataset ${dataset[@]} \
--plugin "zero2" \
--save_interval 400 \
--save_dir $SAVE_DIR \
--tensorboard_dir $TENSORBOARD_DIR \
--config_file $CONFIG_FILE \
--num_epochs 1 \
--micro_batch_size 2 \
--lr 1e-4 \
--mixed_precision "bf16" \
--grad_clip 1.0 \
--weight_decay 0.01 \
--warmup_steps 100 \
--use_grad_checkpoint \
--use_flash_attn \其他训练详情可参考:https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA
大规模训练
对于大规模预训练等场景,结合Llama 3 序列变长、embedding增大等特性,潞晨云针对3D混合并行场景进行了优化,通过自定义流水线切分、gradient checkpoint策略,可以进一步精细化控制每个GPU的内存占用和速度,从而达到整体训练效率的提升。

潞晨云使用整数线性规划搜索出在64x H100上最适合Llama 3 70B的切分、gradient checkpoint策略,最终训练可以达到每卡410+ TFLOPS的卓越性能。
详情可参考:https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/llama
此例子附上了潞晨云测试时使用的配置。使用方法如下:
git clone https://github.com/hpcaitech/ColossalAI
cd ColossalAI/examples/language/llama
BUILD_EXT=1 pip install -U git+https://github.com/hpcaitech/ColossalAI
pip install -r requirements.txt
export PYTHONPATH=$(realpath ..)