


做这篇文章是因为一个朋友想要做Telegraf监控,存入到InfluxDB里,虽然我不理解为什么要这么做,但还是一本正经地研究了起来,愈发觉得这组合确实不错,随着不断地深入发现,这东西居然和Zabbix有点类似,就是操作稍微复杂点,但是熟悉了也还好。
Telegraf:1.17
InfluxDB:2.0.4
- wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.4.x86_64.rpm
- yum localinstall influxdb2-2.0.4.x86_64.rpm -y
- systemctl start influxdb && systemctl enable influxdb
InfluxDB默认前端访问地址是http://ip地址:8086(如果无法访问请检查Selinux和防火墙是否关闭)
下一步即可
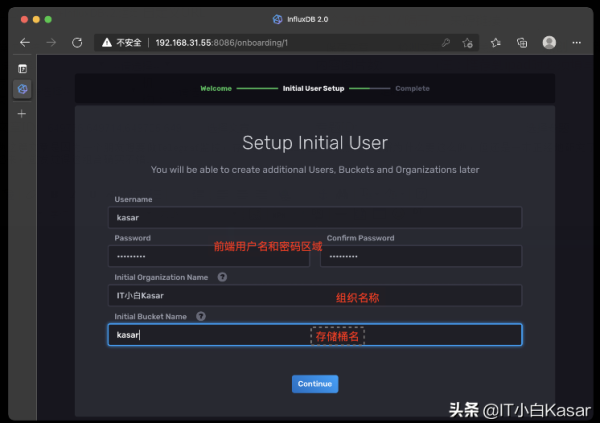
填写相关信息
配置完成,进入首页
首页
1.下载Telegraf
- wget https://dl.influxdata.com/telegraf/releases/telegraf-1.17.3-1.x86_64.rpm
- yum localinstall telegraf-1.17.3-1.x86_64.rpm -y
2.前端创建配置

创建配置
选择系统即可
创建即可
这里确定即可

点击进去
将内容复制一份
3.修改配置文件
- cd /etc/telegraf
- ####备份原有配置文件####
- mv telegraf.conf telegraf.conf.bak
- ####创建配置文件####
- vi telegraf.conf
将刚才的复制的配置文件粘贴进去
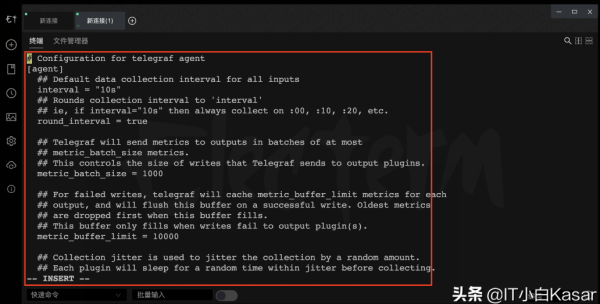
粘贴配置文件
替换token
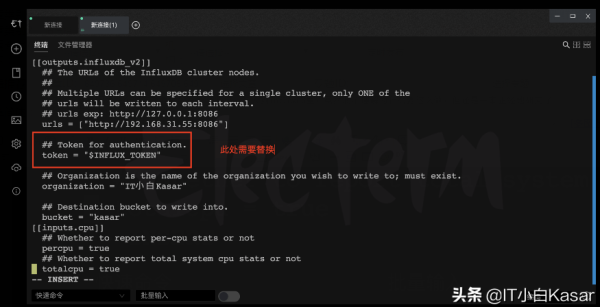
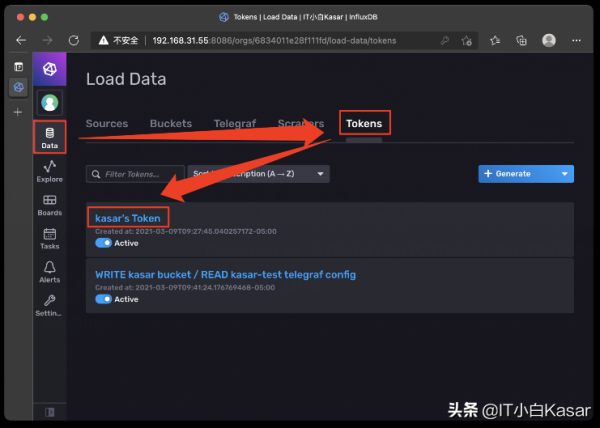
点击进去
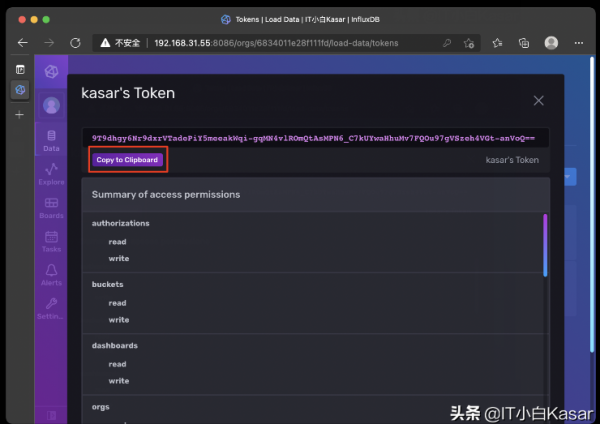
copy该token
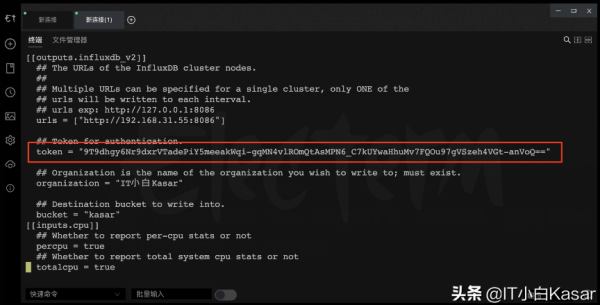
替换token
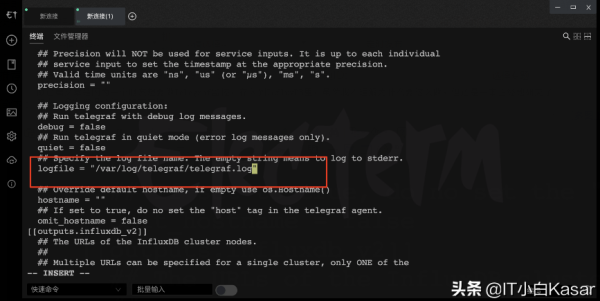
添加日志路径
4.启动服务并查看日志。
- service telegraf start
如果出现下图结果,证明服务成功
5.添加dashboard
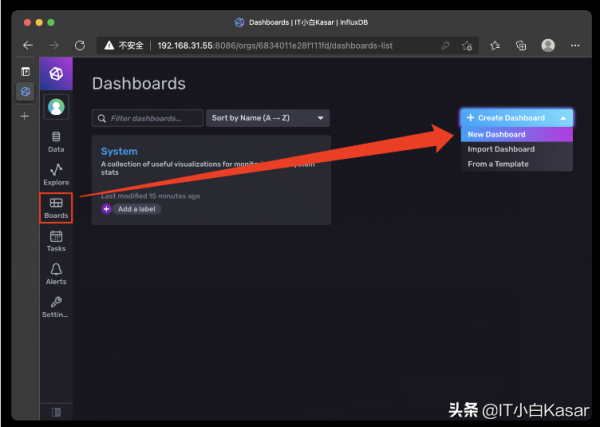
添加新的dashboard,选择from template
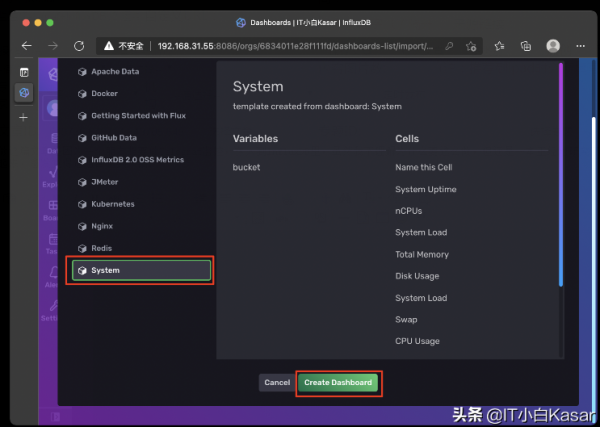
选择system创建
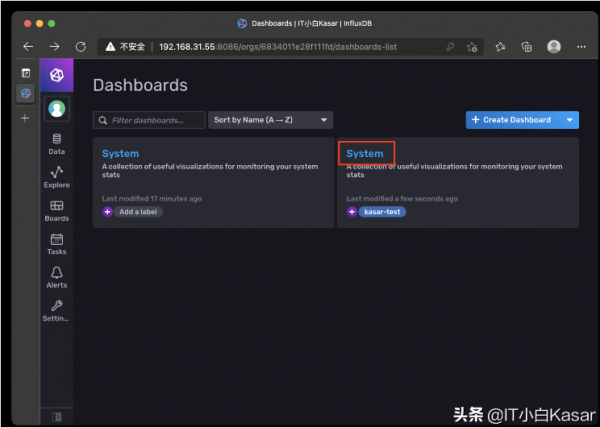
点击进去即可
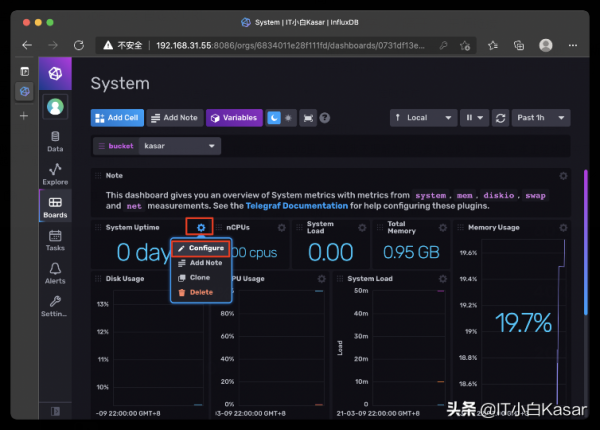
编辑指标
添加一条主机过滤规则,这里和你的环境有关系,替换后面的名称即可
- |> filter(fn: (r) => r["host"] == "MiWiFi-R4A-srv")
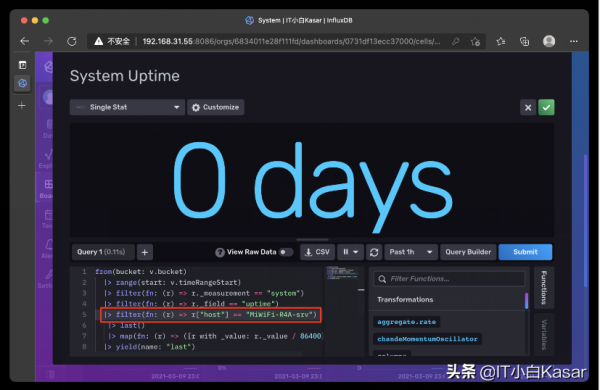
最终效果
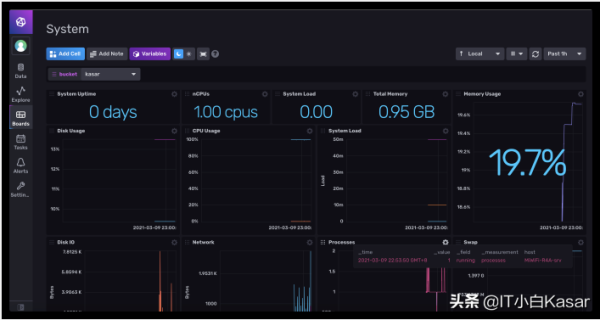
整个部署过程比较容易,由于是开篇,所以理论知识没怎么讲的,大家如果觉得还可以,我可以继续往下深挖,其实和Zabbix很类似,至于为什么没有对接Grafana,大家可以从图中看出,InfluxDB在这个版本已经集成了前端功能,说实话我就是被这个前端所吸引,V2版本更有点像对象存储的理论,但依然还是一个时序数据库,但万变不离其中,皆有迹可循,理解了逻辑就并不难,那这篇就到这里,谢谢。

一、院校分析——东南大学 1. 夏令营预推免 东南大学信科学院的招生没有夏令营只...
获取需要使用到正则的两个对象: 使用的是用正则对象Pattern 和匹配器Matcher。 ...
这篇文章底端的图为什么这么大……不管了 [--大家好我们第一个团本CD就通了PT而...
php语言是一种脚本语言,它能够做很多事情比如说它可以用来与数据库交互开发web...
1.勇敢的女人,永远比懦弱的女人美丽。如果,你的爱人不爱你,我劝你还是勇敢。...
本文将介绍由腾讯与欧洲顶级农业大学 WUR荷兰瓦赫宁根大学共同举办的第二届“国...
本文转载自微信公众号「DBA闲思杂想录」,作者潇湘隐者 。转载本文请联系DBA闲思...
asp的循环语句有以下几类: 循环语句的作用就是重复执行程序代码,循环可分为三...
记录一下折腾nodemcu的经过。 本文主要讲述如何使用nodemcu开发板上报数据到onen...
1、什么是语义化? 必应网典的解释 语义化是指用合理HTML标记以及其特有的属性去...

