

在终端输入hadoop fs或者hdfs dfs可以查看所有的命令:
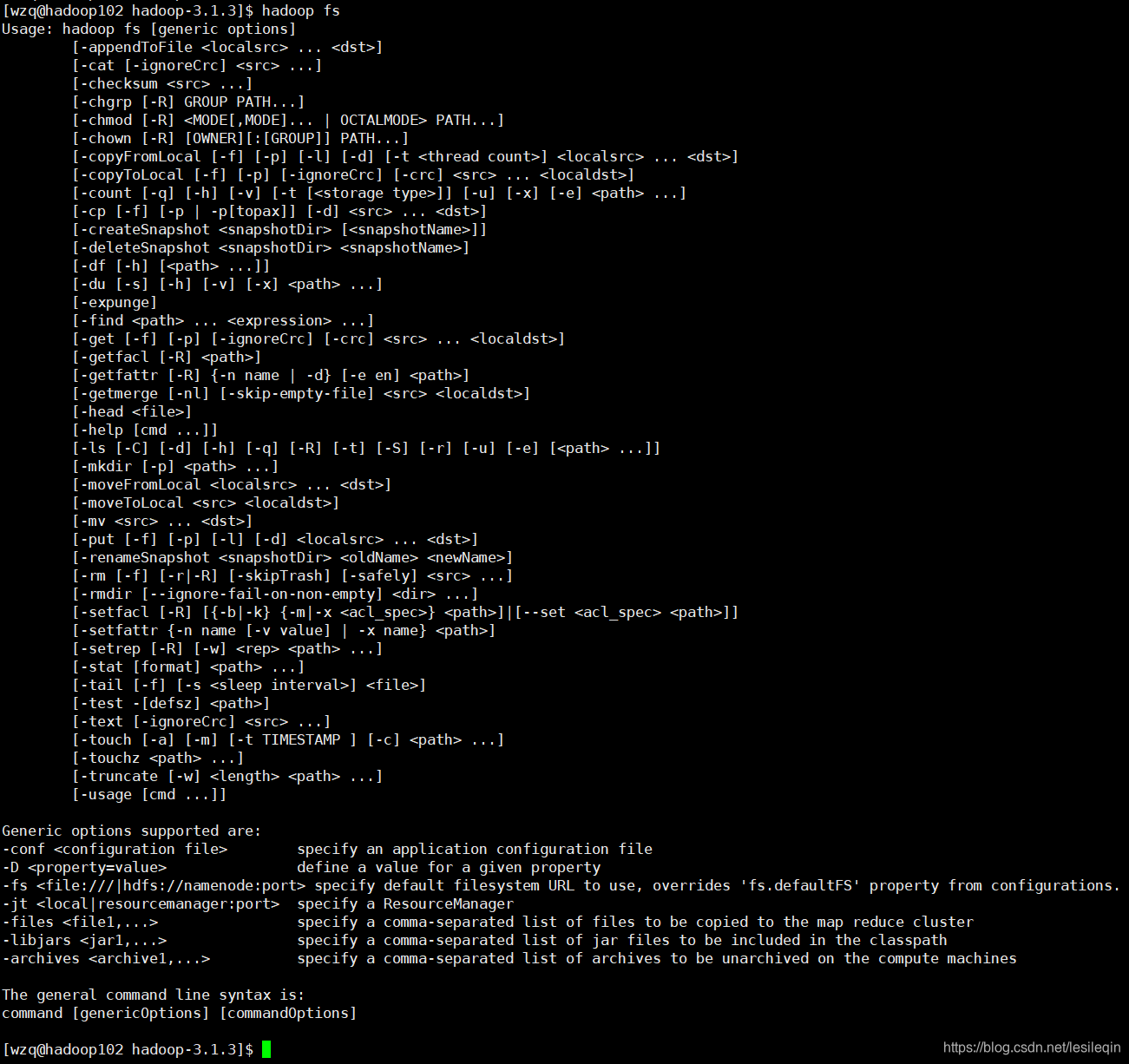
如果想要知道某个命令具体是怎么用的,可以使用-help输出这个命令参数
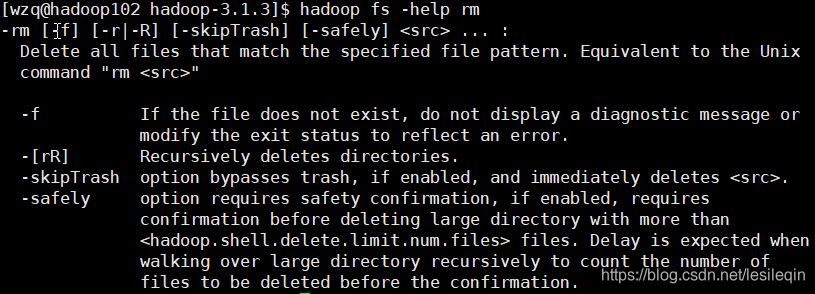
比如:
hadoop fs -help rm
输出的内容有:该命令的解释以及可以追加的参数
hadoop fs -mkdir /sanguo

vim shuguo.txt
# 在该文件中输入:shuguo
# 剪切粘贴到HDFS
hadoop fs -moveFromLocal ./shuguo.txt /sanguo
-copyFromLocal等同于-put,在生产环境中更多使用-put
vim weiguo.txt
# 在该文件中输入:weiguo
# 复制到HDFS
hadoop fs -copyFromLocal weiguo.txt /sanguo
# 或
hadoop fs -put weiguo.txt /sanguo

vim liubei.txt
# 在该文件中输入:liubei
# 执行追加
hadoop fs -appentToFile liubei.txt /sanguo/shuguo.txt
在这里踩个坑,执行插入命令之后如果报以下错误:
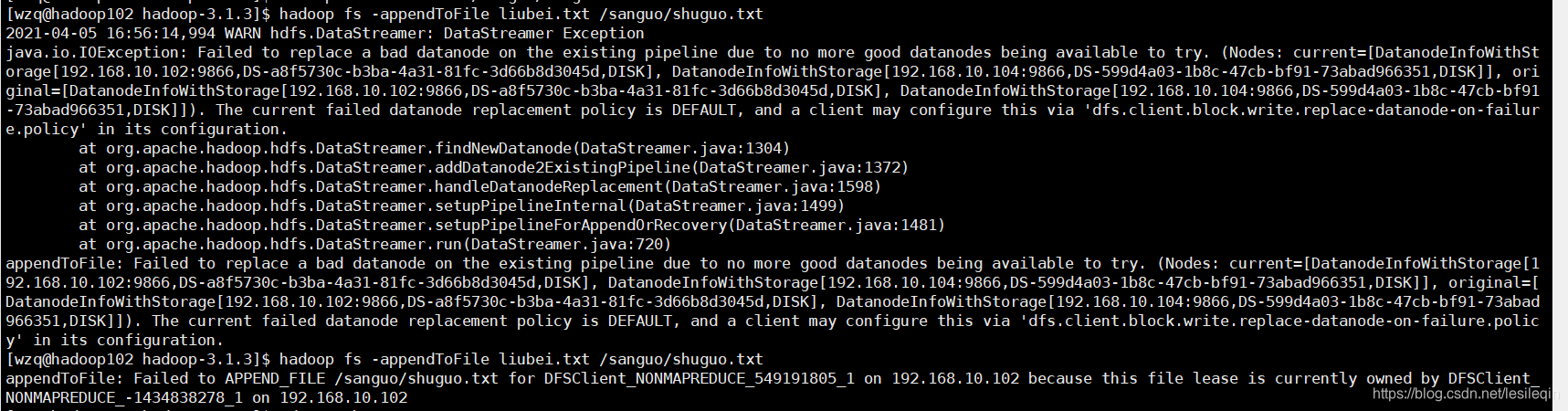
需要在hadoop3.1.3/etc/hadoop/hdfs-site.xml中插入以下配置:
<!--解决Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being availa 异常 -->
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
<value>NEVER</value>
</property>
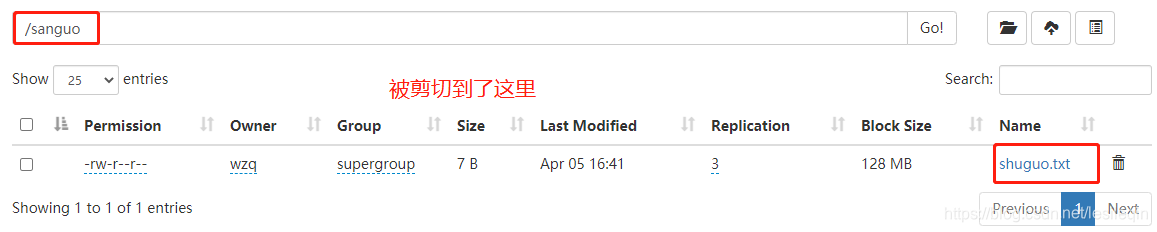
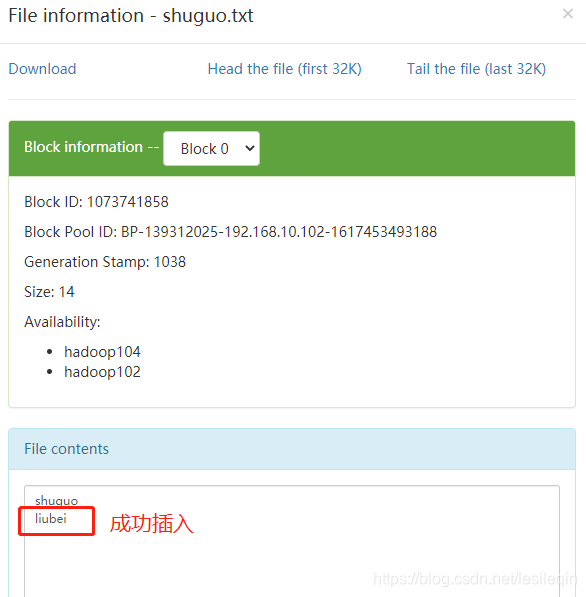
然后分发配置,重启hdfs,再次执行上面的命令,到hdfs中查看效果:
-copyToLocal等同于-get,在生产环境中更多使用-get
# 从hdfs中下载shuguo.txt,在此命令中还可以更改文件名
hadoop fs -copyToLocal /sanguo/shuguo.txt ./shuguo1.txt
# 或者使用get
hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txx

hadoop fs -ls /sanguo

hadoop fs -cat /sanguo/shuguo.txt

# 更改文件权限
hadoop fs -chmod 777 /sanguo/shuguo.txt
# 更改文件的拥有者
hadoop fs -chown wzq:wzq /sanguo/shuguo.txt

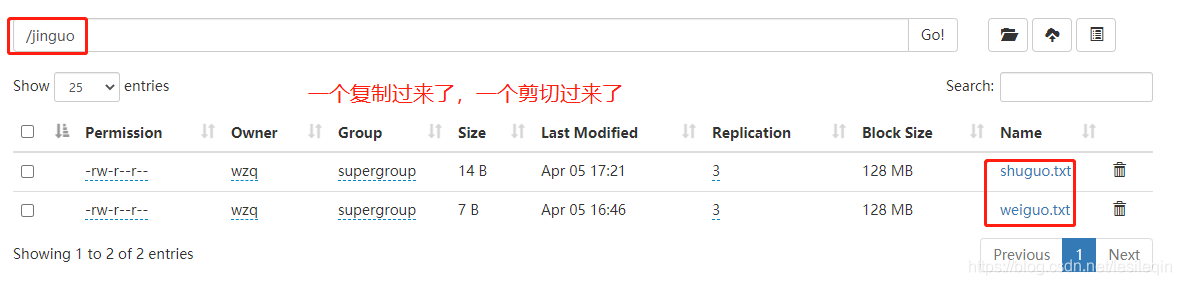
# 在hdfs根目录下创建文件夹jinguo
hadoop fs -mkdir jinguo
# 把/sanguo/shuguo.txt复制到/jinguo
hadoop fs -cp /sanguo/shuguo.txt /jinguo
# 把/sanguo/weiguo.txt移动到/jinguo
hadoop fs -mv /sanguo/weiguo.txt /jinguo

hadoop fs -tail /jinguo/shuguo.txt

# 删除/sanguo/shuguo.txt
hadoop fs -rm /sanguo/shuguo.txt
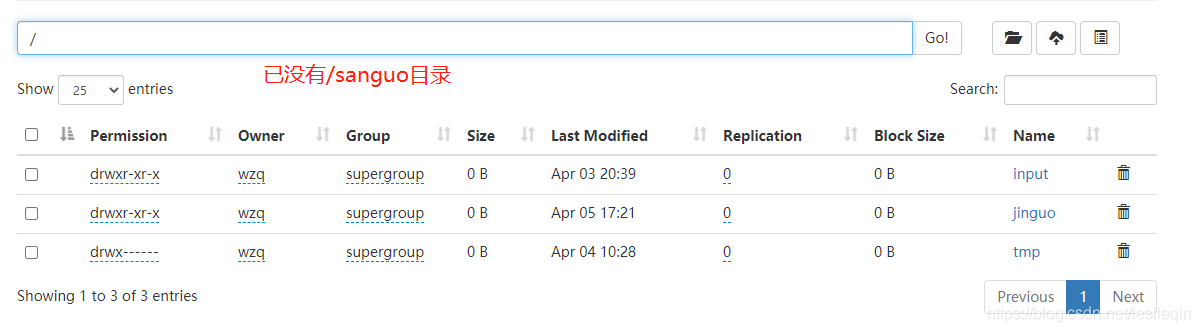
# 递归删除/sanguo目录下所有内容
hadoop fs -rm -r /sanguo
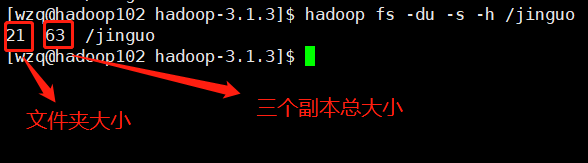
显示整个文件夹大小信息:
hadoop fs -du -s -h /jinguo
显示文件夹里的内容大小信息:
hadoop fs -du -h /jinguo

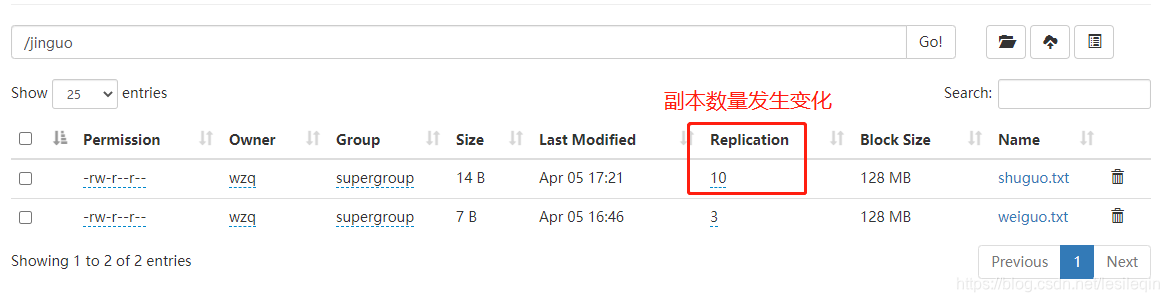
hadoop fs -setrep 10 /jinguo/shuguo.txt

在大三的时候,一直就想搭建属于自己的一个博客,但由于各种原因,最终都不了了...
目录 1. C语言文件接口(库函数) 1.1 fopen 1.2 fclose 1.3 fread 1.4 fwrite 1.5...
首先到这里下载其源码。里面东西挺多的,我们基本上可以把它放到两个文件夹就是...
本文实例为大家分享了vue实现按钮切换图片的具体代码,供大家参考,具体内容如下...
这5个PHP编程中的不良习惯,一定要改掉 PHP世界上最好的语言! 测试循环前数组是...
MFC项目在vs2017编译正常无报错,但是升级vs2019后一打开项目就报如下错误。 项...
目录 读者基础 ?微服务架构梳理 https://www.coder4.com/homs_online/ ? ? 读者...
今天看到个不错的网页播放器,感觉不错,大家可以测试 我写的一个播放器网页: ...
由于固态驱动器(SSD)的速度比传统的硬盘驱动器(HDD)快得多,并且价格越来越便宜...
本文实例为大家分享了javascript实现倒计时提示框的具体代码,供大家参考,具体...

