

上图已魔法反爬,哈哈哈,想爬就爬呗,不拦着。
本系列会写一些什么内容,在开头那张思维导图里面写了个大概了,至于导图里面没有写出来的,就作为一些探索的内容吧。
我之前有写过一个Python爬虫自学系列,反响也还可以,不过那个系列里面的不少链接是另一个付费专栏里面的内容了,相对要阅读就有些困难。
这个系列是在原有知识点的基础上,加入一些新的知识点,重新写的一个系列。不出意外,这个系列将会是我在Python爬虫领域的最后一个教学系列。
这个系列是会有配套视频课的,将会发布在CSDN学院上,当然,如果还是喜欢看博文的朋友可以看我的这个系列。
由于参加了CSDN的“蓄力计划”,诸多条条框框,总结一下就是为读者服务,所以这个系列会写的很认真,毕竟我想上榜啊,大家多多支持。
有Python基本语法基础的人,分支循环、函数、类、模块、异常处理等。
不喜欢枯燥乏味的填鸭式教育的朋友。
肯动手实操为最佳。
说到解析网页,那么我们是不是要自己先了解一下这些个网页呢?
来看一下这个网页:
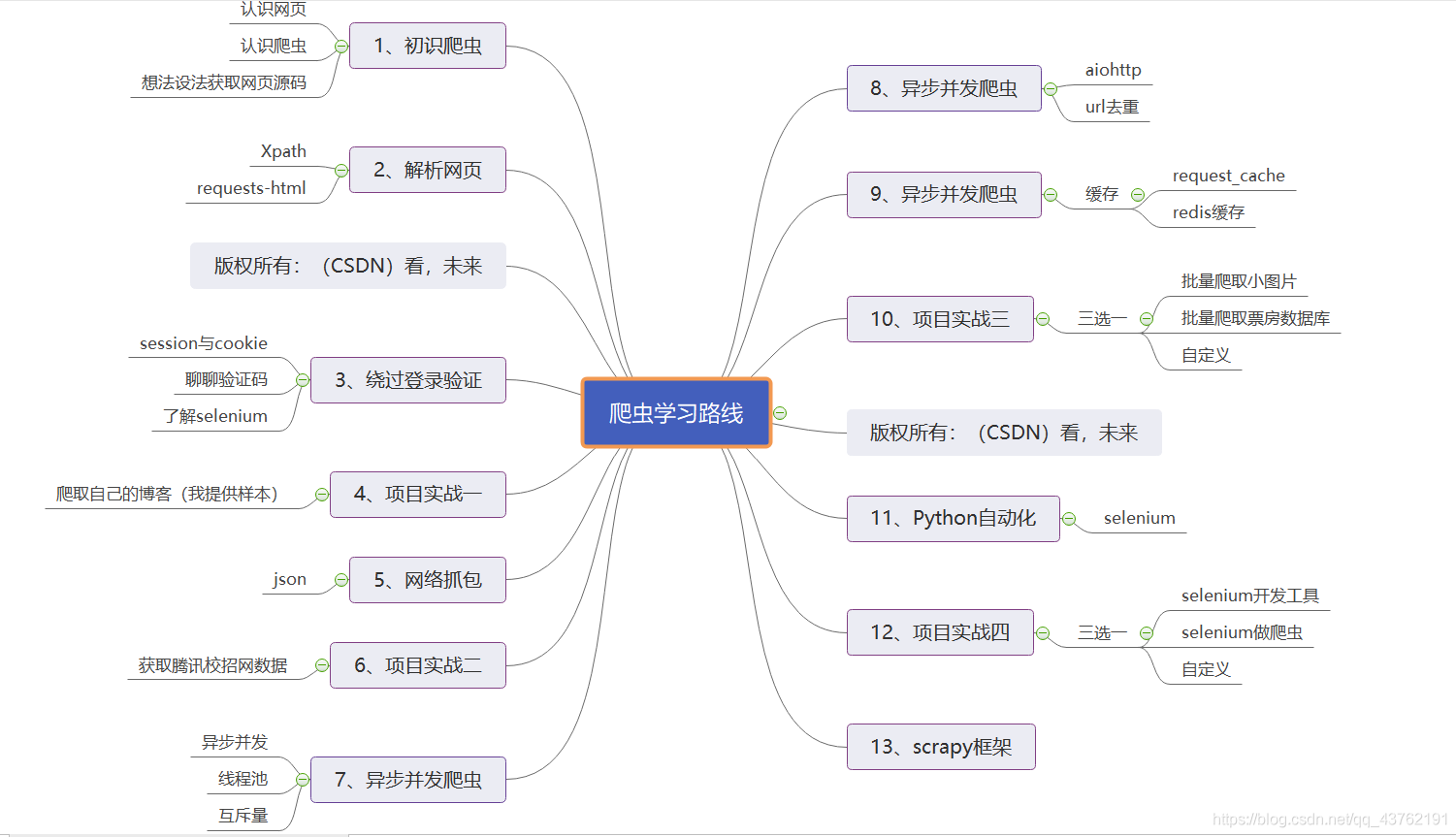
来,我们就拿这个网页来研究一下它的构造,后面其他的网页都是共通的。
首先可以看到在网页的左侧,输入框有颜色。在网页的右侧,也有一段有颜色的代码,这是怎么肥四呢?
这叫做标记,或者叫搜索,或者叫映射,爱怎么叫怎么叫,咱只需要知道左右两个有颜色的地方是一一对应的。
那,要怎么根据页面元素去搜索它对应的代码块儿呢,其实不难哈。
先点击我圈出来的地方,再到网页上点击对应的元素即可。
我们再把目光聚焦在右侧的代码上,可以看到很多的三角形。稍微思索一下,就知道那些三角形是上下级的关系吧。

这些三角形是可以伸缩的。我们把每个三角形以及它包含的所有内容叫做:标签。
(当然,有些没有三角形的也叫标签,比方说)

怎么看标签呢,以"<“为标签的起始,”>"为标签的结尾。
这时候就会有同级标签和上下级标签的区分了,我习惯把它们之间的关系称呼为:父标签、子标签、兄弟标签以及祖标签。
这些概念在后面讲Xpath标签提取的时候会很重要,都长点记性哈。
XPath 是一种将 XML 文档的层次结构描述为关系的方式。因为 HTML 是 由 XML 元素组成的,因此我们可以使用 XPath 从 HTML 文档中定位和选择元素。
要说从网页源码中提取出数据来,那方法其实不少的。比方说某些人动不动就上来一个正则表达式啊,本系列主干中不提正则表达式,最多作为“番外篇”加入。怎么简单怎么来嘛。
也有些人会用beautifulsoup,我初学的时候也是学这个库的,后来发现有诸多的不便性,于是果断放弃了。
其实也没多少不便,就是学完Xpath之后怎么看soup怎么不顺眼。
来看一下它们仨儿的性能对比哈:
| 抓取方法 | 性能 | 使用难度 | 安装难度 |
|---|---|---|---|
| 正则 | 快 | 困难 | 内置模块 |
| beautifulsoup | 慢 | 简单 | 简单(纯Python) |
| lxml | 快 | 简单 | 不难 |
可以看出beautiful为什么慢了吧。在pycharm下,没有太多的安装困难啦。
看完Xpath的性能优势之后,我们来看一下Xpath是如何解析一个网页,并获取到我们所需要的数据的。

别急,我来解释一下这张图。
1、首先,导入Xpath支持的模块,位于lxml包里面的etree模块,如果用pycharm时出现“报错”,别管它,能运行的,历史遗留原因。
2、其次,获取网页源码,这里需要使用content方法来对获取到的网页数据进行转换,不能使用text。
3、接着,对转换出的数据进行编解码。不然会看到一堆的乱码。
4、HTML方法,没什么好说的。
5、xpath方法,这里需要传入参数为待提取标签的Xpath路径。关于这个路径,一会儿会讲。
6、批量提取,关于这个批量提取,一会儿也会讲。
7、没什么好说的了。
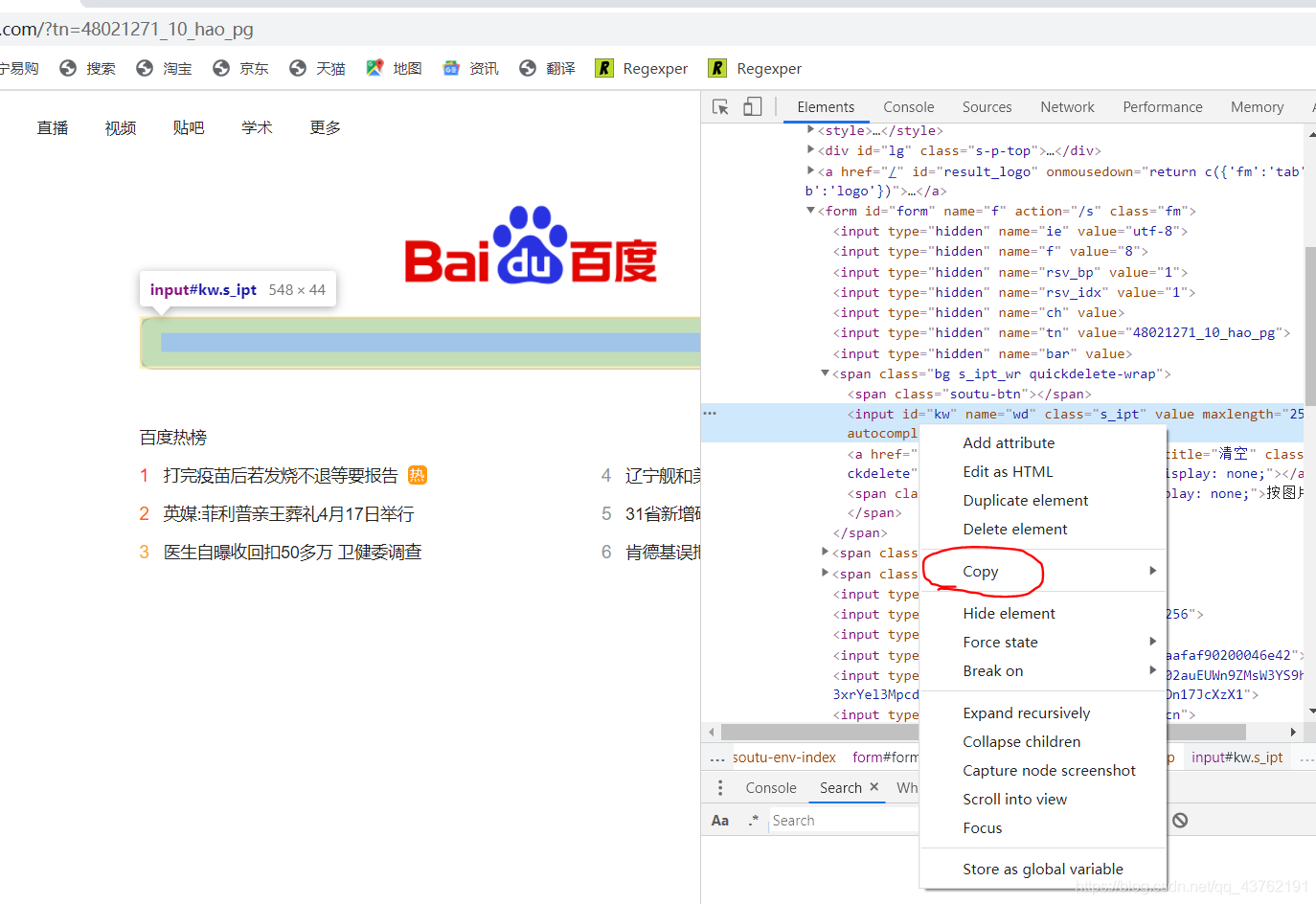
打开谷歌浏览器,在标签上方,进行一次右击,点击那个“copy”,选择里面的“Copy Xpath”,没啥事儿的话就不要去“Copy Full Xpath”了。
这里我们统一使用谷歌浏览器。
这时候相对Xpath路径我们就拿到了。
Xpath的语法太多了,但是我们一般用不到那么多,没必要死记硬背,我给你们挑一些常用的就好。
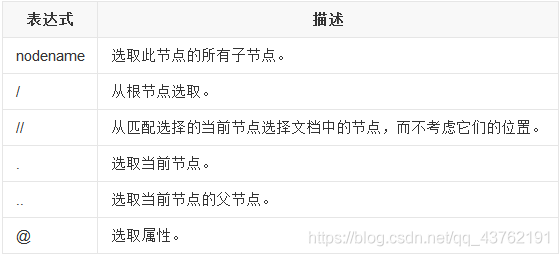
示例:


还有一个text()方法注意一下即可,没必要搞那么多的花里胡哨的。
讲到这里Xpath部分也差不多了,我们来封装一下函数,并做一个小demo。
如果是要提取单个路径下的标签,采用以下方法即可:
def get_data(html_data,Xpath_path):
'''
这是一个从网页源数据中抓取所需数据的函数
:param html_data:网页源数据 (单条数据)
:param Xpath_path: Xpath寻址方法
:return: 存储结果的列表
'''
data = html_data.content
data = data.decode().replace("<!--", "").replace("-->", "") #删除数据中的注释
tree = etree.HTML(data) #创建element对象
el_list = tree.xpath(Xpath_path)
return el_list
如果是要从多个Xpath中提取数据,可以采用以下方法:
def get_many_data(html_data,Xpath_path_list):
'''
通过多个Xpath对数据进行提取
:param html_data: 原始网页数据
:param Xpath_paths: Xpath寻址列表
:return: 二维列表,一种寻址数据一个列表
'''
el_data = []
data = html_data.content
data = data.decode().replace("<!--", "").replace("-->", "")
tree = etree.HTML(data)
for Xpath_path in Xpath_path_list:
el_list = tree.xpath(Xpath_path)
el_data.append(el_list)
el_list = [] #安全起见就自己清理了吧
return el_data
至于要不要修修补补,就看个人喜好啦。
我们来做一个小demo,获取

这里的热榜文本和网址,并一一配对吧。
首先,我们审查以下网页:
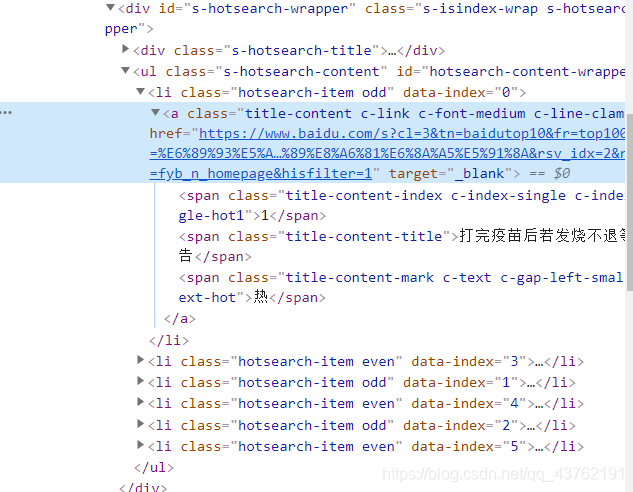
学的快的人看出两个线索,有经验的人看出三个线索:
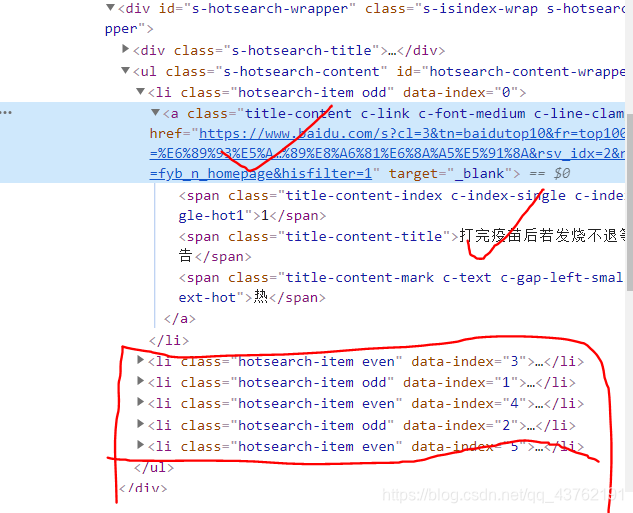
看到网址和文本是应该的,不过我们要一次性全部拿下,就需要查看其它的几个标签所在位置,然后,找到我们所需要的所有标签的最小公共祖宗标签。
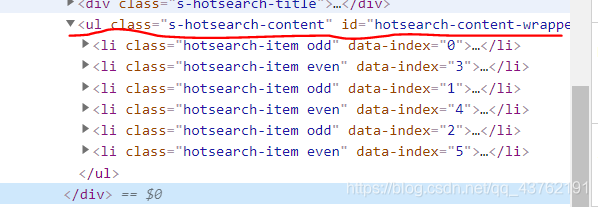
将标签叠起来,我们很容易的发现它们都处在<ul>这个标签下。
那就有办法一次全部提取出来了,如果没想明白的话建议翻到上面Xpath基本语法节选部分再想明白。
先对第一个标签进行提取,发现文本路径为://*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]
而网址路径为://*[@id="hotsearch-content-wrapper"]/li[1]/a/@href
很显然,li[1]代表的是第一个标签,而下面五个标签分别对应li[2]、li[3]、以此类推,此处可以优化为 //li
而对于 li标签以下的部分,我们可以用简单粗暴的 全部提取//的方式提取文本吗?并不行,因为在li标签下有多类文本,而我们只要一种。
所以我们的Xpath路径这样写:
//*[@id="hotsearch-content-wrapper"]//li/a
./span[2]/text() | ./@href
或者这样:
//*[@id="hotsearch-content-wrapper"]//li/a/span[2]/text() | //*[@id="hotsearch-content-wrapper"]//li/a/@href
一个是时间,一个是空间,自己选一个吧。
所以代码也就很快出来了啊:
import requests #做爬虫比较常用的一个包
import random
import time
from lxml import etree
url = 'https://www.baidu.com/?tn=48021271_10_hao_pg'
def get_html(url,header_list,sleep_time):
times = 3
try:
res = requests.get(url=url, headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"})
if res.status_code >= 200 and res.status_code<300:
time.sleep(sleep_time)
return res
else:
return None
except Exception as e:
print(e)
if times>0:
print("机会次数:"+str(times))
get_html(url, header_list,sleep_time)
else:
print("无法爬取")
def get_data(html_data, Xpath_path):
'''
这是一个从网页源数据中抓取所需数据的函数
:param html_data:网页源数据 (单条数据)
:param Xpath_path: Xpath寻址方法
:return: 存储结果的列表
'''
data = html_data.content
data = data.decode().replace("<!--", "").replace("-->", "") # 删除数据中的注释
tree = etree.HTML(data) # 创建element对象
el_list = tree.xpath(Xpath_path)
return el_list
res = get_html(url=url,header_list=header_list,sleep_time=2)
#print(res.content)
el_list = get_data(res,'//*[@id="hotsearch-content-wrapper"]//li/a')
for el in el_list:
e = el.xpath('./span[2]/text() | ./@href')
print(e)
得到结果:
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E6%89%93%E5%AE%8C%E7%96%AB%E8%8B%97%E5%90%8E%E8%8B%A5%E5%8F%91%E7%83%A7%E4%B8%8D%E9%80%80%E7%AD%89%E8%A6%81%E6%8A%A5%E5%91%8A&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '打完疫苗后若发烧不退等要报告']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E8%BE%BD%E5%AE%81%E8%88%B0%E5%92%8C%E7%BE%8E%E5%9B%BD%E9%A9%B1%E9%80%90%E8%88%B0%E8%BF%91%E8%B7%9D%E7%A6%BB%E7%A2%B0%E9%9D%A2&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '辽宁舰和美国驱逐舰近距离碰面']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E5%93%88%E9%87%8C%E5%B0%86%E8%BF%94%E8%8B%B1%E5%8F%82%E5%8A%A0%E8%8F%B2%E5%88%A9%E6%99%AE%E4%BA%B2%E7%8E%8B%E8%91%AC%E7%A4%BC&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '哈里将返英参加菲利普亲王葬礼']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E7%BE%8E%E9%BB%91%E4%BA%BA%E5%86%9B%E5%AE%98%E9%81%AD%E7%99%BD%E4%BA%BA%E8%AD%A6%E5%AF%9F%E5%96%B7%E8%BE%A3%E6%A4%92%E6%B0%B4&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '美黑人军官遭白人警察喷辣椒水']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E5%8C%BB%E7%94%9F%E8%87%AA%E6%9B%9D%E6%94%B6%E5%9B%9E%E6%89%A350%E5%A4%9A%E4%B8%87+%E5%8D%AB%E5%81%A5%E5%A7%94%E8%B0%83%E6%9F%A5&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '医生自曝收回扣50多万 卫健委调查']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E8%82%AF%E5%BE%B7%E5%9F%BA%E8%AF%AF%E6%8A%8A%E6%B6%88%E6%AF%92%E6%B0%B4%E7%BB%99%E5%A5%B3%E5%AD%A9%E9%A5%AE%E7%94%A8&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '肯德基误把消毒水给女孩饮用']
注意看这个结果,排列的也是很有规律性的。
requests-html和其他解析HTML库最大的不同点在于HTML解析库一般都是专用的,所以我们需要用另一个HTTP库先把网页下载下来,然后传给那些HTML解析库。而requests-html自带了这个功能,所以在爬取网页等方面非常方便。
有了上面的铺垫,下面这些应该是轻车熟路了,我就不多说,直接上实操。
from requests_html import HTMLSession
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') # 改变标准输出的默认编码
session = HTMLSession()
r = session.get('https://www.baidu.com/?tn=48021271_10_hao_pg',headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"})
# 查看页面内容
print(r.html.html)
print(r.html.links) # 获取所有链接
print(r.html.text) # 获取所有文本
print(r.html.absolute_links) # 获取全部绝对链接
print(r.html.raw_html) # 返回二进制
这里抓取标签依旧是Xpath,不过就是把过程简化了,其实用我们上面封装好的函数也不比这个麻烦。
这里只讲Xpath,这需要另一个函数xpath的支持,它有4个参数如下:
- selector,要用的XPATH路径;
- clean,布尔值,如果为真会忽略HTML中style和script标签造成的影响(原文是sanitize,大概这么理解);
- first,布尔值,如果为真会返回第一个元素,否则会返回满足条件的元素列表;
- _encoding,编码格式。
print(r.html.xpath("//div[@id='menu']", first=True).text)
print(r.html.xpath("//div[@id='menu']/a"))
print(r.html.xpath("//div[@class='content']/span/text()"))
如果仅仅是获取这些东西的话,我建议直接使用lxml,因为这个模块的底层也是封装了lxml、requests、beautifulsoup等模块包的。
今天先到这里啦,下一篇见啦。
(不要问我为什么不讲requests-html对JavaScript的支持,问就是目前没必要,后面有更简单的方法)


一、前言 在开发项目的过程中,我新创建了一个controller,发现vs会给我们直接在...
compilation debug=true 意味着可以插入一些debugger的中断,这样在开发是就可以...
前言 我们都知道,Redis和Memcached都是内存数据库,它们的访问速度非常之快。但...
文章目录 系列导读 这个系列是什么 本系列配套资源 已加入CSDN“蓄力计划”打造...
自 2019 年首次亮相以来, Windows Terminal 已经走过了很长的一段路,微软也一...
开篇三问 AJAX请求真的不安全么? AJAX请求哪里不安全? 怎么样让AJAX请求更安全...
1、异常概述 异常(Exception)是一种错误处理机制,用于在指定的错误发生时改变...
复制代码 代码如下: !DOCTYPE html html head meta charset="utf-8" title/title...
本文实例讲述了js中正则的查找match()与替换replace()的用法。分享给大家供大家...
作为今年Windows 10的最重要的更新,微软正在做最后的测试,而用户也很快能看上...

