

简单来说,正则表达式是一个特殊的字符序列,判断一个字符串是否与我们所设定的这样的字符数列相匹配,从而可以将匹配的字符做出检索、替换、删除等操作。它常由 普通字符 以及特殊字符 组成。
例如,我们可以用来检查用户输入的内容是否符合我们需要的格式等等。
下面我们用一个例子,简单理解一下,正则表达式。(判断下列字符串中是否包含 Python):
如果我们不用正则表达式,我们可以这样判断(其实已经很简单了):
a='C|C++|Java|Python|C#'
print(a.index('Python')>-1) # 索引
print('Python' in a) # in 关键词
# True
# True
下面我们来看看用正则表达式,怎么办:
import re # 引入一个正则表达式需要的模块
a='C|C++|Java|Python|C#'
re.findall('Python', a) # 正则表达式(使用了findall函数)
r=re.findall('Python', a) # 打印结果
print(r)
# ['Python']
r1=re.findall('Go', a) # 打印结果
print(r1)
# []
# 所以可以如此应用(规则)
if len(r)!=0:
print('a中含Python')
else:
print('No')
相比于以上两种方法,正则表达式不仅判断了其是否存在,而且将此字符串以列表的形式返回。
那有人可能会说了,用正则表达式不是更烦了吗?矮油,不要着急。它的作用可不止这些,我们下面慢慢讲。
我们先来介绍一下re.findall函数
它就是在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
findall(string,a[, pos[, endpos]])
参数:
string : 待匹配的字符串。
a: 原字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
还是原来的字符串,我们换个匹配字符试试。
import re
a='C|C++|Java|Python|C#'
r=re.findall('C', a)
print(r)
# ['C', 'C', 'C']
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
如下列,我想要在一串字符串中提取所有的数字,我们可以这样写:
import re
a = 'adh0eu2jf3+=dj6*&fa90@4'
r = re.findall('[0-9]', a)
print(r)
#['0', '2', '3', '6', '9', '0', '4']
0-9 就是其中的普通字符,而我们 [ ] 表示的是我们匹配的只要是0-9的数都可以。
同理,我们也可以用这种方式匹配大写字母,小写字母,或者个别字符等等。
r = re.findall('[a-z]', a)
r = re.findall('[A-Z]', a)
r = re.findall('[Asu]', a)
元字符也就是特殊字符
当我们想要匹配数字字符,字母字符和一些特殊符号时,我们用普通字符则需要在[ ]里写上一大长串:
r = re.findall('[0-9a-zA-Z!%^&]', a)
这样每次书写,难免会嫌烦了,这时候元字符就能很好的派上用场了,它可以用简短的字符代替冗杂的普通字符。
a='adh0eu2jf3+=dj6*&fa90@4'
r=re.findall('\d',a) # \d 表示0~9
print(r)
r=re.findall('\D',a) # \D 表示除0-9以外的所有字符
print(r)
我们常见的元字符有:
| 常见元字符 | 作用 |
|---|---|
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。 |
| \S | 匹配任何非空白字符 |
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。 |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
元字符有很多,我们下面边讲边介绍。
同样,我们试试匹配一个字符集。
import re
# 字符集
s ='abc,acc,adc,aec,afc,ahc'
# 匹配出acc 或 afc
r = re.findall('a[cf]c', s) # 【】或关系
print(r)
# ['acc', 'afc']
#匹配出除acc和afc以外的字符串
r = re.findall('a[^cf]c', s) # ^ 取反
print(r)
# ['abc', 'adc', 'aec', 'ahc']
#匹配出c-f中的所有
r = re.findall('a[c-f]c', s) # - 范围
print(r)
# ['acc', 'adc', 'aec', 'afc']
数量词:
我们再看看下面这个例子,[a-z]是上面讲过的普通字符,而不同的是后面多了一个{3}.这是什么意思呢?
import re
a = 'python 1111 java739php'
r = re.findall('[a-z]{3}',a)
print(r)

看看运行结果就可以知道。{n} 可以表示一种成组匹配的方式。如上,三个字母为一组,一一取出。
除了{n},我们还有 {n,m} (n,m都是非负整数,且n<m):意思是最少匹配 n 次且最多匹配 m 次。同样, {n,} 至少匹配n 次。
a = 'python 1111 java739php'
r = re.findall('[a-z]{3,6}',a)
# {3,6}表示最少匹配3次,最多匹配6次
print(r)
结果:

这时候有人可能会问了,匹配最少3次,最多6次,那最开始为什么不只匹配3、4、5次呢?为什么‘Python’这个词全被匹配出来了呢?
这就涉及到了贪婪和非贪婪的概念了。
- 贪婪匹配:趋向于最大长度匹配 。尽可能多的匹配,直到不满足条件为止。(正则表达式默认都为贪婪匹配)
- 非贪婪匹配:就是匹配到结果就好,就少的匹配字符。
正则表达式默认都为贪婪匹配。
那如果我们不需要它贪婪匹配,让它们到非贪婪匹配行不行呢?这也是有办法的。在后面加上一个 ? 就可以了。
r = re.findall('[a-z]{3,6}?',a)
print(r)

元字符中的数量词还有:
| 量词元字符 | 含义 |
|---|---|
| * | 匹配0次或无限多次 |
| + | 匹配1次或无限多次 |
| ? | 匹配0次或者一次 |
下面用例子来理解:
import re
a = 'pytho1111 python739pythonn^'
r = re.findall('python*', a)
print(r)
r = re.findall('python+', a)
print(r)
r = re.findall('python?', a)
print(r)
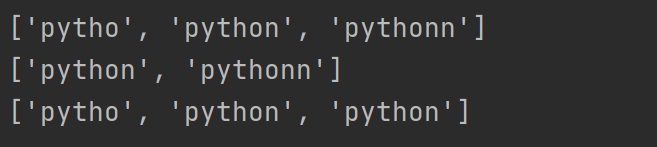
以上a字符串中有三组字符串‘pytho’,‘python’,‘pythonn’。
对于n来说 ‘pytho’中 n数为0次,‘python’ 中n数为1次,'pythonn’中 n数为2次。
所以,根据上面的表格,* 从0到无限次都能匹配,+ 不能匹配0次,?只能匹配0次到1次。
注意:这里的 ? 与之前讲非贪婪匹配时出现的 ? 的区别,两者并不相同。
边界匹配:
边界匹配不得不提两个元字符:
| 元字符 | 含义 |
|---|---|
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
如以下例子,我想要判断用户输入的是否符合4-8位的qq号格式。
import re
qq='qq1000001qq'
r=re.findall('\d{4,8}',qq)
print(r)

这个结果,显然不是我们想要的,以上字符串明明不符合所要的qq号格式,却也能匹配出结果。
这时候就可以用到边界匹配了。
qq='qq1000001'
r=re.findall('^\d{4,8}',qq)
# []
r=re.findall('\d{4,8}$',qq)
# ['1000001']
r=re.findall('^\d{4,8}$',qq)
#[]
qq='1000001qq'
r=re.findall('\d{4,8}$',qq)
# []
r=re.findall('^\d{4,8}',qq)
# ['1000001']
r=re.findall('^\d{4,8}$',qq)
#[]
还记得上面说过的 [ ] 是或关系吗?下面这个 ( ) 则代表的是且关系。
import re
a='PythonPythonPythonPythonPython'
r=re.findall('(Python){3}',a) # 括号表示一个组
print(r) # ()且关系【】或关系
# ['Python']
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。
| 修饰符 | 含义 |
|---|---|
| re.I | 匹配忽略大小写 |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
import re
a = 'Python293jddjkJava\n$%'
r=re.findall('python',a,re.I) # 忽略大小写
print(r)
r=re.findall('java.{1}',a,re.I|re.S) # 且关系
print(r) # 匹配java后的一个字符,包括换行符。
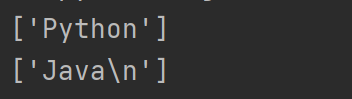
re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
有了例子,好理解:
import re
a = 'Python293jddjkJava$%PythonPython'
r=re.sub('Python', 'C', a)
print(r)
r=re.sub('Python', 'C', a, 1) # 换一次
print(r)

不止可以用字符串替换,还可以用函数替换,也就是把这个函数作为参数传递,函数的返回值替换匹配的字符串。
import re
a = 'Python293jddjkJava$%PythonPython'
def convert(value):
matched=value.group()
return '!!'+matched+'!!'
r=re.sub( 'Python', convert, a)
print(r)

在这里,再举一个例子,我们把字符串中大于等于6的数都替换成9,小于6的都替换为0.
import re
a = ' A9C123456D78'
# 把函数作为参数传递
def convert(value):
matched = value.group() # 拿到具体对象
if int(matched)>=6:
return '9'
else:
return '0'
r=re.sub( '\d', convert, a)
print(r)

re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
import re
a='A83C34D90FE'
r=re.match('\d',a)
print(r)
# 起始位置不是0-9,所以返回一个None
re.search 扫描整个字符串并返回第一个成功的匹配。匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
语法:
re.search(pattern, string, flags=0)
- pattern 匹配的正则表达式
- string 要匹配的字符串。
- flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re
a='A83C34D90FE'
r1=re.search('\d',a)
print(r1)
print(r1.group())
print(r1.span()) # 跨度位置
# 匹配一次就停止

group() 中我们也可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
import re
a = 'Asu is a beautiful girl.Haha!'
# 提取Asu girl之间的所有字符
r = re.search('Asu(.*)girl.*', a)
# . 匹配除\n外所有字符
print('r.group():'+r.group())
print('r.group(0):'+r.group(0))
print('r.group(1):'+r.group(1))

import re
a = 'Asu is a beautiful girl.Asu is cute. Asu is lovely.'
r = re.search('Asu(.*)Asu(.*)Asu',a)
print(r.group(0))
print(r.group(1))
print(r.group(2))
print(r.group(0,1,2))
print(r.groups())
r = re.findall('Asu(.*)Asu(.*)Asu',a)
print(r)

这样我们也可以来看看re.search与re.findall之间的差别:
import re
a = 'Asu is a beautiful girl.Asu is cute. Asu is lovely.'
r = re.search('Asu(.*)Asu(.*)Asu',a)
print(r.group())
r = re.findall('Asu(.*)Asu(.*)Asu',a)
print(r)

re.findall会将中间的字符串以元组的方式取出,而对于re.search中的group()则会结合前后的字符串一同打印出来。

目录 Delphi线程内部 unit System.Classes; unit System;? unit System.Threadin...
本文实例讲述了TP5框架实现的数据库备份功能。分享给大家供大家参考,具体如下:...
大家肯定都知道计算机程序设计语言通常分为机器语言、汇编语言和高级语言三类。...
邮箱地址验证正则表达式 dedecms中的邮箱地址验证 复制代码 代码如下: ?php $ema...
微软目前正在测试一种向Windows 10操作系统提供功能更新和更改的新方法。到目前...
什么是mata标签 meta 元素可提供有关页面的元信息(meta-information),比如针...
目录 一、遇到的问题 二、材料 三、步骤 1. 服务器配置 A. 部署Go语言环境 B. 安...
我想对 html 的图片进行提取. img ico src="http://localhost/UCenter/images/no...
类加载 类加载子系统的作用 ? 类加载器子系统负责从文件系统或者网络中加载class...
本文实例讲述了yii2.0框架数据库操作。分享给大家供大家参考,具体如下: 添加 $...

