

这里说的正则表达式优化,主要是针对目前常用的NFA模式正则表达式,详细可以参考:正则表达式匹配解析过程探讨分析(正则表达式匹配原理)。从上面例子,我们可以推断出,影响NFA类正则表达式(常见语言:GNU Emacs,Java,ergp,less,more,.NET语言,
PCRE library,Perl,PHP,Python,Ruby,sed,vi )其实主要是它的“回溯”,减少“回溯”次数(减少循环查找同一个字符次数),是提高性能的主要方法。 我们来看个例子:
源字符串:<script type="text/javascript">adsfadfsdasfsdafdsfsadfsa</script>
匹配要求,匹配<script….>….</script>标签里面所有内容,包括改标签
常见写法(1),因为<script后面可能出现字符、空白、特殊符号等,还有标签里面也可能出现各种js代码。我们简单方法是:
正则表达式:<script.*?>.*?</script> (测试工具使用了:regexBuddy)
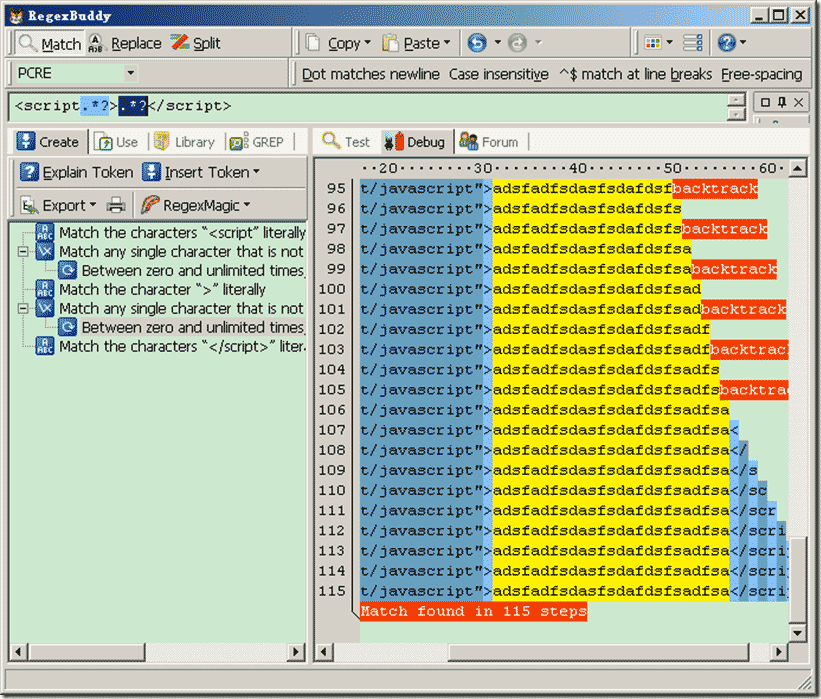
总共花费115步,回溯了:48次。 因为我们使用”.”字符,匹配默认情况下除了\n之外所有字符。
方法(2),我们分析特点发现,<script…>后面,应该是除了”>”之外都可以字符,然后一对<script>标签里面js内容。可以定义为除了”<”之外。(这里面我只是举例说明优化方法,实际网页中script标签里面,常见都会出现有”<”字符了)
正则表达式:<script[^?>]+>[^<]+</script>
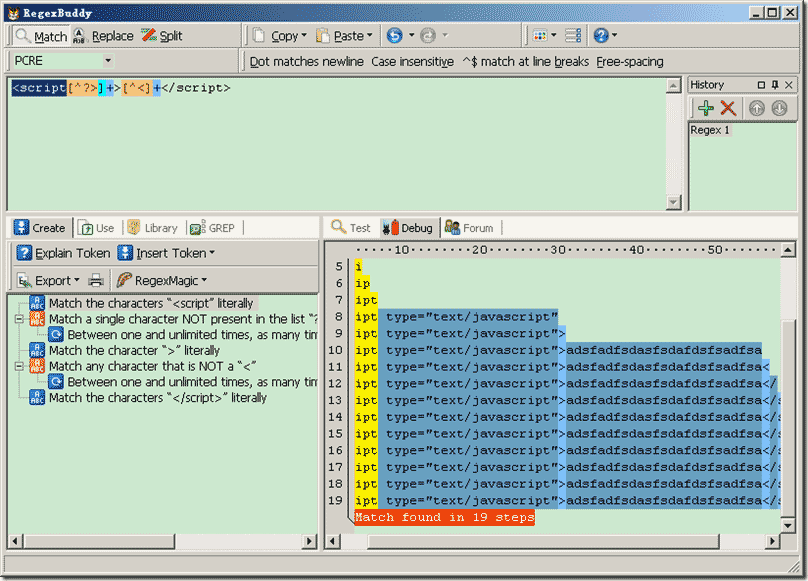
19步,0次回溯! ,步骤只有原先的15%左右,性能几倍的提升了!
从上面我们看到,不同正则表达式,对通用字符配平,性能相差会很大。减少“回溯”是最好的方法,减少回溯其中最主要的方法是:”用最小范围的元字符,尽量避免用过大的元字符!”。一般规律如下:
1、使用正确的边界匹配器(^、$、\b、\B等),限定搜索字符串位置
2、使用具体的元字符、字符类(\d、\w、\s等) ,少用”.”字符
3、使用正确的量词(+、*、?、{n,m}),如果能够限定长度,匹配最佳
4、使用非捕获组、原子组,减少没有必要的字匹配捕获用(?:)
如:我想匹配一些英文字母,它后面接的是数字。如:abc1234,我可以写 “\w+\d+”,也可以写”[a-zA-Z]+\d+” ,其中第一个\w+会先匹配所有abc1234,然后回溯,匹配满足\d+格式。一共4步,而后面这个只需要2步,步骤减少一半了!好了,今天就先到这里,欢迎大家讨论、交流!

1.小程序端代码示例 my.getPhoneNumber({ success: (res) = { let encryptedData...
有许多命令行选手在linux下开发的时候会经常遇到一个问题,无论是svn还是git,提...
vscode怎么浏览器打开html预览?这里大家可以通过安装open in browser插件解决。...
Java HashMap removeNode 方法 分析 源码分析仓库 https://github.com/HANXU2018...
PHP+Mysql简单实现了图书购物车 本文主要讲述如何通过PHP+HTML简单实现图书购物...
mysql提供的模式匹配的其他类型是使用扩展正则表达式。 当你对这类模式进行匹配...
步骤: 1、新建一个空文件,文件名为hhhh 2、初始化 git init 3、自己要与origin...
图片来自 Pexels 突然电话响了起来,一看是我们的一个开发同学,顿时紧张了起来...
官网连接 https://docs.rt-thread.org/#/rt-thread-version/rt-thread-standard/...
1. 始终在 `v-for` 中使用 `:key` 在需要操纵数据时,将key属性与v-for指令一起...

