


数据分析工作中,免不了与SQL数据库打交道,尤其是对库表的使用,所以如何对库表进行创建、修改和删除,是一项基础技能。
DDL(DataDefinition Language的简写形式)是SQL语言集中负责数据结构定义与数据库对象定义的语言,由CREATE、ALTER与DROP三个语法所组成。
接下来分为库、表两部分给出示例代码供读者学习了解。
- # 创建数据库
- CREATE DATABASE testdatabase;
- # 选择数据库
- USE testdatabase;
- # 删除数据库
- DROP DATABASE testdatabase;
- # 列出已有数据库
- SHOW DATABASES;
以上操作语句如果是在命令行中执行,需注意要以分号结束。
CREATE DATABASE关键字后面的testdatabase就是新创建的库名,库名需要是唯一的,也就意味着不能和已经存在的库重名。USE testdatabase命令的作用就是切换到testdatabase库下进行后续操作。SHOW DATABASES会列出所有当前用户能访问到的数据库库名。
- # 创建表
- CREATE TABLE test1 (
- id INT unsigned NOT NULL AUTO_INCREMENT,
- name VARCHAR(225),
- price DECIMAL(10,2),
- PRIMARY KEY (id)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- # 删除表
- DROP TABLE test1;
- # 修改表字段类型
- ALTER TABLE test1 MODIFY name VARCHAR(100);
- # 添加表字段
- ALTER TABLE test1 ADD COLUMN age INT(3) FIRST;
- # 删除表字段
- ALTER TABLE test1 DROP age;
- # 修改表字段名称
- ALTER TABLE test1 CHANGE age age2 INT(20);
- # 表重命名
- ALTER TABLE test1 RENAME test2;
- # 查看表结构
- DESC test2;
同样,以上操作语句如果是在命令行中执行,需注意要以分号结束。
CREATE TABLE 的时候,要求新指定的表名必须不存在,否则会出错,这主要是为了防止意外覆盖已有的表。
ALTER TABLE后面给出的要更改信息的表名必须存在,否则将报错。使用ALTERTABLE要极为小心,应该在进行改动前做完整的备份(表结构和数据的备份),增加列会对数据存储造成影响,因此要尽量避免此类操作。
类似地,如果删除了不应该删除的列,可能会丢失该列中的所有数据。删除表操作同样无法撤销,所以执行该操作之前需十分谨慎小心。
另外和大家分享下,工作中常用的建表小技巧:
1. 创建表时,尽量使用一个自增的整型字段做主键。这样做,如果后续需要使用spark等框架分析这个表时,是非常方便的。
2. 创建表时,可以增加两个字段create_time和update_time。create_time存储记录的创建时间,update_time存储记录的最后一次变更时间,方便后续排查数据的变更情况。如果是使用MySQL,需要5.7及以上版本,具体语法示例如下:
- CREATE TABLE test1 (
- id INT unsigned NOT NULL AUTO_INCREMENT,
- name VARCHAR(225),
- price DECIMAL(10,2),
- create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
- update_time TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
- PRIMARY KEY (id)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3. 可以考虑增加一个逻辑删除列,存储记录的生效状态。这样在删除数据时,可以进行逻辑删除,即把状态为改为失效,而不是真的把数据删掉。

MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。主要分为两种类型,单列索引和组合索引。
接下来,我们一起来看下如何创建不同类型的索引:
语法:
- CREATE TABLE 表名(
- 字段名 数据类型 [完整性约束条件],
- ……,
- [UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
- [索引名](字段名1 [(长度)] [ASC | DESC]) [USING 索引方法]
- );
- 说明:
- UNIQUE:可选。表示索引为唯一性索引。
- FULLTEXT:可选。表示索引为全文索引。
- SPATIAL:可选。表示索引为空间索引。
- INDEX和KEY:用于指定字段为索引,两者作用是一样的。
- 索引名:可选。给创建的索引取一个新名称。
- 字段名1:指定索引对应的字段的名称,该字段必须是前面定义好的字段。
- 长度:可选。指索引的长度,必须是字符串类型才可以使用。
- ASC:可选。表示升序排列。
- DESC:可选。表示降序排列。
- BTree是最常见的索引方法,所有值(被索引的列)都是排过序的,每个叶节点到根节点距离相等。所以BTree适合用来查找某一范围内的数据,而且可以直接支持数据排序(ORDER BY)。还有其他几种索引方法,读者可自行百度了解一下。
建表时创建单列索引和组合索引示例:
- CREATE TABLE classInfo(
- id INT AUTO_INCREMENT COMMENT 'id',
- classname VARCHAR(128) COMMENT '课程名称',
- classid INT COMMENT '课程id',
- classtype VARCHAR(128) COMMENT '课程类型',
- classcode VARCHAR(128) COMMENT '课程代码',
- -- 主键本身也是一种索引
- PRIMARY KEY (id),
- -- 给classid字段创建了唯一索引(注:也可以在上面创建字段时使用unique来创建唯一索引)
- UNIQUE INDEX (classid),
- -- 给classname字段创建普通索引
- INDEX (classname),
- -- 创建组合索引
- INDEX (classtype,classcode)
- -- 指定使用INNODB存储引擎(该引擎支持事务)、utf8字符编码
- ) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT '课程明细表';
语法:
- ALTER TABLE 表名 ADD [UNIQUE| FULLTEXT | SPATIAL] INDEX | KEY [索引名] (字段名1 [(长度)] [ASC | DESC]) [USING 索引方法];
- 或
- CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX 索引名 ON 表名(字段名) [USING 索引方法]
建表后创建单列索引和组合索引示例:
- --将id列设置为主键
- ALTER TABLE classInfo ADD PRIMARY KEY(id) ;
- --给classInfo表中的classid创建唯一索引
- ALTER TABLE classInfo ADD UNIQUE INDEX (classid);
- --给classInfo表中的classname创建普通索引
- ALTER TABLE classInfo ADD INDEX (classname);
- --给classInfo表中的classtype和classcode创建组合索引
- ALTER TABLE classInfo ADD INDEX (classtype,classcode);
索引建立以后,来看下如何对索引进行查看和删除操作。
查看:
- show index from classInfo;
结果:

删除:
- DROP INDEX 索引名 ON 表名
- 或
- ALTER TABLE 表名 DROPINDEX 索引名
示例:
- drop index classname on classInfo;
- alter table classInfo drop index classid;
索引的优点:
索引的缺点:
创建索引的原则:

如果一个SQL执行缓慢,远低于预期,我们该怎么去优化它呢?
关于这个问题,MySQL提供了一个explain命令,它可以对select语句进行分析,并输出SQL执行的详细过程和细节信息,以供开发人员进行针对性的优化。
explain的语法很简单,首先我们通过一个简单的sql查询来了解一下:
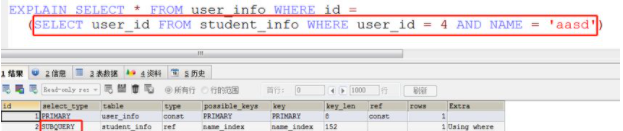
- explain select * from user_info where id = 2
其返回结果如下:

返回的每一个字段代表什么意思呢?
简单总结一下:
- id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
- select_type: SELECT 查询的类型.
- table: 查询的是哪个表.
- type: 访问类型.
- possible_keys: 此次查询中可能选用的索引.
- key: 此次查询中确切使用到的索引,如果没有选择索引,键是NULL.
- key_len:表示查询优化器使用了索引的字节数. 这个字段可以评估组合索引是否完全被使用, 或只有最左部分字段被使用到,如果键是NULL,则长度为NULL。
- ref: 哪个字段或常数与key一起被使用.
- rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
- extra: 额外的信息.
以上各个字段中,我们来重点讲解下select_type、type和extra,其他字段通过以上注释相信大家已经基本能够理解其含义了。
表示查询的类型,它的常用取值有:
(1)SIMPLE,表示此查询不包含 UNION 查询或子查询。示例见上文。
(2)PRIMARY,表示此查询是最外层的查询;
DEPENDENT UNION,子查询UNION语句的第二个或后面的SELECT,取决于外面的查询, 即子查询依赖于外层查询的结果;
DEPENDENT SUBQUERY,子查询中的第一个 SELECT,取决于外面的查询,即子查询依赖于外层查询的结果;
UNION RESULT, UNION 语句的结果集;
示例代码如下,相同颜色标示sql语句与select_type值的相对应。
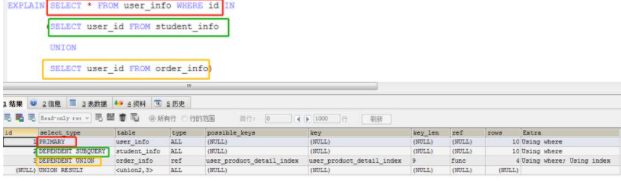
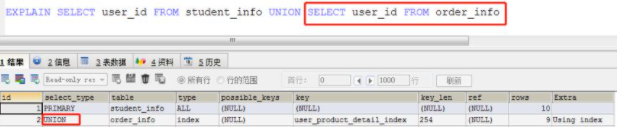
(3)UNION, 表示此查询是使用UNION语句的第二个或后面的SELECT
(4)SUBQUERY, 子查询中的第一个 SELECT
那么DEPENDENT UNION和UNION, DEPENDENT SUBQUERY与SUBQUERY之间有什么区别呢?
顾名思义,关键点就在于DEPENDENT了,它的作用在于标示子查询依赖于外层查询的结果。
在以上第(2)点示例中,内部“student_info.user_id=user_info.id” 与“order_info.user_id=user_info.id”条件会自动添加到UNION所使用的SELECT查询的WHERE条件,然后再执行。
由于外部定义的user_info数据表的id数据列要在子查询中使用,所以DEPENDENT UNION和DEPENDENT SUBQUERY关键字出现在select_type中。
type表示的是访问类型,以上示例中,已经出现了几种type,接下来将常见type值及含义汇总一下:
|
Null >system > const > eq_ref > ref > range > index > ALL ,一般来说,得保证查询至少达到range级别,最好能达到ref。结果值从好到坏依次是:
EXPLAIN 中的很多额外的信息会在 Extra 字段显示, 常见的是以下四种:
|
本章节之前给出的示例中,有出现Using index和Using where,关于另外两种的使用示例读者感兴趣的话可上网百度了解一下,这里就不再继续举例说明了。
能够看懂explain的输出,是对SQL或表结构进行优化的前提。所以,大家需要首先看懂并理解explain输出内容所包含的信息,进而优化实现更加高效的查询。

主从同步,简单来说就是将一个服务器上的数据同步到另一个服务器上。
数据所在的服务器被称为主服务器(Master),接受数据拷贝的服务器被称为从服务器(Slave)。
主从同步主要有以下好处:
为什么要单独强调一下mysql的主从同步机制,那是因为在实际数据分析工作中,当我们通过hive、spark等分布式框架去访问mysql数据库的时候,此时的分布式读取会对服务器产生很大的压力,如果直接读取主库的话,极可能会导致正在运行的主库线上任务暂停几分钟,进而对线上业务造成不良影响。
所以,一般建议尽量通过从库进行数据读取,避免对线上服务造成损害。
由于主从同步相关操作平时都是运维或者DBA他们在维护,作为数据分析人员很少会需要直接实现这些,所以这里对如何实现主从同步等相关知识点就不展开细讲,感兴趣的小伙伴,可参考一下链接,了解一下。
https://blog.csdn.net/qq_15092079/article/details/81672920
上面提到主从同步是一种实时的数据备份方案,通常我们还会定时去对数据库做数据备份。
其目的,是为了防止执行一些灾难性操作后,数据仍然可以恢复。
比如说,删库删表。这是因为主从同步,通常是采用同步操作语句的方式,进行库表结构和数据拷贝的。因此,如果主库执行删除数据库或表的操作,从库也会同步删除。如果有定时备份的数据文件,出现这种情况,只需要把数据反向导入到数据库中,就可以恢复。
mysql提供的数据备份的命令为mysqldump,通常是由DBA或者运维来进行备份操作,大家只需要知道这个知识点即可,方面平时沟通交流。
另外大家要有备份的意识,备份操作是十分必要的,相当于后悔药。在笔者的公司,就发生过几次数据误删的问题,都是通过备份完成恢复的。

show [full] processlist 能显示用户正在运行的线程,这在数据分析工作中对于协助故障诊断非常有帮助。
full关键字,可以不写,如果加上后,会把正在执行的SQL语句完整打印出来。
我们来直接执行一下看看能返回哪些信息:
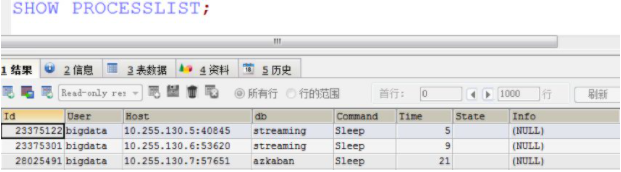
结果中的每个字段含义总结如下:
|
有一种情况,需要大家重点注意下,就是Command中出现Waiting for ... lock字眼时,表示有语句把库或表给锁住了。
通常这个时候,相关的操作库或表的程序就会处于假死状态,表现为程序卡住不动。这时就需要联系DBA或运维看下是什么原因导致锁库或锁表。所以,在你排查程序假死的问题时,如果程序有使用数据库,可以考虑是不是这个因素导致的。
注:show processlist 显示的信息都是来自MySQL系统库 information_schema 中的 processlist 表。所以使用下面的查询语句可以获得相同的结果:
- select * from information_schema.processlist
数据分析工作中的常用操作:
1.按客户端 IP 分组,看哪个客户端的链接数最多
- select client_ip,count(client_ip) as client_num
- from (
- selectsubstring_index(host,':' ,1) as client_ip
- fromprocesslist ) as connect_info
- group by client_ip
- order by client_num desc;
2.查看正在执行的线程,并按 Time 倒排序,看看有没有执行时间特别长的线程
- select *
- from information_schema.processlist
- where Command != 'Sleep'
- order by Time desc;
3.找出所有执行时间超过 5 分钟的线程,拼凑出 kill 语句,方便后面查杀
- select concat('kill ', id, ';')
- from information_schema.processlist
- where Command != 'Sleep' and Time > 300
- order by Time desc;

MySQL默认设置下,一个连接最长等待时间为8小时,如果8小时都处于空闲状态,就会出现连接超时问题,在使用MySQL时相信大家或多或少都会遇到这种状况,这里跟大家分享下在遇到这种情况时,通常采取的措施和解决办法。
首先,查看问题,看下wait_timeout的取值。
打开MySQL的控制台,运行showvariables like '%timeout%',查看和连接时间有关的MySQL系统变量。
然后,解决问题,解决方式常用的有三种。
1. 增加 MySQL 的 wait_timeout 属性的值
- //修改mysql配置文件,重启后生效
- wait_timeout = 31536000
- or
- //通过mysql命令修改
- mysql> set wait_timeout= 31536000;
2. 减少连接池内连接的生存周期
通过代码配置,让线程在mysql提示超时前回收,并重新连接。以下举例为c3p0连接池的配置,其他连接池(如Druid、Dbcp)原理类似。
修改 c3p0 的配置文件,在 Spring 的配置文件中设置:
- <beanid="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
- <property name="maxIdleTime"value="1800"/>
- <!--other properties -->
- </bean>
3. 定期使用连接池内的连接
定期使用连接池内的连接,使得它们不会因为闲置超时而被 MySQL 断开。
修改 c3p0 的配置文件,在 Spring的配置文件中设置:
- <beanid="dataSource"class="com.mchange.v2.c3p0.ComboPooledDataSource">
- <propertyname="preferredTestQuery" value="SELECT 1"/>
- <propertyname="idleConnectionTestPeriod" value="18000"/>
- <propertyname="testConnectionOnCheckout" value="true"/>
- </bean>

普通语言里的布尔型只有 true 和 false 两个值,这种逻辑体系被称为二值逻辑。而 SQL 语言里,除此之外还有第三个值NULL,因此这种逻辑体系被称为三值逻辑。
本章节对于NULL值这部分的讲解重点在于提醒大家对NULL 使用比较谓词后得到的结果总是 NULL 。
这是因为,NULL 既不是值也不是变量。NULL 只是一个表示“没有值”的标记,而比较谓词只适用于值。因此,对并非值的 NULL 使用比较谓词本来就是没有意义的。比如如下几种比较,返回的结果均是NULL 。
- 1 = NULL
- 2 > NULL
- 3 < NULL
- 4 <> NULL
- NULL = NULL
所以,当SQL语句的where条件里有一个字段(比如age)有NULL值,用该字段用于谓词比较判断的时候,比如 age <> 30,表面上理解起来age字段中的NULL值跟30不等,那这个where条件返回的应该是true,从而age字段为NULL的记录应该会被保留下来,实际上不是的,它们比较后返回的结果是NULL ,age字段为NULL的记录会被过滤掉。
因此,要想留下NULL值,正确的写法为,age <> 30 or age is null。在没有学到这个知识点之前,这样进行数据过滤容易导致提取出来的数据结果与预期有偏差。

作为上一篇sql基础的补充,结合实际工作经验,给大家分享一下经常用到的更深层一点的sql技能,包括有DDL、索引、EXPLAIN、主从同步、数据备份、show processlist、wait_timeout和NULL值判断,希望大家有所收获哦!

1.世界上最悲哀的事莫过于睡眠不足,尤其是在感冒的时候。 2.我是一个很有原则...
1.我手机掉进厕所了怎么办?是屎在给我发信息吗? 2.生活就像新闻联播,不是换...
数据目录已成为企业数据管理策略的重要组成部分,但选择合适的数据目录并不是简...
年味到底是什么?不同的时代,人们迎接春节的方式也在变换。 在70后的眼里,年味...
我们将创建以下三个Shell脚本来锁定和解锁多个帐户和查看账号状态。 创建锁定用...
Knative 是基于 Kubernetes 的开源 Serverless 应用编排框架。阿里云 Knative 在...
1.男女之间是真的可以有纯友谊的,只要一个打死不说一个装傻到底。 2.不要迷恋...
新冠肺炎疫情的全球大流行不仅深刻影响了世界政治经济格局的发展演进,而且加速...
作者 许力 阿里云原生多模数据库Lindorm与东软云科技推出联合解决方案 共建面向...
?又到一年毕业季,即将开启(实习及正式)职场生涯的同学们会有不少疑惑。比如,...


