


CentOs7
docker20
jdk1.8
hadoop3.2
手把手复现,有手就行。
可以使用虚拟机或服务器,白嫖服务器可参考:
学生党白嫖服务器-不会吧不会吧,你还在买学生机吗?
还可关注左侧公众号领取👈
yum update #更新(询问输入y)
yum install -y yum-utils device-mapper-persistent-data lvm2 #安装依赖
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce #安装docker
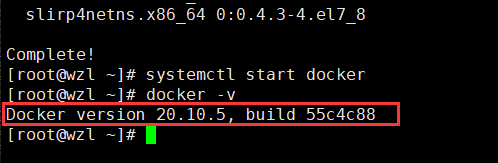
systemctl start docker #启动docker
docker -v #查看docker版本

docker pull centos

vim Dockerfile
#复制以下内容
FROM centos
MAINTAINER mwf
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
RUN yum install -y openssh-clients
RUN echo "root:123456" | chpasswd #ssh密码可自定义,这里就写123456了
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
#然后按Esc :wq保存退出
docker build -t="centos7-ssh" . #镜像名可自定义
docker images #查看镜像

至此一个带ssh服务的centos镜像就安好了。
eyu3
ca8s
mv Dockerfile Dockerfile.centos_ssh
vim Dockerfile
#复制以下内容
FROM centos7-ssh
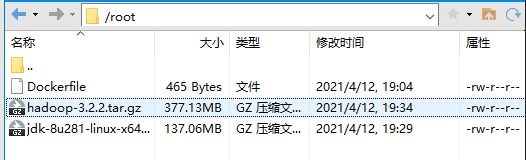
ADD jdk-8u281-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_281 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
ADD hadoop-3.2.2.tar.gz /usr/local
RUN mv /usr/local/hadoop-3.2.2 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
RUN yum install -y which sudo
#然后按Esc :wq保存退出
docker build -t="hadoop" .

设置集群间的网络。
docker network create --driver bridge hadoop-br

docker run -itd --network hadoop-br --name hadoop1 -p 50070:50070 -p 8088:8088 hadoop
docker run -itd --network hadoop-br --name hadoop2 hadoop
docker run -itd --network hadoop-br --name hadoop3 hadoop

3. 检查网络情况
docker network inspect hadoop-br

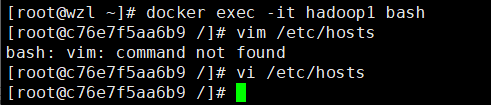
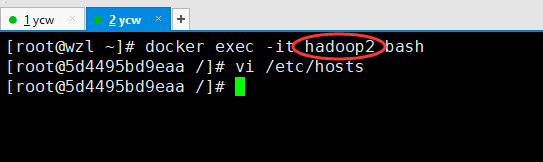
docker exec -it hadoop1 bash #hadoop2、hadoop3
vi /etc/hosts
# 加入以下id和hostname,就是上一个图圈起来的
172.18.0.2 hadoop1
172.18.0.3 hadoop2
172.18.0.4 hadoop3

ssh-keygen
#一路回车
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop1
#输入密码就是前面的123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop2
#输入密码就是前面的123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop3
#输入密码就是前面的123456

(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
ping hadoop1
ping hadoop2
ping hadoop3
ssh hadoop1
ssh hadoop2
ssh hadoop3
#记得exit

以下操作在主节点hadoop1上执行即可:
docker exec -it hadoop1 bash#进入hadoop1
mkdir /home/hadoop #创建目录
mkdir /home/hadoop/tmp /home/hadoop/hdfs_name /home/hadoop/hdfs_data
cd /usr/local/hadoop/etc/hadoop/
#vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>

2. hdfs-site.xml
#vi hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs_name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs_data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>

3. mapred-site.xml
#vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>

4. yarn-site.xml
# vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
#vi workers
hadoop2
hadoop3
6. 拷贝
scp -r /usr/local/hadoop/ hadoop2:/usr/local/
scp -r /usr/local/hadoop/ hadoop3:/usr/local/
scp -r /usr/local/hadoop hadoop2:/
scp -r /usr/local/hadoop hadoop3:/
三个都执行
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash
cd /usr/local/hadoop/sbin
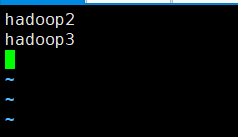
vi start-dfs.sh#第二行添加如下4句
vi stop-dfs.sh#第二行添加如下4句
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
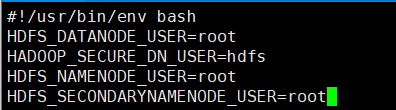
cd /usr/local/hadoop/sbin
vi start-yarn.sh#第二行添加如下3句
vi stop-yarn.sh#第二行添加如下3句
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
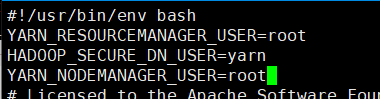
4. env.sh
cd /usr/local/hadoop/etc/hadoop
vi hadoop-env.sh#加入下面这句话
export JAVA_HOME=/usr/local/jdk1.8
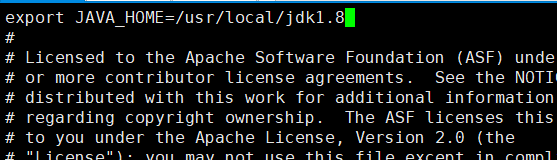
export JAVA_HOME=/usr/local/jdk1.8
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:/bin:/usr/bin:$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin
source ~/.bashrc #执行
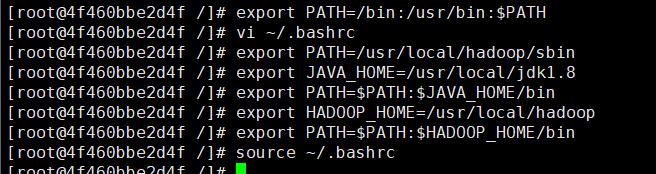
在hadoop1下执行
hdfs namenode -format
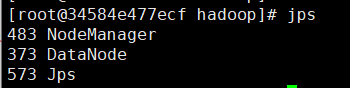
start-all.sh
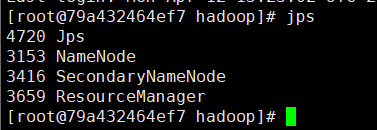
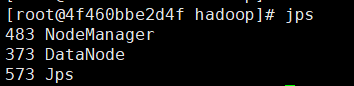
jps
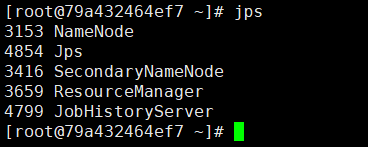
若需要可开启历史服务
mr-jobhistory-daemon.sh start historyserver

原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
微信公众号:唔仄lo咚锵
如果文章对你有帮助,记得一键三连?

错误描述: 在开发.net项目中,通过microsoft.ACE.oledb读取excel文件信息时,报...
工具:Eclipse,Oracle,smartupload.jar;语言:jsp,Java;数据存储:Oracle。...
Elasticsearch 是通过 Lucene 的倒排索引技术实现比关系型数据库更快的过滤。特...
上篇文章给大家介绍了 Java正则表达式匹配,替换,查找,切割的方法 ,接下来,...
复制代码 代码如下: % URL="http://news.163.com/special/00011K6L/rss_newstop....
正则忽略大小写 – RegexOptions.IgnoreCase 例如: 复制代码 代码如下: Str = R...
本文实例讲述了Laravel框架源码解析之反射的使用。分享给大家供大家参考,具体如...
项目中用到的一些特殊字符和图标 html代码 XML/HTML Code 复制内容到剪贴板 div ...
4月11日20:30~22:00通过腾讯会议进行了第二次在线学习讨论我把学习笔记整理一下...
DELETEFROMTablesWHEREIDNOTIN(SELECTMin(ID)FROMTablesGROUPBYName) Min的话保...

