大模型探索:阿里向量检索服务DashVector

一 背景
大模型无疑是这两年最火的概念,国内外各厂商都不甘示弱纷纷推出自己的大模型能力和应用。废话不多说,在实际的大模型应用中,向量检索服务无疑是目前不可缺少的一个重要部分,几乎所有的prompt工程都离不开,因此这里从阿里的DashVector入手,从实际应用角度来了解什么是向量检索服务,以及怎样使用。
之所以选择阿里的向量检索,是因为有些公司会使用钉钉作为通讯工具,以及在钉钉上的一些工作流和应用。这样在选型的时候考虑对接的工作量和一些非技术层面因素,就会优先考虑阿里系产品。
二 阿里DashVector简介
向量检索服务DashVector基于阿里云自研的Proxima向量引擎,面对非结构化数据(图片、视频、文本、语音、DNA、分子式等),提供具备垂直和水平扩展的高效相似向量比对服务。使用DashVector服务能有效提升向量检索效率,实现针对非结构化数据的高性能向量检索服务,可广泛应用于大模型搜索、多模态搜索、AI搜索、分子结构分析等几乎所有的 AI 搜索场景。
这是阿里云官方网站(https://dashvector.console.aliyun.com/cn-hangzhou/overview)上对DashVector的描述。简单理解,使用向量检索的云服务,就是避免我们自己搭建向量数据库、同时简化文本转向量的计算量,以及执行向量检索的工作,从而快速搭建应用。有精力和能力,其实也可以自己来进行环境搭建和逐步优化,对于深入学习会更加有利。当然,这也会是下一篇将要探讨的内容。
三 操作实践
3.1 环境准备
3.1.1 DashVector准备
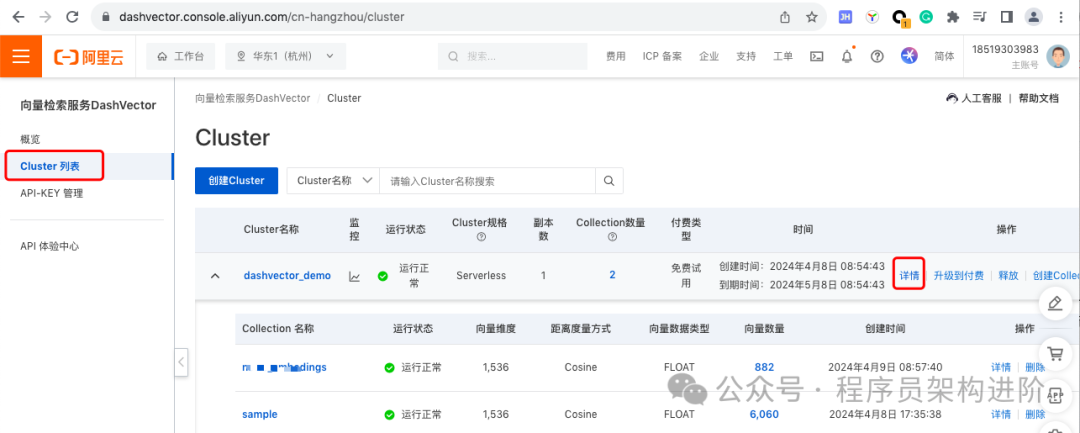
DashVector服务使用官网介绍很清楚,这里不再赘述。参照流程图和链接操作,创建API-KEY-->创建试用Cluster(可理解为向量数据库)-->创建Collection(理解为向量库表),然后就可以通过sdk或http API进行向量操作。

需要注意的是,在完成Cluster和Collection创建后,我们需要在Cluster的详情中查到Endpoint,后续通过sdk或http api的向量操作都需要使用到这个Endpoint信息。简单理解,这就是一个服务实例的子域名。

3.1.2 DashScope
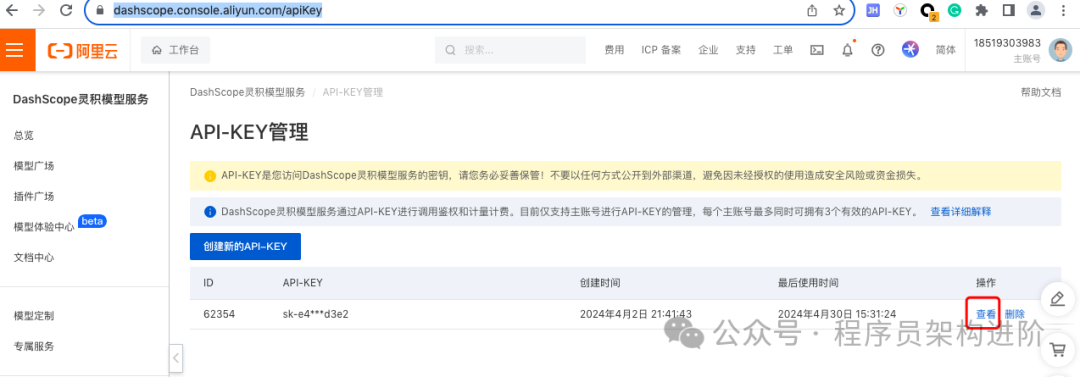
我们在做向量检索前,通常需要针对原始问题做向量化处理,然后才能拿着这个向量到向量库中进行检索。所以,在计算问题的向量时还会使用到阿里的灵积(DashScope)服务。可直接在https://dashscope.console.aliyun.com/apiKey 申请api-key,通过查看按钮复制出来。
3.2 一个基于专属知识问答的应用示例
3.2.1 应用简介
有了上述准备,接下来我们就可以完成下面的一个应用示例。参考官方文档:《DashVector x 通义千问大模型:打造基于专属知识的问答服务》(https://help.aliyun.com/document_detail/2510235.html?spm=a2c4g.2510225.4.3.11f0250eFnZsmy&scm=20140722.H_2510235._.ID_2510235-OR_rec-V_1)

简单理解,可以分为以下步骤:
(1)本地知识库的向量化:录入一篇/多篇自己准备的文档到向量库作为知识库内容;
(2)用户通过接口输入问题,服务端把问题文本计算为向量;
(3)利用DashVector的API查询相似向量,召回相似度最高的文档;
(4)通过召回的文档+prompt,调用大模型能力进行回答
3.2.2 本地知识向量化
这一步通常都可以由脚本完成,所以可以考虑直接使用官方的python代码示例。在安装完dashvector和dashscope的python依赖之后:
pip3 install dashvector dashscope通过下面的脚本来实现文档处理并把包含向量化结果的数据上传到DashVector服务:
import os
import dashscope
from dashscope import TextEmbedding
from dashvector import Client, Doc
# 文档批量处理,batch_size表示批量处理的文档数量
def prepare_data(path, batch_size=25):
batch_docs = []
for file in os.listdir(path):
with open(path + '/' + file, 'r', encoding='utf-8') as f:
batch_docs.append(f.read())
if len(batch_docs) == batch_size:
yield batch_docs
batch_docs = []
if batch_docs:
yield batch_docs
# 生成embeddings
def generate_embeddings(news):
rsp = TextEmbedding.call(
model=TextEmbedding.Models.text_embedding_v1,
input=news
)
embeddings = [record['embedding'] for record in rsp.output['embeddings']]
return embeddings if isinstance(news, list) else embeddings[0]
if __name__ == '__main__':
dashscope.api_key = '{your-dashscope-api-key}' #注意,这个不是DashVector的apikey,不要混了
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 创建集合:指定集合名称和向量维度, text_embedding_v1 模型产生的向量统一为 1536 维
rsp = client.create('news_embedings', 1536)
assert rsp
# 加载语料
id = 0
collection = client.get('news_embedings')
for news in list(prepare_data('CEC-Corpus/raw corpus/allSourceText')):
ids = [id + i for i, _ in enumerate(news)]
id += len(news)
vectors = generate_embeddings(news)
# 写入 dashvector 构建索引
rsp = collection.upsert(
[
Doc(id=str(id), vector=vector, fields={"raw": doc})
for id, vector, doc in zip(ids, vectors, news)
]
)
assert rsp注意:如果我们分批多次调用上述脚本处理文档,一定要注意第45行的id = 0,由于录入集合时使用的是collection.upsert,所以当对已有的文档id 做upsert时会覆盖原有的文档内容。一定确认没有问题才能操作。否则就先查询最大的id,然后从下一个不存在的文档id开始进行下一批文档处理,避免造成不在预期内的文档覆盖。
文档格式txt文本即可。如果想效果更好,也可以提前做一些处理,例如有明确Q&A回答预期的,可以把问答对作为文档内容。
3.2.3 问题文本向量化及向量检索
from dashvector import Client
from embedding import generate_embeddings
def search_relevant_news(question):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取刚刚存入的集合
collection = client.get('news_embedings')
assert collection
# 向量检索:指定 topk = 1
rsp = collection.query(generate_embeddings(question), output_fields=['raw'],
topk=1)
assert rsp
return rsp.output[0].fields['raw']其中,generate_embeddings是3.2.2 本地知识向量化 代码中定义的函数,通过DashScope api对文本进行embedding。
3.2.4 构造prompt,向大模型提问
这一步比较简单,直接调用通义千问大模型的DashScope api,指定模型为 qwen-turbo,使用定义的提示词结合上一步召回的文档进行提问。
from dashscope import Generation
def answer_question(question, context):
prompt = f'''请基于```内的内容回答问题。"
```
{context}
```
我的问题是:{question}。
'''
rsp = Generation.call(model='qwen-turbo', prompt=prompt)
return rsp.output.text3.3 DashScope和DashVector的API
接下来我们补充一些基础知识。为了让大家快速了解DashVector的能力和应用场景,我把API描述放在了这里进行详细描述。
DashScope和DashVector都同时包含Python SDK、Java SDK,也支持使用Http协议直接进行curl调用。很显然,上面的例子虽然看起来简单,但python的脚本并不适合做实际的应用开发,更多的情况下还是需要通过Java SDK或者Http接口进行调用。在使用过程中,我发现官方文档的组织并不太友好,对新人来说需要一定的学习成本,这也是我整理这篇文章的初衷。下面我们就进行详细描述。
3.3.1 DashScope API
官方API详情:
https://help.aliyun.com/zh/dashscope/developer-reference/api-details?spm=a2c4g.11186623.4.2.28ec6a99T7vvvI&scm=20140722.H_2399481._.ID_2399481-OR_rec-V_1
SDK准备:https://help.aliyun.com/zh/dashscope/developer-reference/install-dashscope-sdk?spm=a2c4g.11186623.0.i4
3.3.1.1 依赖引入
最新的dashscope-sdk-java版本可从下面代码注释中的maven库获取。截至目前(2024-05),最新的版本是2.12.0。
<!-- https://mvnrepository.com/artifact/com.alibaba/dashscope-sdk-java -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>the-latest-version</version>
</dependency>3.3.1.2 SDK使用示例与最佳实践
参考下面示例:
// 需要引入的依赖包
import com.alibaba.dashscope.embeddings.TextEmbedding;
import com.alibaba.dashscope.embeddings.TextEmbeddingParam;
import com.alibaba.dashscope.embeddings.TextEmbeddingResult;
import com.alibaba.dashscope.utils.JsonUtils;
/**
* 生成文档的embedding
*/
TextEmbeddingParam param = TextEmbeddingParam.builder()
.apiKey(llmAliConfig.getDashscopeApiKey())
.model(TextEmbedding.Models.TEXT_EMBEDDING_V1)
.text(query)
.build();
TextEmbedding textEmbedding = new TextEmbedding();
TextEmbeddingResult textEmbeddingResult = textEmbedding.call(param);
log.info("query textEmbeddingResult:{}", textEmbeddingResult.getOutput());
/**
* 封装文档检索 request, 传入embedding
*/
List<Double> embeddings = textEmbeddingResult.getOutput().getEmbeddings().get(0).getEmbedding();其中,llmAliConfig是一个常量类,可以直接替换成你申请的DashScope API Key即可;model参数是指定使用的Embedding模型,默认推荐使用的是TEXT_EMBEDDING_V1;text是要进行embedding的原始文本。
第16行的textEmbedding.call(param) 就是利用sdk封装的方法执行embedding过程。
Java sdk的最佳实践可参考:
https://help.aliyun.com/zh/dashscope/support/java-sdk-best-practices?spm=a2c4g.11186623.0.i11
通过查看源码,可以定位到ClientProviders,这个方法用于创建客户端。通过下面的代码可以看出,支持http 和 websocket两种协议,并且默认使用http协议。
public static HalfDuplexClient getHalfDuplexClient(ConnectionOptions options, String protocol) {
if (protocol == null) {
protocol = "https";
}
if (options == null) {
return (HalfDuplexClient)(protocol.toLowerCase().startsWith("http") ? new OkHttpHttpClient(OkHttpClientFactory.getOkHttpClient()) : new OkHttpWebSocketClient(OkHttpClientFactory.getOkHttpClient()));
} else {
return (HalfDuplexClient)(protocol.toLowerCase().startsWith("http") ? new OkHttpHttpClient(OkHttpClientFactory.getNewOkHttpClient(options)) : new OkHttpWebSocketClient(OkHttpClientFactory.getNewOkHttpClient(options)));
}
}3.3.1.3 HTTP API
除了上述java 和pythoy的sdk,我们也可以直接通过http接口调用dashscope的能力。其实最重要的就只有下面一个跟大模型的交互接口:
https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation
调用方式:POST
header和body参数如下所示:
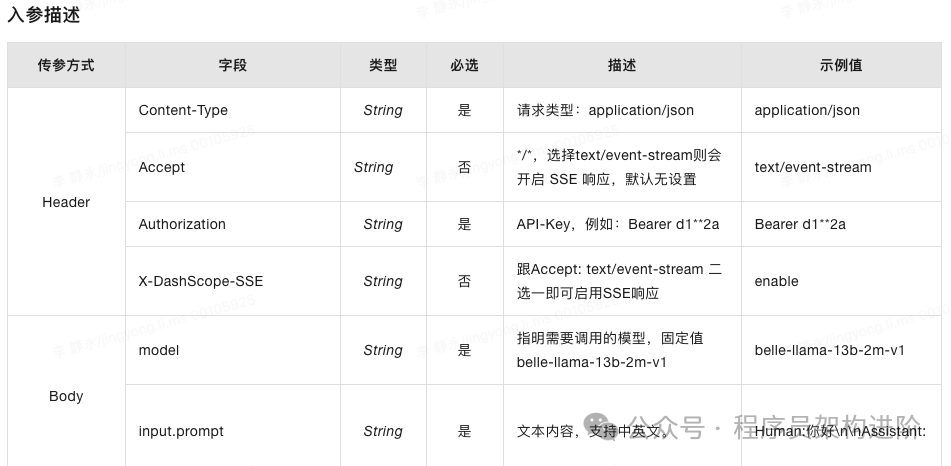
更直接的示例,直接通过curl命令请求:
curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation' \
--header 'Authorization: Bearer <your-dashscope-api-key>' \
--header 'Content-Type: application/json' \
--data '{
"model": "belle-llama-13b-2m-v1",
"input": {
"prompt": "Human:你好\n\nAssistant:"
},
"parameters":{
}
}'返回示例如下,我们可以从output:text获取结果信息:
{
"output": {
"finish_reason": "stop",
"text": "你好!很高兴为你提供帮助。有什么我可以解答的问题或者需要协助的吗?"
},
"usage": {
"total_tokens": 42,
"output_tokens": 17,
"input_tokens": 25
},
"request_id": "44ec45fc-910f-91fb-971a-d3b6c29e969d"
}3.3.2 DashVector API
3.3.2.1 文档参考
https://help.aliyun.com/document_detail/2572893.html?spm=a2c4g.2572891.0.i0
- 新建Client
- Collection操作
- Doc 操作
- Partition操作
3.3.2.2 Java SDK使用示例
可参照SDK说明逐个尝试,这里就先不赘述,有问题欢迎在评论区留言探讨。

3.3.2.3 HTTP API
能力与Java SDK基本一致。针对我们在3.2章节的应用,这里主要使用的是检索Doc的API,所以这里也只单独介绍这个API。
使用的前提条件是(1)已创建Cluster:创建Cluster。(2)已获得API-KEY:API-KEY管理。通过下面接口提交请求:POST https://{Endpoint}/v1/collections/{CollectionName}/query
可以看到这里面有2个变量:Endpoint是分配的向量服务实例地址,CollectionName是我们要存入向量的集合名称。另外还需要的就是DashVector的API Key。
这个接口支持的检索能力包括:(1)根据向量进行相似性检索;(2)根据主键(对应的向量)进行相似性检索;(3)带过滤条件的相似性检索;(4)带有Sparse Vector的向量检索。
在我们的示例应用中,使用的是(1)根据向量进行相似性检索。请求示例如下:
curl -XPOST \
-H 'dashvector-auth-token: YOUR_API_KEY' \
-H 'Content-Type: application/json' \
-d '{
"vector": [0.1, 0.2, 0.3, 0.4],
"sparse_vector":{"1":0.4, "10000":0.6, "222222":0.8},
"topk": 1,
"include_vector": true
}' https://YOUR_CLUSTER_ENDPOINT/v1/collections/quickstart/query
注意:vector是输入的向量,实际上不会只有这几个维度,通常会超过1000维(dashvector控制台推荐的是1,536维)以保证能够体现文本之间的差异性,从而提升检索的准确度。topk表示查找几条结果,为1时表示只检索相似度最高的一个doc。
检索结果示例:
# {
# "code":0,
# "request_id":"ad84f7a0-b4b2-4023-ae80-b6f092609a53",
# "message":"Success",
# "output":[
# {
# "id":"2",
# "vector":[
# 0.10000000149011612,
# 0.20000000298023224,
# 0.30000001192092896,
# 0.4000000059604645
# ],
# "fields":{"name":null,"weight":null,"age":null},
# "score":1.46,
# "sparse_vector":{
# "10000":0.6,
# "1":0.4,
# "222222":0.8
# }
# }
# ]
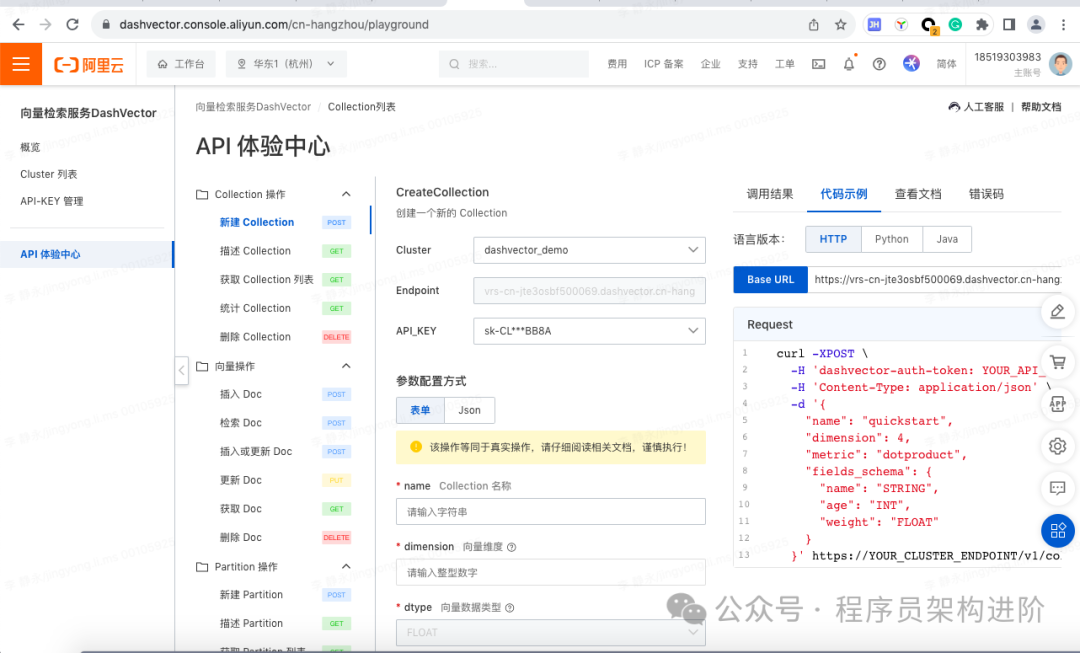
# }Dashvector有一项很好的功能,就是API体验中心。我们可以把它直接当做一个工具,也可以获取对应的代码,方便把相应的功能快速转换为可用的代码,非常推荐使用。
四 小结
如果你看到了这里,那么恭喜,这里有作为一名老开发人员最想说的一些话。官网的说明和示例,对于很多具备一定文档阅读和动手实践能力的开发人员来说,都足以跑通一个demo,甚至做一些简单改造做成一个看起来还不错的“产品”,那么这篇文章就显然有些繁冗拖沓,甚至是水的嫌疑。事实上,实际的应用开发往往都不会这么简单。几种SDK的选择,除了要考虑当前团队的技术栈之外,更重要的是要清楚SDK封装的约好,那么它暴露出来可以个性化调整的能力就越少,而大模型应用场景,如果要真正做到“实用”,一定免不了做大量的专项优化,才能够达到可用和好用的目标。有经验的朋友都清楚,“大而全”往往同时代表着只能做demo,只作为演示或者当个玩具。只有把深入的领域知识加入其中,才能成为有意义的应用。
另外在某些场景,例如对网络或协议在安全层面上有限制的情况,是http还是websocket,亦或者是grpc,绝不是“都行”、“看场景”几句敷衍的话术能解决的,这些都需要在深入理解的基础上作出准确的角色,这也是作为一名架构师的基本能力和职责。
下一篇文章,我们将继续深化这个示例应用,尝试自建向量数据库,并使用开源的embedding和向量检索方法替换掉当前的DashVector。也欢迎感兴趣的小伙伴们一起研究,共同成长。