


本文转载自微信公众号「Java极客技术」,作者鸭血粉丝 。转载本文请联系Java极客技术公众号。
在开始之前,咱们要知道:如果我的 SQL 语句执行的足够快,还有没有必要去做优化?
完全没有必要对吧
所以我们一般说,要给 SQL 做个优化,那肯定就是这条 SQL 语句执行的比较慢了
那么,为什么它会执行比较慢呢?
SQL 语句执行较慢的 3 个原因
没有建立索引,或者索引失效导致了 SQL 语句执行较慢
这个应该是比较好理解的,如果数据比较多,在千万级别以上,然后呢又没有建立索引,在这千万级别的数据中查找你想要的内容,简直就是在肉搏啊(哎呦,可了不得,竟然敢肉搏
索引失效这块内容说起来就比较多了,比如在查询的时候,让 like 通配符在前面了,比如经常念叨的“最左匹配原则”,又比如我们在查询条件中使用 or ,而且 or 前后条件中有一个列没有索引,等等这些情况都会导致索引失效
锁等待
常用的存储引擎主要有 InnoDB 和 MyISAM 这两种了,前者支持行锁和表锁,后者就只支持表锁
如果数据库操作都是基于表锁的话,意思就是说,现在有个更新操作,就会把整张表锁起来,那么查询的操作都不被允许,所以就不要说提高系统的并发性能了
不恰当的 SQL 语句
这个也比较常见了,啥是不恰当的 SQL 语句呢?就比如,明明你需要查找的内容是 name , age ,但是呢,为了省事,直接 select *,或者在 order by 时,后面的条件不是索引字段,这就是不恰当的 SQL 语句
优化 SQL 语句
在知道了 SQL 语句执行比较慢的原因之后,接下来要做的就是对症下药了
针对 没有索引/索引失效 这块,最有效的办法就是 EXPLAIN 语法了,那你知不知道 Show Profile 也可以嘞
针对 锁等待 这块,没办法了,只能自己多注意
针对 不恰当的 SQL 语句 这块,介绍几个常用的 SQL 优化,比如分页查询怎么优化一下可以查询的更快一些呀,你不是说 select * 不是正确的打开方式嘛?那什么是正确的 select 方式呢?别急嘛,阿粉下面都会说到的
废话不多说,咱们开始了
先来个表
为了确保优化后的结果和我写的一样(起码 90% 是相符的
所以咱们用一样的数据库好不好?乖~
首先建个 demo 的数据库
接下来咱们建表,就建个非常简单的表好不好
- CREATE TABLE demo.table(
- id int(11) NOT NULL,
- a int(11) DEFAULT NULL,
- b int(11) DEFAULT NULL,
- PRIMARY KEY(id)
- ) ENGINE = INNODB
然后插入 10 万条数据
- DROP PROCEDURE IF EXISTS demo_insert;
- CREATE PROCEDURE demo_insert()
- BEGIN
- DECLARE i INT;
- SET i = 1;
- WHILE i <= 100000 DO
- INSERT INTO demo.`table` VALUES (i, i, i);
- SET i = i + 1 ;
- END WHILE;
- END;
- CALL demo_insert();
OK ,准备工作做好了,接下来开始实战
通过 EXPLAIN 分析 SQL 是怎样执行的
只要说 SQL 调优,那就离不开 EXPLAIN
- EXPLAIN SELECT * FROMtableWHERE id < 100 ORDER BY a;

咱们能够看到有好几个参数:
如果对这些参数了解的非常不错,那么 EXPLAIN 这块内容就难不住你了
Show Profile 分析下 SQL 执行性能
通过 EXPLAIN 分析执行计划,只能说明 SQL 的外部执行情况,如果想要知道 mysql 具体是如何查询的,需要通过 Show Profile 来分析
可以通过 SHOW PROFILES; 语句来查询最近发送给服务器的 SQL 语句,默认情况下是记录最近已经执行的 15 条记录,如下图我们可以看到:
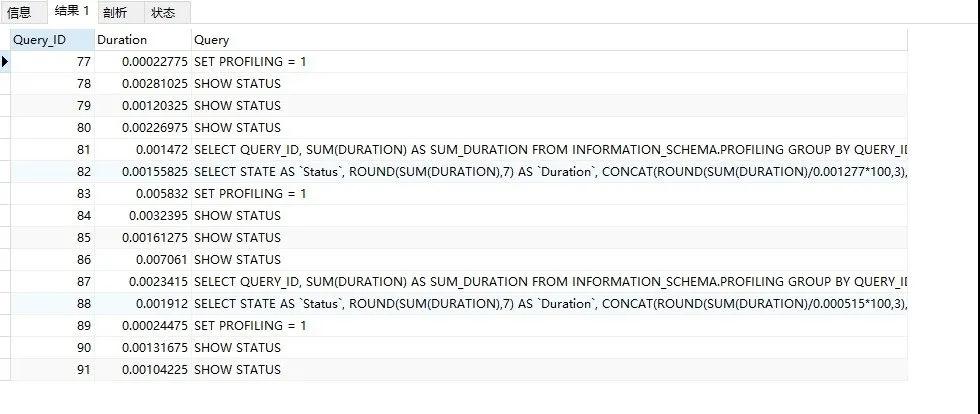
我想看具体的一条语句,看到 Query_ID 了嘛?然后运行下 SHOW PROFILE FOR QUERY 82;这条命令就可以了:
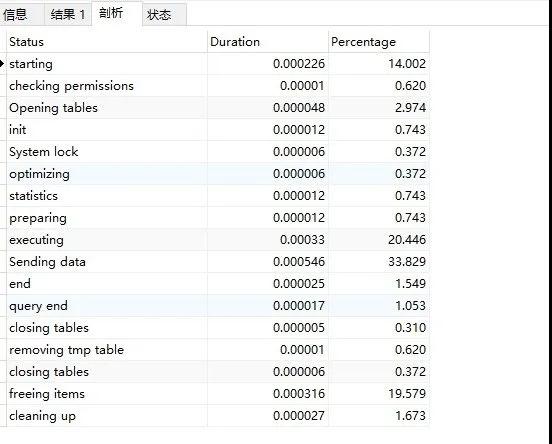
可以看到,在结果中, Sending data 耗时是最长的,这是因为此时 mysql 线程开始读取数据并且把这些数据返回到客户端,在这个过程中会有大量磁盘 I/O 操作
通过这样的分析,我们就能知道, SQL 语句在查询过程中,到底是 磁盘 I/O 影响了查询速度,还是 System lock 影响了查询速度,知道了病症所在,接下来对症下药就容易多了
分页查询怎么可以更快一些在使用分页查询时,都会使用 limit 关键字
但是对于分页查询,其实还可以优化一步
我这里给出的数据库不是太好,因为它太简单了,看不出来有什么区别,我使用目前项目上正在用的表来做个实验,可以看下区别(使用的 SQL 语句如下面):
- EXPLAIN SELECT * FROM `te_paper_record` ORDER BY id LIMIT 10000, 20;
- EXPLAIN SELECT * FROM `te_paper_record` WHERE id >= ( SELECT id FROM `te_paper_record` ORDER BY id LIMIT 10000, 1) LIMIT 20;

上面一张图片,我没有使用子查询,可以看到执行了 0.033s ,下面的查询语句,我使用了子查询去做优化,能够看到执行了 0.007s ,优化的结果还是很显而易见的
那么,为什么使用了子查询,查询的速度就提上来了呢,这是因为当我们没有使用子查询时,查询到的 10020 行数据都返回回来了,接下来要对这 10020 行数据再进行过滤操作
那可不可以直接就返回需要的 20 行数据呢,这样就不需要再做过滤操作了,直接返回就可以了嘛
你也太聪明了吧。子查询就是在做这件事情
所以查询时间上有了一个很大的优化
正确的 select 打开方式
在查询时,有时为了省事,直接使用 select * from table where id = 1 这样的 SQL 语句,但是这样的写法在一些环境下是会存在一定的性能损耗的
所以最好的 select 查询就是,需要什么字段就查询什么字段
一般在查询时,都会有条件,按照条件查找
这个时候正确的 select 打开方式是什么呢?
如果可以通过主键索引的话, where 后面的条件,优先选择主键索引
为什么呢?这就要知道 MySQL 的存储规则
MySQL 常用的存储引擎有 MyISAM 和 InnoDB , InnoDB 会创建主键索引,而主键索引属于聚簇索引,也就是在存储数据时,索引是基于 B+ 树构成的,具体的行数据则存储在叶子节点
也就是说,如果是通过主键索引查询的,会直接搜索 B+ 树,从而查询到数据
如果不是通过主键索引查询的,需要先搜索索引树,得到在 B+ 树上的值,再到 B+ 树上搜索符合条件的数据,这个过程就是“回表”
很显然,回表能够产生时间。
这也是为什么建议, where 后面的条件,优先选择主键索引
其他调优
看完上面的,心里应该就大概有数了, SQL 调优主要就是建立索引/防止产生锁等待/使用恰当的 SQL 语句去查询
但是,如果问你除了索引,除了上面这些手段,还有没有其他调优方式
啥?竟然还有?!
有的,这就需要跳出来,不要局限在具体的 SQL 语句上了,需要在数据库设计之初就考虑好
比如说,我们常说的要遵循三范式,但是在有的业务场景里面,如果在数据库里面多几个冗余字段的话,可能要比严格遵循三范式带来的性能要好很多。
但是这点就及其考验平时的积累了,阿粉在这里把这一点提出来之后,希望读者们可以看看自己项目上目前用的数据库有没有多余的字段,为什么要这样设计呢?这样多去观察,你的技术能力想不提高都很难
以上,就这样啦~

目录 读者基础 ?微服务架构梳理 https://www.coder4.com/homs_online/ ? ? 读者...
由于固态驱动器(SSD)的速度比传统的硬盘驱动器(HDD)快得多,并且价格越来越便宜...
首先到这里下载其源码。里面东西挺多的,我们基本上可以把它放到两个文件夹就是...
本文实例为大家分享了javascript实现倒计时提示框的具体代码,供大家参考,具体...
本文实例为大家分享了vue实现按钮切换图片的具体代码,供大家参考,具体内容如下...
目录 1. C语言文件接口(库函数) 1.1 fopen 1.2 fclose 1.3 fread 1.4 fwrite 1.5...
这5个PHP编程中的不良习惯,一定要改掉 PHP世界上最好的语言! 测试循环前数组是...
今天看到个不错的网页播放器,感觉不错,大家可以测试 我写的一个播放器网页: ...
MFC项目在vs2017编译正常无报错,但是升级vs2019后一打开项目就报如下错误。 项...
在大三的时候,一直就想搭建属于自己的一个博客,但由于各种原因,最终都不了了...

