华为诺亚| 提出自推测解码框架:Kangaroo,降低成本,提升大模型推理效率!
华为诺亚| 提出自推测解码框架:Kangaroo,降低成本,提升大模型推理效率!

引言
为了提升大模型的推理效率,本文作者提出一种新型的自推测解码框架:Kangaroo,该框架将大模型的一个固定浅层子网络作为自草稿模型(self-drafting model),同时引入双提前退出机制,在保持高Token接受率的同时,显著提高了大模型的推理速度和参数利用效率。在Spec-Bench基准测试中实现了高达1.7倍的速度提升,并且在参数数量上比Medusa-1模型少了88.7%。
https://arxiv.org/pdf/2404.18911
背景介绍
大模型(LLMs)无疑在各种NLP任务中展现出了卓越的性能。但受内存带宽的限制,LLMs在自回归解码过程中会出现延迟,从而影响模型生成效率。比如使用四个NVIDIA V100 GPU解码Vicuna-33B模型,每秒只能产生七个新Token。为应该该项挑战,研究人员提出了一种称为推测性解码(Speculative Decoding, SD)的技术,旨在通过并行验证草图模型(Draft Model)生成的多个Token来加速自回归解码。给定
个草图Token(Draft Tokens),SD可以在每个大模型的前向传递中生成
到
个新Token。
SD技术的有效性主要取决于以下两个因素:
- 草图模型(Draft Model)与目标LLM之间存在差距(gap)。人们通常在大型语料库上从头开始训练一个小型草图模型,来加速同一系列的大型LLM,例如,为了加速LLaMA7B模型,训练了LLaMA-68M模型。然而,这种特定任务模型的训练成本会很高,这限制了其在实际场景中的应用。
- 草图模型存在推理延迟。如果小型模型的推理成本与目标大模型相比可以忽略不计,那么端到端的加速比直接与Token接受率成正比。
为解决以上问题,有些专家提出self-drafting方法而不是依赖外部Draft模型,比如,LLMA和REST则通过从参考文本中选择文本片段或从数据库中检索相关Token来生成Draft Token,除此之外,Medusa在最后一个解码层之上训练了多个时间独立的前馈网络(FFN)头,尽管Medusa能够有效地在相邻位置生成多个Draft Token,但其Token接受率并不高,如下图所示。

此外,如果只关注Token接受率而不考虑生成Draft Token的延迟,可能会导致端到端加速效果不佳。例如,在数学推理子任务中,Lookahead达到了与Kangaroo相当的Token接受率,显著优于Medusa。但由于其生成Draft Token的效率低于Medusa,其端到端加速比略低于Medusa。
基于以上问题,本文作者提出了一种基于双提前退出机制的自推测解码框架:Kangaroo,该框架既高效又强大,其参数量仅为Medusa头的11.3%。另外,为了减少不必要的成本,作者还提出了早退出机制来生成Draft Token。
Kangaroo框架
Kangaroo框架是一种创新的自推测解码方法,专为提高大型语言模型(LLMs)的推理效率而设计。如下图所示:
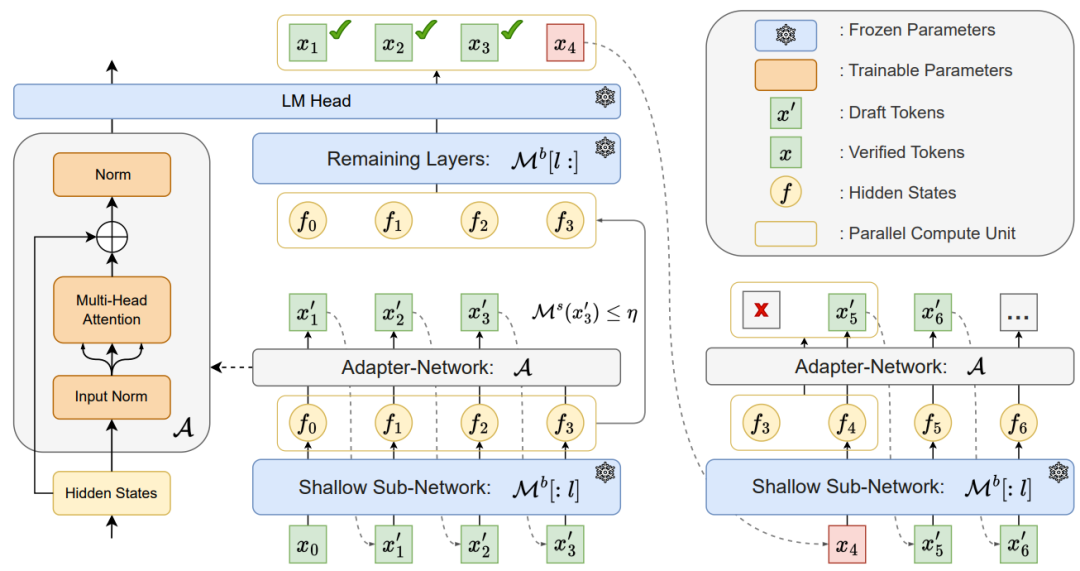
该框架的核心在于利用大型模型的一个固定浅层子网络作为自草稿模型(self-drafting model),并在此基础上训练一个轻量级的适配器模块,以便高效地生成Draft Token。适配器网络由一个多头注意力机制和两个标准化层组成,这样的设计不仅简单,而且高效。
「提前退出机制」 提前退出是一种在模型不必完成所有层的计算时就可以开始输出结果的技术。在Kangaroo框架中提前退出机制被用作self-drafting模型的一部分,以动态决定在生成Draft Token时何时退出
「Kangaroo动态退出机制」,即在自草稿模型生成Draft Token时,一旦当前Token的置信度低于预设阈值,就会触发退出,从而避免在难度较高的Token上进行不必要的计算。这种动态的起草步骤与固定起草步骤相比,可以更灵活地适应不同的上下文场景,面对困难样本可以减少不必要的推测,同时把控对简单Token的推测机会。
「在训练适配器网络时」,Kangaroo使用交叉熵损失函数来最大化草稿Token的接受率,并通过实验确定了最佳的退出层和置信度阈值。在Spec-Bench基准测试中,Kangaroo在单序列验证下实现了最高1.7倍的速度提升,显著超过了其他自推测解码方法,如Medusa和Lookahead,同时大大减少了额外参数的需求。
实验结果
下图展示了在Spec-Bench的数学推理子任务中,不同自推测解码方法的Token接受率。「Kangaroo在各个Token位置上都显示出了较高的接受率」。同时也比较了在Spec-Bench的四个子任务中的端到端速度提升比率。Kangaroo在所有子任务中都实现了优于或至少可比于其他方法的速度提升。
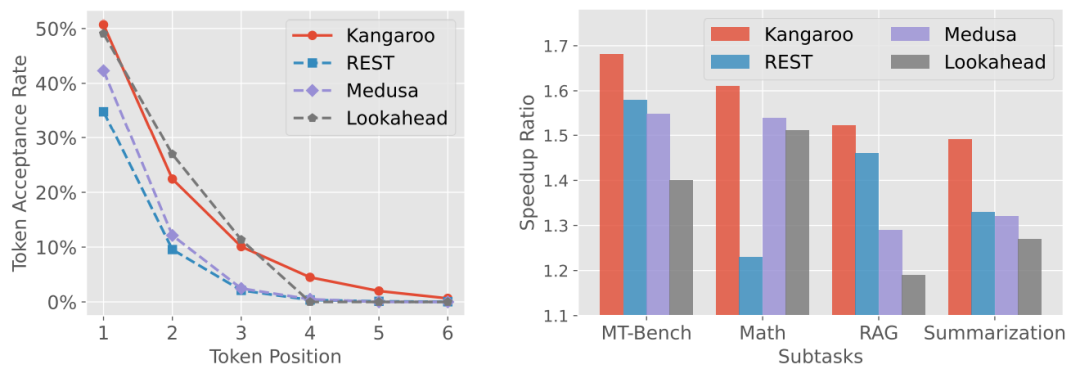
下图展示在Spec-Bench上不同方法的速度提升和压缩率的详细比较。「Kangaroo在7B和13B模型上均展现出了优秀的速度提升和合理的压缩率」。