OFC2024:关于 LPO 与 LRO

近年来,数据中心技术的进化轨迹中,AI/ML 后端网络的扩张速度超乎我们的预见。今年的 OFC 大会无疑是对这一现象的最佳诠释:规模之宏大,前所未见。
我们的印象中,这一块儿以前是由谷歌来推动的,现在则是由英伟达,因其在 AI 计算方面的主导地位,起到推动光通信等光学技术发展的主要作用。
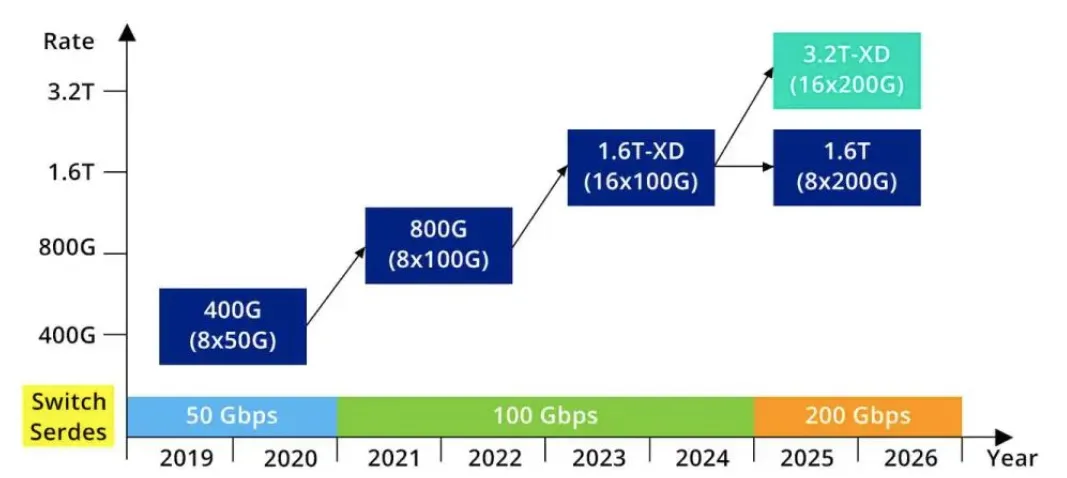
根据预测,到 2025 年,AI/ML 后端网络的光学需求将与现有庞大的前端网络市场并驾齐驱,很可能在两年之后,后端将超越前端。当然,伴随而来的是对更高速度和更高密度接口的需求。
因此,我们可以看到,用于前端和后端数据中心结构的 800Gb、1.6TB 和未来的 3.2TB 可插拔光收发器,引起了人们的极大兴趣。
去年,线性可插拔光学器件(LPO)的概念引发热议,它是通过将 DSP 从光模块转移至主机 ASIC ,理论上能够大幅的削减功耗和成本。思科等公司已通过数据验证了这一创新带来的效益。但随着时间推移,人们开始关注链路的稳定性和性能诊断等,使得 LPO 的推广热情有所降温。
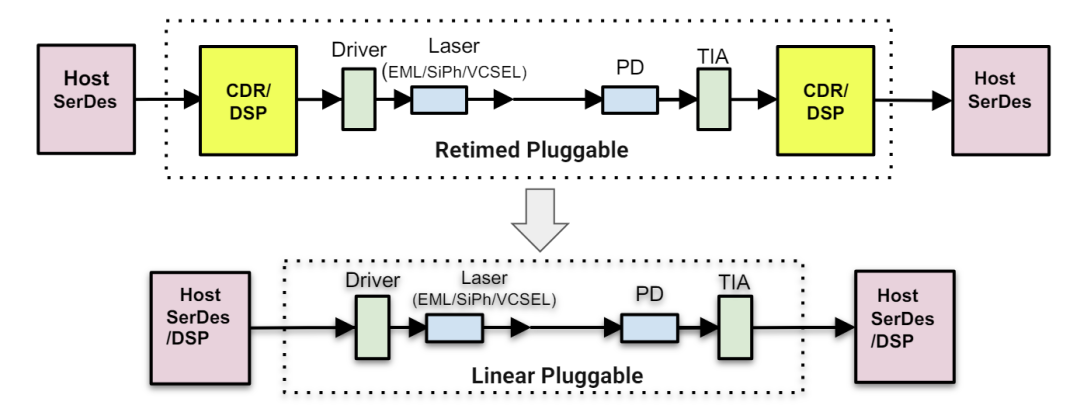
在此背景下,线性接收光学器件(LRO)作为一种折衷方案进入视野。即在发射端(Tx)使用重定时器(retimer),线性接收器直接驱动到主机 ASIC。这一方案虽然不如 LPO 的功耗或成本友好,但与完全重定时的模块相比,仍然起到了降低模块功耗和一定成本的作用,同时还能为链路提供了一些诊断支持。
在每通道100Gb 速率上,LRO 与LPO 在降低功耗、成本等方面都有很大的优势,但针对 LPO 在单波 200Gbps 速率场景中的可行性,今年的 OFC 大会展开了激烈的讨论,为此专门搞了一个Workshop。从会上的各位专家的报告来看,目前主要有两大阵营:
- Arista和Macom 是 LPO 技术的坚定支持者,他们相信即使在 200Gbps 的速率下,LPO 技术仍然可行。
- Google, Meta, 华为和阿里则是不同的意见。他们认为,为了实现单波200Gbps的速率,就必须引入重定时器,并采用传统的 DSP 方案。通过 DSP 提供强大的链路性能和较高的链路预算,可有效应对链路中的损耗和干扰,等等...。
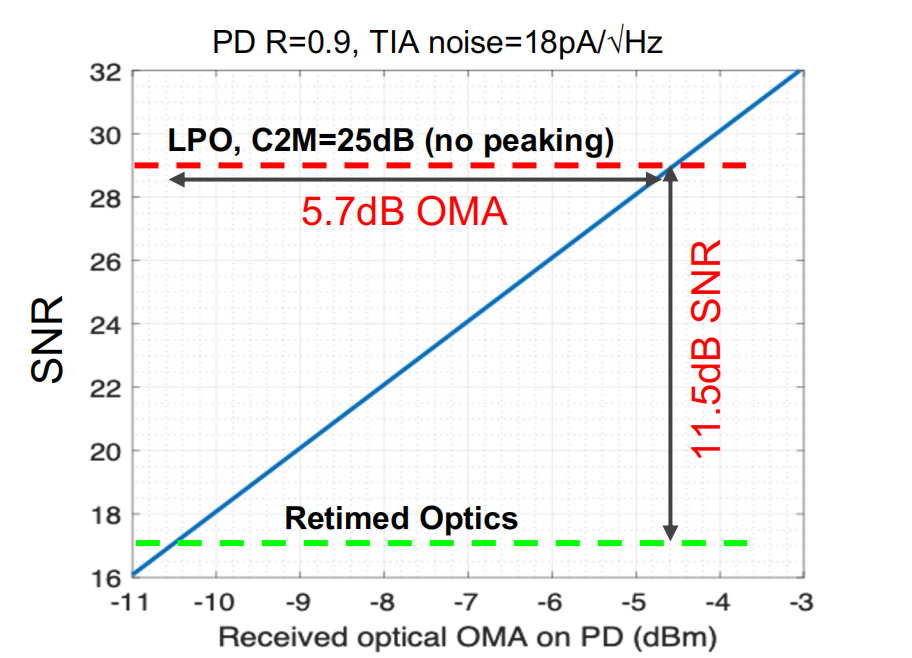
图:无retimer的LPO, 25dB(C2M),比Retimed Optics需要高11.5dB的SNR
另外,市场上对 LPO 的功耗还是较大的质疑。LPO 方案虽然省去了模块中的串行器/解串器(SerDes)和oDSP的功耗,但由于对链路损耗的要求更为严格,需要在主机端对信号进行补偿,导致主机端SerDes的功耗增加。
我们可以看出虽然 LPO 方案的初衷是为了降低功耗,但在提高信道速率的同时如何继续有效降低功耗,仍是业界面临的一个难题。而这一需求也催生了创新性的冷却技术,比如液体冷却和浸没式冷却,它们通过直接或间接的液体接触散热,可有效缓解高速度、高密度硬件带来的热管理难题。目前据了解各公司正根据自身情况,探索个性化的解决方案。
这里提一下阿里巴巴的谢崇在Workshop上展示的一张 LPO 和400G DR4的PPT。根据PPT内容,LPO在功耗上减少了 50%,在延迟上减少了 100%,在生产成本上减少了 30%。但是,正如谢崇进和会议中的许多其他专家所指出的那样,200Gbps 单通道的 LPO 技术的可行性仍是一个尚未解决的重大行业挑战。
虽然去年的 OFC 大会上,我们就看到了首批支持 200Gbps 单通道技术的光模块亮相。这些初期的解决方案,通过一种类似“gearbox”的设计,实现了与宿主接口 100Gbps 电通道的兼容。尽管一些前沿的采用者可能会选择这种配置的系统和光模块,但长远来看,更理想的方案是宿主与光模块之间直接使用 200Gbps 的电通道进行连接,这将更能发挥 200Gbps 单通道光模块的潜力。
而今年的大会上,我们看到了 200Gbps 单通道速率的光模块种类更加丰富,技术成熟度也比去年的初步演示有了大幅提升。比如说牛B的博通,宣布推出每通道 200 Gbps EML 模块和首款200G/通道垂直腔面发射激光器 VCSEL 模块。
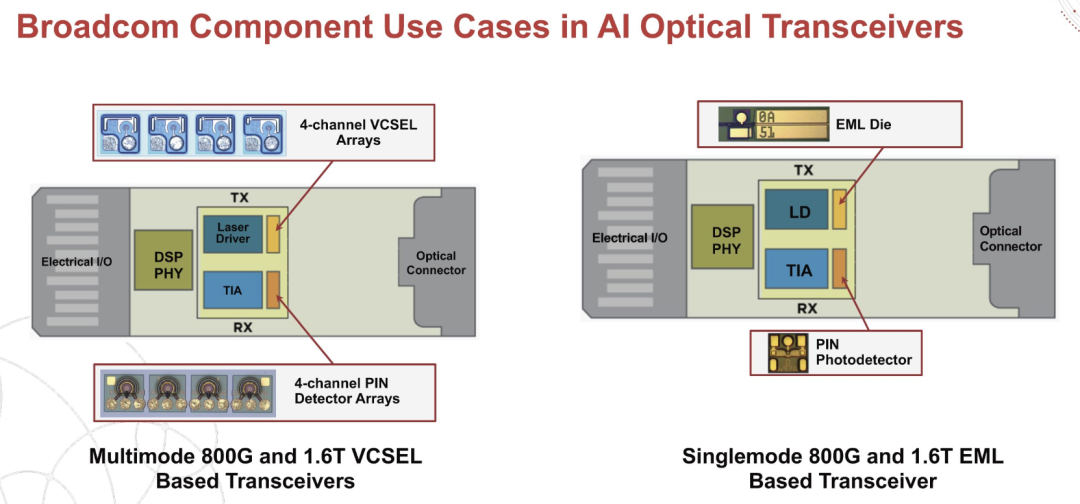
但对于 200Gbps 单通道速率的模块方案,是采用 LPO 还是 LRO?大家可以留言发表看法!
无论是何种方案,相信 200Gbps 单通道光模块能够在数据中心的互连、AI/ML 以及大规模网络传输等关键领域扮演更加关键的角色。
闲聊,若有不准确地方,请见谅,感谢阅读!欢迎关注我们!