

网页爬虫:就是一个程序用于在互联网中获取指定规则的数据。
思路:
1.为模拟网页爬虫,我们可以现在我们的tomcat服务器端部署一个1.html网页。(部署的步骤:在tomcat目录的webapps目录的ROOTS目录下新建一个1.html。使用notepad++进行编辑,编辑内容为:
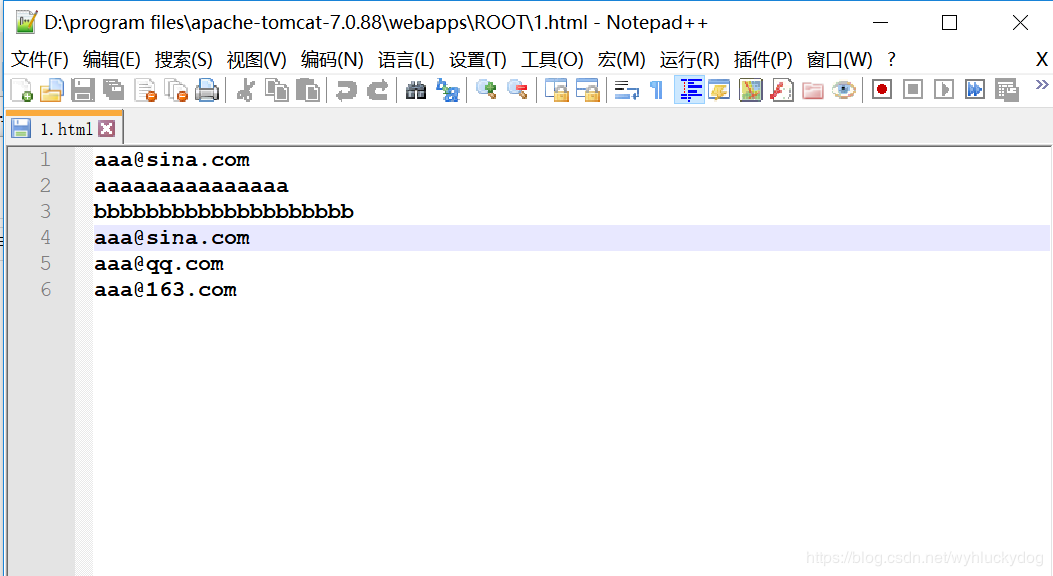 )
)
2.使用URL与网页建立联系
3.获取输入流,用于读取网页中的内容
4.建立正则规则,因为这里我们是爬去网页中的邮箱信息,所以建立匹配 邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+";
5.将提取到的数据放到集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List<String> list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List<String> getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List<String> list=new ArrayList<String>();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:在执行前需要先开启tomcat服务器
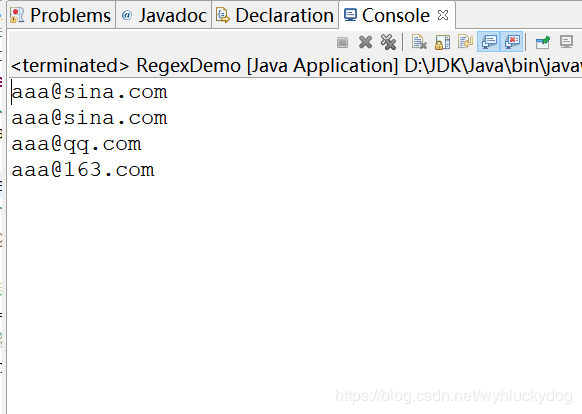
运行结果:
总结
以上所述是小编给大家介绍的使用正则表达式实现网页爬虫的思路详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对站长技术网站的支持!

本文实例讲述了AJAX+Servlet实现的数据处理显示功能。分享给大家供大家参考,具...
CKeditor,以前叫FCKeditor,已经使用过好多年了,功能自然没的说。最近升级到3....
来源:DeepenStudy 漏洞文件:js.asp % Dimoblog setoblog=newclass_sys oblog.a...
本文转载自微信公众号「SQL数据库」,作者丶平凡世界 。转载本文请联系开发公众...
前言 项目开发中不管是前台还是后台都会遇到烦人的null,数据库表中字段允许空值...
本文转载自微信公众号「SH的全栈笔记」,作者SH。转载本文请联系SH的全栈笔记公...
大家好,我是狂聊君。 今天来聊一聊 Mysql 缓存池原理。 提纲附上,话不多说,直...
问题:我们在做flex的开发中,如果用到别人搭建好的框架,而别人的server名称往...
在Flash Player 10.1及以上版本中,adobe新增了全局错误处理程序UncaughtErrorEv...
idea官方推送了2020.2.4版本的更新,那么大家最关心的问题来了,之前激活idea202...


