

URL是Uniform Resource Locator的简称,是Internet上用于指定数据位置的表示方法。这些数据可以是图像、文件、视频、音频、超链接等。可以认为URL是数据在Internet上的存取路径,一个URL对应一个数据资源。例如:链家网的一个URL是https://sh.lianjia.com/ershoufang/107103462926.html,用浏览器的HTTP协议发送后从Internet上获得响应如图所示,也就是打开了网页。

可以看到这个URL指向的是一个HTML文件。HTML全称是HyperText Markup Language,中文叫超文本标记语言,是一种标记网页上各种数据位置的描述语言,上述链家URL的HTML文件如图所示。可以看到网页上各种数据的位置都放在了标签对(即尖括号)中。

有时发送的URL请求,也可能获得如图所示的出错响应。

常见的URL请求响应状态如表所示,响应除了有HTML文件外,还会有JSON数据、二进制数据等。

网络爬虫爬取的对象就是网页数据,根据方式的不同网页数据可以分为三种:
所谓解析网页就是从网页服务器返回的信息中提取想要数据的过程。常见的方式是使用正则表达式或者一些第三方开发正则表达式软件库,例如lxml、BeauifulSoup、requests-html等。这里使用名为lxml(https://lxml.de/)的正则表达式相关软件库中的XPath方式进行网页解析。XPath中有些特殊用途的表达式说明如表所示。

安装URL解析包Palladian,安装手册在这里。Palladian包的全名为Palladian for KNIME (2.4.1.202103282119 Version)。

在Table Creator节点中设置初始的URL,例如斗鱼。并双击列头,命名为url。

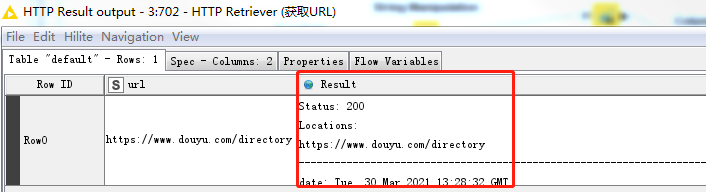
在HTTP Retriever节点中获取URL,通过右击HTTP Result Output进行查看。
用HTML Parser节点进行语法分析,转换为XML格式。

在XPath节点中设置如下,解析出游戏主页网址(href)和游戏名称(title),在XML文件的489行附近。


结果显示为

使用Column Filter节点只保留游戏主页网址(href)和游戏名称(title)列。

使用Regex Split节点用正则表达式获取游戏名称的缩写,例如英雄联盟的缩写为LOL。

执行后,有一个WARN:1 input string(s) did not match the pattern or contained more groups than expected,问:为什么?怎么解决?
使用Row Filter过滤不需要分析的游戏名称,只保留需要数据分析的游戏名称,例如LOL

使用Table Creator节点,设置爬取的斗鱼聊天室的网页数,并且命名列变量名为pages。

使用Constant Value Column节点设置斗鱼聊天室URL,注意其中的pages就是Table Creator节点中命名的变量。并且将聊天室的URL以roomURL的变量名追加到数据集中。

使用String Mnipulation节点将Pages和roomURL两个变量拼接起来。

输出结果如下:

使用Cross Joiner节点,将步骤8和步骤11的2个输出结果交叉式地拼接起来,执行后结果如下。

使用String Manipulation节点将roomURL(聊天室URL)和split_0(游戏名称缩写)连接起来。

执行后的结果如下:

使用GET Request对获取的10页(Pages)游戏聊天内容进行爬取。

并在Request Headers页设置User-Agent为Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36,以模拟浏览器(如Chrome)访问网站。

执行后GET Request节点,可以查看爬取的数据。

使用Column To XML节点,将{JSON}body列转换为XML类型的列。

使用JSON Path节点,解析出聊天室编号roomID、聊天室名称roomNames、在线人数hotSpots、主播网名nickNames。

执行后的结果为:

使用Ungroup节点将组合的数据分解开。

执行后的结果为:

使用Excel Writer节点保存数据。完!

JSP 开发之Servlet解决网页缓存问题 (1)我们为什么要防止游览器页面缓存的问题...
SQL在使用过程中,经常会遇到一些奇奇怪怪的小问题,今天给大家总结一下常见的几...
本文转载自微信公众号「三太子敖丙」,作者三太子敖丙。转载本文请联系三太子敖...
如果没有恢复场景,备份就失去了业务价值,毕竟单纯靠业务价值一把尺子就衡量系...
1 Android屏幕适配相关概念 1.1 屏幕尺寸(Screen Size) 屏幕尺寸是屏幕的对角线...
github是一个项目的存储仓库,使用的时候非常的方便,下面就介绍一下管理 github...
最近与同行交流,经常被问到分库分表与分布式数据库如何选择。 图片来自 Pexels ...
这5个PHP编程中的不良习惯,一定要改掉 PHP世界上最好的语言! 测试循环前数组是...
比如CUTEEDITOR,虽 然功能比FCKEDITOR还要强大,可是,它本身也够庞大了,至于FREET...
我司是一家正处于高速发展,目前拥有数百万用户,年销售额近五十亿的社交电商公...

