统一元数据:业界方案设计概览
原创
背景介绍
针对元数据管理系统,各类开源方案在业界层出不穷,本文将列举和对比几个业内比较流行的元数据管理组件:
- Apache Atlas:基于Hadoop之上的元数据管理框架,主要以计算引擎Hook的方式,来获取元数据信息,并提供基本的元数据应用管理;
- LinkedIn DataHub:LinkedIn Warehows的前身,提供元数据搜索及集成功能;
- Lyft Amundsen:比较热门的元数据管理系统之一,由lyft开源的数据发现平台;
- Netflix Metacat:Netflix开源的Metacat项目,统一操作API,用于分离计算引擎与具体的数据源;
- 其他:整理各个大厂对外发布的元数据系统方案
开源系统
Apache Atlas
系统架构
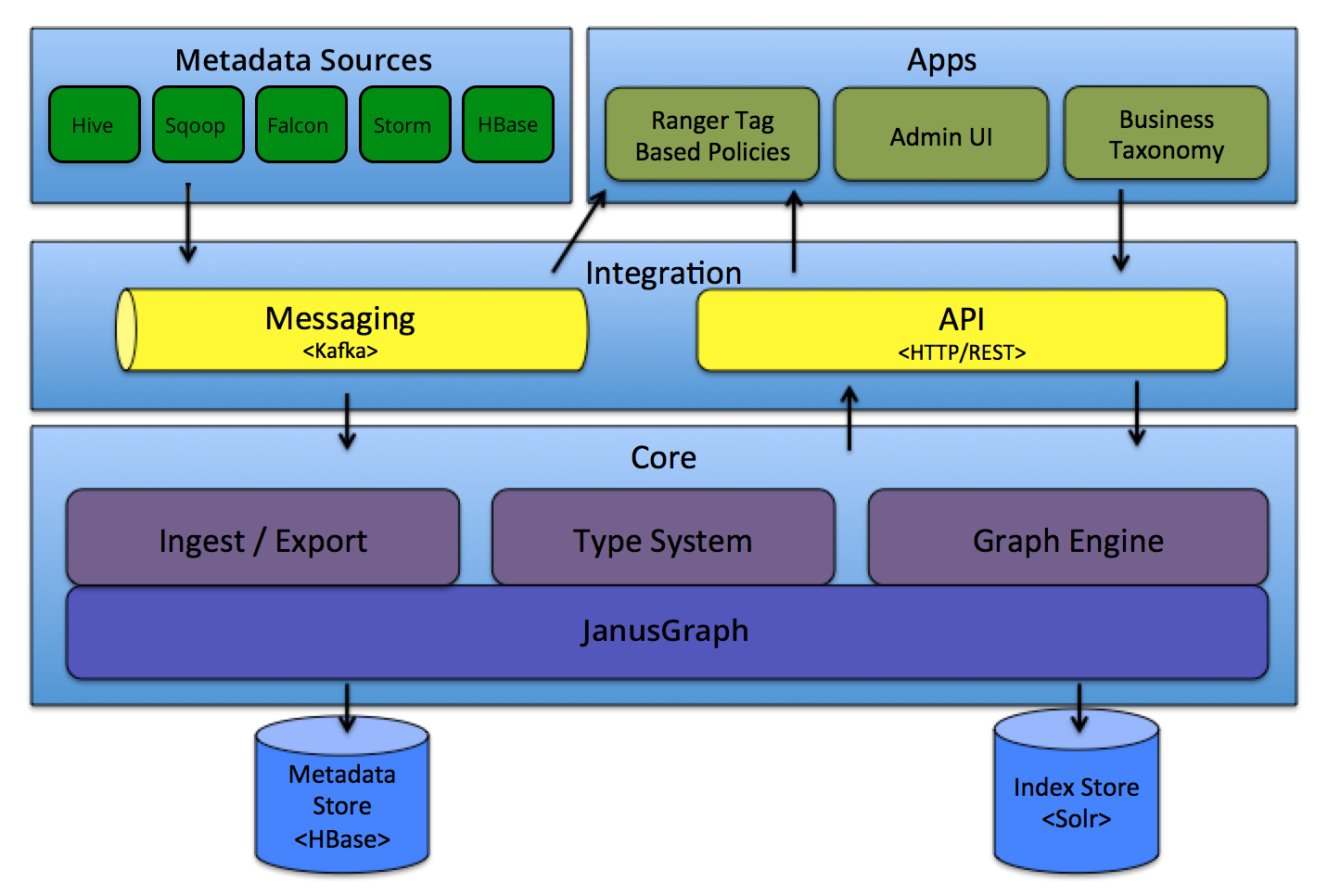
Apache Atlas为Hadoop大数据生态体系提供基本的元数据治理功能,主要的特性包括:数据分类:业务元数据标签、定义、注释;元数据搜索及血缘;集中操作审计;安全与策略引擎。系统组成模块架构如下:
- core:包含(1). 元数据定义的类型系统(元元模型) Type System、(2). 元数据基于消息中间件的数据接入/数据输出 Ingest/Export、(3). 图引擎 Graph Engine三大模块;
- integration:Atlas的元数据集成子系统,支持以REST API(关注业务元数据)和消息系统(关注技术元数据)两种方式将元数据导入Atlas;
- metadata sources:Atlas的数据源插件,目前支持从常见的大数据服务中捕获元数据以及其变更信息,并及时通知到消息中间件;支持HBase、Hive、Sqoop、Strom、Kafka等
- Apps:构建在Atlas元数据管理之上的元数据对外应用,主要包括Atlas Admin UI、Tag Based Policies
类型系统
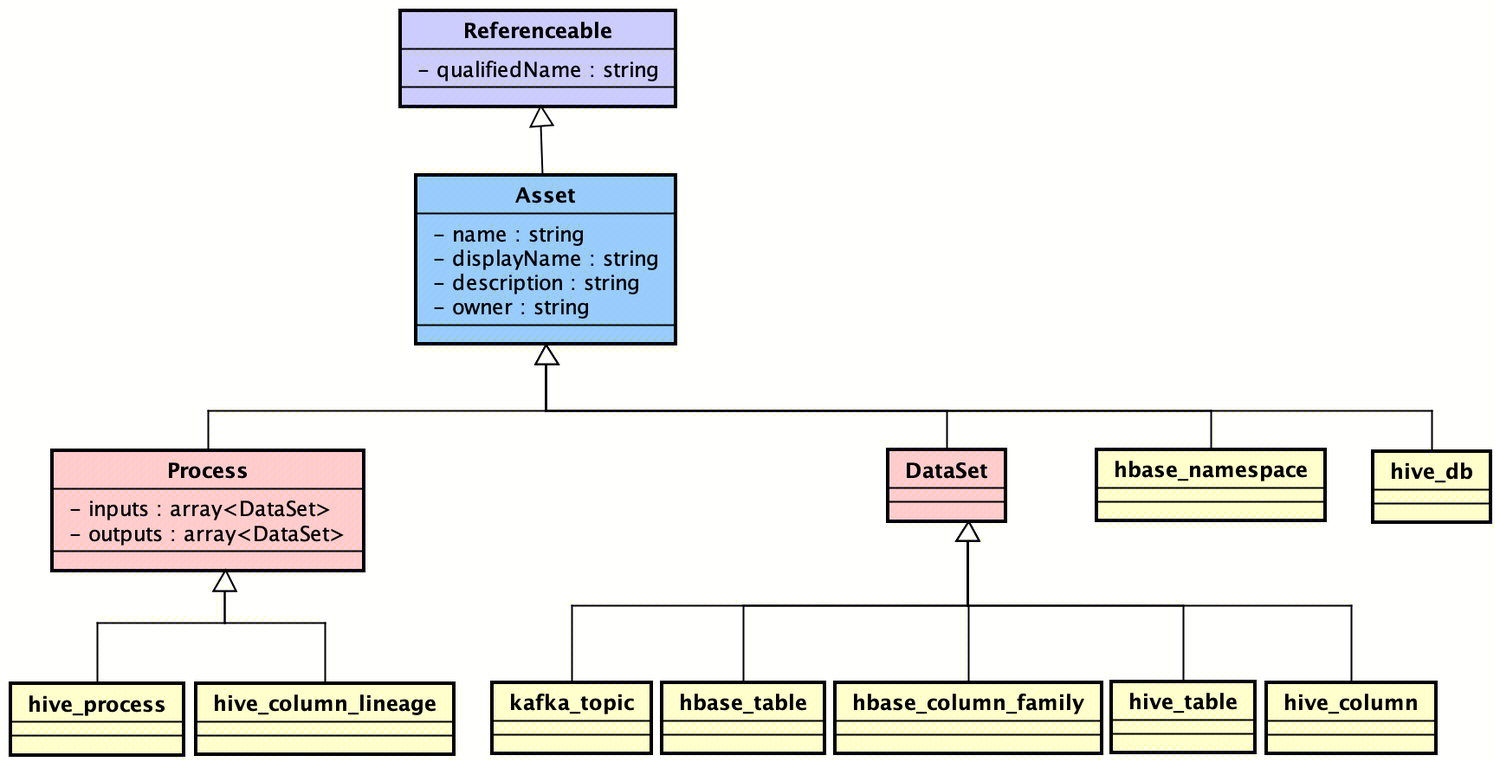
Atlas支持多类型的元数据接入,具有良好的可扩展性,目前支持数据源:HBase、Hive、Sqoop、Storm、Kafka。在Atlas中定义了类型系统(Type System),用于元模型管理,而每个entity即是对应的元数据记录,Data是具体元数据下的主数据信息,关系如下所示:

Atlas支持基于json文件定义类型,内置模型定义的源码路径:atlas/addons/models,json定义类型对应AtlasTypesDef(Atlas启动时会注册这些元模型类型),AtlasTypesDef中定义的基础元模型AtlasEntityDef继承关系如下:
- Referenceable:定义元数据的基本要素qualifiedName,元数据的唯一标识;
- Asset:定义元数据的基本数据资产信息,包括name,description等;
- DataSet:定义元数据的基本数据集,其实现扩展类包括:hive_table,kafka_topic等;
- Process:定义元数据流程信息,如hive_process(hive表血缘)
以AtlasEntityDef中类型名称为hive_tables为例的类型定义如下:
Name: hive_table
TypeCategory: Entity
SuperTypes: DataSet
Attributes:
name: string
db: hive_db
owner: string
createTime: date
lastAccessTime: date
comment: string
retention: int
sd: hive_storagedesc
partitionKeys: array<hive_column>
aliases: array<string>
columns: array<hive_column>
parameters: map<string>
viewOriginalText: string
viewExpandedText: string
tableType: string
temporary: booleanAtlasBaseTypeDef 抽象类是基本的元模型Type定义属性,用于拼装元模型定义(即AtlasTypesDef)。

AtlasType 是Atlas类型定义的抽象类,最常用的是AtlasEntityType 定义实体(Entity)元模型类型。

而具体的Entity元模型定义对象由AtlasEntity类定义,继承通用的Atlas结构化数据的定义类AtlasStruct,其中
- typeName:定义元数据类型,如Hive SQL处理流程(血缘)为hive_process;
- attributes:元数据的属性信息;
消息通知
Atlas基于消息中间件(Kafka)发送消息来实现元数据变更(新增/更新/删除)通知,发送的消息定义为ATLAS_ENTITIES,关注元数据变更的系统可监听该消息Topic变更实现功能自定义。
Atlas V1.0版本及之后使用Notifications V2,元数据以下变更操作会触发元数据消息发送:
ENTITY_CREATE: sent when an entity instance is created
ENTITY_UPDATE: sent when an entity instance is updated
ENTITY_DELETE: sent when an entity instance is deleted
CLASSIFICATION_ADD: sent when classifications are added to an entity instance
CLASSIFICATION_UPDATE: sent when classifications of an entity instance are updated
CLASSIFICATION_DELETE: sent when classifications are removed from an entity instance消息的格式如下所示:包括元数据对象,操作类型,元数据分类操作;
AtlasEntity entity;
OperationType operationType;
List<AtlasClassification> classifications;元数据操作类型OperationType包括:ENTITY_CREATE, ENTITY_UPDATE, ENTITY_DELETE,CLASSIFICATION_ADD, CLASSIFICATION_DELETE, CLASSIFICATION_UPDATE, RELATIONSHIP_CREATE, RELATIONSHIP_UPDATE, RELATIONSHIP_DELETE。
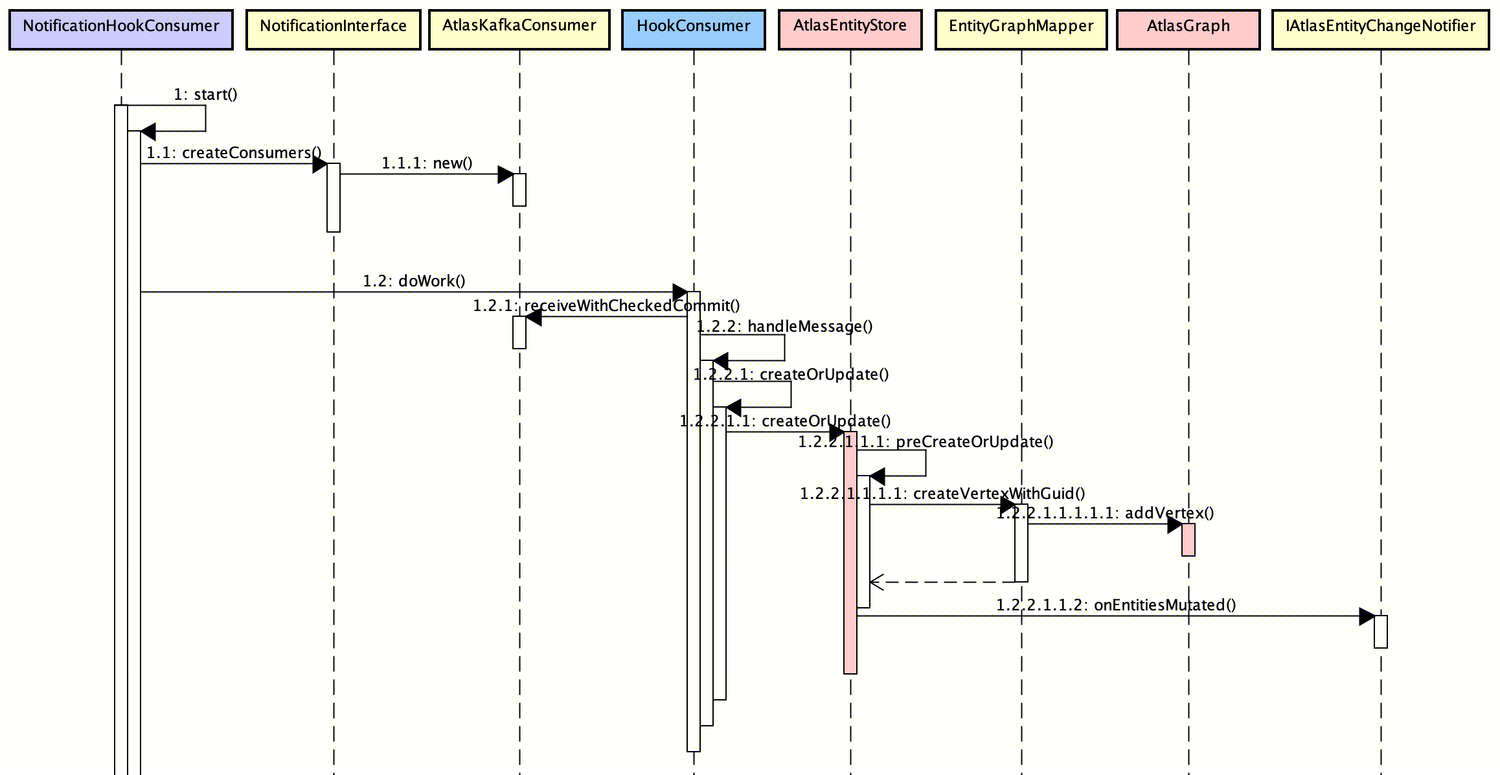
NotificationHookConsumer定义了元数据变更的消息消费,启动Thread线程消费Kafka消息并逐条处理消息持久化,元数据新增的大致流程如下:
- NotificationHookConsumer 以后台方式启动多线程针对不同Topic创建KafkaConsumer进行消费(AtlasKafkaConsumer#doWork);
- AtlasKafkaConsumer 根据消息类型OperationType执行指定的元数据操作,以ENTITY_CREATE为例,会调用AtlasEntityStore元数据存储积累持久化元数据,底层以图数据库(JanusGraph)操作存储元数据(持久化元数据顶点对象)。
血缘实现
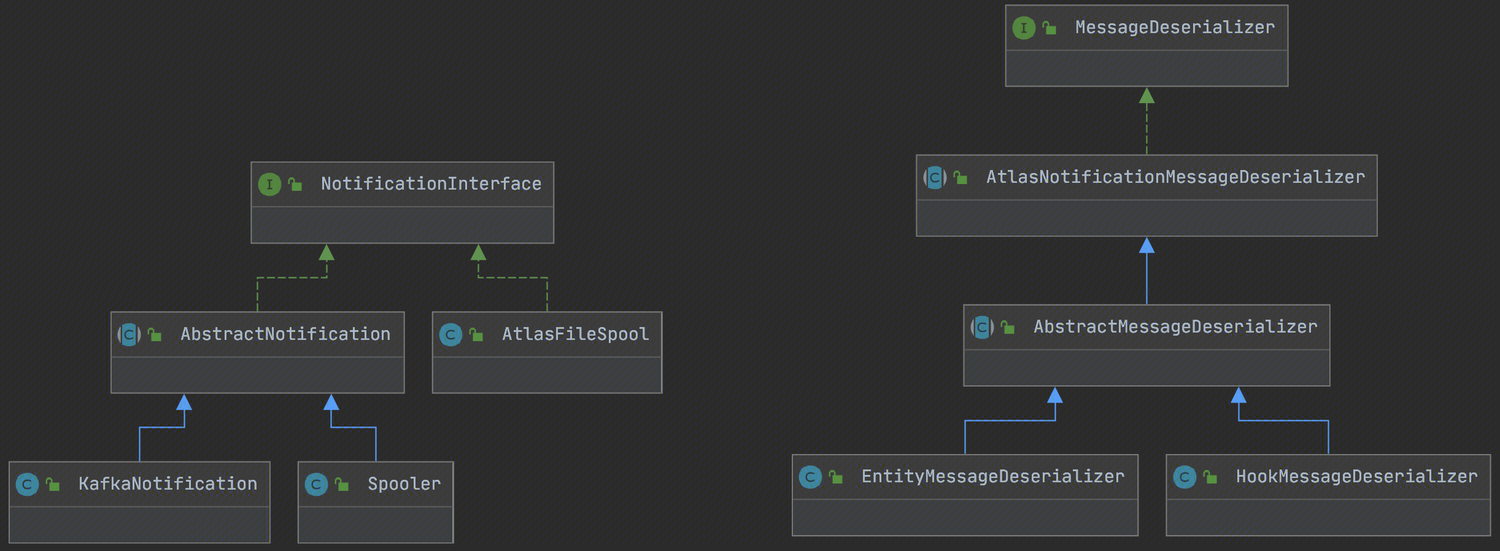
NotificationInterface 消息通知接口:定义Atlas中根据通知类型(NotificationType)的通用消息生产和消费,NotificationType包括:Hook和ENTITIES,可根据JSON数据进行执行类型的反序列化(MessageDeserializer),最终JSON定义的消息反序列化为HookNotification和EntityNotification对象。
基于LineageREST类提供实体对象血缘关系查询REST API接口,基于接口AtlasLineageService#getAtlasLineageInfo 实现元数据查看操作,
以Hive血缘生产为例,血缘信息的AtlasEntityDef都会继承Process(可参考前述),基于CreateHiveProcess#getNotificationMessages封装Hive产生的血缘信息并最终发送到消息中间件,基于Hive原生的HookContext中获取血缘信息,支持血缘解析的Hive SQL类型:
- CREATETABLE_AS_SELECT:基于Select创建Hive表;
- CREATE_MATERIALIZED_VIEW:物化视图创建
- CREATEVIEW:创建视图;
- ALTERVIEW_AS:变更视图表;
- LOAD/EXPORT/IMPORT:数据加载、导入、导出;
- QUERY:复杂查询语句;
图数据存储
Atlas中关联数据采用图存储,目前是Janusgraph实现。Atlas的所有数据最终都会转换成图存储中的顶点vertex、边edge和属性property三种元素。
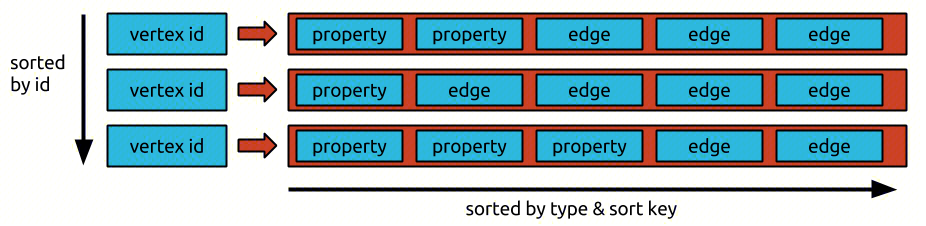

LinkedIn DataHub
系统架构
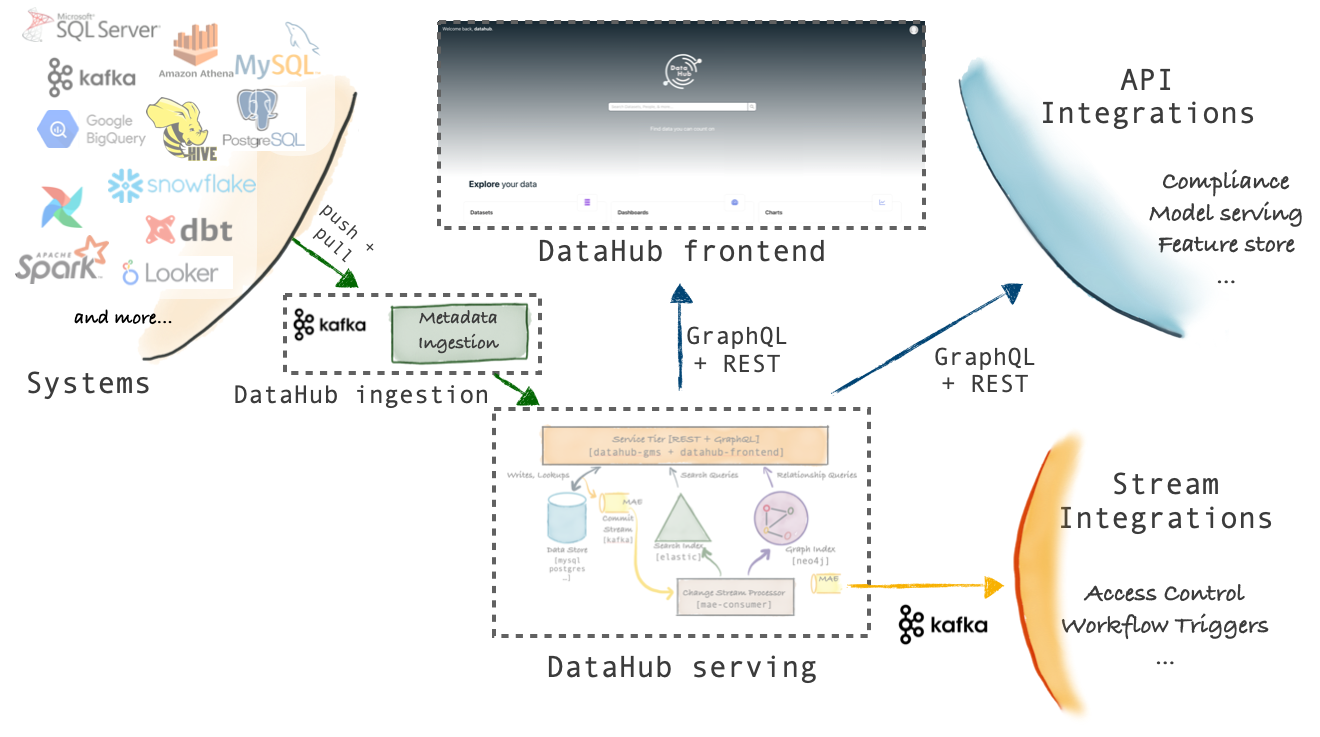
Linkedin DataHub是开源的元数据管理平台,由之前Linkedin WhereHows项目重构改造,项目主要分为三大模块:
- Ingestion:元数据采集/集成,控制元数据如何进入DataHub体系;
- Serving:提供元数据加工处理,元数据读写服务(持久化/元数据读取);
- Frontend:提供与用户交互的界面,支持元数据搜索、数据地图等功能;
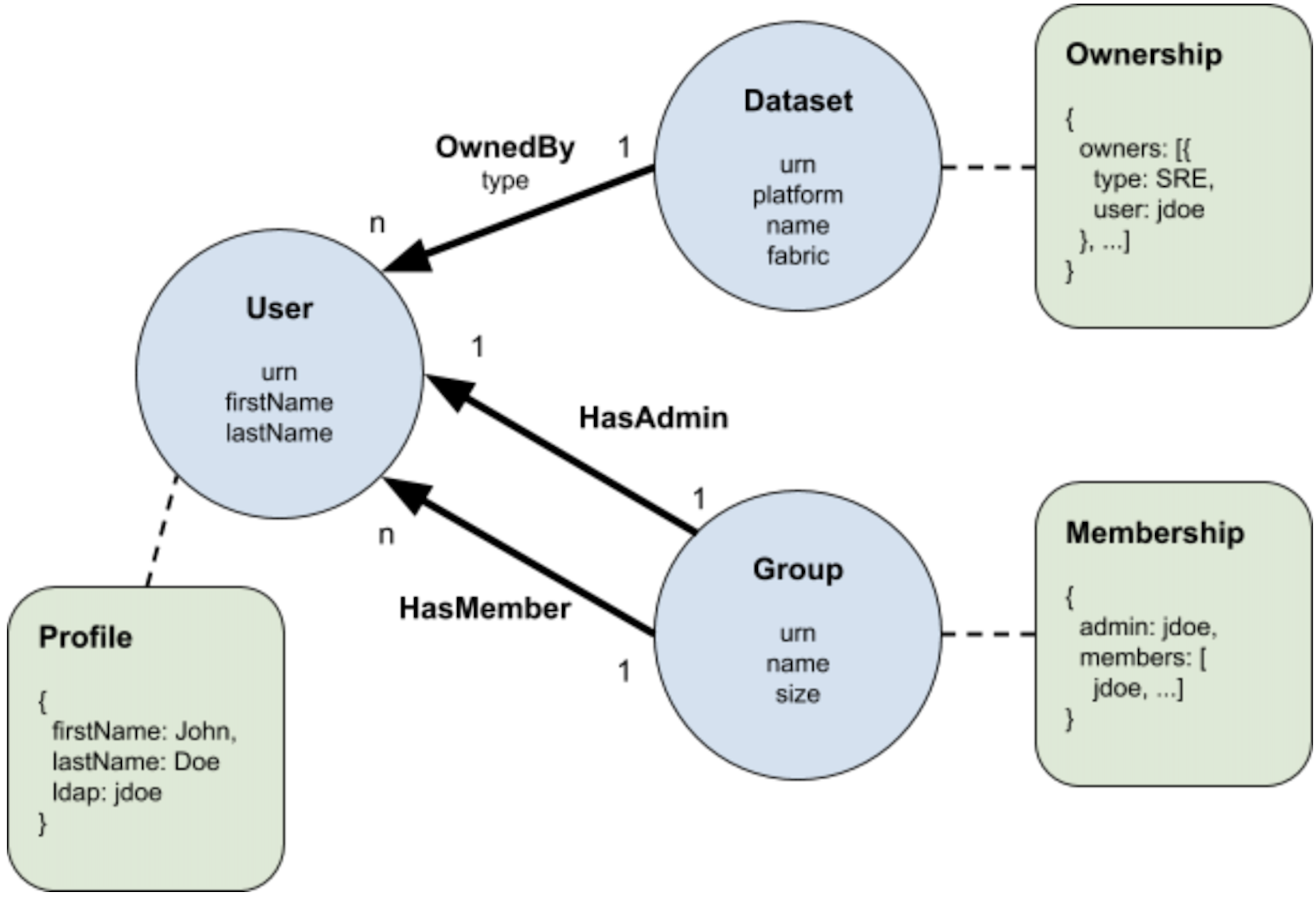
其中Modeling:定义通用性的元模型:实体、关系、属性。
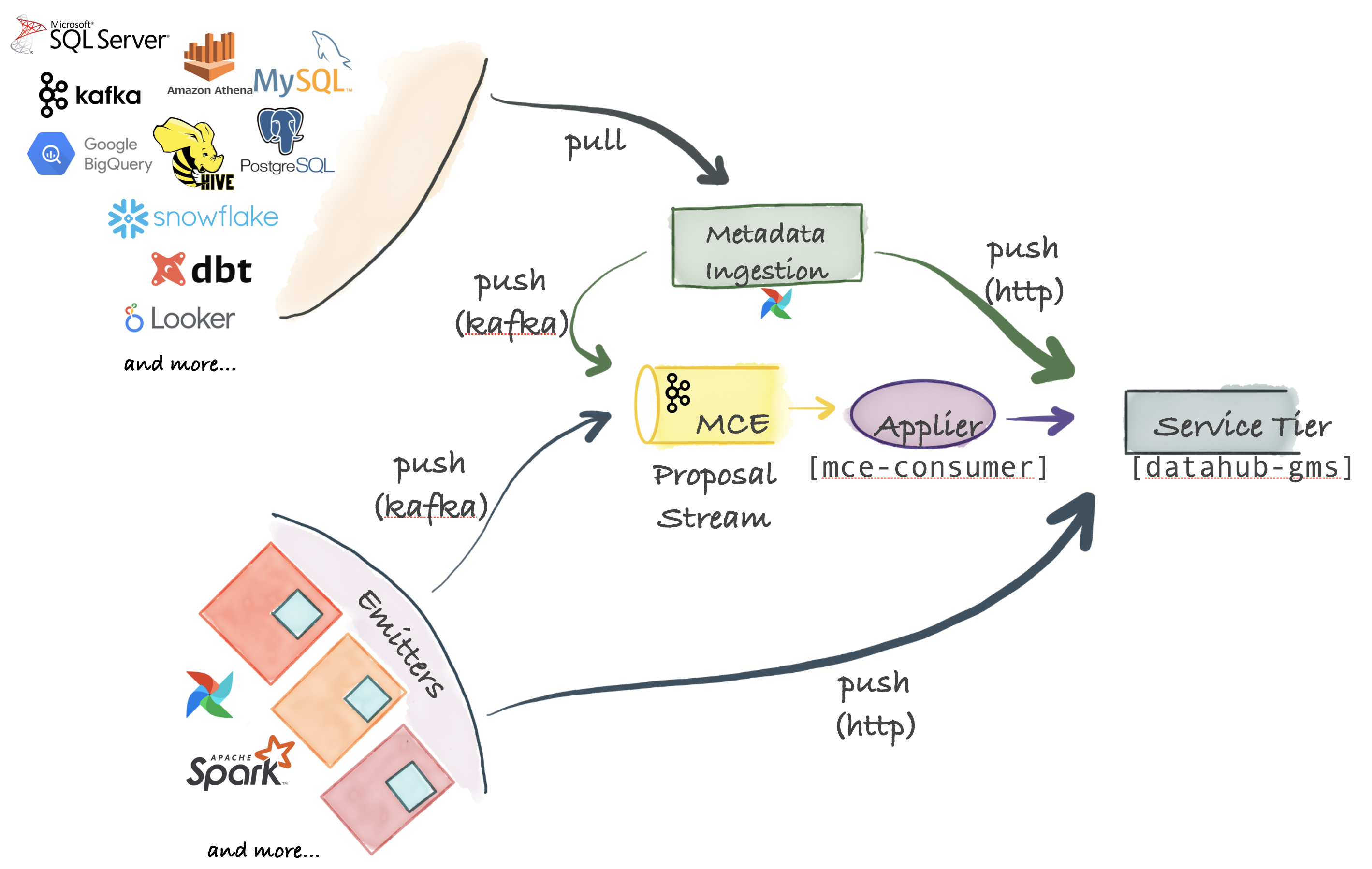
Ingestion
元数据集成(Ingestion)是灵活的服务架构,支持:PUSH、PULL、异步/同步数据模型(底层基于Python实现):
- MCE(Metadata Change Event):元数据变更事件是Ingestion中核心模块,定义了上游系统中存在元数据变更,通常MCE会以固定消息格式传入中间件;
- PULL集成:内部以Python实现各个数据源的元数据采集,采集的数据支持直接PUSH到消息中间件(如Kafka)或调用HTTP接口直接持久化到元数据存储中;
- PUSH集成:支持外部业务系统,将业务元数据以指定消息格式发送消息中间件,生产MCE元数据变更事件;
其中,MCE中的元数据变更来源的分类主要有:hook(引擎Hook),lineage(SQL血缘)、operators(任务DAG过程);基于airflow框架实现。
Serving
DataHub Serving,也称为Serving Tier(分层服务),主要提供元数据的持久化和查询检索能力,即提供元数据管理能力。最核心的是提供gms服务并对外部暴露元数据CRUD操作接口。
- GMS(DataHub Metadata Service):以Java提供元数据管理接口服务
- GraphQL API:变更和获取元数据信息及图关联信息;
- Http API:提供通用元数据REST接口进行元数据管理;
- MAE(Metadata Audit Event):在Serving系统中元数据变更操作会产生MAE(元数据审计事件)并发送到消息中间件(Kafka);特别的,外部系统可以通过调用产生MAE接口,使得外部系统的元数据变更操作可以近实时同步到DataHub系统。
- MAE-Consumer:消费中间件中的MAE事件,并将元数据变更同步索引数据库和图数据库;
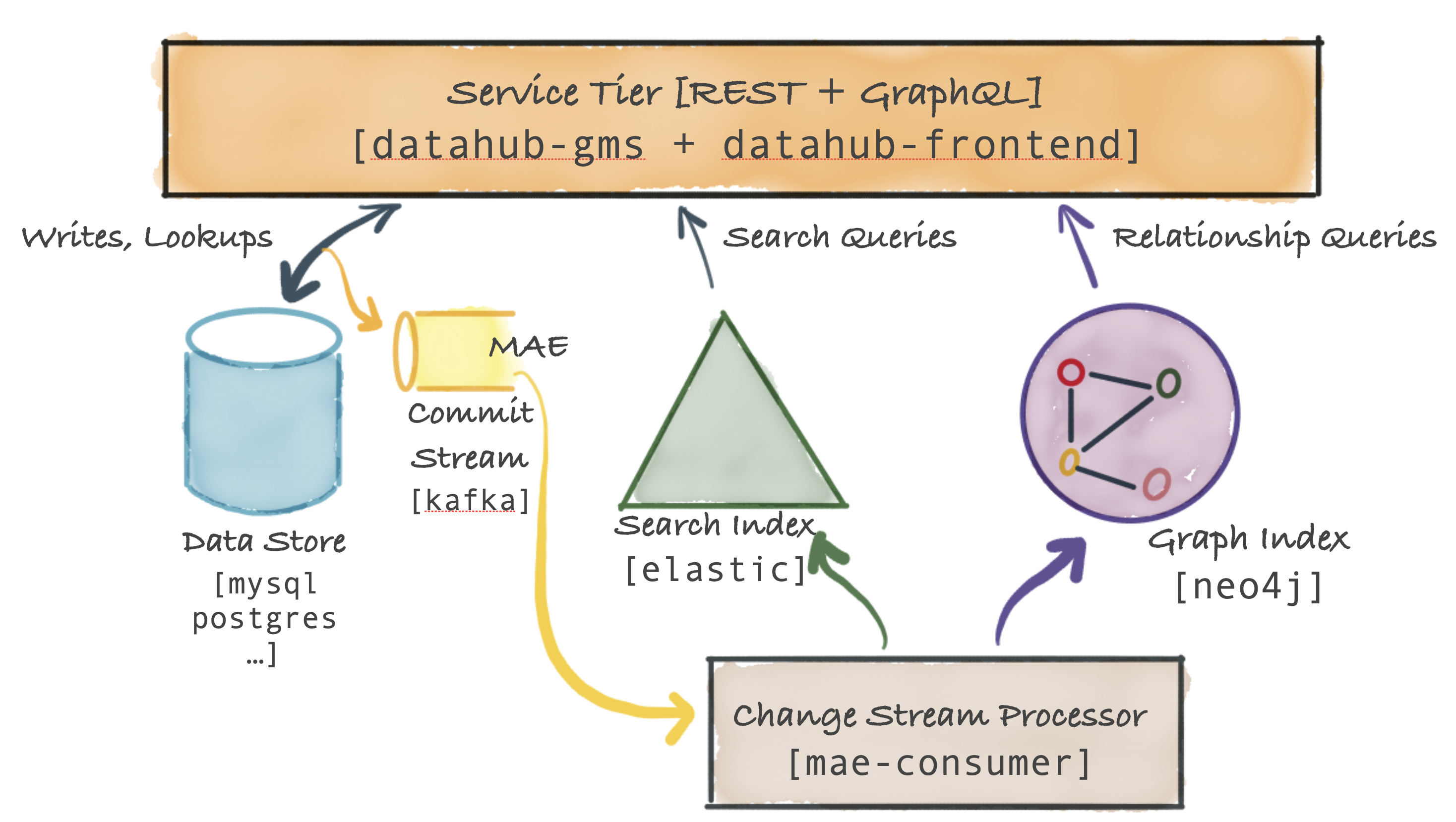
Serving Tier:提供不同等级的查询支持,包括:KV文本存储,基于ES索引检索,基于图数据库关系查询。

血缘实现
LinkedIn DataHub中没有实现SQL血缘解析,是基于Airflow实现的作业血缘,可参考lineage-backend,基于airflow.lineage#prepare_lineage 解析血缘信息。
Netflix Metacat
Netflix Metacat 是 Netflix 研发的统一的元数据探索服务。通过分离计算引擎与具体的数据源,解决在 Netflix 大规模和多样化的数据生态系统中,不同数据存储系统之间的元数据互操作性问题。提供统一的REST/Thrift 接口来访问各种数据存储的元数据。通过直连数据源管理,实时联邦视图。
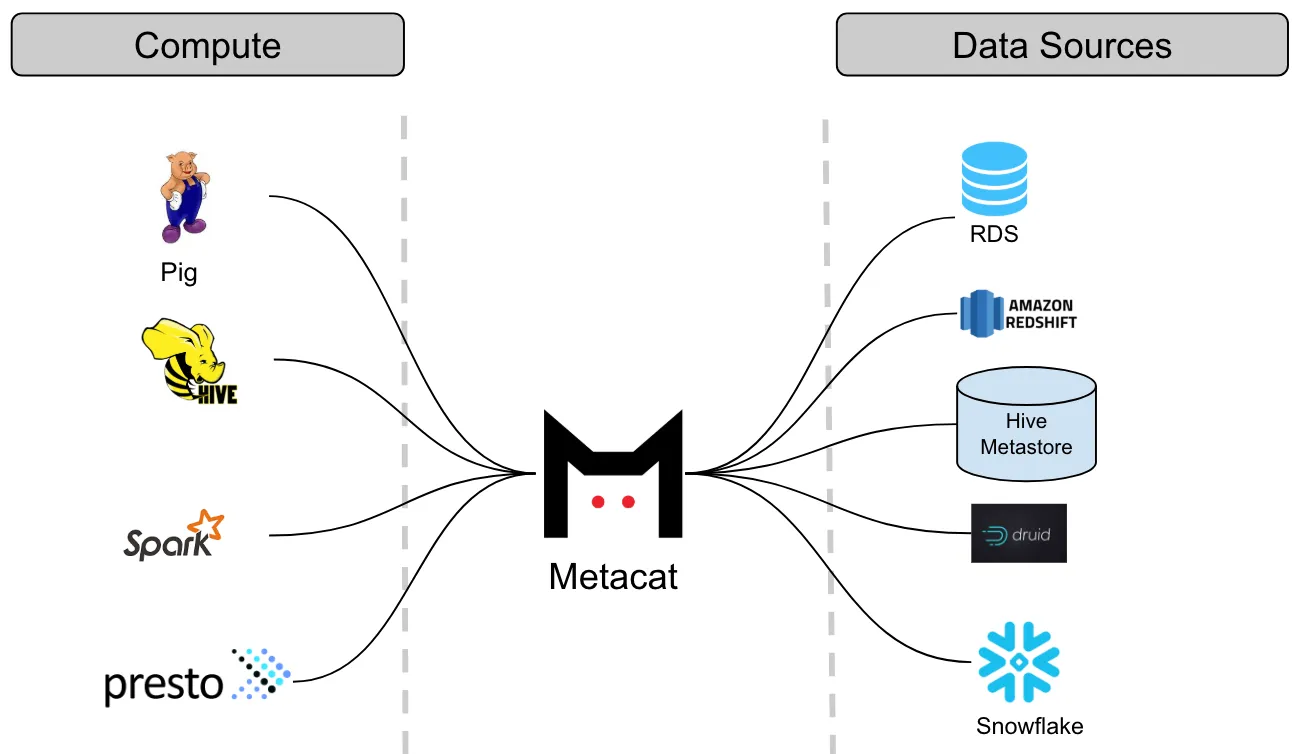
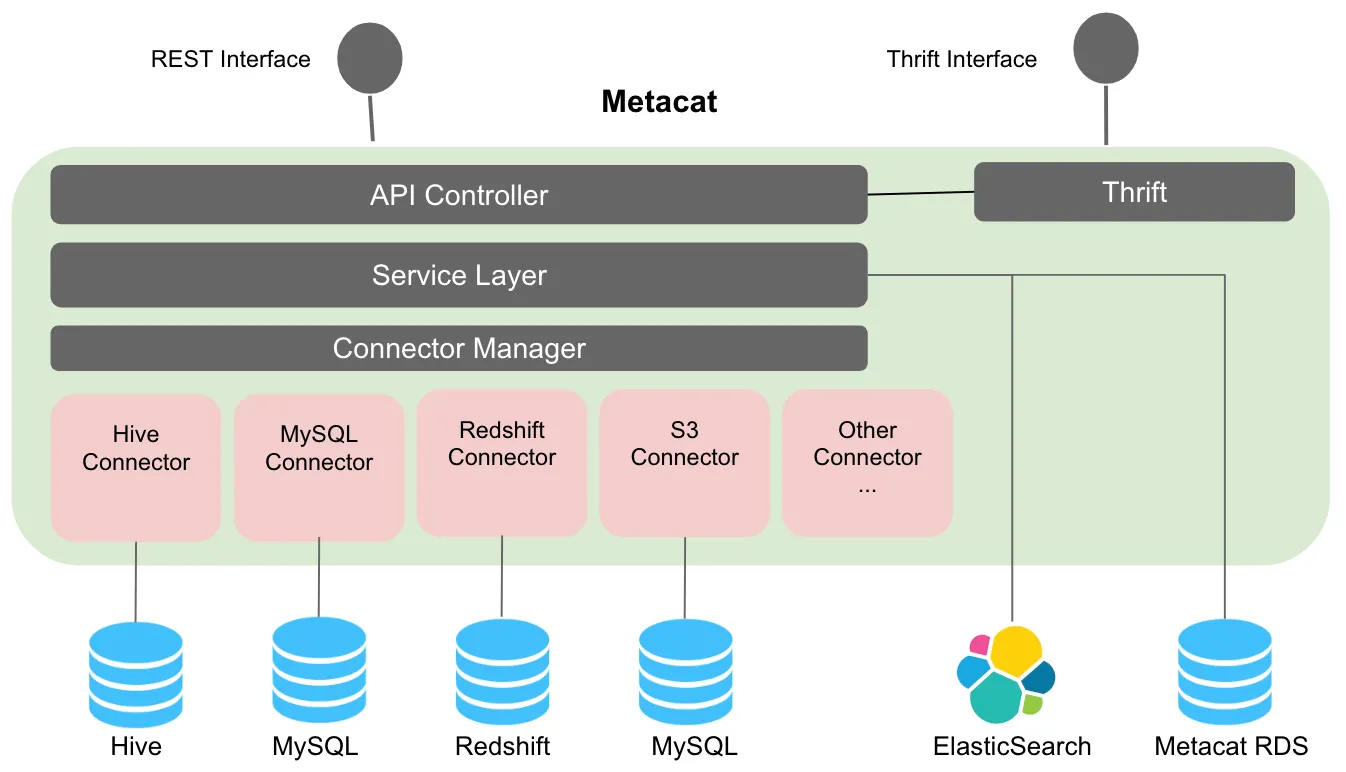
整体架构设计:
- API Controller:接口层,对外提供REST 和 Thrift接口
- Service Layer:服务层,用于数据加工处理,索引数据维护、元数据持久化
- Connector Manager:管理各类型的Connector连接,基于不同的Connector对接数据源
Lyft Amundsen
Lyft Amundsen 是由 Lyft 开源的数据发现和元数据引擎项目,用于解决数据探索
- Metadata Service:接收处理前端的元数据请求,默认存储在图数据库Neo4j中;主要支持三种类型资源:表元数据(表名/描述/字段/统计信息等)、用户信息(用户/组/团队/联系方式)、Dashborad资源,支持以Atlas作为引擎获取元数据;
- Search Service:接收处理前端的搜索请求,默认使用ES;
- Front-End Service:默认前端Web服务;
- Databuilder:通用数据集成框架,支持多种元数据采集;基于Apache Gobblin启发,记录ETL操作,基于HOCON(human-optimized config object notation)使得插件化,基于AirFlow作为调度引擎。

实现过程中的问题与挑战:
- 不同数据源组织结构:需提供两种数据采集方式,PULL(基于爬虫)、PUSH(push 到中间件);
- 移除清理过期数据:没有提供元数据版本,过期数据未被删除;
- 支持多类数据仓库;
其他系统
PayPal UDC
PayPal内部使用的一个数据目录系统,用于统一管理和组织公司内部的数据目录。主要包括三个模块:
- Metadata Services:对外提供元数据管理应用服务和可视化界面
- Metadata Discovery Services:元数据发现服务
- Metadata Store:维护元数据存储,包括关系型数据库、图数据库、ES检索和Kafka消息中间件

AWS Glue
AWS Glue 是亚马逊提供的一种完全托管的ETL(Extract, Transform, Load)服务,能够自动发现AWS上存储的数据,并将其存储在AWS Glue Data Catalog中,这是一个中央元数据存储库,可以作为数据湖和数据仓库的基础。AWS Glue 核心功能包括两部分:
- 数据目录:中央元数据存储库,提供了一个统一的存储库,不同的系统都可以在其中存储和查找元数据来跟踪数据孤岛中的数据,并使用该元数据来查询和转换数据。
- ETL任务引擎:支持自动生成 Python 或 Scala 代码的 ETL 引擎,支持处理任务的依赖项解析、任务监控和重试;

AWS Glue 数据目录提供持久性元数据存储,它是一项全托管服务,可在AWS 云中存储、注释和共享元数据,就像在 Apache Hive 元存储中一样。
数据目录支持多租户:每个AWS账户在每个AWS区域有一个 AWS Glue 数据目录 它提供了一个统一的存储库,不同的系统可以在其中存储和查找元数据来跟踪数据孤岛中的数据,并使用该元数据来查询和转换数据。
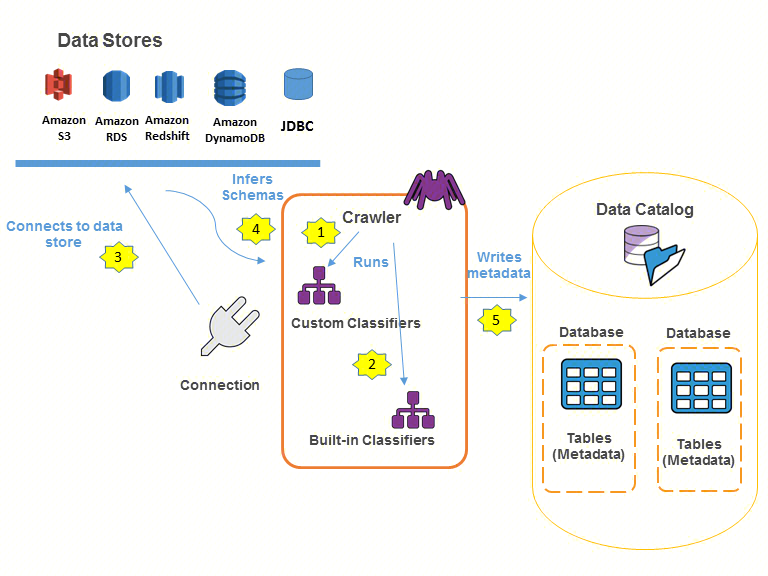
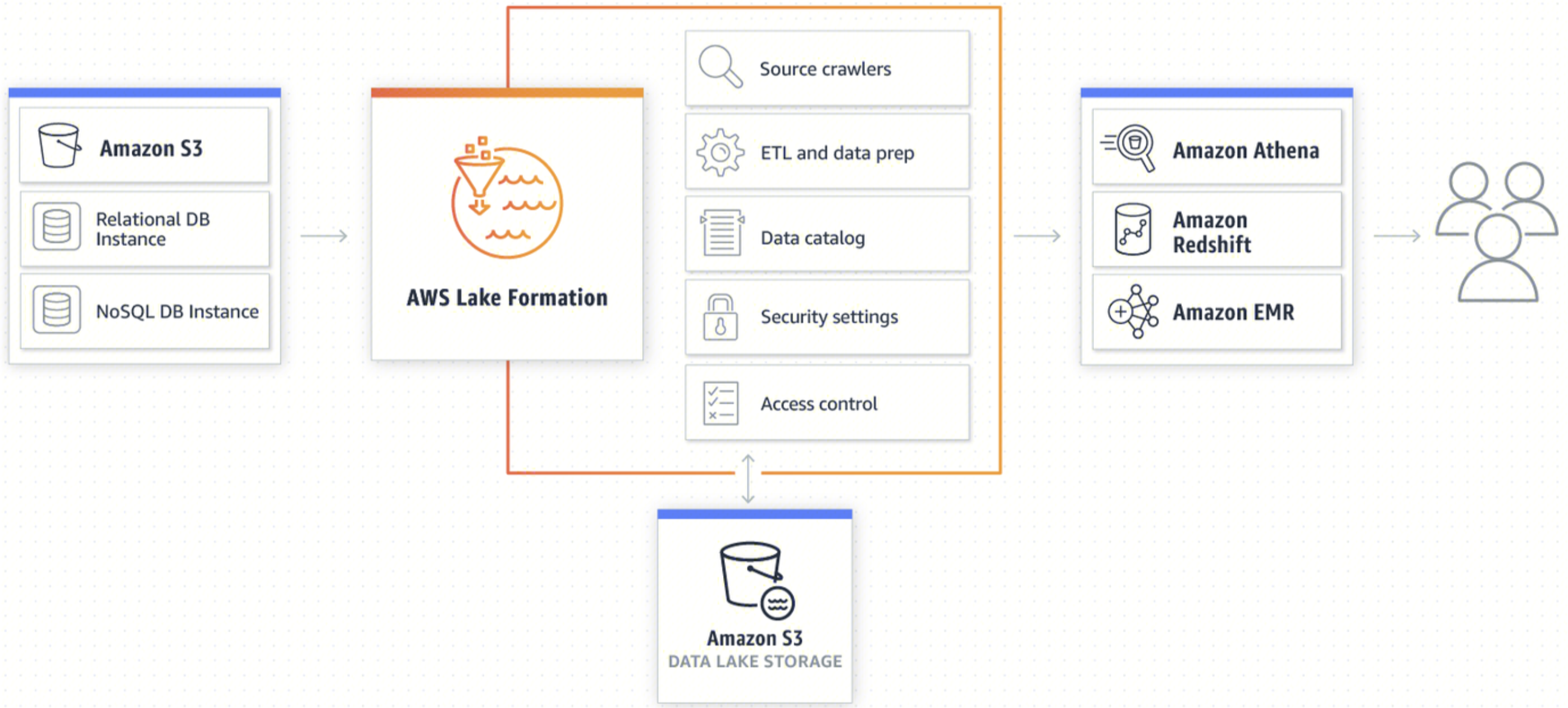
AWS Lake Formation
AWS Lake Formation 是亚马逊提供的数据湖托管服务,目标是让用户能够轻松地设置一个数据湖,并提供必要的安全性和权限管理,以便用户可以安全地存储、分类和搜索他们的数据。
AWS Lake Formation提供的元数据管理功能:
- 元数据采集
- 元数据加工/清理
- 元数据维护
- 元数据安全
Facebook Nemo
广泛意义的数据挖掘,主要包括两个部分:Indexing、serving。基于数据治理的数据进行模型训练和数据挖掘。

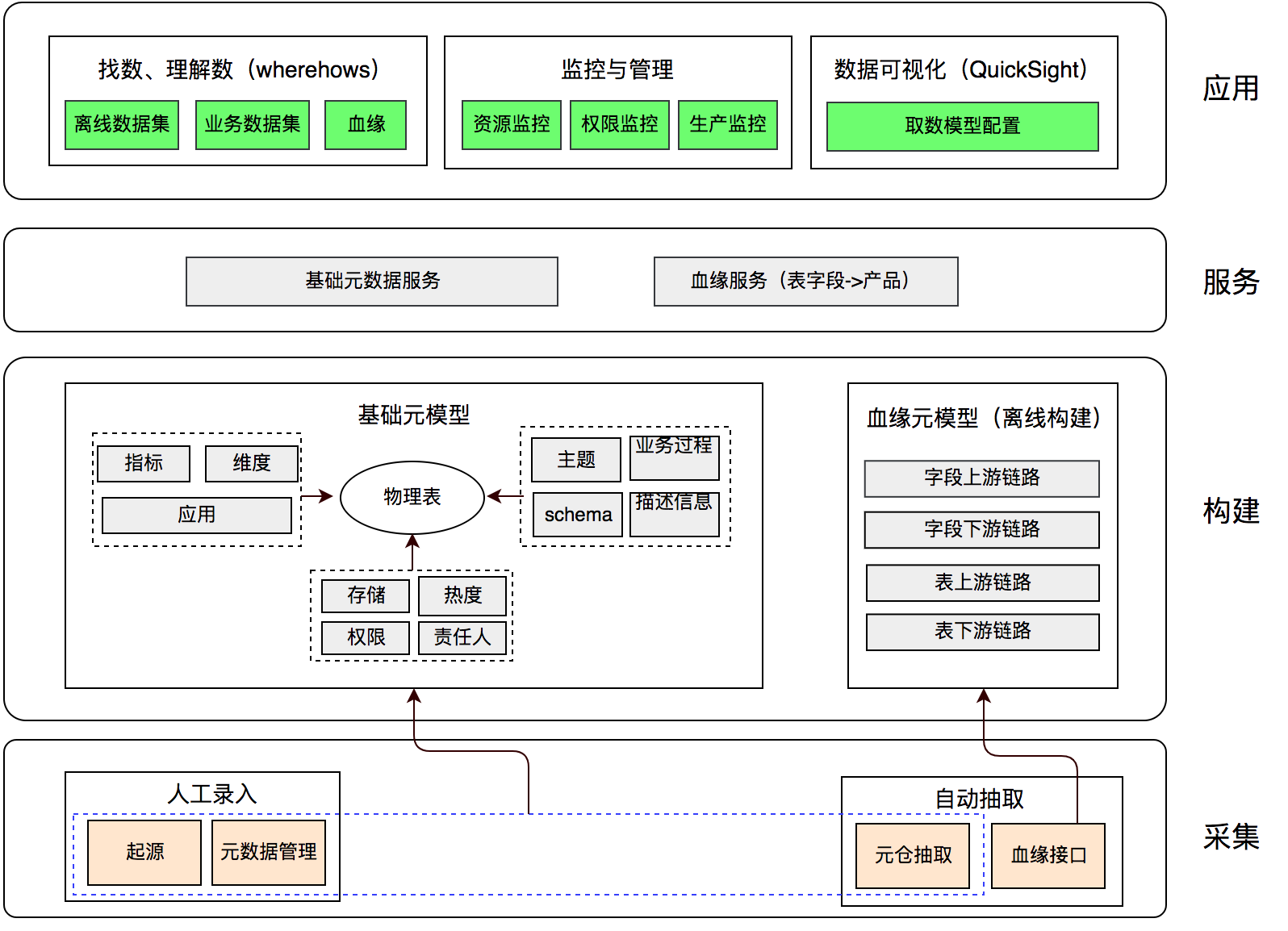
美团配送
元数据建设架构自底向上包括:
- 元数据采集:包括人工录入、自动抽取
- 元模型构建:定义基础元模型和血缘元模型
- 元数据服务:基础元数据服务、血缘服务
- 元数据应用:找数、监控管理、可视化报表等
网易严选
数据治理体系如图所示:自底向上主要包括数据基础服务、数据治理模型、数据治理应用等 3 层

数据治理基础服务:
- 统一元数据服务(MetaService)
- 全链路的血缘服务(LineageService)
- 监控服务建设(MonitorService)
数据治理模型:数据生产链路进行自动化治理,将数据治理与资源管理相结合
- Table Lifecycle Model:生命周期管理,根据表的访问次数来进行自动化分类:Hot, Warn, Cold,数据治理服务中的 Task Governace Module 即是在 Table Lifecycle Model 的基础上实现模型,策略,执行等全流程自动化治理。
- Task Health Model:是数据治理的核心,从任务维度,根据经验总结主要包括 7 种需要优化的类型,分别是:冷任务,错误的任务依赖,缺少任务依赖,任务配置不合理,耗时过长,耗资源过多,任务倾斜等。Task Health Model 主要是识别以上可以优化的数据计算任务,为任务优化的 action 提供基础。
- Data batch-process Model:整个数据生产链路的关键点,系统资源的瓶颈,整体调度策略信息等等。Data Batch Process Model 能告诉我们从哪些角度去优化和治理系统能得到最好的 ROI。
功能对比
基于业界方案调研,可以总结出以下规律:
- 开源的数据治理产品也在不断迭代更新:从单体服务到分层服务,但都以消息驱动为主,很多主流的元数据管理系统,会采用消息中间件来解耦数据采集和数据加工,使得系统更具通用性。新增的异构数据源,仅需按照规定的消息格式发送元数据到消息中间件,元数据就可以被系统进行加工处理;
- 完整的数据治理系统可以分为五个基本模块:元模型定义、元数据采集、元数据加工、元数据存储、元数据应用;更多可参考《大数据平台:统一元数据管理》
- 数据治理服务常用的基础组件有:
- 关系型数据库:用于元数据存储,
- 索引数据库:用于数据检索的,如ElasticSearch
- 图数据库:用于关联数据存储,如数据血缘或者元数据实体;
- 消息中间件:用于解耦元数据操作;
- 调度引擎:用于执行采集任务。
腾讯云数据湖的统一元数据架构:支持在线数据目录和离线数据治理的统一,除了完善的离线数据治理能力外,也为计算引擎提供在线数据目录功能。
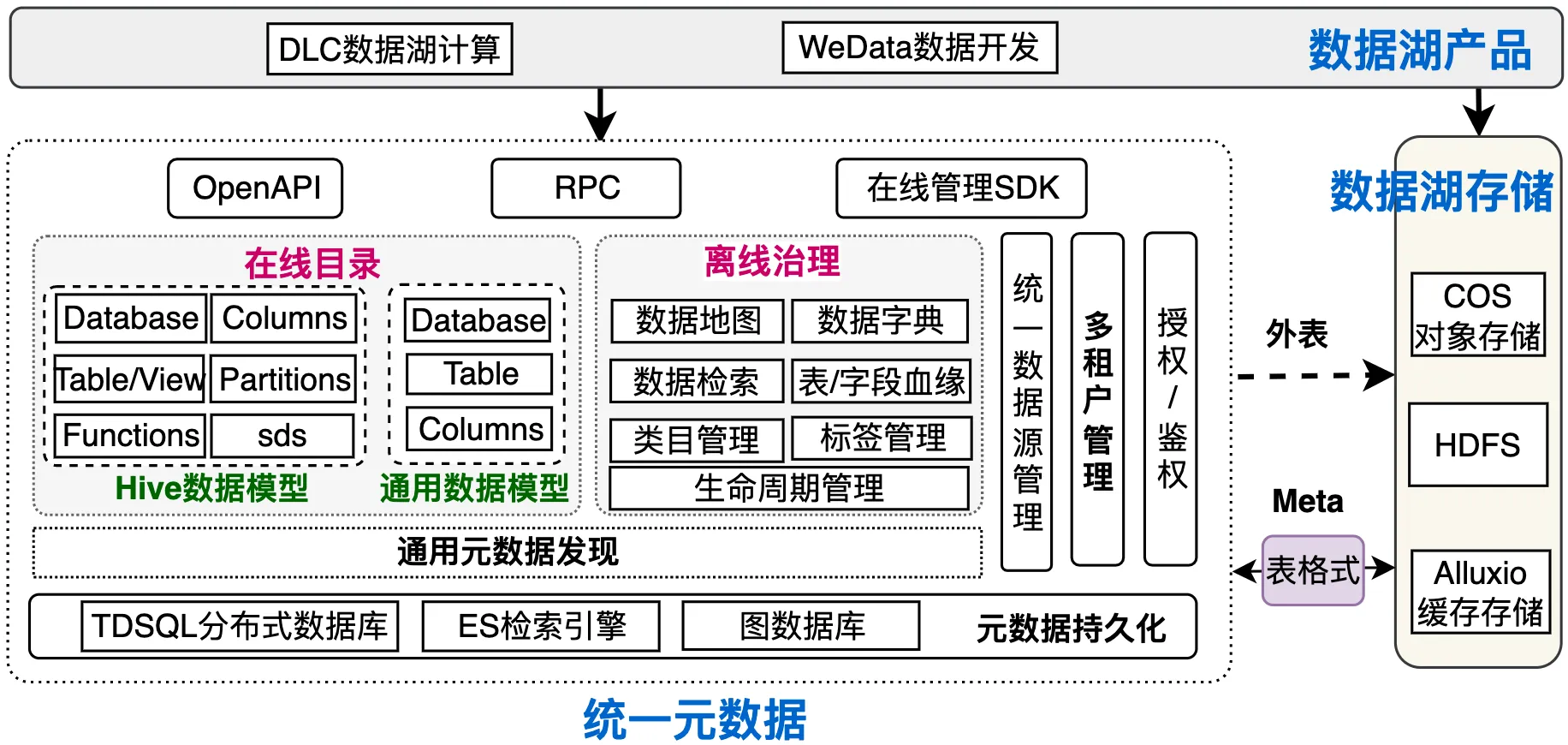
下表展示了各个开源系统与腾讯云数据治理功能的对比,其中腾讯数据治理服务主要依托于WeData对外提供,对比可以看出腾讯云数据治理具备丰富且完整的离线治理能力。

总结
按照以往经验,除了系统的功能完整性外,开源的数据治理系统在实际业务中是很难直接使用起来的。因为数据治理是与业务领域和形态密切相关,而开源项目为保证通用性,会尽可能与具体业务解耦。因此,直接使用具有一定抽象性且通用的开源系统,只能获取比较基础的数据治理能力,很难得到业务相关的数据价值。若与业务结合,则需要对开源系统进行深度的二次开发,因此我们在数据治理模块选择了完全自研。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。