中山&港大| 提出DQ-LoRe框架,自动选择上下文示例,为LLMs复杂推理开辟新道路!
中山&港大| 提出DQ-LoRe框架,自动选择上下文示例,为LLMs复杂推理开辟新道路!

引言
大模型(LLMs)在上下文学习方面展现出了卓越的能力。为了提高LLMs在复杂推理任务中的表现,人们提出思维链”(Chain-of-Thought,CoT)的方法,利用中间推理步骤来辅助模型生成。那么,如何有效地选择优秀示例来提升LLMs上下文学习能力呢?
为此,本文提出了DQ-LoRe框架,利用「双重查询(DQ)和低秩近似重排(LoRe)」自动选择上下文学习示例。实验表明,DQ-LoRe在自动选择GPT-4示例方面超越了之前的方法,准确率从92.5%提升至94.2%,为LLMs解决复杂推理问题开辟了新道路。
https://arxiv.org/pdf/2310.02954
背景介绍
随着模型规模和语料规模的扩大,大模型展现出了强大的上下文学习能力(ICL)。这种能力使得LLMs能够通过少量示例学习就能执行各种复杂任务,例如:摘要总结、信息抽取和规划推理。此外,为了增强LLM的能力,人们还探索了通过提供中间推理步骤的“思维链”(Chain-of-Thought,CoT)来增强其学习能力。
CoT的有效性体现在它可以通过多种方法进一步提升,例如将复杂问题分解、在推理前进行规划,以及在多轮投票和推理中应用CoT范式。特别是在多步推理任务中,使用CoT的上下文学习方法已被证明比对同一大型模型进行的全数据集微调更为有效。这些进展不仅展示了LLMs在执行复杂任务方面的能力,还为未来在自然语言处理领域的研究和应用开辟了新的可能性。
在此过程中,如何选择合适的示例将是一个关键的问题。因为先前研究表明,在选择示例时会面临不稳定的挑战,即示例中样本顺序的微小变化也可能影响大模型的输出,可见样本示例选择对增强LLM多步推理能力至关重要。当前主要有两种方法来选择示例:1)人工选择设计;2)基于检索的方法
- 人工选择设计方法:例如,传统的CoT方法主要利用人工编写的八个示例,而PAL方法则将这些示例转化为编程语言语句;Auto-CoT方法通过将训练示例聚类成k个类别,并选择与每个类别中心最近的k个样本来选择示例。该类方法主要是基于试错的方法,很难从经验观察中提取出普遍性的规律来形成有效的选择标准。
- 基于检索的方法:利用编码器在训练期间对样本进行编码并输入问题,这使得能够选择接近输入问题的向量表示的样本。例如,高效提示检索(EPR)对输入问题和上下文样本之间的交互进行建模,并通过对比学习目标对其进行优化以获得首选样本。此类方法主要关注输入问题和训练集中示例之间的相似性,并没有充分利用给定问题中间推理步骤与其他示例之间的关系。
相比以上两种方法,本提出了一种了DQ-LoRe框架,利用「双重查询和低秩近似重排」自动选择上下文学习中的示例。简单来说,本文方法会将原始表示投影到一个新的表示空间,对实例进行重新排名,以选择与输入问题知识更紧密对齐的示例,从而提高了大模型上下文学习能力。
DQ-LoRe
DQ-LoRe的整体流程如下图所示。它主要由三部分组成:双重查询(DQ)、检索器(Retriever)、低秩近似重排序(LoRe)。
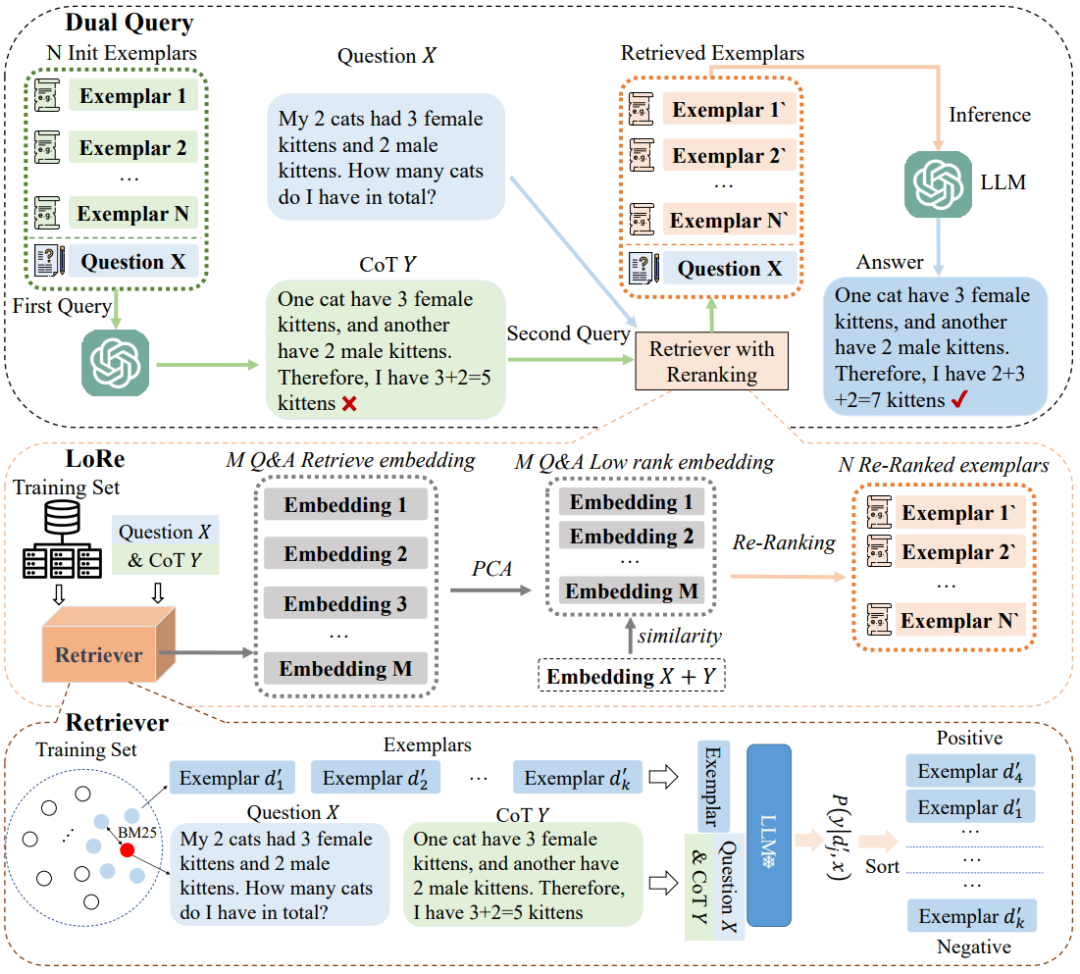
「DQ」 首先通过请求大模型(LLMs)来生成思维链(CoT)。这个过程始于初始的n-shot示例,这些示例可以通过多种检索方法,此外,示例还可以包括人工设计的示例,例如CoT、Tree-of-Thought和Graph-of-Thought等模板。本文主要是采用Complex-CoT方法来获取这些初始示例,因为这种方法能够生成信息量丰富的CoT。
随后,利用这些初始示例和DQ问题再次请求LLMs,从而获得对应的CoT 。最后,结合问题和生成的CoT ,作者使用训练的「编码器」来获得测试样本的嵌入表示。
「Retriever」 为了获得示例和测试样本的表示,作者训练了一个编码器,同时为了衡量思维链(CoT)与示例之间的相似性,还开发了一个检索器。简单来说,作者利用训练集中的数据来构建训练数据,每个样本由一个问题
及其对应的CoT
组成,其中
代表训练集中的第
个数据点。通过这种方式,编码器能够学习到能够准确反映问题和CoT之间关系的特征表示,从而提高检索器在挑选与输入问题最相关示例时的性能。
「LoRe」 在获取了基于语义相似性检索的示例后,使用主成分分析(PCA)进行降维,以去除嵌入中的冗余信息,并使用高斯核函数重新计算示例和目标样本之间的相似性,以此来重排序示例。根据重排序后得到的示例,选择顶部的n个示例,并将它们与问题一起输入LLMs以获得最终的CoT和推理结果。
通过以上步骤,DQ-LoRe框架能够在考虑输入问题的CoT的同时,自动选择和重排序示例,以提高LLMs在复杂推理任务中的性能。该方法通过双重查询和低秩近似重排序,有效地结合了问题内容和CoT信息,提高了示例选择的相关性和准确性。
实验结果
下图展示了在独立同分布
设置下,本文模型在GSM8K和AQUA数据集上展现了优异的性能。为了排除偶然相关性的影响并评估模型的真实性能,作者进行了分布偏移条件下的实验。作者在GSM8K数据集上训练检索器,并在SVAMP测试集上进行测试,本文模型在SVAMP*上达到了90%的准确率,显著超过了EPR模型。
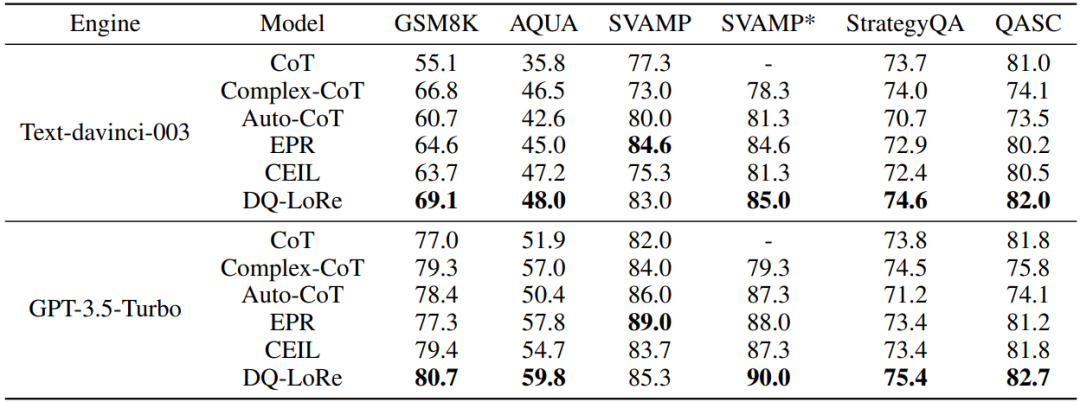
下图展示了GPT-4在GSM8K数据集上的ICL结果。本文模型性能大大超过了之前最先进的基于检索的方法 CEIL,准确率大幅提高了1.7%。e
