强化学习系列(九)--A3C
原创
好久没有更新强化学习这个系列了,今天继续更新下强化学习系列的A3C技术,后面会结合当前最火大模型强化学习训练持续更新此系列。
前年...我们学习了强化学习基础知识中的AC和A2C技术。
Advantage Actor-Critic(A2C)(强化学习系列六)
本文介绍进一步提升A2C的方案Asynchronous Advantage Actor-Critic(A3C)方法。
Asynchronous Advantage Actor-Critic(A3C)
论文地址:http://proceedings.mlr.press/v48/mniha16.pdf
《Asynchronous Methods for Deep Reinforcement Learning》这篇文章提出了A3C的思路:
通过创建多个agent,在多个环境实例中并行且异步的执行和学习,充分的利用了计算资源。每个线程有一个agent运行在环境中,每个agent的状态不一样所以参数梯度也不一样,多个线程的梯度进行累加,然后到一定步数后一起更新共享参数。
论文中提到将one-step Sarsa, one-step Q-learning, n-step Q-learning和advantage AC扩展至多线程异步架构。这些算法在之前的系列中有提到过,AC是on-policy的policy搜索方法,而Q-learning是off-policy value-based方法。这也体现了该框架的通用性。在上文也提过,每个线程都有agent运行在环境的拷贝中,每一步生成一个参数的梯度,多个线程的这些梯度累加起来,一定步数后一起更新共享参数。
论文提出框架优点:
1)它运行在单个机器的多个CPU线程上,而非使用parameter server的分布式系统,这样就可以避免通信开销和利用lock-free的高效数据同步方法(Hogwild!方法)。
2)多个并行的actor可以有助于exploration。在不同线程上使用不同的探索策略,使得经验数据在时间上的相关性很小。这样不需要DQN中的experience replay也可以起到稳定学习过程的作用,意味着学习过程可以是on-policy的。
其它好处包括更少的训练时间,另外因为不需要experience replay所以可以使用on-policy方法,且能保证稳定。
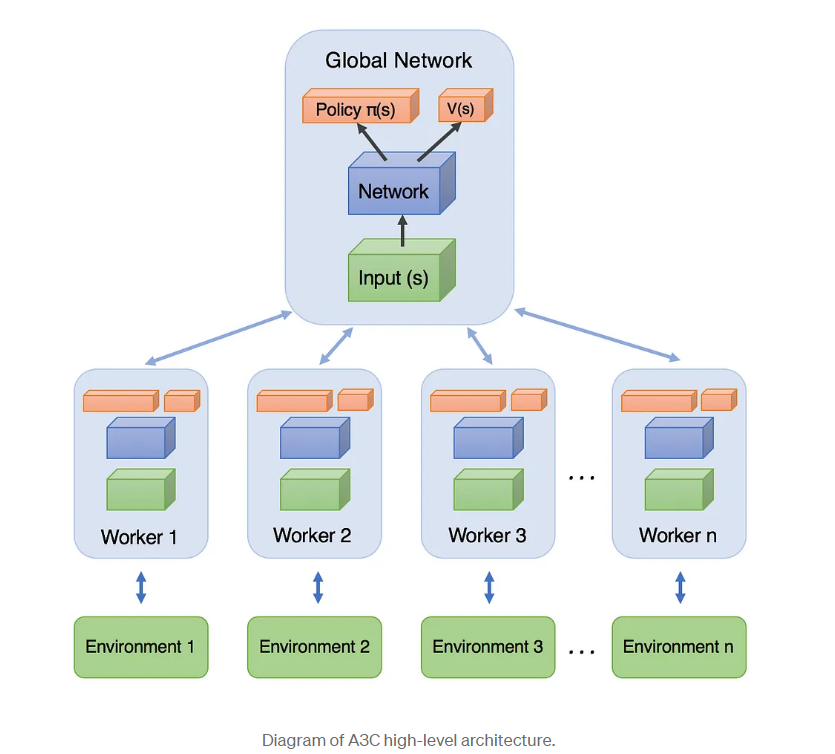
从A3C框架图中也可以看出,框架中有多个Worker,论文主推的是每个Woker使用A2C网络。主网络会将参数拷贝道每个Worker中,以及从每个Worker同步各自的梯度在主网络同步进行参数更新。类似我们的分布式模型训练,在每张卡上进行梯度计算,然后同步一起更新共享模型参数。
虽然现在看起来这个思路很常见,但是这篇文章可是2016年提出来的。
下面直接通过代码理解A3C思路:
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
import matplotlib.pyplot as plt
import pandas as pd
GAME = 'CartPole-v0'
OUTPUT_GRAPH = True
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_GLOBAL_EP = 500
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.001
LR_A = 0.001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.n
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.int32, [None, ], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
self.a_prob, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td)) # critic的loss是平方loss
with tf.name_scope('a_loss'):
# Q * log(
log_prob = tf.reduce_sum(tf.log(self.a_prob + 1e-5) *
tf.one_hot(self.a_his, N_A, dtype=tf.float32),
axis=1, keep_dims=True)
exp_v = log_prob * tf.stop_gradient(td) # 这里的td不再求导,当作是常数
entropy = -tf.reduce_sum(self.a_prob * tf.log(self.a_prob + 1e-5),
axis=1, keep_dims=True) # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'): # 把主网络的参数赋予各子网络
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'): # 使用子网络的梯度对主网络参数进行更新
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
a_prob = tf.layers.dense(l_a, N_A, tf.nn.softmax, kernel_initializer=w_init, name='ap') # 得到每个动作的选择概率
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # 得到每个状态的价值函数
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return a_prob, v, a_params, c_params
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
prob_weights = SESS.run(self.a_prob, feed_dict={self.s: s[np.newaxis, :]})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME).unwrapped
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
while True:
a = self.AC.choose_action(s)
s_, r, done, info = self.env.step(a)
if done: r = -5
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_ # 使用v(s) = r + v(s+1)计算target_v
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.array(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
s = s_
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.99 * GLOBAL_RUNNING_R[-1] + 0.01 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
# Coordinator类用来管理在Session中的多个线程,
# 使用 tf.train.Coordinator()来创建一个线程管理器(协调器)对象。
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job) # 创建一个线程,并分配其工作
t.start() # 开启线程
worker_threads.append(t)
COORD.join(worker_threads) #把开启的线程加入主线程,等待threads结束
res = np.concatenate([np.arange(len(GLOBAL_RUNNING_R)).reshape(-1,1),np.array(GLOBAL_RUNNING_R).reshape(-1,1)],axis=1)
pd.DataFrame(res, columns=['episode', 'a3c_reward']).to_csv('../a3c_reward.csv')
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()参考资料:
https://blog.csdn.net/jinzhuojun/article/details/72851548
https://github.com/princewen/tensorflow_practice/blob/master/RL/Basic-A3C-Demo/A3C.py
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。