

--------本文一半翻译,一半自己总结,翻译(翻译连接)了错了水平太差,总结错了不要信。
ZooKeeper是一个文件一致性系统基础上的特殊 filesystem/trigger API 。Kafka是 一致性文件系统上的pub / sub API, 这导致系统的人员去调优、配置、监视、保护和判断 通信和新能 在两个日志实现、两个网络层和两个安全实现(并且每个都有不同的 distinct tools and monitoring hooks),这都是一些不必要复杂度。这些固有的并且不必要的负责度,加速了kafka的改革,在即将发行的2.8版本Kafka 决定用内部的 quorum service来替代zookeeper 和 controller 的工作。
因此我们第一次使用到没有zookeeper 的kafka集群,把它叫做 Kafka Raft Metadata mode, 简称为 KRaft(pronounced like craft) mode
注:有些功能在此抢先体验版本中不可用。尚不支持使用ACL和其他安全功能或交易。同样,在KRaft模式下不支持分区重新分配和JBOD.
Kafka 新的仲裁机制 将之前放在 Zookeeper 和 Controller 的metadata 信息 合并放在了 quorum service 之中。Kafka集群再没有了对外的依赖,所有的组件完全运行在自己的集群之中。
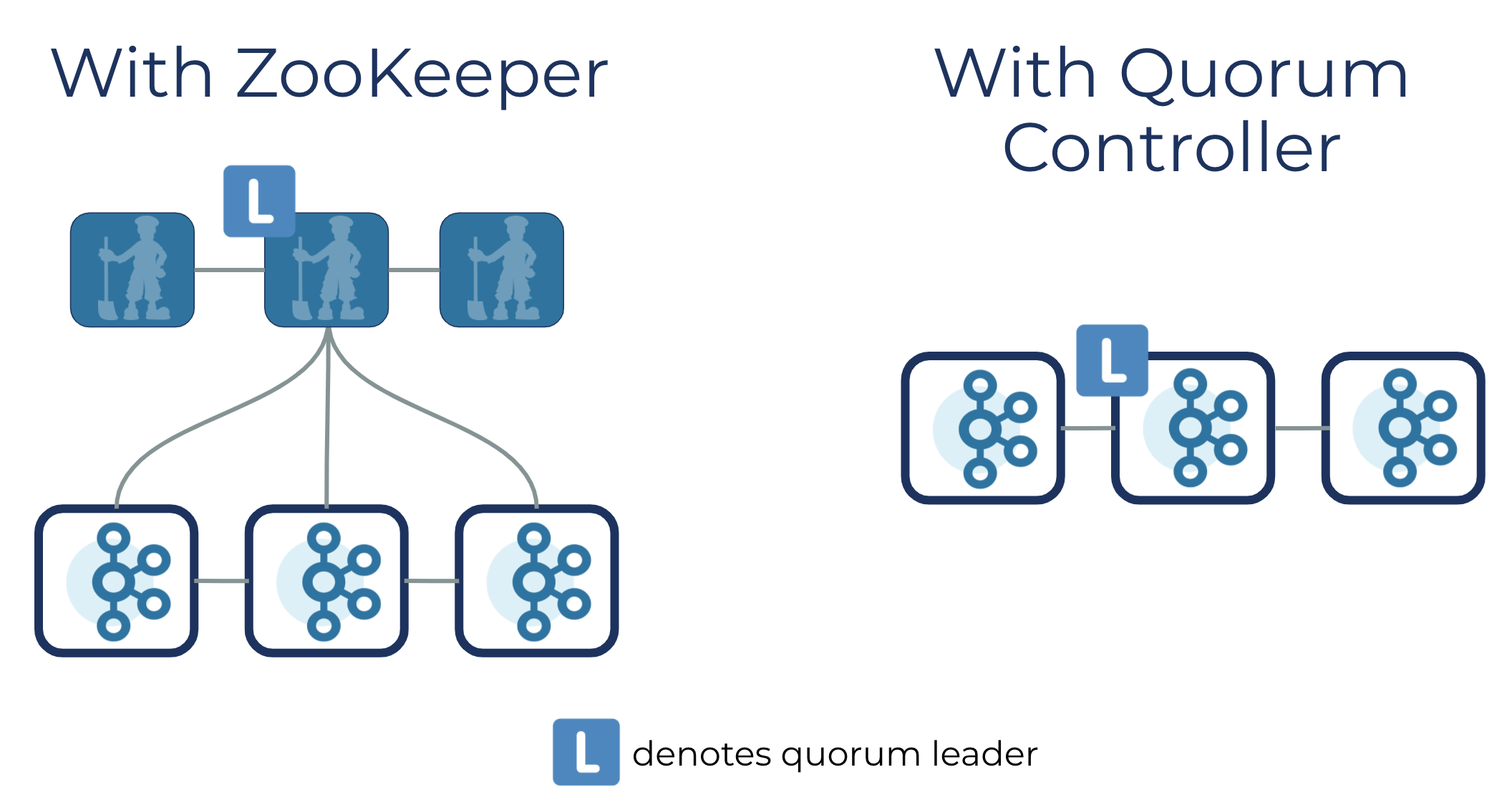
可以详细的对比一下早些版本的Kafka集群架构,过去必须要在Kafka 集群的元数据必须要在外部Zookeeper 集群和内部Controller 之间进行流动,使得Kafka集群的搭建有着非常沉重的基础设施。整个元数据的交互都要通过Kafka协议进行交互(也就是RPC)。

改为如下所示事件驱动的共识机制进行管理元数据的方式,通过完全的inside 事情开始变得有趣起来,Kafka使用了新的协议 KRaft,来存储和确保元数据在集群当中能够精确的进行复制。
KRaft协议和Zookepeer 的ZAB协议、Raft协议非常相似。但是也有着自己的特殊的地方就是有着一套基于事件驱动的体系结构。
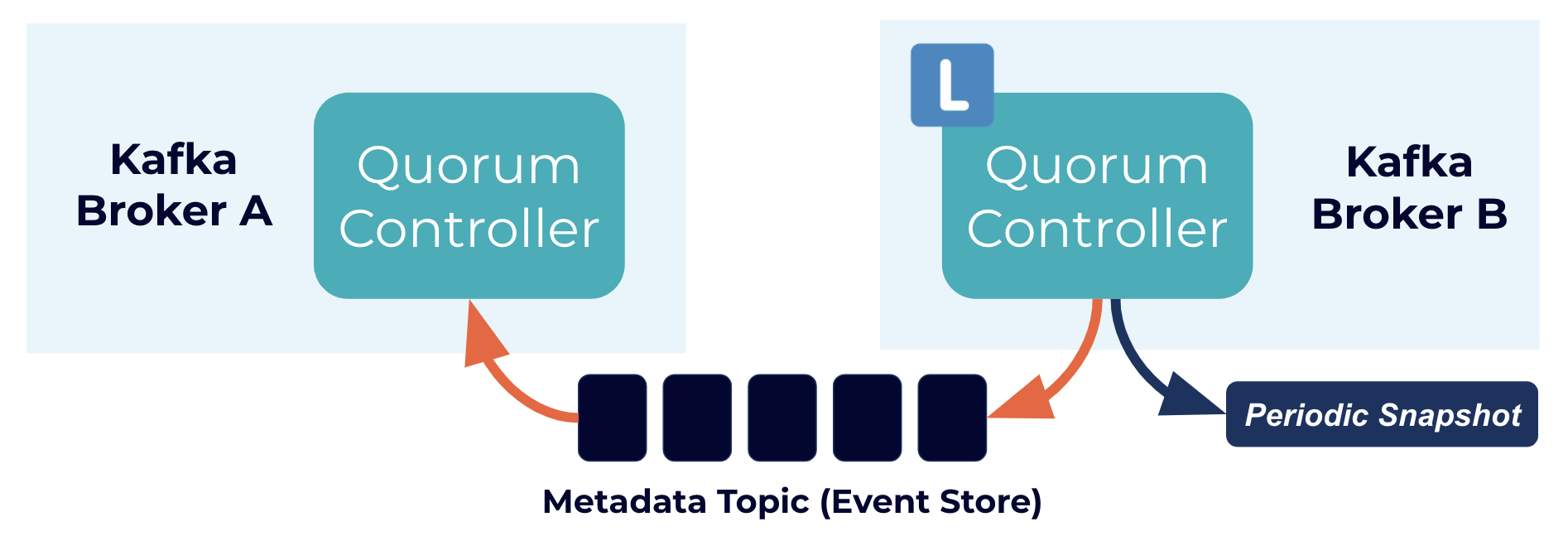
quorum controller 使用的是一种 event-sourced 的存储模式,该模式可以精准的去创建内部状态机。
kafka使用一个Metadata Topic (Event Store)来此存储这些 state。snapshots会定期的去清理这些state,确保数据不会无限的增长。
所有的节点中都会有quorum controller ,但是一个集群中会存在一个 active controller,其他的控制器通过 active controller 存储的log来响应对应的事件。这样的话,如果一个controller 因为一个分区事件而停止,当他重新加入集群的时候可以通过访问日志能够快速的赶上它错过的任何事件,这样显著的减少了不可用的事件窗口,缩短了系统最坏情况下的访问时间。
quorum controller机制,重新启动而时候不再需要通过controller通过zookeeper 来加载数据,当leader变更的时候,新的active controller 已经获取了所有的已经提交了存储在内存中的的元数据信息。此外在KRaft协议中使用了相同的事件驱动机制来跟踪整个集群的元数据信息,用了事件驱动的方式和使用实际的log来进行通信的方式来替换RPC进行处理任务。使得Kafka的单个集群可以支持更多的分区。
使用Zookeeper 的Kafka集群可以支持 20万个分区,使用了quorum的Kafka集群可以支持到200万个分区左右,是之前的数十倍之多。
一个Kafka集群的分区数主要有两个属性确定:
Kafka曾经尽力的优化了单个节点的分区数(但是这不是真正的瓶颈所在),kafka本身就是一个高可扩展的应用,通过增加新的broker来增加整个系统的容量。这点很重要,正是它的扩展性来决定了系统的上线,然而现在Kakfa的高扩展性却收到了元数据管理的限制,因素就是如果集群很大的话,Zookeeper 和 Kafka Controller 之间所花费的时间非常长。而quorum controller,通过完全的inside和事件驱动的方式完美的解决了这个问题,元数据的转移现在完全都是瞬时的操作,不会影响到系统的性能,和扩展性。
性能对比:

| With ZooKeeper-Based Controller | With Quorum Controller | |
|---|---|---|
| Controlled Shutdown Time(2 million partitions) | 135 sec. | 32 sec. |
| Recovery from Uncontrolled Shutdown (2 million partitions) | 503 sec. | 37 sec. |
这两个指标都非常重要。
Controlled Shutdown Time(受控制的关机):滚动重启:我们的软件在重新部署中始终保持可用性的一个标准。
Recovery from Uncontrolled Shutdown (从不受控制的shutdown中恢复):这个指标可能更重要,因为它决定了系统的RTO(系统的恢复时间)
zk时代的kafka被普遍认为是一个重量级的应用,因为我们不仅仅要管理Kakf集群,还要去管理Zookeeper集群。这往往会造成系统在刚开始使用的时候去选择ActiveMQ 和 RabbitMQ等消息钟家中间件,并在具备一定的规模的时候才会迁移到Kafka集群。
不好意思,Kafka也轻量级了。您俩改怎么办呢----------------------------
现在完全可以很轻巧的去使用Kafka了,不管你是自己练习还是商用,都可以从小规模开始然后慢慢的往大规模中去发展,都是使用相同的基础结构,非常方便(下载安装包,简单修改配置启动即可,脚本操作再也不需要 --zookeeper-list的这个操作了,仅仅执行一个broker的信息即可)。

首先插件配备好了,写一个HTML测试一下 首先创建一个文件夹,创建一个HTML 文件...
IT之家2月18日消息外媒 Windows Latest 报道,微软正在与谷歌合作进行一项新的改...
2 月 18 日消息 据外媒 Windowslatest 报道,在预览版本中发现的参考资料表明,...
一.前言 .NET Core 是一个通用开发平台,由 Microsoft 和 GitHub 上的 .NET 社区...
第一课趣味二进制——修改植物大战僵尸数据 任务介绍 学习目标 知识需求 需求工...
JSP spring boot / cloud 使用filter防止XSS 一.前言 XSS(跨站脚本攻击) 跨站脚...
在项目开始之前我们可以先去了解一下IConfiguration接口,.Net Core Web应用程序...
1.ajax跨域传递值是所需要的回传的类型为jsonp $.ajax({url: "http://.......",t...
文章目录 前言 本周最重要的五件事情 本周搞砸的四件事情 本周的四个启发 前言 ...
昨天刚学了html的一些内容,就迫不及待的想做个京东上面的搜索条,结果做是做出...

