


前言
Hadoop到目前为止发展已经有10余年,版本经过无数次的更新迭代,目前业内大家把Hadoop大的版本分为Hadoop1.0、Hadoop2.0、Hadoop3.0 三个版本。
一、Hadoop 简介
Hadoop版本刚出来的时候是为了解决两个问题:一是海量数据如何存储的问题,一个是海量数据如何计算的问题。Hadoop的核心设计就是HDFS和 Mapreduce.HDFS解决了海量数据如何存储的问题, Mapreduce解决了海量数据如何计算的问题。HDFS的全称:Hadoop Distributed File System。
二、分布式文件系统
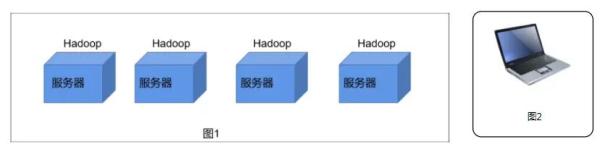
图片 HDFS其实就可以理解为一个分布式文件系统,可以看如图1所示有4个服务器是不是都有他自己的文件系统都可以进行存储数据,假设每个服务器的存储空间存储10G的数据。假设数据量很小的时候存储10G的数据还是ok的当数据量大于服务器的存储空间时是不是单个服务器就没法存储了。 我们是不是可以在服务器中部署一个Hadoop这样就能构建出一个集群(超级大电脑)。这样就存储 4*10=40G的数据量,这样我们面向用户时是不是只有一台超级大的电脑相当于一个分布式文件系统。
HDFS是一个主从的架构、主节点只有一个NemeNode。从节点有多个DataNode。
三、HDFS 架构
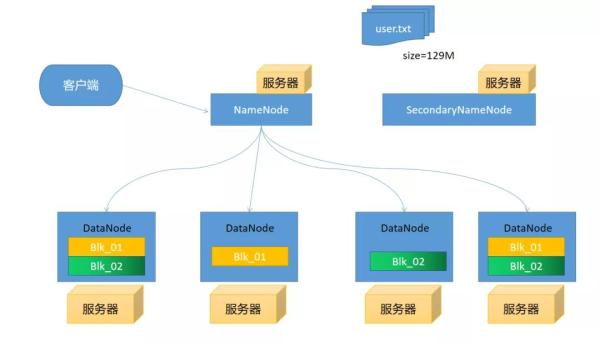
图片 假设我们这里有5台服务器每台服务器都部署上Hadoop,我们随便选择一台服务器部署上NameNode剩下服务器部署上DataNode。
客户端上传文件时假设文件大小为129MHDFS默认切分的大小为128M这时就会产生出2个blkNameNode去通知DataNode上传文件(这里有一定的策略),我们就假设就将这几个文件分别存储在4个服务器上。为什们要进行分别存储在,假设DataNode服务器有一天突然挂掉了我们是不是还可通过DataNode4或2和3进行读取数据,这样是不是就防止数据丢失。
NameNode
DataNode
SecondaryNamenode
周期性的到NameNode节点拉取Edtis和fsimage文件,将这两个文件加入到内存进行 然后将这两个文件加入到内存中进行合并产生新的fsimage发送给NameNode。
四、HDFS写入数据流程
五、HDFS读取数据流程
六、HDFS缺陷
注意:早期版本
总结
上述给大家讲解了简单的HDFS架构,我在最后面留了一个小问题,我会在下期通过画图的方式给大家讲解,我在这里为大家提供大数据的资料需要的朋友可以去下面GitHub去下载,信自己,努力和汗水总会能得到回报的。我是大数据老哥,我们下期见~~~
本文转载自微信公众号「大数据老哥」,可以通过以下二维码关注。转载本文请联系大数据老哥公众号。


基本介绍 给定 n 个权值作为 n 个叶子节点,构造一颗二叉树,若该树的带权路径长...
今年春节黄金周期间,全国零售和餐饮企业销售额首次突破万亿元,根据电商大数据...
本文由 T3 出行大数据平台负责人杨华和资深大数据平台开发工程师王祥虎介绍 Flin...
数据分析师的工作中最离不开的就是数据,业务中所有的情况都离不开数据这个载体...
随着云计算、大数据和机器学习技术的不断发展,各行各业都开始利用大数据分析技...
不少作者跟我们反馈,文章自荐的流程太长了,而且荐完就忘,要不是收到文章上首...
前言 本篇是SLS新版告警系列宣传与培训的第一篇 后续我们会推出20 系列直播与实...
大数据的时代已经来临了,从媒体到企业,再到各国政府,从咖啡馆,到会议室,人人都在...
有同学问:领导总让我们挖掘用户需求,咋个挖掘法?特别是手头还没什么数据,最多...
00、BEGIN 提及 体系 二字,我的脑海里浮现出老板说的 对于工作的规划要从全局出...


