

在大数据的处理上,起到关键性作用的就是大数据框架,通过大数据系统框架,实现对大规模数据的整合处理。从人工统计分析到计算机,再到今天的分布式计算平台,数据处理速度飞速提高的背后是整体架构的不断演进。当今,市面上可用的大数据框架很多,最流行的莫过于Hadoop,Spark以及Storm这三种了,Hadoop是主流,然而Spark和Storm这两个后起之秀也正以迅猛之势快速发展。接下来让我们一起了解一下这三个平台。
1、Hadoop
说到大数据,首先想到的肯定是Hadoop,因为Hadoop是目前世界上使用最广泛的大数据工具。具有良好的跨平台性,并且可部署在廉价的计算机集群中,在业内应用非常广泛,是的代名词,也是分布式计算架构的鼻祖。凭借极高的容错率和极低的硬件价格,在大数据市场上蒸蒸日上。几乎所有主流厂商都围绕Hadoop进行开发和提供服务,如谷歌、百度、思科、华为、阿里巴巴、微软都支持Hadoop。到目前为止,Hadoop已经成为一个巨大的生态系统,并且已经实现了大量的算法和组件。
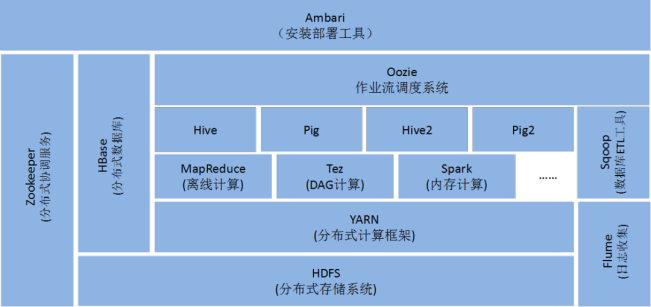
Hadoop框架当中最主要的单个组件就是HDFS、MapReduce以及Yarn。
在大数据处理环节当中,HDFS负责数据存储,MapReduce负责数据计算,Yarn负责资源调度。基于这三个核心组件,Hadoop可以实现对大规模数据的高效处理,同时Hadoop出色的故障处理机制,支持高可伸缩性,容错能力,具有高可用性,更适合大数据平台研发。
但是Hadoop存在比较大的一个局限就是,处理数据主要是离线处理,对于大规模离线数据处理很有一套,但是对于时效性要求很高的数据处理任务,不能实现很好的完成。
作为一种对大量数据进行分布式处理的软件框架,Hadoop具有以下几方面特点:

Hadoop架构大幅提升了计算存储性能,降低计算平台的硬件投入成本。但是由于计算过程放在硬盘上,受制于硬件条件限制,数据的吞吐和处理速度明显不如使用内存快,尤其是在使用Hadoop进行迭代计算时,非常耗资源,且在开发过程中需要编写不少相对底层的代码,不够高效。
2、Spark
基于Hadoop在实时数据处理上的局限,Spark与Storm框架应运而生,具有改进的数据流处理的批处理框架,通过内存计算,实现对大批量实时数据的处理,基于Hadoop架构,弥补了Hadoop在实时数据处理上的不足。为了使程序运行更快,Spark提供了内存计算,减少了迭代计算时的I/O开销。Spark不但具备Hadoop MapReduce的优点,而且解决了其存在的缺陷,逐渐成为当今领域最热门的计算平台。
作为大数据框架的后起之秀,Spark具有更加高效和快速的计算能力,其特点主要有:

我们知道计算模式主要有四种,除了图计算这种特殊类型,其他三种足以应付大部分应用场景,因为实际应用中处理主要就是这三种:复杂的批量数据处理、基于历史数据的交互式查询和基于实时数据流的数据处理。
Hadoop MapReduce主要用于计算,Hive和Impala用于交互式查询,Storm主要用于流式数据处理。以上都只能针对某一种应用,但如果同时存在三种应用需求,Spark就比较合适了。因为Spark的设计理念就是“一个软件栈满足不同应用场景”,它有一套完整的生态系统,既能提供内存计算框架,也可支持多种类型计算(能同时支持、流式计算和交互式查询),提供一站式解决方案。
此外,Spark还能很好地与Hadoop生态系统兼容,Hadoop应用程序可以非常容易地迁移到Spark平台上。
除了数据存储需借助Hadoop的HDFS或Amazon S3之外,其主要功能组件包括Spark Core(基本通用功能,可进行复杂的批处理计算)、Spark SQL(支持基于历史数据的交互式查询计算)、Spark Streaming(支持实时流式计算)、MLlib(提供常用机器学习,支持基于历史数据的数据挖掘)和GraphX(支持图计算)等。
尽管Spark有很多优点,但它并不能完全替代Hadoop,而是主要替代MapReduce计算模型。Spark没有像Hadoop那样有数万个级别的集群,所以在实际应用中,Spark常与Hadoop结合使用,它可以借助YARN来实现资源调度管理,借助HDFS实现分布式存储。此外,比起Hadoop可以用大量廉价计算机集群进行分布式存储计算(成本低),Spark对硬件要求较高,成本也相对高一些。
3、Storm
与Hadoop的批处理模式不同,Storm使用一个流计算框架,该框架由Twitter开源,托管在GitHub上。与Hadoop相似,Storm也提出了两个计算角色,Spout和Bolt。
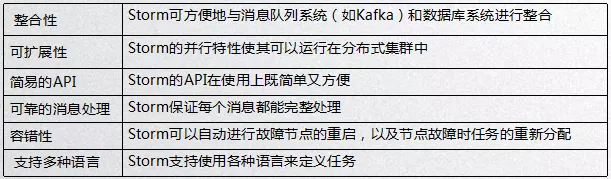
如果说Hadoop是一个水桶,一次只能在一口井里装一个水桶,那么Storm是一个水龙头,它可以打开来连续生产水。Storm还支持许多语言,如Java、Ruby、Python等。因为Storm是一个流计算框架,它使用内存,这在延迟方面有很大优势,但是Storm不会持久化数据。
但Storm的缺点在于,无论是离线、高延迟,还是交互式查询,它都不如Spark框架。不同的机制决定了二者所适用的场景不同,比如炒股,股价的变化不是按秒计算的,因此适合采用计算延迟度为秒级的Spark框架;而在高频交易中,高频获利与否往往就在1ms之间,就比较适合采用实时计算延迟度的Storm框架。
Storm对于实时计算的意义类似于Hadoop对于的意义,可以简单、高效、可靠地处理流式数据并支持多种语言,它能与多种系统进行整合,从而开发出更强大的实时计算系统。
作为一个实时处理流式数据的计算框架,Storm的特点如下:
就像目前云计算市场中风头最劲的混合云一样,越来越多的组织和个人采用混合式大数据平台架构,因为每种架构都有其自身的优缺点。
比如Hadoop,其数据处理速度和难易度都远不如Spark和Storm,但是由于硬盘断电后其数据可以长期保存,因此在处理需要长期存储的数据时还需要借助于它。不过由于Hadoop具有非常好的兼容性,因此也非常容易同Spark和Storm相结合使用,从而满足不同组织和个人的差异化需求。
考虑到网络安全态势所应用的场景,即大部分是复杂批量数据处理(日志事件)和基于历史数据的交互式查询以及数据挖掘,对准实时流式数据处理也会有一部分需求(如会话流的检测分析),建议其大数据平台采用Hadoop和Spark相结合的建设模式。
大数据处理的框架是一直在不断更新优化的,没有哪一种结构能够实现对大数据的完美处理,在真正的大数据平台开发上,需要根据实际需求来考量。

阿里 云服务器 可以试用吗?阿里 云服务器 是可以试用的,不过,试用阿里云 云服...
就在刚刚,Java 16正式发布。 Java 16 正式发布 主要特性 Vector API(孵化) 提升...
是什么让中小企业拥抱了云计算? 对中小企业来说 云服务什么最重要 中小企业上云...
阿里巴巴基于对人、货、场数据体系的深度钻研和思考,积累了深厚的企业、经济、...
欢迎大家加入云开发技术图谱活动 以下是打卡指南 开始打卡前请务必认真阅读 活动...
又到一年 315,面对大数据时代的消费,在给我们的日常生活带来不少便利,但同时...
阿里 云虚拟主机 支持php么?一般来说,阿里云的 虚拟主机 是能够支持php的。用...
美国当地时间 2021 年 2 月 2 日,全球顶级开源社区云原生计算基金会(Cloud Nat...
不懂计算机的她,为何成为了计算机科研界顶流? 大家好,我是鱼皮,今天带大家认...
后端传输网络是 RTC 系统的核心能力 比如阿里云的 GRTN、声网的 SD-RTN 等。本文...

