

БОЯЕСаЮФеТЩцМАЕФЫуЗЈАќРЈЫбЫїЁЂЛиЫнЁЂЕнЙщЁЂХХађЁЂЕќДњЁЂЬАаФЁЂЗжжЮКЭЖЏЬЌЙцЛЎЕШ,ЩцМАЕФЪ§ОнНсЙЙАќРЈзжЗћДЎЁЂСаБэЁЂжИеыЁЂЧјМфЁЂЖгСаЁЂОиеѓЁЂЖбеЛЁЂСДБэЁЂЙўЯЃБэЁЂЯпЖЮЪїЁЂЖўВцЪїЁЂЖўВцЫбЫїЪїКЭЭМНсЙЙЕШЁЃ
БОЯЕСаЮФеТЪЧБЪепЮЊЪЪгІЕБЧАНЬг§ИФИяЕФДДаТвЊЧѓ,ИќКУЕиМљаагябдРрПЮГЬ,ТњзуЪЕМљНЬбЇгыДДаТФмСІХрбјЕФашвЊ,дФЖСДѓСПЪщМЎЁЂИїДѓЛЅСЊЭјЙЋЫОЕФУцЪдЫуЗЈЁЂLintCodeЁЂLeetCodeЁЂОХеТЫуЗЈКЭНсКЯБЪепНќМИФъЯюФПОбщБраДЕФЯЕСаЮФеТ,ОЋбЁСЫ 1000 ИіШЄЮЖадЁЂЪЕгУадЧПЕФгІгУЪЕР§,ДгВЛЭЌФбЖШЁЂВЛЭЌЫуЗЈЁЂВЛЭЌРраЭКЭВЛЭЌЪ§ОнНсЙЙЕШЗНУц,НЋЪЕМЪЫуЗЈНјаазмНс,ЯЃЭћЮЊ Python БрГЬШЫдБХззЉв§гёЁЃгЩгкБЪепОбщгыЫЎЦНгаЯо,ВЉЮФжаЪшТЉМАВЛЭзжЎДІдкЫљФбУт,ждаФЕиЯЃЭћИїЮЛЖСепдкЦРТлЧјЖрЬсБІЙѓвтМћМАОпЬхЕФаоИФНЈвщ,вдБуБЪепНјвЛВНаоИФКЭЭъЩЦЁЃ
ЗжПщВщевЪЧЖўЗжЗЈВщевКЭЫГађВщевЕФИФНјЗНЗЈ,ЗжПщВщеввЊЧѓЫїв§БэЪЧгаађЕФ,ЖдПщФкНсЕуУЛгаХХађвЊЧѓ,ПщФкНсЕуПЩвдЪЧгаађЕФвВПЩвдЪЧЮоађЕФЁЃ
ЗжПщВщевОЭЪЧАбвЛИіДѓЕФЯпадБэЗжНтГЩШєИЩПщ,УППщжаЕФНкЕуПЩвдШЮвтДцЗХ,ЕЋПщгыПщжЎМфБиаыХХађЁЃгыДЫЭЌЪБ,ЛЙвЊНЈСЂвЛИіЫїв§Бэ,АбУППщжаЕФзюДѓжЕзїЮЊЫїв§БэЕФЫїв§жЕ,ДЫЫїв§БэашвЊАДПщЕФЫГађДцЗХЕНвЛИіИЈжњЪ§зщжаЁЃВщевЪБ,ЪзЯШдкЫїв§БэжаНјааВщев,ШЗЖЈвЊевЕФНсЕуЫљдкЕФПщЁЃгЩгкЫїв§БэЪЧХХађЕФ,вђДЫ,ЖдЫїв§БэЕФВщевПЩвдВЩгУЫГађВщевЛђЖўЗжВщев;ШЛКѓ,дкЯргІЕФПщжаВЩгУЫГађВщев,МДПЩевЕНЖдгІЕФНсЕуЁЃ
Р§Шч,гаетбљвЛСаЪ§Он:23ЁЂ43ЁЂ56ЁЂ78ЁЂ97ЁЂ100ЁЂ120ЁЂ135ЁЂ147ЁЂ150ЁЃШчЯТЭМЫљЪО:

ЯывЊВщевЕФЪ§ОнЪЧ 150,ЪЙгУЗжПщВщевЗЈВНжшШчЯТ:
ВНжш1:НЋЩЯЭМЫљЪОЕФЪ§ОнНјааЗжПщ,АДееУППщГЄЖШЮЊ 4 НјааЗжПщ,ЗжПщЧщПіШчЯТЭМЫљЪО:

ЫЕУї:УППщЕФГЄЖШЪЧШЮвтжИЖЈЕФ,ВЉжїдкетРягУЕФГЄЖШЮЊ4,ЖСепПЩвдИљОнздМКЕФашвЊжИЖЈУППщГЄЖШЁЃ
ВНжш2:бЁШЁИїПщжаЕФзюДѓЙиМќзжЙЙГЩвЛИіЫїв§Бэ,МДбЁШЁЩЯЭМЫљЪОЕФИїПщЕФзюДѓжЕ,ЕквЛПщзюДѓЕФжЕЪЧ 78,ЕкЖўПщзюДѓЕФжЕЪЧ 135,ЕкШ§ПщзюДѓжЕЪЧ 155,аЮГЩЕФЫїв§БэШчЯТЭМЫљЪО:
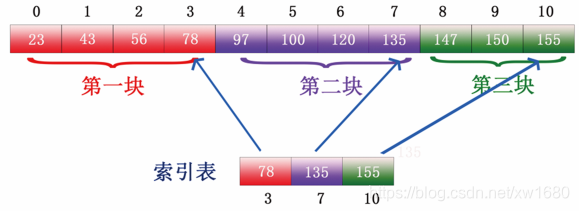
ВНжш3:гУЫГађВщевЛђепЖўЗжВщевХаЖЯЯывЊВщевЪ§Он 150 дкЩЯЭМЫљЪОЕФЫїв§БэжаЕФФФПщФкШнжа,етРяВЉжїгУЕФЪЧЖўЗжВщевЗЈ,МДЯШШЁжаМфжЕ 135 гы 150 БШНЯ,ШчЯТЭМЫљЪО:
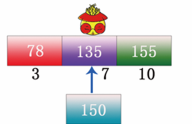
ВНжш4:НсЙћЪЧжаМфЮЛжУЕФЪ§Он 135 БШФПБъЪ§Он 150 аЁ,вђДЫФПБъЪ§Ондк 135 ЕФЯТвЛПщФкЁЃНЋЪ§ОнЖЈЮЛдкЕк 3 ПщФк,ДЫЪБНЋЕк 3 ПщФкЕФЪ§ОнШЁГі,НјааЫГађБШНЯ,ШчЯТЭМЫљЪО:

ВНжш5:ЭЈЙ§ЫГађВщевЕк 3 ПщЕФФкШн,жегкдкЕк 9 ИіЮЛжУевЕНФПБъЪ§,ДЫЪБЗжПщВщевНсЪјЁЃ
змНс:жСДЫ,ЗжПщВщевЫуЗЈвбОНВНтЭъБЯЁЃЭЈЙ§КЭЖўЗжВщевЗЈКЭЫГађВщевЗЈЖдБШРДПД,ЗжПщВщевЕФЫйЖШЫфШЛВЛШчЖўЗжВщевЫуЗЈ,ЕЋБШЫГађВщевЫуЗЈПьЕУЖрЁЃЕБЪ§ОнКмЖрЧвПщЪ§КмДѓЪБ,ЖдЫїв§БэПЩвдВЩгУЖўЗжВщев,етбљФмЙЛНјвЛВНЬсИпВщевЕФЫйЖШЁЃ
ОпЬхДњТыШчЯТ:
def search(data, key): # гУЖўЗжВщев ЯывЊВщевЕФЪ§ОндкФФПщФк
length = len(data) # Ъ§ОнСаБэГЄЖШ
first = 0 # ЕквЛЮЛЪ§ЮЛжУ
last = length - 1 # зюКѓвЛИіЪ§ОнЮЛжУ
print(f"ГЄЖШ:{length} ЗжПщЕФЪ§ОнЪЧ:{data}") # ЪфГіЗжПщЧщПі
while first <= last:
mid = (last + first) // 2 # ШЁжаМфЮЛжУ
if data[mid] > key: # жаМфЪ§ОнДѓгкЯывЊВщЕФЪ§Он
last = mid - 1 # НЋlastЕФЮЛжУвЦЕНжаМфЮЛжУЕФЧАвЛЮЛ
elif data[mid] < key: # жаМфЪ§ОнаЁгкЯывЊВщЕФЪ§Он
first = mid + 1 # НЋfirstЕФЮЛжУвЦЕНжаМфЮЛжУЕФКѓвЛЮЛ
else:
return mid # ЗЕЛижаМфЮЛжУ
return False
# ЗжПщВщев
def block(data, count, key): # ЗжПщВщевЪ§Он,dataЪЧСаБэ,countЪЧУППщЕФГЄЖШ,keyЪЧЯывЊВщевЕФЪ§Он
length = len(data) # БэЪОЪ§ОнСаБэЕФГЄЖШ
block_length = length // count # вЛЙВЗжЕФМИПщ
if count * block_length != length: # УППщГЄЖШГЫвдЗжПщзмЪ§ВЛЕШгкЪ§ОнзмГЄЖШ
block_length += 1 # ПщЪ§Мг1
print("вЛЙВЗж", block_length, "Пщ") # ПщЕФЖрЩй
print("ЗжПщЧщПіШчЯТ:")
for block_i in range(block_length): # БщРњУППщЪ§Он
block_data = [] # УППщЪ§ОнГѕЪМЛЏ
for i in range(count): # БщРњУППщЪ§ОнЕФЮЛжУ
if block_i * count + i >= length: # УППщГЄЖШвЊгыЪ§ОнГЄЖШБШНЯ,вЛЕЉДѓгкЪ§ОнГЄЖШ
break # ОЭЭЫГібЛЗ
block_data.append(data[block_i * count + i]) # УППщГЄЖШвЊРлМгЩЯвЛПщЕФГЄЖШ
result = search(block_data, key) # ЕїгУЖўЗжВщевЕФжЕ
if result != False: # ВщевЕФНсЙћВЛЮЊFalse
return block_i * count + result # ОЭЗЕЛиПщжаЕФЫїв§ЮЛжУ
return False
data = [23, 43, 56, 78, 97, 100, 120, 135, 147, 150, 155] # Ъ§ОнСаБэ
result = block(data, 4, 150) # ЕкЖўИіВЮЪ§ЪЧПщЕФГЄЖШ,зюКѓвЛИіВЮЪ§ЪЧвЊВщевЕФдЊЫи
print("ВщевЕФжЕЕУЫїв§ЮЛжУЪЧ:", result) # ЪфГіНсЙћ
дЫааНсЙћШчЯТЭМЫљЪО:
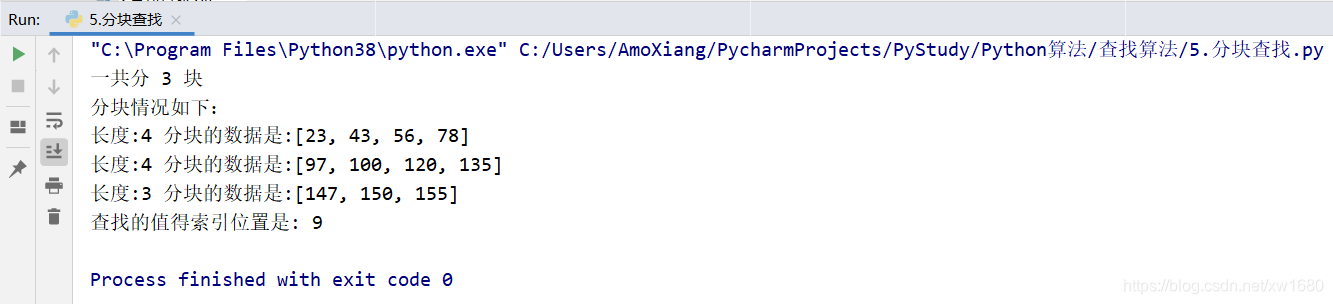
ДгЩЯУцЕФдЫааНсЙћПДЕН,ЕБВщев 150 ЪБ,ВщевНсЙћЭъШЋЗћКЯЩЯЪіУшЪіЕФВНжшЁЃ
ИааЛФњдФЖСБОЦЊВЉЮФ,ЯЃЭћБОЮФФмГЩЮЊФњБрГЬТЗЩЯЕФСьКНепЁЃзЃФњдФЖСгфПь!

????КУЪщВЛбсЖСАйЛи,ЪьЖСПЮЫМзгзджЊЁЃЖјЮвЯывЊГЩЮЊШЋГЁзюіІЕФза,ОЭБиаыМсГжЭЈЙ§бЇЯАРДЛёШЁИќЖржЊЪЖ,гУжЊЪЖИФБфУќдЫ,гУВЉПЭМћжЄГЩГЄ,гУааЖЏжЄУїЮвдкХЌСІЁЃ
????ШчЙћЮвЕФВЉПЭЖдФугаАяжњЁЂШчЙћФуЯВЛЖЮвЕФВЉПЭФкШн,ЧыЕудоЁЂЦРТлЁЂЪеВивЛМќШ§СЌХЖ!Ь§ЫЕЕудоЕФШЫдЫЦјВЛЛсЬЋВю,УПвЛЬьЖМЛсдЊЦјТњТњпЯ!ШчЙћЪЕдквЊАзцЮЕФЛА,ФЧзЃФуПЊаФУПвЛЬь,ЛЖгГЃРДЮвВЉПЭПДПДЁЃ
?БрТыВЛвз,ДѓМвЕФжЇГжОЭЪЧЮвМсГжЯТШЅЕФЖЏСІЁЃЕудоКѓВЛвЊЭќСЫЙизЂЮвХЖ!

ЧАбд зівЛИіаТЕФЯюФПОЭашвЊГЃгУЕФДњТыЃЌБШШч ЕЧТМЃЌзЂВс (ФЃАх) ШЋОжТЗгЩЪиЮРЃЈ...
ЧАбд дкжЎЧАЕФВЉПЭРяЃЌБЪепЯъЯИВћЪіСЫPrometheusЪ§ОнЕФВхШыЙ§ГЬЁЃЕЋЮвУЧзюГЃМћЕФ...
вЛЁЂЮЊКЮШЫЙЄжЧФм(AI)ЪзбЁPythonЃП ЖСЭъетЦЊЮФеТФуОЭжЊЕРСЫЁЃЮвУЧПДЙШИшЕФTensor...
ObjectvieSQLМђНщ ObjectiveSQL ЪЧвЛИіJava ORM ПђМмЃЌЫќВЛНіЪЧActive Record ФЃ...
вЛЁЂPostmanБГОАНщЩм гУЛЇдкПЊЗЂЛђепЕїЪдЭјТчГЬађЛђепЪЧЭјвГB/SФЃЪНЕФГЬађЕФЪБКђ...
Ъ§ОнПтSQLServerЃЌВтЪдГЬађЯдЪОГіДэаХЯЂЃК"ADODB.Recordset ДэЮѓ ЁА800a0e78ЁБ ...
ЩљУїБОЮФжЛзїбЇЯАбаОПНћжЙгУгкЗЧЗЈгУЭОЗёдђКѓЙћздИКШчгаЧжШЈЧыИцжЊЩОГ§аЛаЛ ЮФеТ...
НёЬьРДПДвЛЯТasp.net coreЕФжДааЙмЕРЁЃЯШПДЯТЙйЗНЫЕУїЃК ДгЩЯЭМПЩвдХзЙтЃЌasp.ne...
СЫНтШчКЮдк Bash жаБраДЖЈжЦГЬађвдздЖЏжДаажиИДадВйзїШЮЮёЁЃ Unix зюГѕЕФЯЃЭћжЎ...
ЮФеТФПТМ JavaЛљДЁШыУХбЕСЗ вЛЁЂИљОнФъСфЪ§жЕЪфГіФъСфЖЮ ЖўЁЂДђгЁ1-100ЫиЪ§ Ш§ЁЂ...

