LLVM的ThinLTO编译优化技术在Postgresql中的应用
LLVM的ThinLTO编译优化技术在Postgresql中的应用

部分内容引用:https://blog.llvm.org/2016/06/thinlto-scalable-and-incremental-lto.html
LTO是什么?
链接时优化(Link-time optimization,简称LTO)是编译器在链接时对程序进行的一种优化。它适用于以文件为单位编译程序,然后将这些文件链接在一起的编程语言(如C和Fortran),而不是一次性编译(如Java的即时编译(JIT))。
传统上,编译器将所有文件分别编译成目标文件,然后将这些目标文件链接成一个单独的可执行文件。然而,在GNU编译器集合(GCC)和LLVM中实现的LTO中,编译器能够转储其中间表示(IR),即GIMPLE字节码或LLVM字节码,以便在最终链接时将组成单个可执行文件的所有不同编译单元作为单个模块进行优化。这扩大了跨过程优化的范围,涵盖了整个程序(或者更准确地说,链接时可见的所有内容)。通过链接时优化,编译器可以对整个程序应用各种形式的跨过程优化,进行更深入的分析、更多的优化,从而实现更好的程序性能。
实际上,LTO并不总是对整个程序进行优化,特别是动态链接的共享对象等库函数会被有意排除在外,以避免过多的重复和允许更新。静态链接自然适用于LTO的概念,但它只适用于包含IR对象而不是仅包含机器码的库存档文件。由于性能问题,甚至不总是直接使用整个单元,可以将程序分割成类似GCC的WHOPR的分而治之的LTO形式。当构建的程序本身是一个库时,优化会保留每个外部可用(导出的)符号,而不会过于努力地将它们作为DCE的一部分删除。
即使没有LTO,仍然可以使用一种更有限的WPO形式,例如GCC的-fwhole-program开关。这种模式使GCC假设正在编译的模块包含整个程序的入口点,因此其中的其他函数不会被外部使用,可以安全地进行优化。由于它仅适用于单个模块,因此无法真正涵盖整个程序。它可以与LTO结合使用,以一大模块的方式,这在链接器不会向GCC反馈外部使用的入口点或符号时非常有用。
LLVM提供的lto独立工具:
$ llvm-lto --help
OVERVIEW: llvm LTO linker
USAGE: llvm-lto [options] <input bitcode files>
OPTIONS:
Color Options:
--color - Use colors in output (default=autodetect)
Generic Options:
--help - Display available options (--help-hidden for more)
--help-list - Display list of available options (--help-list-hidden for more)
--version - Display the version of this program
LTO Options:
-O <char> - Optimization level. [-O0, -O1, -O2, or -O3] (default = '-O2')
--check-for-objc - Only check if the module has objective-C defined in it
--disable-verify - Do not run the verifier during the optimization pipeline
--dso-symbol=<string> - Symbol to put in the symtab in the resulting dso
--exported-symbol=<string> - List of symbols to export from the resulting object file
-j <uint> - Number of backend threads
--list-dependent-libraries-only - Instead of running LTO, list the dependent libraries in each IR file
--list-symbols-only - Instead of running LTO, list the symbols in each IR file
--lto-freestanding - Enable Freestanding (disable builtins / TLI) during LTO
-o <filename> - Override output filename
--print-macho-cpu-only - Instead of running LTO, print the mach-o cpu in each IR file
--restore-linkage - Restore original linkage of globals prior to CodeGen
--save-linked-module - Write linked LTO module to file before optimize
--save-merged-module - Write merged LTO module to file before CodeGen
--set-merged-module - Use the first input module as the merged module
--thinlto - Only write combined global index for ThinLTO backends
--thinlto-action=<value> - Perform a single ThinLTO stage:
=thinlink - ThinLink: produces the index by linking only the summaries.
=distributedindexes - Produces individual indexes for distributed backends.
=emitimports - Emit imports files for distributed backends.
=promote - Perform pre-import promotion (requires -thinlto-index).
=import - Perform both promotion and cross-module importing (requires -thinlto-index).
=internalize - Perform internalization driven by -exported-symbol (requires -thinlto-index).
=optimize - Perform ThinLTO optimizations.
=codegen - CodeGen (expected to match llc)
=run - Perform ThinLTO end-to-end
--thinlto-cache-dir=<string> - Enable ThinLTO caching.
--thinlto-cache-entry-expiration=<uint> - Set ThinLTO cache entry expiration time.
--thinlto-cache-max-size-bytes=<ulong> - Set ThinLTO cache pruning directory maximum size in bytes.
--thinlto-cache-max-size-files=<int> - Set ThinLTO cache pruning directory maximum number of files.
--thinlto-cache-pruning-interval=<int> - Set ThinLTO cache pruning interval.
--thinlto-index=<string> - Provide the index produced by a ThinLink, required to perform the promotion and/or importing.
--thinlto-index-stats - Print statistic for the index in every input files
--thinlto-module-id=<string> - For the module ID for the file to process, useful to match what is in the index.
--thinlto-prefix-replace=<string> - Control where files for distributed backends are created. Expects 'oldprefix;newprefix' and if path prefix of output file is oldprefix it will be replaced with newprefix.
--thinlto-save-objects=<string> - Save ThinLTO generated object files using filenames created in the given directory.
--thinlto-save-temps=<string> - Save ThinLTO temp files using filenames created by adding suffixes to the given file path prefix.
--use-diagnostic-handler - Use a diagnostic handler to test the handler interface那么thinlto是什么?
LTO背景和动机
LTO(Link Time Optimization)是通过整个程序分析和跨模块优化来实现更好的运行时性能的一种方法。在编译阶段,clang会生成LLVM字节码而不是目标文件。链接器识别这些字节码文件,并在链接过程中调用LLVM来生成构成可执行文件的最终对象。LLVM实现会加载所有输入的字节码文件,并将它们合并成一个单独的模块。在这个庞大的模块上,进行了跨过程的分析(IPA)和跨过程的优化(IPO),这些优化是串行进行的。

在实践中,这意味着LTO通常需要大量的内存(一次性保存所有IR)并且非常慢。而且,如果通过-g启用了调试信息,IR的大小和所需的内存要求会显著增加。即使没有调试信息,这对于非常大的应用程序或在内存受限的机器上进行编译也是不可行的。这也使得增量构建变得不太有效,因为当任何输入源发生变化时,从LTO步骤开始的所有内容都必须重新执行。
ThinLTO是什么?
ThinLTO是一种新的方法,旨在像非LTO构建一样具有可扩展性,同时保留了完整LTO的大部分性能优势。
在ThinLTO中,串行步骤非常轻量且快速。这是因为它不是加载bitcode并合并单个庞大模块来执行这些分析,而是在串行链接步骤中利用每个模块的摘要进行全局分析,以及用于后续跨模块导入的函数位置索引。函数导入和其他IPO转换是在模块在完全并行的后端进行优化时执行的。
ThinLTO全局分析所启用的关键转换是函数导入,只有可能进行内联的函数被导入到每个模块中。这最大程度地减少了每个ThinLTO后端的内存开销,同时最大化了最有影响力的跨模块优化机会。因此,IPO转换是在每个扩展了其导入函数的模块上执行的。
ThinLTO过程分为3个阶段:
- 编译:生成带有模块摘要的IR,与完整LTO模式相同,
- Thin链接:thin链接器插件层,用于合并摘要并执行全局分析
- ThinLTO后端:基于摘要的导入和优化的并行后端(默认情况下,支持ThinLTO的链接器被设置为在线程中启动ThinLTO后端。因此,第二阶段和第三阶段之间的区别对用户来说是透明的)

这个过程的关键是在第一阶段发出的摘要。
这些摘要使用位码格式发出,但设计得可以单独加载,而不涉及LLVMContext或任何其他昂贵的构造。每个全局变量和函数在模块摘要中都有一个条目。条目包含抽象描述该符号的元数据。例如,函数使用其链接类型、包含的指令数量和可选的分析信息(PGO)进行抽象化。此外,还记录了对其他全局变量的每个引用(地址引用、直接调用)。这些信息在Thin链接阶段期间构建了完整的引用图,并使用全局摘要信息进行快速分析。
总结:
ThinLTO的核心思想是将程序分为多个模块,每个模块都可以独立地进行编译和优化。然后,通过使用一个索引文件(称为"summary")来跟踪每个模块的信息,以便在链接阶段进行全局的优化。这种方式可以减少编译时间和内存消耗,同时仍能够实现类似于WPO的优化效果。
Postgresql中使用thinlto技术生成带有模块摘要的IR
PG根目录下的Makefile.golbal.in中增加了对LLVM的支持,位置:
# Install LLVM bitcode module (for JITing).
#
# The arguments are:
# $(1) name of the module (e.g. an extension's name or postgres for core code)
# $(2) source objects, with .o suffix
#
# The many INSTALL_DATA invocations aren't particularly fast, it'd be
# good if we could coalesce them, but I didn't find a good way.
#
# Note: blank line at end of macro is necessary to let it be used in foreach
define install_llvm_module
$(MKDIR_P) '$(DESTDIR)${bitcodedir}/$(1)'
$(MKDIR_P) $(sort $(dir $(addprefix '$(DESTDIR)${bitcodedir}'/$(1)/, $(2))))
$(foreach obj, ${2}, $(INSTALL_DATA) $(patsubst %.o,%.bc, $(obj)) '$(DESTDIR)${bitcodedir}'/$(1)/$(dir $(obj))
)
cd '$(DESTDIR)${bitcodedir}' && $(LLVM_BINPATH)/llvm-lto -thinlto -thinlto-action=thinlink -o $(1).index.bc $(addprefix $(1)/,$(patsubst %.o,%.bc, $(2)))
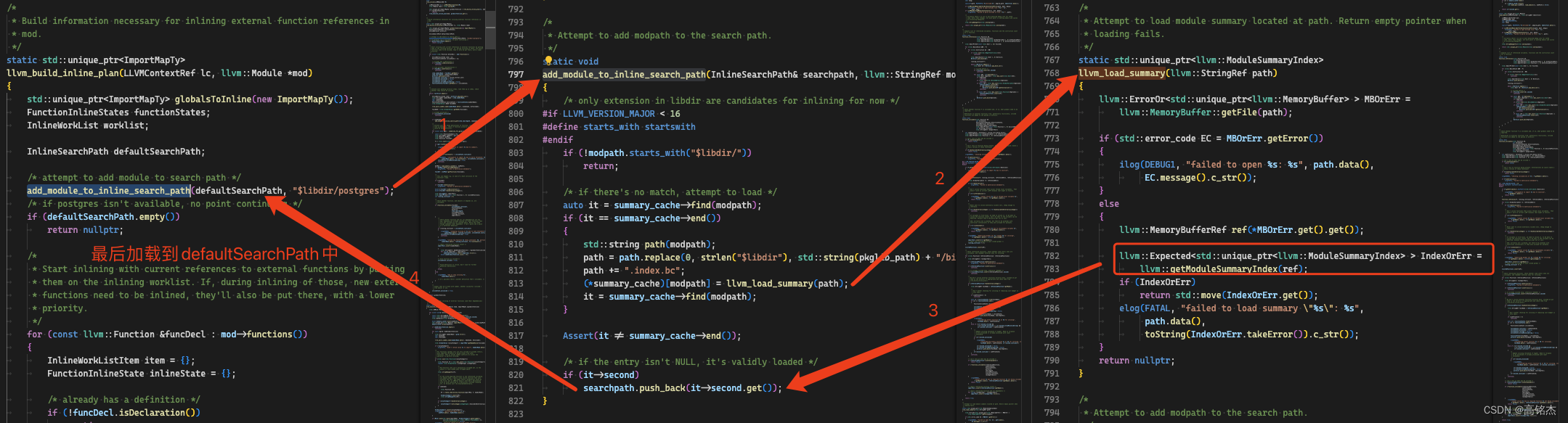
endefinstall_llvm_module函数中调用了llvm-lto -thinlto -thinlto-action=thinlink生成摘要文件:postgres.index.bc。
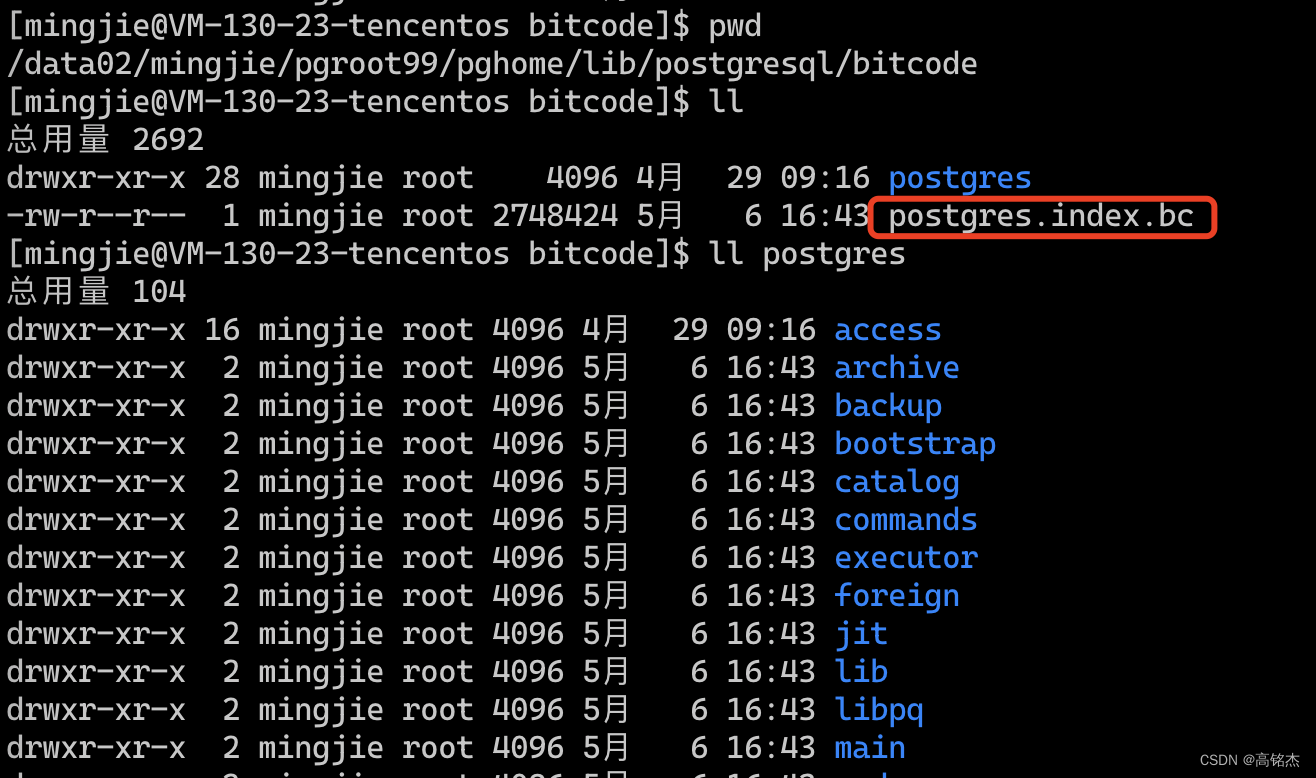
postgres.index.bc只有2.7MB显然没有保存所有bitcode。通过llvm-dis反解成ll看下里面保存了什么:
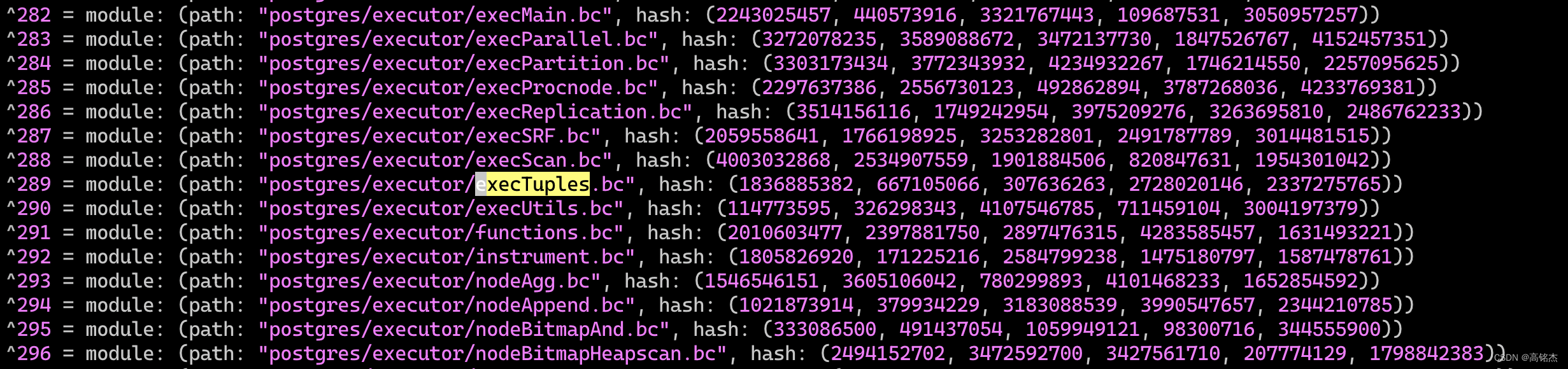
- 索引文件前半部分中保存了文件的bc路径、bc的moduleid。
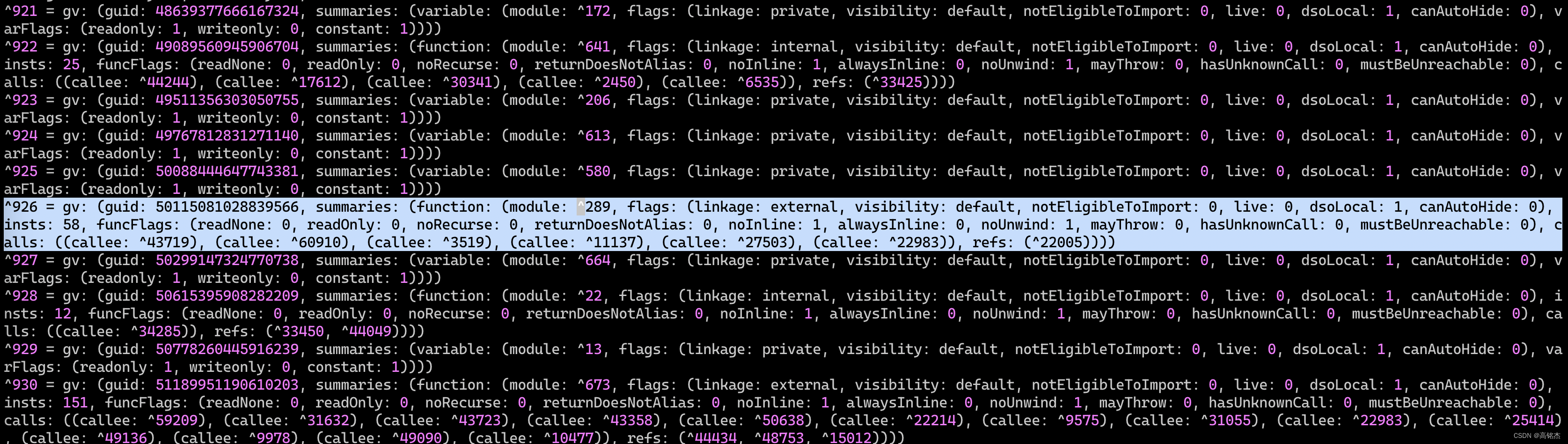
- 索引文件后半部分保存了全局变量、函数的信息,包括自身的全局guid、所属bc的moduleid、函数的连接类型、可见性、能否内联、能否抛出异常等等信息。
Postgresql如何加载使用postgres.index.bc
在llvm_load_summary中使用getModuleSummaryIndex加载postgres.index.bc,最后读取到defaultSearchPath中使用。
static std::unique_ptr<llvm::ModuleSummaryIndex>
llvm_load_summary(llvm::StringRef path)
{
llvm::ErrorOr<std::unique_ptr<llvm::MemoryBuffer> > MBOrErr =
llvm::MemoryBuffer::getFile(path);
if (std::error_code EC = MBOrErr.getError())
{
ilog(DEBUG1, "failed to open %s: %s", path.data(),
EC.message().c_str());
}
else
{
llvm::MemoryBufferRef ref(*MBOrErr.get().get());
llvm::Expected<std::unique_ptr<llvm::ModuleSummaryIndex> > IndexOrErr =
llvm::getModuleSummaryIndex(ref);
if (IndexOrErr)
return std::move(IndexOrErr.get());
elog(FATAL, "failed to load summary \"%s\": %s",
path.data(),
toString(IndexOrErr.takeError()).c_str());
}
return nullptr;
}代码流程: