[译文] LLM安全:1.黑客如何读取您与ChatGPT或微软Copilot的聊天内容
[译文] LLM安全:1.黑客如何读取您与ChatGPT或微软Copilot的聊天内容

这是作者新开的一个专栏,主要翻译国外知名安全厂商的技术报告和安全技术,了解它们的前沿技术,学习它们威胁溯源和恶意代码分析的方法,希望对您有所帮助。当然,由于作者英语有限,会借助LLM进行校验和润色,最终结合自己的安全经验完成,还请包涵!
这篇文章将讲解黑客如何利用聊天机器人的功能来恢复OpenAI ChatGPT、Microsoft Copilot和大多数AI聊天机器人的加密聊天记录。该文章来源自以色列Offensive AI Lab的研究人员发表的一篇论文,其描述了一种恢复被截获的AI聊天机器人消息文本的方法。现在,我们将探讨这种攻击是如何工作的,以及它在现实中具有多大的危险性。基础性技术文章,希望您喜欢
原文标题:《How hackers can read your chats with ChatGPT or Microsoft Copilot》
原文链接:https://www.kaspersky.com/blog/ai-chatbot-side-channel-attack/51064/
文章作者:Alanna Titterington
发布时间:2024年4月24日
文章来源:https://www.kaspersky.com一.从拦截的AI聊天机器人信息中可以提取哪些信息?
通常而言,聊天机器人会以加密形式发送消息。然而,大型语言模型(large language models,LLMs) 及其上构建的聊天机器人包含了一些严重削弱加密的特性。结合这些特性,当从泄露的信息片段中恢复消息内容时,就有可能造成侧信道攻击。
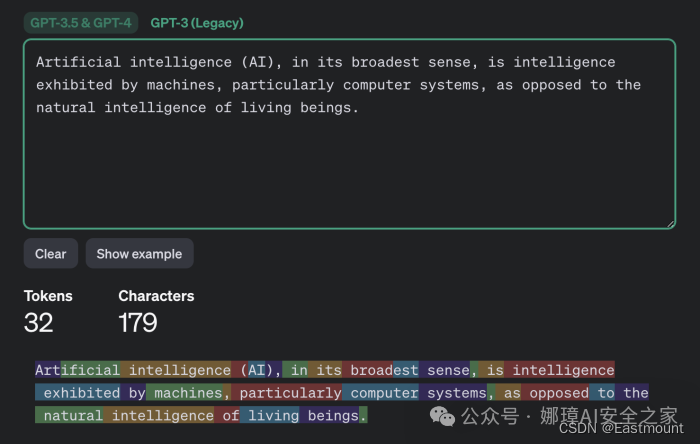
为了理解这种攻击过程中发生了什么,我们需要深入了解LLM(大型语言模型)和聊天机器人的工作机制。首先,我们需要知道,LLM并不是直接操作单个字符或单词,而是操作tokens,这些tokens可以被描述为文本的语义单元。OpenAI网站上的Tokenizer页面为我们提供了内部工作原理的描述。
下图演示了消息tokenization如何与GPT-3.5和GPT-4模型一起工作的。
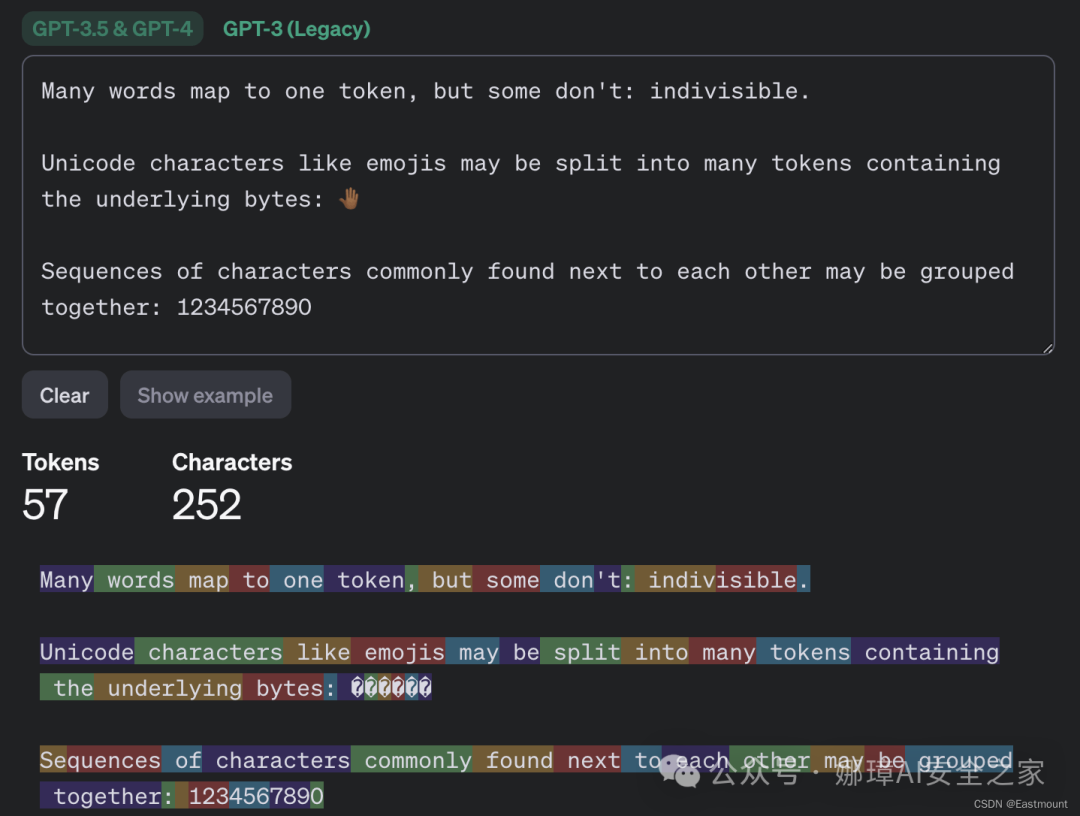
如果您曾与AI聊天机器人有过交互,您就会知道促成这种攻击的第二个特点:
- 它们不会一次性发送大量响应,而是逐渐发送——几乎就像人在打字一样。
但与人类不同的是,LLMs以tokens为单位进行书写,而不是单个字符。因此,聊天机器人会一个接一个地实时发送生成的tokens。或者更确切地说,大多数聊天机器人都是这样做的,除了Google Gemini,这使得它不受这种攻击的影响。
第三个特点是:
- 在论文发表时,大多数聊天机器人在加密消息之前并未使用压缩(compression)、编码(encoding)或填充(padding),其中填充是指向有意义的文本追加垃圾数据,以降低可预测性并增加加密强度。
综上,侧信道攻击利用了这三个特性。虽然截获的聊天机器人消息无法解密,但攻击者可以从中提取有用的数据——特别是聊天机器人发送的每个token的长度。其结果类似于一个“幸运之轮”的谜题:
- 您无法看到具体加密的具体内容,但各个tokens(非words)的长度会被揭示出来。
虽然无法解密消息,但攻击者可以提取聊天机器人发送的tokens长度,由此产生的序列类似于“幸运之轮”节目中隐藏的短语。

二.使用提取的信息来恢复信息文本
接下来要做的就是猜测这些tokens背后隐藏着什么单词或信息。您可能永远猜不到谁擅长这种猜测游戏:没错——就是LLMs(大型语言模型)。事实上,这是它们的主要使命:在给定的上下文中猜测正确的单词。因此,为了从生成的token长度序列中恢复原始消息的文本,研究人员求助于LLM…
确切地说是两个LLMs(大型语言模型),因为研究人员观察到与聊天机器人的初始交流几乎总是公式化的,因此,很容易被一个模型根据流行语言模型生成的一系列介绍性信息通过专门训练而猜出来。
- 第一个模型用于恢复介绍性消息并将其传递给第二个模型
- 第二个模型处理对话的其余部分
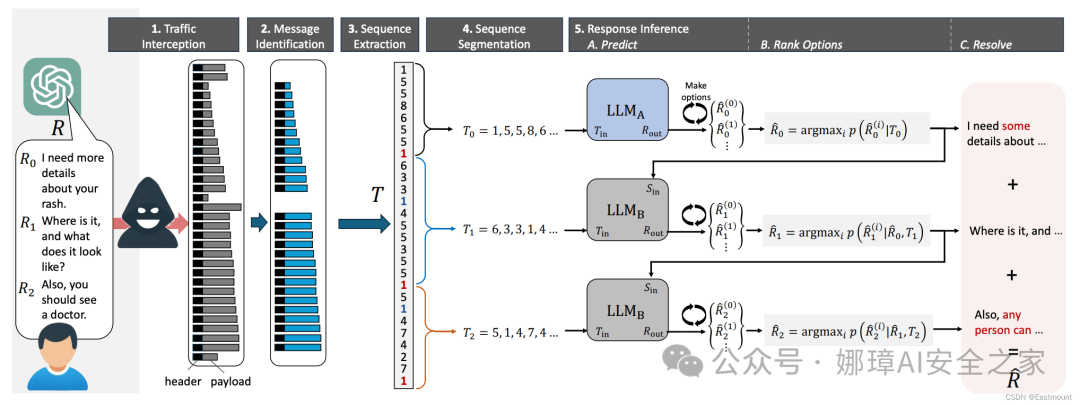
这将生成一个文本,其中tokens长度与原始消息中的长度相对应。但是,具体的单词通过暴力破解的方式,取得了不同程度的成功。请注意,恢复的消息与原始消息之间的完美匹配是很罕见的——通常会发生文本的一部分被错误猜测的情况。有时结果是可以接受的,在下图的示例中,文本被恢复得非常接近原文。

但在不成功的情况下,重构的文本可能与原始文本几乎没有共同点,甚至完全不一样。例如,结果可能如下图所示:

甚至是这样:

总的来说,研究人员检查了十多个AI聊天机器人,并发现其中大多数都容易受到这种攻击——例外的是Google Gemini(原名Bard)和GitHub Copilot(不要与Microsoft Copilot混淆)。如论文中的下表所示。

三.我们应该担心吗?
值得注意的是,这种攻击是具有追溯性的(retrospective)。假设有人不费苦心地拦截并保存了您与ChatGPT的聊天记录(虽然不容易,但有可能),在这些记录中您透露了一些可怕的秘密。在这种情况下,使用上述方法,那个人理论上将能够读取这些消息。
值得庆幸的是,拦截者的成功率并不高。正如研究人员所指出的那样,即使是聊天的一般主题也只有55%的几率被确定。至于成功的重建,这个比例仅为29%。值得一提的是,研究人员对完全成功重建的标准得到了满足,例如:

那么,这种语义上的细微差别的重要性如何呢?这完全由您自己决定。但请注意,这种方法很可能无法以任何程度的可靠性提取实际细节(如姓名、数值、日期、地址、联系方式、其他重要信息)。
此外,这种攻击还有一个研究人员未提及的限制:文本恢复的成功与否在很大程度上取决于被拦截消息所使用的语言,tokenization的成功在不同语言之间差异很大。本文主要关注英语,其特点是tokens非常长,通常相当于一个完整的单词。因此,经过token处理的英文文本显示了不同的模式,从而使得重构(reconstruction)相对简单。
注意,其他语言都无法比拟。即使是那些与英语最为接近的日耳曼语系和罗曼语系的语言,其平均token长度也只比英语短1.5-2倍;而对于俄语,更是达到2.5倍,一个典型的俄语token通常只有几个字符长,这将可能使这种攻击的有效性降至零。
至少有两家AI聊天机器人的开发者已经针对这篇论文做出了反应。
- Cloudflare
- OpenAI
他们添加了上述提到的填充方法,该方法就是专门为了应对这种类型的威胁而设计的。其他AI聊天机器人开发者也将效仿,希望未来与聊天机器人的通信能够得到保护,免受此类攻击的威胁。