

/*比如我想查询2009年秋季和2010年春季开课的course_id,以及该课上课的房间号*/
(
SELECT course_id , room_number
FROM section
WHERE semester='Fall' AND YEAR = 2009
)
UNION -- union会自动帮我们的结果去重
(
SELECT course_id , room_number
FROM section
WHERE semester = 'Spring' AND YEAR = 2010
);
/*将结果合并在一起,但是不去重*/
(
SELECT course_id
FROM section
WHERE semester='Fall' AND YEAR=2009
)
UNION ALL
(
SELECT course_id
FROM section
WHERE semester='Spring' AND YEAR=2010
);
union查询结果如图
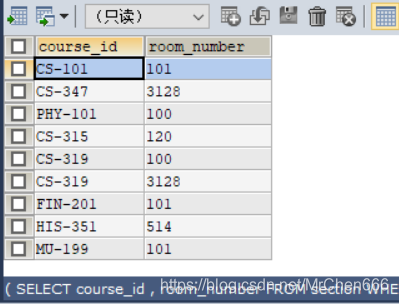
/*通过对两个表where来实现集合交运算*/
SELECT T.course_id
FROM
(SELECT course_id
FROM section
WHERE semester='Fall' AND YEAR = 2009
) AS T , -- T表储存的是2009年秋季开课的course_id
(SELECT course_id
FROM section
WHERE semester='Spring' AND YEAR = 2010
) AS S -- S表储存的是2010年春季开课的course_id
WHERE T.course_id = S.course_id; -- 这里的T中course_id会逐个与S中的course_id进行比较,相等的话就保存到
-- 结果表中

/*通过where中not in 操作实现集合差*/
/*这里我们想找出只在2009年秋季开课而不在2010年春季开课的课程*/
SELECT T.course_id
FROM
(SELECT course_id
FROM section
WHERE semester='Fall' AND YEAR = 2009) AS T
WHERE T.course_id NOT IN -- 这里用到了not in
(SELECT course_id
FROM section
WHERE semester='Spring' AND YEAR = 2010);
/*主意啊,上述两个表的顺序一但调换,结果是不同的!!大家可以自己理解一下为什么不同*/
/*这里我们想找出只在2010年春季开课而不在2009年秋季开课的课程*/
SELECT S.course_id
FROM
(SELECT course_id
FROM section
WHERE semester='Spring' AND YEAR = 2010) AS S
WHERE S.course_id NOT IN
(SELECT course_id
FROM section
WHERE semester='Fall' AND YEAR = 2009);
查询方法与上面类似,当T集合的一条记录在S集合中没有出现,此时就会返回真,并把该记录储存到结果表中。
/*利用avg或者其他函数求值*/
SELECT AVG(salary) AS avg_salary
FROM instructor
WHERE dept_name = 'Comp. Sci.';
/*通常利用这个来查找表中有多少行*/
SELECT COUNT(*) AS number
FROM course;
/*还有像max()还有min()函数大家可以自行去练习,这里我就不举例子了*/
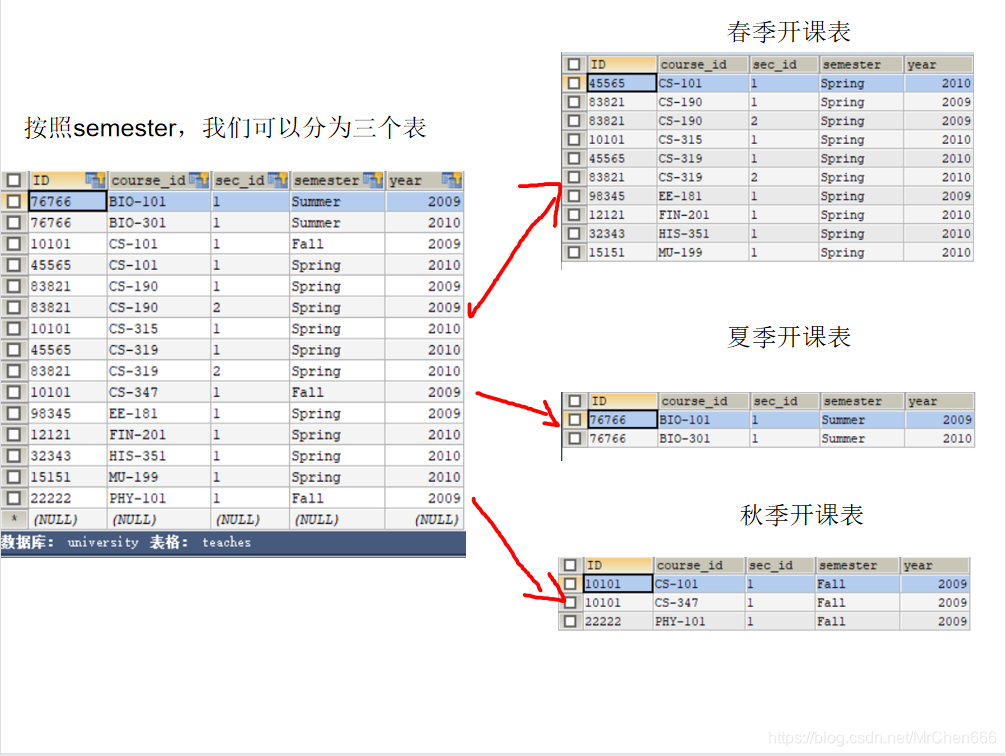
接下来给大家举个例子,让大家对group by有个更好的掌握
/*统计一下2010年春季有各个系的老师有多少人开课*/
/*group by 后面接的select语句语法比较严格,需要谨慎,一般接函数或者分组的键,比如这里的dept_name*/
SELECT dept_name , COUNT(DISTINCT instructor.ID) AS inst_count
FROM instructor , teaches
WHERE instructor.ID = teaches.ID AND -- 第一个=是找出某个老师上的课的记录
semester = 'Spring' AND -- 第二个=是在上一个=的基础上,找出春季开课,也就是找出该老师春季教的课
YEAR = 2010 -- 第三个=在上面的结果中,找出是2010年开的课,可以发现三个=其实一直在做集合交运算
GROUP BY dept_name; -- 注意group by是在where后面的,对结果表进行分组
这是最终的查询结果,可以发现,每一个分组,就只有一个记录,因此select最后必须有代表这个组的键
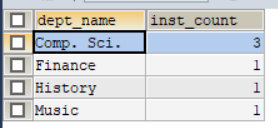
这个时候给大家一个问题:我能不能select这些组中的name键,如下代码所示:
SELECT dept_name , NAME -- 这样做的意义是什么?
FROM instructor , teaches
WHERE instructor.ID = teaches.ID AND
semester = 'Spring' AND
YEAR = 2010
GROUP BY dept_name;
事实上我的MySQL是可以执行的,但是这个语句是错误的,大家可以看到,最后select是对不同组的表选择键,比如我可以选择各个组表的dept_name,或者各个组表的平均工资等等。但是要选择老师名字是什么意思?比如计算机系中有三个老师,我该选择哪一个老师的名字呢?可以发现是毫无意义的查询,在Oracle或者其他数据库中这个语句是会报错的!因此:group by 后面接的select语句语法比较严格,需要谨慎,一般接函数或者分组的键,比如这里的dept_name。
SELECT dept_name,AVG(salary) AS avg_salary
FROM instructor
GROUP BY dept_name
HAVING AVG(salary) > 42000; -- 这里是筛选group by之后的结果
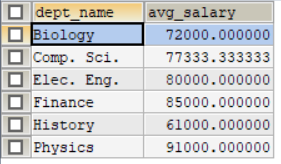
/*求出2009年两个学期中有超过两个学生去学习的课程的平均学分*/
SELECT course_id,semester,YEAR,sec_id,AVG(tot_cred)
-- FROM takes,student
-- WHERE takes.ID = student.ID AND YEAR = 2009
FROM takes NATURAL JOIN student -- 上面的takes.ID = student.ID相当于NATURAL JOIN,表示找出学生上过的课的记录
WHERE YEAR = 2009
/*这里按如下顺序进行分组*/
GROUP BY course_id,semester,YEAR,sec_id -- 比如当course_id组中按semester又分多个组,如此继续分。
-- 这里给大家思考,如果按主键分组,我们最后可以得到什么,其实就是得到原表的每一条记录!
HAVING COUNT(takes.ID)>=2;
查询结果如图

/*limit语句用于筛选一定数目的记录,当实际记录少于限定的记录也没关系*/
/*这里找出平均工资前二的系名和该系的平均工资*/
SELECT dept_name,AVG(salary) AS avg_salary
FROM instructor
GROUP BY dept_name
ORDER BY avg_salary DESC
LIMIT 2; -- limit是对结果表的记录进行限制,所以放在一定放在where,group by后面
/*
LIMIT 0,5 -- 表示显示第一到第五条的记录,注意记录是从0下表开始算的。
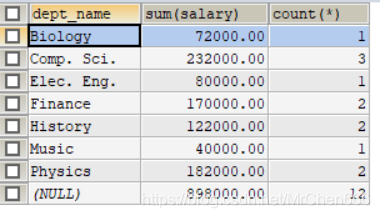
/*汇总一般是求一个sum*/
SELECT dept_name , SUM(salary) , COUNT(*)
FROM instructor
GROUP BY dept_name WITH ROLLUP;
查询记录如图,最后那一条就是with rollup的字段,但是可以发现,对于无法统计的键dept_name是空值

Elasticsearch 是通过 Lucene 的倒排索引技术实现比关系型数据库更快的过滤。特...
错误描述: 在开发.net项目中,通过microsoft.ACE.oledb读取excel文件信息时,报...
项目中用到的一些特殊字符和图标 html代码 XML/HTML Code 复制内容到剪贴板 div ...
DELETEFROMTablesWHEREIDNOTIN(SELECTMin(ID)FROMTablesGROUPBYName) Min的话保...
复制代码 代码如下: % URL="http://news.163.com/special/00011K6L/rss_newstop....
正则忽略大小写 – RegexOptions.IgnoreCase 例如: 复制代码 代码如下: Str = R...
上篇文章给大家介绍了 Java正则表达式匹配,替换,查找,切割的方法 ,接下来,...
工具:Eclipse,Oracle,smartupload.jar;语言:jsp,Java;数据存储:Oracle。...
4月11日20:30~22:00通过腾讯会议进行了第二次在线学习讨论我把学习笔记整理一下...
本文实例讲述了Laravel框架源码解析之反射的使用。分享给大家供大家参考,具体如...

