

上海贝尔网络应用-林锐


目前还在C语言阶段,大部分是C语言能用到的细节,看一遍总会忘,记得收藏~
C++复制粘贴了一部分,然而越看越吃力,就待定了…
- `ifndef famer_h`
- define famer_h
- ..
- endif




【规则 2-5-1】代码行最大长度宜控制在 70 至 80 个字符以内。代码行不要过长,否则眼睛看不过来,也不便于打印。
【规则 2-6-1】应当将修饰符 * 和 & 紧靠变量名 *


Windows 应用程序的标识符通常采用“大小写”混排的方式,如 AddChild。
【规则 3-1-6】变量的名字应当使用“名词”或者“形容词+名词”。
【规则 3-1-7】全局函数的名字应当使用“动词”或者“动词+名词”(动宾词组)。
【规则 3-1-8】用正确的反义词组命名具有互斥意义的变量或相反动作的函数等.
- 例如:int minValue;
- int maxValue;
- int SetValue(…);
- int GetValue(…)
【规则 3-2-1】类名和函数名用大写字母开头的单词组合而成。

【规则 3-2-3】常量全用大写的字母,用下划线分割单词。
【规则 3-2-4】静态变量加前缀 s_(表示 static)。
【规则 3-2-5】如果不得已需要全局变量,则使全局变量加前缀 g_(表示 global)。
-
【规则 3-2-6】类的数据成员加前缀 m_(表示 member),这样可以避免数据成员与_成员函数的参数同名。

C++/C 语言的运算符有数十个,运算符的优先级与结合律如表 4-1 所示。注意一元运算符 + - * 的优先级高于对应的二元运算符。
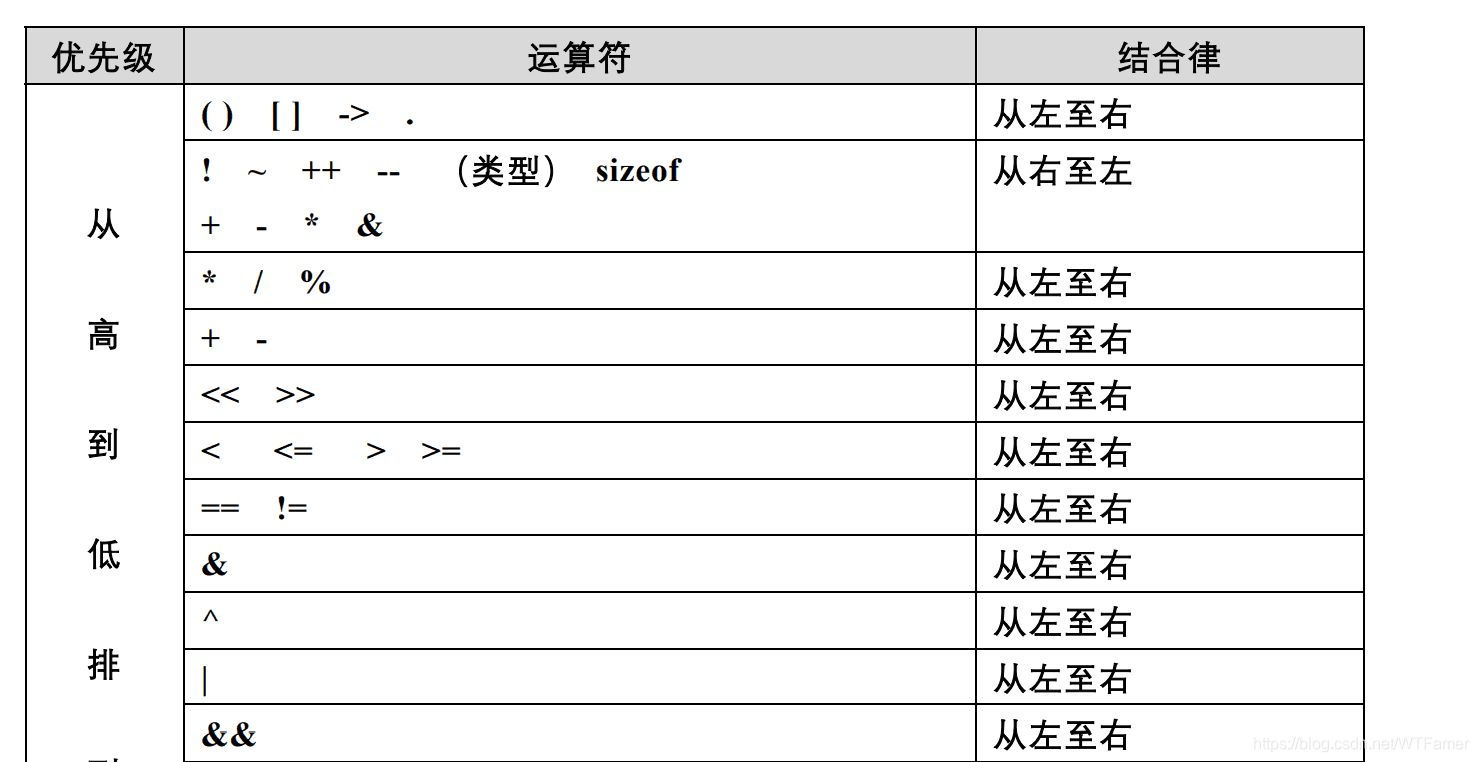

【规则 4-1-1】如果代码行中的运算符比较多,用括号确定表达式的操作顺序,避免使用默认的优先级。
- 例如:word = (high << 8) | low
- if ((a | b) && (a & c))
如 a = b = c = 0 这样的表达式称为复合表达式。允许复合表达式存在的理由是:(1)书写简洁;(2)可以提高编译效率。但要防止滥用复合表达式。
z 【规则 4-2-1】不要编写太复杂的复合表达式。
例如:
i = a >= b && c < d && c + f <= g + h ; // 复合表达式过于复杂
z 【规则 4-2-2】不要有多用途的复合表达式。
例如:d = (a = b + c) + r ;
该表达式既求 a 值又求 d 值。应该拆分为两个独立的语句:
a = b + c;
d = a + r;
- if (flag) 表示 flag 为真
- if (!flag) 表示 flag 为假
- if (value == 0)
- if (value != 0)
- 转化为 if ((x>=-EPSINON) && (x<=EPSINON))
- 其中 EPSINON 是允许的误差(即精度)。
- if (p == NULL) // p 与 NULL 显式比较,强调 p 是指针变量 if (p != NULL)
C++/C 循环语句中,for 语句使用频率最高,while 语句其次,do 语句很少用。
【建议 4-4-1】在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少 CPU 跨切循环层的次数。
- for (col=0; col<5; col++ )
- {
- for (row=0; row<100; row++)
- {
- sum = sum + a[row][col];
- }
- }
- for (i=0; i<N; i++) *C
- {
- if (condition)
- DoSomething();
- else
- DoOtherthing();
- }
- if (condition) *D
- {
- for (i=0; i<N; i++)
- DoSomething();
- }
- else
- {
- for (i=0; i<N; i++)
- DoOtherthing();
- }
- switch (variable)
- {
- case value1 : …
- break;
- case value2 : …
- break;
- ….
- default : …
- break;
- }

(1) const 常量有数据类型,而宏常量没有数据类型。编译器可以对前者进行类型安全检查。而对后者只进行字符替换,没有类型安全检查,并且在字符替换可能会产生意料不到的错误(边际效应)。
(2) 有些集成化的调试工具可以对 const 常量进行调试,但是不能对宏常量进行调试。
【规则 5-2-1】在 C++ 程序中只使用 const 常量而不使用宏常量,即 const 常量完全取代宏常量。
- const float RADIUS = 100;
- const float DIAMETER = RADIUS * 2;

void StringCopy(char *strDestination,const char *strSource);【规则 6-2-1】不要省略返回值的类型
如果 getchar 碰到文件结束标志或发生读错误,它必须返回一个标志 EOF。为了区别于正常的字符,只好将 EOF 定义为负数(通常为负 1)。因此函数 getchar 就成了 int 类型。

函数的出口入口处对参数的有效性进行检查

编译器直接把临时对象创建并初始化在外部存储单元中,省去了拷贝和析构的化费,提高了效率。


640K ought to be enough for everybody — Bill Gates 1981
内存分配方式有三种:
要对堆区开辟的内存判断是否为NULL
数组要么在静态存储区被创建(如全局数组),要么在栈上被创建。数组名对应着(而不是指向)一块内存,其地址与容量在生命期内保持不变,只有数组的内容可以改变。
指针可以随时指向任意类型的内存块,它的特征是“可变”,所以我们常用指针来高质量 C++/C 编程指南,操作动态内存。指针远比数组灵活,但也更危险
指针 p 指向常量字符串“world”(位于静态存储区,内容为 world\0),
常量字符串的内容是不可以被修改的。从语法上看,编译器并不觉得语句 p[0]= ‘X’有什么不妥,但是该语句企图修改常量字符串的内容而导致运行错误

数组之间比较用 strcmp ,赋值用strcpy。

sizeof(字符串) ,’\0’也算字符串大小。

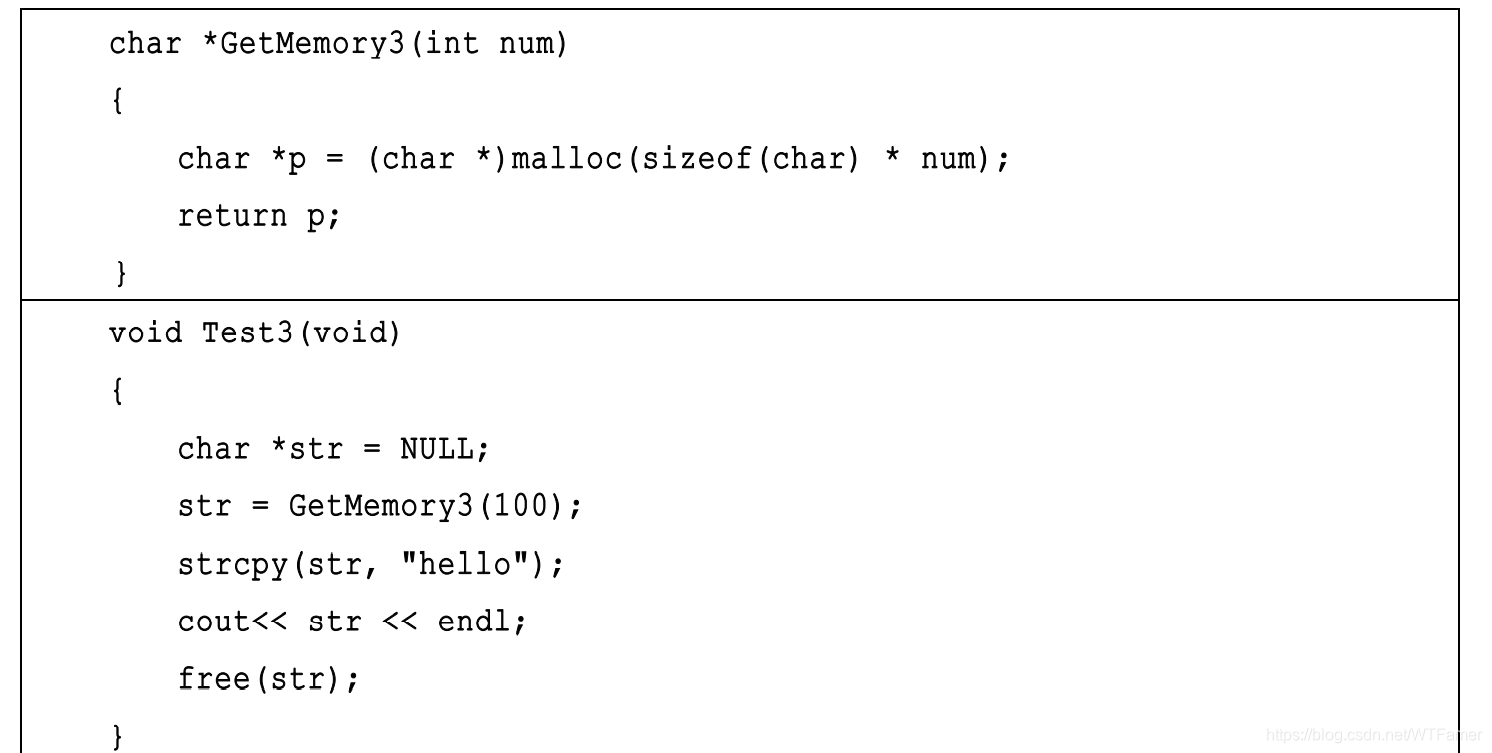



char *p = NULL; *
char *str = (char *) malloc(100);
void Func(void)
{
A *a = new A;
if(a == NULL)
{
return;
}
…
}
(2)判断指针是否为 NULL,如果是则马上用 exit(1)终止整个程序的运行。例如:
void Func(void)
{
A *a = new A; *
if(a == NULL)
{
cout << “Memory Exhausted” << endl;
exit(1);
}
…
}
(3)为 new 和 malloc 设置异常处理函数。例如 Visual C++可以用_set_new_hander 函_数为 new 设置用户自己定义的异常处理函数,也可以让 malloc 享用与 new 相同的异常处理函数。详细内容请参考 C++使用手册
上述(1)(2)方式使用最普遍。如果一个函数内有多处需要申请动态内存,那么方式(1)就显得力不从心(释放内存很麻烦),应该用方式(2)来处理。很多人不忍心用 exit(1),问:“不编写出错处理程序,让操作系统自己解决行不行?”
不行。如果发生“内存耗尽”这样的事情,一般说来应用程序已经无药可救。如果不用 exit(1) 把坏程序杀死,它可能会害死操作系统。道理如同:如果不把歹徒击毙,歹徒在老死之前会犯下更多的罪.
有一个很重要的现象要告诉大家。对于 32 位以上的应用程序而言,无论怎样使用malloc 与 new,几乎不可能导致“内存耗尽”。我在 Windows 98 下用 Visual C++编写了测试程序,见示例 7-9。这个程序会无休止地运行下去,根本不会终止。因为 32 位操作系统支持“虚存”,内存用完了,自动用硬盘空间顶替。我只听到硬盘嘎吱嘎吱地响,Window 98 已经累得对键盘、鼠标毫无反应
void main(void)
{
float *p = NULL;
while(TRUE)
{
p = new float[1000000];
cout << “eat memory” << endl;
if(p==NULL)
exit(1);
}
}
void * malloc(size_t size); int *p = (int *) malloc(sizeof(int) * length);


待定
void EatBeef(…); 可以改为 void Eat(Beef …);
void EatFish(…); 可以改为 void Eat(Fish …);
void EatChicken(…); 可以改为 void Eat(Chicken …);
重载是如何实现的?

所以只能靠参数而不能靠返回值类型的不同来区分重载函数。编译器根据参数为每个重载函数产生不同的内部标识符。例如编译器为示例 8-1-1 中的三个 Eat 函数产生象_eat_beef、_eat_fish、_eat_chicken 之类的内部标识符(不同的编译器可能产生不同风格的内部标识符)。
如果 C++程序要调用已经被编译后的 C 函数,该怎么办?假设某个 C 函数的声明如下:void foo(int x, int y);
extern “C”
{
void foo(int x, int y);
… 其它函数
}
或者写成
extern “C”
{
#include “myheader.h”
… 其它 C 头文件
}
这就告诉 C++编译译器,函数 foo 是个 C 连接,应该到库中找名字_foo 而不是找_foo_int_int。C++编译器开发商已经对 C 标准库的头文件作了 extern“C”处理,所以我们可以用#include 直接引用这些头文件。
注意并不是两个函数的名字相同就能构成重载。全局函数和类的成员函数同名不算重载,因为函数的作用域不同。例如:
void Print(…); 全局函数
class A
{…
void Print(…); // 成员函数
}
不论两个 Print 函数的参数是否不同,如果类的某个成员函数要调用全局函数 Print,为了与成员函数 Print 区别,全局函数被调用时应加‘::’标志。
::Print(…);// 表示 Print 是全局函数而非成员函数当心隐式类型转换导致重载函数产生二义性
示例 8-1-3 中,第一个 output 函数的参数是 int 类型,第二个 output 函数的参数是 float 类型。由于数字本身没有类型,将数字当作参数时将自动进行类型转换(称为隐式类型转换)。
#include <iostream.h>
void output( int x); // 函数声明
void output( float x); // 函数声明
void output( int x)
{
cout << " output int " << x << endl ;
}
void output( float x)
{
cout << " output float " << x << endl ;
}
void main(void)
{
int x = 1;
float y = 1.0;
output(x); output int 1
output(y); output float 1
output(1); output int 1
output(0.5); error! ambiguous call, 因为自动类型转换
output(int(0.5)); output int 0
output(float(0.5)); output float 0.5
}
待定
待定
待定
待定
待定



用 const 修饰函数的返回值
- const char * GetString(void); *
- 如下语句将出现编译错误:
- char *str = GetString(); *
- 正确的用法是
- const char *str = GetString();*
程序的时间效率是指运行速度,空间效率是指程序占用内存或者外存的状况。
全局效率是指站在整个系统的角度上考虑的效率,局部效率是指站在模块或函数角度上考虑的效率。
当心那些视觉上不易分辨的操作符发生书写错误。我们经常会把“==”误写成“=”,象“||”、“&&”、“<=”、“>=”这类符号也很容易发生“丢 1”失误。然而编译器却不一定能自动指出这类错误。
变量(指针、数组)被创建之后应当及时把它们初始化,以防止把未被初始化的变量当成右值使用。
当心变量的初值、缺省值错误,或者精度不够
当心数据类型转换发生错误。尽量使用显式的数据类型转换(让人们知道发生了什么事),避免让编译器轻悄悄地进行隐式的数据类型转换。
当心变量发生上溢或下溢,数组的下标越界。
当心忘记编写错误处理程序,当心错误处理程序本身有误。
当心文件 I/O 有错误。
避免编写技巧性很高代码。
不要设计面面俱到、非常灵活的数据结构。
尽量使用标准库函数,不要“发明”已经存在的库函数。
尽量不要使用与具体硬件或软件环境关系密切的变量。
把编译器的选择项设置为最严格状态。
如果可能的话,使用 PC-Lint、LogiScope 等工具进行代码审查。
略显仓促:
如有和原文较大差异的地方、或不完善的地方、或不明白的地方,可以百度、或者评论区柳岩…!
三联,三联,三联…

守护进程也称精灵进程Daemon是运行在后台的一种特殊进程。守护进程独立于控制终...
前段时间,个人小程序 因服务器磁盘空间被占满,导致MongoDB挂了。清理了一些无...
SQL编程既令人兴奋又具有挑战性。 即使是经验丰富的SQL程序员,开发人员和数据库...
本文是在课程课件基础上修改的学习笔记 课程原地址https://www.bilibili.com/vid...
Linux sort命令用于将文本文件内容加以排序。 sort可针对文本文件的内容,以行为...
目录 目录 前言 信号量 counting_semaphore latch与barrier latch barrier 总结 ...
采用java制作: 思路一: 合并mp3,把声音文件录制成以下几种: 1. “您的验证码...
[Ctrl+A 全选 注: 引入外部Js需再刷新一下页面才能执行 ] 原文链接:https://m.j...
Android Studio 中搭建 Robotium 环境 现在大部分的 Android 项目都从之前的 Ecl...
实现批处理的技术许许多多,从各种关系型数据库的sql处理,到大数据领域的MapRed...

