

接触MGR有一段时间了,MySQL 8.0.23的到来,基于MySQL Group Replicaion(MGR)的高可用架构又提供了新的架构思路。
MGR 到底可以坏几个节点?
这次我就以上2个问题,和大家简单聊下MGR的一些思想和功能。
一、MySQL Group Relication 成员数量的容错能力
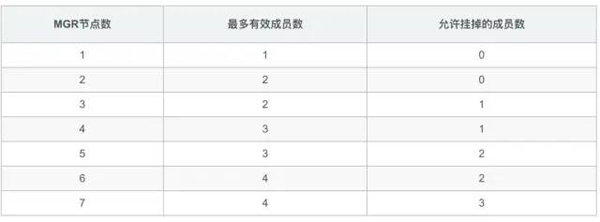
上面的表格相信大家不会陌生了,我经常在面试里会问:“4个节点的MGR,最多坏几个呢?” ,多数人回答:“最多坏1个,坏2个就脑裂不能工作了。”
那我们来看看MGR的处理方式,是不是这个答案呢?
1)我们具有一个4节点MGR
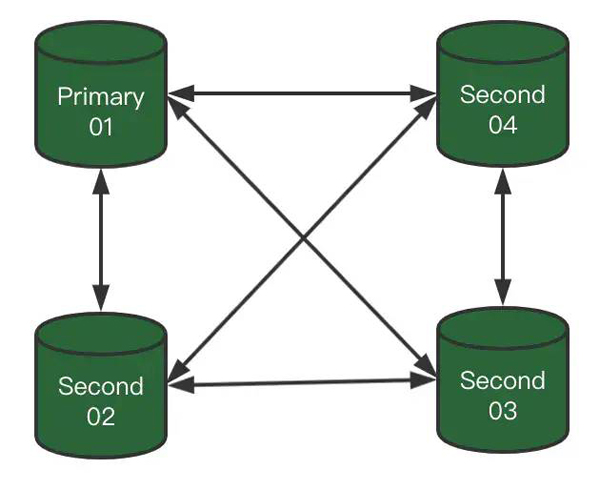
埋一个问题:这个图一看就是Single模式,但箭头不是单向,是不是画错了?
2)此时,Second-04突然宕机了,那么MGR集群会成什么样子呢?
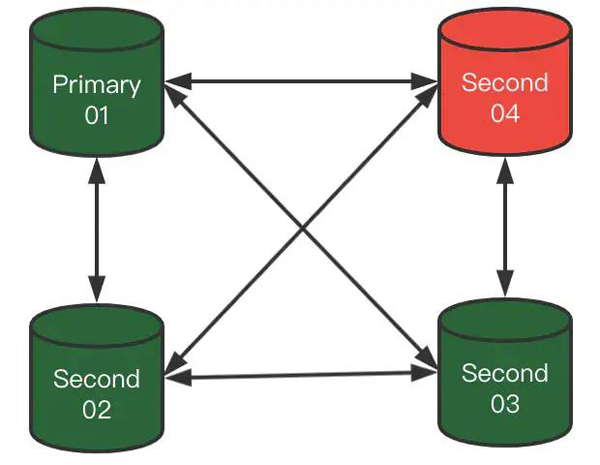
集群此时状态会变成:
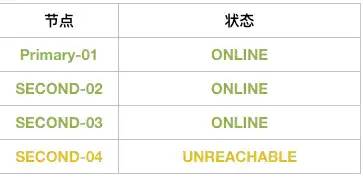
那么重点来了,敲黑板
在Second-04,没有被驱逐出去时:
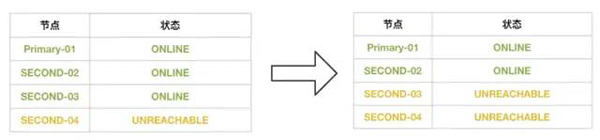
在Second-04,被驱逐出去后:
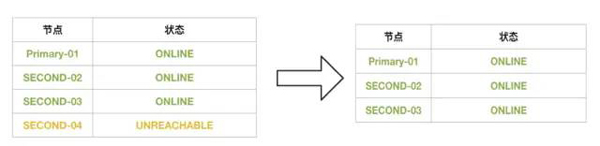
所以4节点集群是否可以坏1个还是2个,具体要看集群处理过程哪个阶段哦。
PS:
我们说说刚才埋的问题:这个图一看就是Single模式,但箭头不是单向,是不是画错了?
首先Single模式,Second节点默认是不能写入的,但只是由于Second节点的super-read-only开启了。
将Second节点super-read-only = 0,Second节点可以正常写入,并可以同步其他节点(Primary和其他Second),传输还是基于Paxos协议的。
跑个火车:Second节点反向同步其他节点,是不会经过冲突检测阶段(理论效率要高于多写模式),没有验证,大家有兴趣可以研究下。
二、 Asynchronous Connection Failover
MySQL 8.0.22,推出了异步复制连接故障转移,很多朋友都发文做了介绍,这里我只简单描述下:
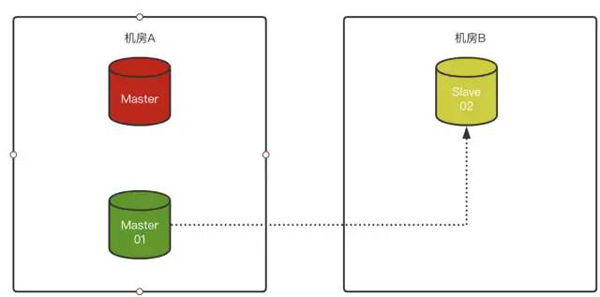
1)同机房1主1从,异地机房单独放一个slave节点
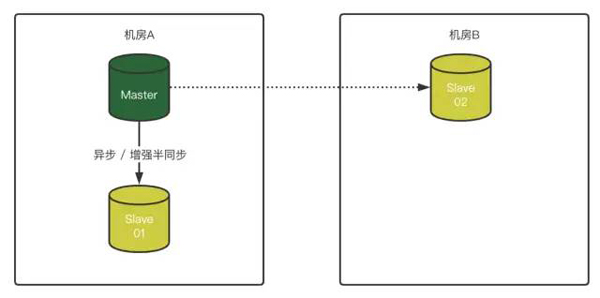
2)Master 故障,将Slave-01变成Master,Slave-02无法连接原Master

3)如果对Slave-02配置了“异步连接故障转移配置”,那么Slave-02在识别原Master故障后,会自动尝试按照预先定义好的配置,与原Slave-01(新Master)建立复制关系:
这个功能非常好,引用三方工具(例如MHA的修复主从关系)已经可以被MySQL原生功能代替了。
但我测试完,又有了几点疑虑:
1. “异步”复制故障转移,难道不支持半同步架构?不能确保数据不丢失,还是无法完全代替MHA啊?
答:其实是支持增强半同步的。
2. 要预先配置故障转移的Master List,那么A机房架构变更,还要去维护机房B的节点吗?
答:是的。
3. 如果A机房是MGR,那么MGR的节点(master)异常,但服务没有关,可以访问,机房B节点岂不是一直连接着?
答:是的
然后,MySQL 8.0.23发布了,带来了此功能的增强:
Slave可以支持MGR集群,并且可以动态识别MGR成员,来建立Master-Slave关系了
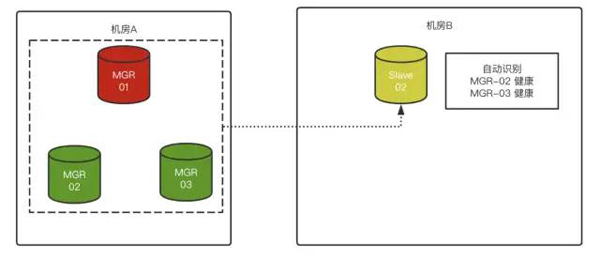
最后让我们跑一圈:
1)首先我们有3节点的MGR集群,版本8.0.22(异步连接故障转移,是作用在Slave的IO Thread上的,所以Slave是8.0.23版本就成)
- +----------------------------+-------------+--------------+-------------+---------------------+
- | now(6) | member_host | member_state | member_role | VIEW_ID |
- +----------------------------+-------------+--------------+-------------+---------------------+
- | 2021-01-22 13:41:27.902251 | mysql-01 | ONLINE | SECONDARY | 16112906030396799:9 |
- | 2021-01-22 13:41:27.902251 | mysql-02 | ONLINE | PRIMARY | 16112906030396799:9 |
- | 2021-01-22 13:41:27.902251 | mysql-03 | ONLINE | SECONDARY | 16112906030396799:9 |
- +----------------------------+-------------+--------------+-------------+---------------------+
2)然后我们在独立Slave节点,指定Slave上“对Master连接故障转移列表”
- SELECT asynchronous_connection_failover_add_managed('ch1', 'GroupReplication', 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1', 'mysql-02', 3306, '', 80, 60);
- 简单解释下参数:
- ch1:chanel名称
- GroupReplication:强制写死的参数,目前支持MGR集群
- aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1:MGR组名(参数 group_replication_group_name)
- mysql-02:MGR成员之一
- 80:Primary节点的优先级(0-100),多主相同优先级则随机选择节点充当master。
- 60:Second节点的优先级(0-100),基本就是给Single模式准备的
3)为Slave指定复制通道信息
- CHANGE REPLICATION SOURCE TO SOURCE_USER='rpl_user', SOURCE_PASSWORD='123456', SOURCE_HOST='mysql-02',SOURCE_PORT=3306,SOURCE_RETRY_COUNT=2,SOURCE_CONNECTION_AUTO_FAILOVER=1,SOURCE_AUTO_POSITION=1 For CHANNEL 'ch1';
4)启动Slave,并查看“连接的可转移列表”
rpl_user需要在MGR节点对performance_schema具有select权限
- start slave;
- SELECT * FROM performance_schema.replication_asynchronous_connection_failover;
- +--------------+----------+------+-------------------+--------+--------------------------------------+
- | CHANNEL_NAME | HOST | PORT | NETWORK_NAMESPACE | WEIGHT | MANAGED_NAME |
- +--------------+----------+------+-------------------+--------+--------------------------------------+
- | ch1 | mysql-01 | 3306 | | 60 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
- | ch1 | mysql-02 | 3306 | | 80 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
- | ch1 | mysql-03 | 3306 | | 60 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
- +--------------+----------+------+-------------------+--------+--------------------------------------+
5)然后我们将mysql-02 stop group_replication(不是关闭服务),
- Slave列表自动淘汰mysql-02,重新与其他节点建立连接-- mysql-02(Primary):
- stop group_replication;
- -- Slave:
- SELECT * FROM performance_schema.replication_asynchronous_connection_failover;
- +--------------+----------+------+-------------------+--------+--------------------------------------+
- | CHANNEL_NAME | HOST | PORT | NETWORK_NAMESPACE | WEIGHT | MANAGED_NAME |
- +--------------+----------+------+-------------------+--------+--------------------------------------+
- | ch1 | mysql-01 | 3306 | | 80 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
- | ch1 | mysql-03 | 3306 | | 60 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
- +--------------+----------+------+-------------------+--------+--------------------------------------+
- show slave status\G
- *************************** 1. row ***************************
- Slave_IO_State: Waiting for master to send event
- Master_Host: mysql-01
- Master_User: rpl_user
- Master_Port: 3306
- Connect_Retry: 60
- Master_Log_File: mybinlog.000003
- Read_Master_Log_Pos: 4904
- Relay_Log_File: mysql-01-relay-bin-ch1.000065
- Relay_Log_Pos: 439
- Relay_Master_Log_File: mybinlog.000003
- Slave_IO_Running: Yes
- Slave_SQL_Running: Yes
- ...
至此,配置完成。后面MGR节点增、减,Slave都可以自动维护这个列表。不贴其他用例了。
PS:
- -- 删除配置
- SELECT asynchronous_connection_failover_delete_managed('ch1', 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1');
- -- 重新添加,调整Second优先级高于Primary
- SELECT asynchronous_connection_failover_add_managed('ch1', 'GroupReplication', 'aaaaaa

在Flash Player 10.1及以上版本中,adobe新增了全局错误处理程序UncaughtErrorEv...
本文转载自微信公众号「SH的全栈笔记」,作者SH。转载本文请联系SH的全栈笔记公...
本文转载自微信公众号「SQL数据库」,作者丶平凡世界 。转载本文请联系开发公众...
前言 项目开发中不管是前台还是后台都会遇到烦人的null,数据库表中字段允许空值...
来源:DeepenStudy 漏洞文件:js.asp % Dimoblog setoblog=newclass_sys oblog.a...
本文实例讲述了AJAX+Servlet实现的数据处理显示功能。分享给大家供大家参考,具...
大家好,我是狂聊君。 今天来聊一聊 Mysql 缓存池原理。 提纲附上,话不多说,直...
idea官方推送了2020.2.4版本的更新,那么大家最关心的问题来了,之前激活idea202...
CKeditor,以前叫FCKeditor,已经使用过好多年了,功能自然没的说。最近升级到3....
问题:我们在做flex的开发中,如果用到别人搭建好的框架,而别人的server名称往...


