

БОЮФзЊдиздЙЋжкКХ“ЖСаОЪѕ”(IDЃКAI_Discovery)ЁЃ
ШчЙћФувЛжБЙизЂKaggleаТЮХЃЌФЧЖдMechanisms of ActionОКШќгІИУВЛФАЩњЃЌИУБШШќгЩЙўЗ№ДДаТПЦбЇЪЕбщЪвОйАьЃЌНќШеИеИеТфЯТсЁФЛЁЃдкетГЁБШШќжаЃЌЮвКЭДюЕЕAndy WangГЩЙІНјШыЧА4%——дк4373жЇЖгЮщжаХХЕк152УћЃЌЖдДЫЮвИаЕНЪЎЗжНОАСЁЃ

ЦфЪЕЮвУЧЖдгкKaggleБШШќЭІФАЩњЕФЁЃЮвУЧВЛЪЧЛњЦїбЇЯАСьгђЕФзЈвЕШЫЪПЃЌжЛЪЧдкЭјЩЯдкЯпПЮГЬбЇЯАСЫPythonКЭЛњЦїбЇЯАЖјвбЁЃ
ЮугЙжУвЩЃЌЮвУЧВЂУЛгаФУЕНН№ХЦЁЃећГЁБШШќЧА10УћВХгазЪИёЛёЕУН№ХЦЃЌФбЖШЗЧЭЌвЛАуЁЃН№ХЦбЁЪжашвЊИјГіЕФЗНАИЭљЭљЗЧГЃИДдгЁЃЯТУцетЗљЭМОЭЪЧХХУћЕквЛЕФЖгЮщЫљЬсГіЕФ7-modelЗНАИжаЕФвЛВПЗжЃК
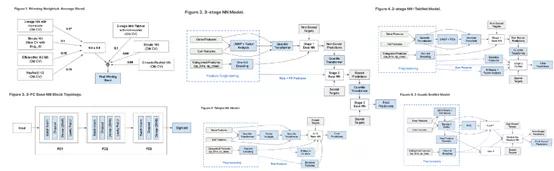
ЭМжагаКмЖрИДдгЭјТчЭиЦЫНсЙЙ
KaggleЭЈГЃЛсВЩЗУЛёЪЄепЃЌДгЖјЩюШыСЫНтЫћУЧЕФНтОіЗНАИ(ДѓЖрЖМЪЧЗЧГЃгХауЕФЗНАИ)ЁЃЕЋЪЧЃЌЮвЗЂЯжетаЉЛёЪЄепКмЩйЬсМАШчКЮФмдкетжжРраЭЕФОКШќжазіЕН“ИпаЇ”ЁЃЛЈЗбДѓСПЕФЪБМфЩшМЦЗНАИЃЌвЛЕувЛЕуЕиЬсИпГЩМЈЃЌЛђаэФмШУВЮШќепЛёЕУН№ХЦвдМАЪ§СППЩЙлЕФЯжН№ЁЃЕЋЪЧЖдгкДѓЖрЪ§ШЫРДЫЕЃЌетжжЗНЪНЕФЪЕВйадВЂВЛИпЁЃ
ЛёЕУН№ХЦгыЛёЕУ3ЭђУРдЊНБН№вВаэжЛга0.0002ЗжжЎВюЁЃ
етЦЊЮФеТжаЃЌЮвЛсСаГіЮвКЭДюЕЕЫљбЇЁЂЫљгУЕФУиОїКЭаЁММЧЩЁЃЮвУЧЛЙдкВЛЖЯЕибЇЯАКЭУўЫїЃЌЯЃЭћетЦЊЮФеТФмЙЛИјДѓМвДјРДжњвцЁЃ
змЕФРДЫЕЃЌЮвУЧЕФУиОїгаСНЕуЃЌЗжБ№ЪЧММФмЦеЪЪадКЭЗНЪНИпаЇадЃЌжЎКѓЛЙПЩвддйЯИЗжЕНММЪѕВуУцКЭВпТдВуУцЁЃ
ММЪѕВуУцММЧЩ
ЯТУцЕФММЧЩЦЋЯђММЪѕВуУцЁЃетаЉБШНЯОпЬхЕФзЈвЕММЧЩПЩвдгУгкБрГЬЗНАИЃЌдкKaggleБШШќгХауЕФВЮШќзїЦЗжавВКмГЃгУЁЃ
1. ЭъУРЮоШБЕФЬиеїЙЄГЬ
ШчЙћЫЕЮвДгетДЮБШШќжабЇЕНСЫЪВУДЃЌФЧОЭЪЧ“ЬиеїЙЄГЬЪЧЙиМќ”ЁЃМђЕЅРДЫЕЃЌЬиеїЙЄГЬОЭЪЧЬсШЁвбгаЬиеїВЂВЛЖЯЬэМгаТЕФЬиеїЃЌетПЩвдЪЧМђЕЅЕФНЋСНСаЯрГЫЁЃ
дкГЃгУЕФЛњЦїбЇЯАЗНЗЈжаЃЌЩёОЭјТчПЩЪгЮЊЩёЦцЕФЭђФмЗНАИЃЌОнЫЕЩёОЭјТчПЩвдДгЪ§ОнжабЇЯАШЮКЮЖЋЮїЁЃВЛЙ§ЪТЪЕВЂЗЧШчДЫЃЌДѓЖрЪ§ЪБКђЃЌвЛИіФЃаЭвЊЯыЭЈЙ§Ъ§ОнбЇЯАЕФЛАЃЌЛЙашвЊШЫРрДгХдажњЁЃ
ФЃаЭЕФгХСгШЁОігкЪ§ОнЕФКУЛЕЃЌзюКУЬсЙЉОЁПЩФмЖрЕФаХЯЂШУдЪМЪ§ОнгавтвхЁЃЖдЬиеїЙЄГЬгаАяжњЕФСНИіЙлЕуЃК
ЬиеїЙЄГЬЪЧвЛУХвеЪѕЁЃзюживЊЕФЪЧвЊМЧзЁдкНјааЬиеїЙЄГЬЪБвЊПМТЧЕНЪ§ОнЛЗОГЁЃШчЙћЪ§ОндкЯжЪЕЩњЛюжаУЛгавтвх(Р§ШчНЋСНИіБЫДЫУЛгаЙиЯЕЕФСаЯрГЫ)ЃЌКмПЩФмВЛЛсАяжњФЃаЭИќКУЕиРэНтЪ§ОнЁЃ

ЭМдДЃКunsplash
2. бЯИёАбПиЙІФмбЁдё
ШЋСІвдИАЕиНјааЬиеїЙЄГЬЪЧКмКУЕФзіЗЈЃЌЕЋЭЌбљживЊЕФЪЧвЊМЧзЁЃЌЙ§ЖрЕФЪ§ОнЛсШУФЃаЭВЛПАжиИКЃЌИјбЇЯАживЊФкШнДјРДРЇФбЁЃОЋШЗХаЖЯФФаЉЬиеївЊСєДцЃЌгжгаФФаЉЬиеївЊЬоГ§ЃЌПЩвдЖдФЃаЭДѓгаёдвцЁЃ
ЭЈГЃЃЌЩОГ§СаЪБвЊОЁСПБЃЪивЛаЉЁЃЪ§ОнВЛПЩЖрЕУЃЌЫљвджЛгаЕБФуШЗЖЈЪ§ОнВЛЛсгаЪВУДгУДІЪБЃЌВХПЩвдАбЫќЩОГ§ЁЃ
3. ЯШРэНтжИБъЃЌдйЩшМЦЗНАИЁЃ
KaggleЛсАДеевЛЖЈЕФжИБъРДЦРЙРВЮШќЗНАИЃЌВЂвдДЫОіЖЈВЮШќепЕФУћДЮЁЃгаЪБКђЛсгУФЃаЭЦРЙРжИБъ(AUC)ЃЌгаЪБвВПЩФмЛсгУЖдЪ§Ы№ЪЇКЏЪ§(logloss)ЁЃKaggleвЛАуЛсдкОКШќИХРРЕФ“ЦРЙР”ВПЗжЬсЙЉЦфгУЕНЕФЙЋЪНЁЃ
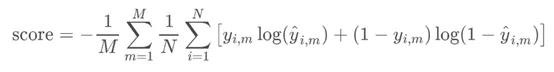
KaggleЮЊMechanismsof ActionОКШќЬсЙЉЕФЙЋЪН
ФуашвЊСєвтетаЉжИБъЃЌвђЮЊЫќУЧЭљЭљОіЖЈСЫВЮШќепИУШчКЮЙЙдьЗНАИЁЃБШШчЃЌЪЙгУвЛИігыЦРЙРКЏЪ§ЗЧГЃЯрЫЦЕФЬиЖЈЫ№ЪЇКЏЪ§ЃЌНЋЬсИпФЃаЭдкИУжИБъЯТЕФадФмЁЃ
вдЖдЪ§Ы№ЪЇКЏЪ§ЮЊР§ЁЃЖдЛЅСЊЭјНјааЩюЭкФмЙЛДјРДКмЖргагУаХЯЂЃЌЖјЖдЪ§Ы№ЪЇКЏЪ§ЛсГЭЗЃздаХЧвДэЮѓЕФдЄВтЁЃвВОЭЪЧЫЕЃЌдкдЄВтжаЃЌФЃаЭдНздаХЃЌЖдЦфДэЮѓадЕФЗЃЗжвВЛсЩЯЩ§ЕФдНПьЁЃЙигкетвЛЕуЛЙгаКмЖрашвЊзаЯИехзУЃК
(1) ЪзЯШЃЌШчЙћЯЕЭГадДэЮѓ(МДФЃаЭВЛФмЖдЪ§ОнНјааРэНт)ЪЙЕУФЃаЭдкЖдЪ§Ы№ЪЇЗНУцЗЧГЃдуИтЃЌФЧУДДЫЪБШУФЃаЭБфЕУИќ“ГйЖл”ПЩФмЛсгаАяжњЁЃжСЩйдкМДНЋвЊЕУГіДэЮѓД№АИжЎЧАЃЌЫќВЛЛсЯдЕУздаХЁЃ
ПЩвдЭЈЙ§діМгЪ§Он(вРЧщПіЖјЖЈ)ЛђепНЕЕЭФЃаЭЕФздаХРДЭъЩЦФЃаЭЁЃШєЪЧЯыЭЕРСЃЌвВПЩвджЛЪЙгУ“ФПБъВУМє”ЃКШчЙћдЄВтаЁгк1%ЛђДѓгк99%ЃЌФЧУДжЛашвЊЗжБ№НЋЦфВУМєдк1%КЭ99%ЁЃетбљОЭБмУтСЫШЮКЮЙ§ЖШздаХЕФД№АИ(ЕБШЛСЫЃЌЛЙгаСэвЛИіЗНЯђОЭЪЧШчКЮШУФЃаЭЕФЯЕЭГЮѓВюИќаЁЃЌИќКУЕФРэНтЪ§Он)ЁЃ
(2) ЦфДЮЃЌвВаэФЃаЭФмЙЛНЯКУЕиРэНтЪ§ОнЁЃЕЋЪЧФЃаЭЙ§гкГйЖлЃЌФЧУДгыЦфЫЕЪЧгаЯЕЭГадДэЮѓЃЌВЛШчЫЕЪЧгаОЋШЗадДэЮѓЁЃетОЭЬсЙЉСЫвЛИіаТЫМТЗЃКПЩвдГЂЪдЬзДќЗЈЛђЦфЫћМЏГЩЗНЗЈЃЌЮШЖЈдЄВтЕФПЩаХЖШЃЌдіЧПдЄВтздаХЁЃ
етаЉЫМЮЌЗНЪНЪЙЕУЪ§бЇжЊЪЖФмЙЛзЊЛЏЮЊЪЕМЪЕФММЪѕЃЌВЂИјЪ§ОнПЦбЇДјРДЮоЯоЕФДДдьадгыШЄЮЖадЁЃ
4. НгЯТРДЪЧНЈФЃЕФЯрЙиВпТд
НЈФЃЕЅЕїЗІЮЖЃЌЪЧвђЮЊЮвУЧЭЈГЃАбНЈФЃЙ§ГЬЪгЮЊЭъГЩШЮЮёЃК
ПДЦ№РДЫЦКѕжЛгагаЯоЕФНЈФЃЫГађЃЌЬиБ№ЪЧдкФуОбщгаЯоЧвВЛЯАЙпЪЙгУЕЭВуДњТыЕФЧщПіЯТЁЃЦфЪЕНЈФЃвеЪѕжавВгаКмЖрРжШЄКЭбЇЮЪЁЃЯТУцЪЧвЛаЉПЩааНЈвщЃК
зюКѓЃЌЛЙгааЉЗНЗЈжЕЕУвЛЪдЃКНЋМЏКЯжаЕФдЄВтНсЙћДДдьадЕиНсКЯдквЛЦ№;Г§ReLUвдЭтЕФМЄЛюКЏЪ§(БШШчЃЌLeaky ReLUЃЌSwish);ЖдЗЧЪїаЮФЃаЭЕФ‘boosting’(НЋЖдвЛИіФЃаЭЕФдЄВтЪфШыЕНСэвЛИіФЃаЭжагУвдбЇЯАДэЮѓ)ЕШЕШЁЃ
УПИіШЫЖМФмНЈФЃЃЌВЛЛсаДTensorFlowЕФдДДњТывВФмПЊЗЂГіИДдгЧвГЩЙІЕФФЃаЭЃЌПЊЗЂФЃаЭжЛашвЊгЕгаДДдьСІКЭЪЕЯжЯыЗЈЕФвтдИЁЃ

ЭМдДЃКunsplash
ВпТдММЧЩВуУц
етВПЗжЬсЕНЕФММЧЩИќЖргыВЮШќепдкОКШќжаЕФВпТдЪЙгУКЭаФРэзДЬЌЯрЙиЁЃ
1. ОГЃВщПДЬжТлЧј
ЮвБиаыГаШЯЃЌЯыГіаТЕФЫМТЗЬЋФбСЫЁЃФмЙЛеОдкдИвтЗжЯэаХЯЂЕФОоШЫМчЩЯвВЭІКУЕФЃЌетжЕЕУЙФРјЁЃетРягаЬЋЖржЕЕУвЛЪдЕФЯыЗЈЃЌЖЈЦкВщПДЬжТлЧјгажњгкСЫНтФФаЉгагУЃЌФФаЉУЛгУЁЃ
БШШќжаЃЌвЛИіУћЮЊTabNetЕФФЃаЭЛёЕУСЫЧАЫљЮДгаЕФГЩЙІЁЃетИіФЃаЭУжВЙСЫЩёОЭјТчдкДІРэБэИёЪ§ОнЩЯЕФШБЯнЁЃвђДЫЃЌЮвУЧЖдЦфНјааСЫбаОПВЂНЋжЎФЩШыСЫЮвУЧЕФзюКѓвЛАцЗНАИЃЌЦфжаОЭАќРЈСЫTabNetЕФСНжжБфЬхЁЃЕЋЪЧЃЌвЊМЧзЁЃЌВЛФмАбБ№ШЫЕФЯыЗЈзїЮЊЬНЫїЕФжеЕуЃЌЖјЪЧвЊзїЮЊвЛИіЬјАхЁЃгавдЯТСНЕудвђЃК
2. ВЛвЊЙ§гкЙизЂЙЋПЊЕФХХааАё
KaggleгавЛИіЙЋПЊЕФХХааАёЯЕЭГКЭвЛИіЗЧЙЋПЊЕФХХааАёЯЕЭГЁЃ
ДгзюжеШЗЖЈЕФХХааАёжаВЛФбЗЂЯжЃЌЙЋПЊЕФХХааАёКЭЗЧЙЋПЊЕФХХааАёжЎМфгаКмДѓЕФВювьЃЌВЮШќепУћДЮПЩФмЛсЧАКѓвЦЖЏЪ§АйИіЮЛДЮЁЃKaggleПЩФмЪЧгУетжжЯЕЭГРДЗРжЙзїБзЁЃ
ВЮШќепдкЙЋПЊЕФХХааАёЩЯЕФУћДЮИќЖрЕФжЛЪЧвЛИіЗЖЮЇЃЌЖјВЛЪЧШЗЖЈЕФЮЛДЮЁЃКмгаПЩФмзюжеЕФУћДЮЛсБШЙЋПЊЕФХХааАёЩЯЕФУћДЮЩЯЯТИЁЖЏ5%ЁЃвђДЫЃЌетФмКмКУЕФЙРСПХХУћЫљдкЕФЗЖЮЇЃЌЕЋЪЧРызюжеЕФУћДЮЛЙгавЛЖЈОрРыЁЃ
ВЛвЊвђЮЊЙЋПЊЕФХХааАёЩЯЕФЗжЪ§ЖјЛваФЩЅЦј(ЛђБИЪмЙФЮш)ЁЃдкБШШќжаЩшМЦЗНАИЪБвЛЖЈвЊМЧзЁЫљИјГіЕФВтЪдЪ§ОнвВжЛЪЧецЪЕЕФВтЪдЪ§ОнЕФвЛаЁВПЗжЖјвбЁЃ
ЧыУњМЧетвЛЧаЖМЪЧЮЊСЫдіГЄМћЪЖ!

ЭМдДЃКunsplash
дкБШШќжаЃЌееАсееГЫћШЫаСПрЫљЕУЕФЗНАИКмШнвзОЭШУШЫЕєШыШІЬзЃЌжЛЮЊСЫЗшПёзЗЧѓдіМгФЧвЛЕуЕуЗжЪ§ЕФСуЭЗЁЃ
KaggleецЕФЪЧвЛГЁвддіГЄМћЪЖЁЂОбщЮЊФПЕФОКШќЁЃЖдгкДѓЖрЪ§ШЫРДЫЕЃЌВЛЙмЪЧЮЂЕїИДдгФЃаЭЃЌЛЙЪЧЮЊСЫЩёОЭјТчзаЯИзСФЅгХЛЏЦїЕФОпЬхБфжжЃЌЖМВЛжЕЕУЛЈЗбЪ§аЁЪБЕФЪБМфЃЌЕЋе§ЪЧетжжДѓСПЕФЪдбщКЭОбщВХЪЧзюзюживЊЕФЁЃ
жЛвЊЮвУЧзЈзЂгкбЇЯАКЭЫМПМЃЌЮвУЧОЭгаПЩФмШЁЕУКмДѓЕФНјВНЁЃетОЭЪЧИпаЇГЩЙІбЇЕФКЫаФЃКРћгУгаЯоЕФОЋСІКЭЪБМфЛёЕУзюДѓЕФбЇЯАаЇЙћЁЃ
KaggleЕФХХУћБОЩэОЭДњБэзХдкЪ§ОнПЦбЇСьгђбЇЯАЕФОоДѓГЩОЭЁЃШЛЖјЃЌГ§ЗЧФувбОгаКмДѓЯЃЭћЛёЕУНБН№(етКмВЛДэ)ЃЌФЧУДетИіХХУћНіНіжЛЪЧвЛИіРяГЬБЎЃЌВЂВЛФмБЃжЄЮЊВЮШќепДјРДШЮКЮЙЄзїЁЃ
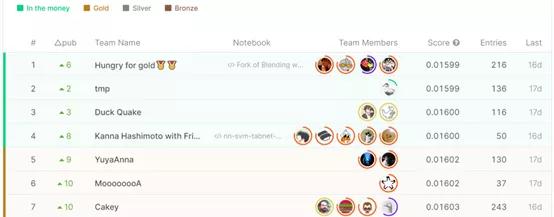
е§ШчMonolith AIЕФИпМЖЪ§ОнПЦбЇМвGareth JonesдквЛЦЊЮФеТжаЫљаДЕФЃК“зюНќЃЌЮвЗЂЯжжСЩйгаСНЮЛЙЭгЖЮвДгЪТЯжНёЙЄзїЕФШЫЭъШЋВЛжЊЕРЮвдкKaggleЕФзЪСЯЃЌОЁЙмдкЮвЕФМђРњЛЙгаСьгЂЕФЖЅВПЖМгаСДНгЁЃ”
“ЛАЫфШчДЫЃЌдкУцЪдЕФЙ§ГЬжаЃЌЮвФмЙЛЯъЯИЕФЬжТлИїжжKaggleЕФЯюФПЁЃвђДЫЃЌKaggleОКШќдкетЗНУцПЯЖЈЪЧЗЧГЃгагУЕФЁЃдкЮвЯждкЫљДгЪТЕФЙЄзїжЎЧАЃЌЮвЕФДѓВПЗжЕФЛњЦїбЇЯАКЭЪЕМљОбщЖМЪЧДгKaggleжаЛёЕУЕФЁЃЮвЯыВЛТлШчКЮЕУРДЕФОбщЖМУжзуефЙѓЁЃ”
ЯывЊЭЈЙ§KaggleЛёЕУОбщЃЌгавдЯТМИИівЊЕуашвЊзЂвтЃК
ЯТУцЪЧвЊЕузмНсЁЃ
ММЪѕбЇЯАЃК
ВпТдбЇЯАЃК
ЯЃЭћФубЇгаЫљЫМЁЂгаЫљЛёЁЃ


ШеЧА АЂРядЦдЦаЇСЊКЯАЂРядЦДѓбЇЭХЖг УцЯђШЋЙњИпаЃбЇзге§ЪНЦєЖЏСЫ83ааДњТыжиЙЙДѓ...
НќЦкНјеЙ дк ffmpeg-go init жЎКѓЃЌЯюФПвВЪеЕНСЫвЛаЉЙизЂЃЌЛЙгаМИИіЭЌбЇЗЂгЪМўЬН...
ЧАбд гябдЕФФкДцЙмРэЪЧгябдЩшМЦЕФвЛИіживЊЗНУцЁЃЫќЪЧОіЖЈгябдадФмЕФживЊвђЫиЁЃЮо...
МјгкНќЦкМгУмЛѕБвДѓеЧЃЌЕМжТКмЖраЁ(ОТ)Аз(ВЫ)ЗзЗзШыГЁЃЌШЛКѓКмЖрШЫЖМдкЮЪЯдПЈЭк...
ЮФБОзїепЃКСѕЯўЙњЃЌElastic ЙЋЫОЩчЧјВМЕРЪІЁЃаТМгЦТЙњСЂДѓбЇЫЖЪПЃЌЮїББЙЄвЕДѓбЇ...
ГЁОАУшЪі зюНќЪЙгУ Redis гіЕНСЫвЛИіРрЫЦЗжВМЪНЫјЕФГЁОАЃЌИњ Redis ЪЕЯжЗжВМЪНЫј...
дЦМЦЫуЗўЮёе§дквдЧАЫљЮДгаЕФЫйЖШдкИїааИївЕПьЫйЦеМАЃЌГЩЮЊITгІгУЕФзюжїСїЪЕЯжаЮ...
AnalyticDB for MySQLЪЧдЦЖЫЭаЙмЕФPBМЖИпВЂЗЂЕЭбгЪБЪ§ОнВжПт ЭЈЙ§AnalyticDB for...
ПЭЛЇНщЩм ЯагуЪЧвРЭаАЂРяЕчЩЬЬхЯЕЕФЧАЬЈаЭвЕЮёЃЌгаЗЧГЃЖРЬиЕФвЕЮёЬиЕуКЭгУЛЇЫпЧѓ...
БОЮФзЊдиздЮЂаХЙЋжкКХЁИМћЯЭЫМБрГЬЁЙЃЌзїепЬЉЖЗЯЭШєШч ЁЃзЊдиБОЮФЧыСЊЯЕМћЯЭЫМБр...

