

Spring事务的基本原理
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。对于纯JDBC操作数据库,想要用到事务,可以按照以下步骤进行:
使用Spring的事务管理功能后,我们可以不再写步骤 2 和 4 的代码,而是由Spirng 自动完成。那么Spring是如何在我们书写的 CRUD 之前和之后开启事务和关闭事务的呢?解决这个问题,也就可以从整体上理解Spring的事务管理实现原理了。
下面简单地介绍下,注解方式为例子
1. 配置文件开启注解驱动,在相关的类和方法上通过注解@Transactional标识。
2. spring 在启动的时候会去解析生成相关的bean,这时候会查看拥有相关注解的类和方法,并且为这些类和方法生成代理,并根据@Transaction的相关参数进行相关配置注入,这样就在代理中为我们把相关的事务处理掉了(开启正常提交事务,异常回滚事务)。
3. 真正的数据库层的事务提交和回滚是通过binlog或者redo log实现的。
Spring的事务机制
所有的数据访问技术都有事务处理机制,这些技术提供了API用来开启事务、提交事务来完成数据操作,或者在发生错误的时候回滚数据。
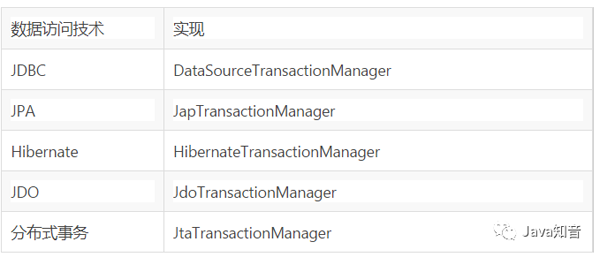
而Spring的事务机制是用统一的机制来处理不同数据访问技术的事务处理。Spring的事务机制提供了一个PlatformTransactionManager接口,不同的数据访问技术的事务使用不同的接口实现,如表所示。
数据访问技术及实现
在程序中定义事务管理器的代码如下:
- @Bean
- public PlatformTransactionManager transactionManager() {
- JpaTransactionManager transactionManager = new JpaTransactionManager();
- transactionManager.setDataSource(dataSource());
- return transactionManager;
- }
声名式事务
Spring支持声名式事务,即使用注解来选择需要使用事务的方法,它使用@Transactional注解在方法上表明该方法需要事务支持。这是一个基于AOP的实现操作。
- @Transactional
- public void saveSomething(Long id, String name) {
- //数据库操作
- }
在此处需要特别注意的是,此@Transactional注解来自org.springframework.transaction.annotation包,而不是javax.transaction。
AOP 代理的两种实现:
Java 动态代理。
具体有如下四步骤:
GCLIB代理
cglib(Code Generation Library)是一个强大的,高性能,高质量的Code生成类库。它可以在运行期扩展Java类与实现Java接口。
原理区别:
java动态代理是利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。而cglib动态代理是利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
如果是类内部方法直接不是走代理,这个时候可以通过维护一个自身实例的代理。
- @Service
- public class PersonServiceImpl implements PersonService {
- @Autowired
- PersonRepository personRepository;
- // 注入自身代理对象,在本类内部方法调用事务的传递性才会生效
- @Autowired
- PersonService selfProxyPersonService;
- /**
- * 测试事务的传递性
- *
- * @param person
- * @return
- */
- @Transactional
- public Person save(Person person) {
- Person p = personRepository.save(person);
- try {
- // 新开事务 独立回滚
- selfProxyPersonService.delete();
- } catch (Exception e) {
- e.printStackTrace();
- }
- try {
- // 使用当前事务 全部回滚
- selfProxyPersonService.save2(person);
- } catch (Exception e) {
- e.printStackTrace();
- }
- personRepository.save(person);
- return p;
- }
- @Transactional
- public void save2(Person person) {
- personRepository.save(person);
- throw new RuntimeException();
- }
- @Transactional(propagation = Propagation.REQUIRES_NEW)
- public void delete() {
- personRepository.delete(1L);
- throw new RuntimeException();
- }
- }
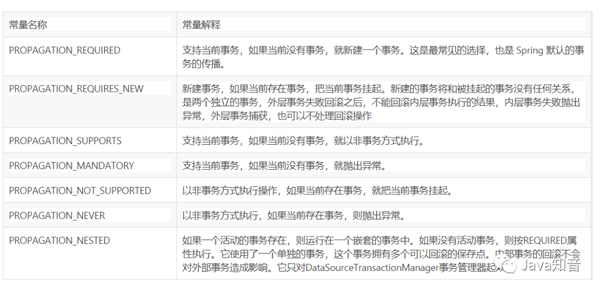
Spring 事务的传播属性
所谓spring事务的传播属性,就是定义在存在多个事务同时存在的时候,spring应该如何处理这些事务的行为。这些属性在TransactionDefinition中定义,具体常量的解释见下表:
数据库隔离级别
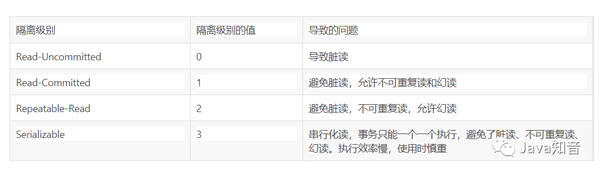
脏读:一事务对数据进行了增删改,但未提交,另一事务可以读取到未提交的数据。如果第一个事务这时候回滚了,那么第二个事务就读到了脏数据。
不可重复读:一个事务中发生了两次读操作,第一次读操作和第二次操作之间,另外一个事务对数据进行了修改,这时候两次读取的数据是不一致的。
幻读:第一个事务对一定范围的数据进行批量修改,第二个事务在这个范围增加一条数据,这时候第一个事务就会丢失对新增数据的修改。
总结:
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。
大多数的数据库默认隔离级别为 Read Commited,比如 SqlServer、Oracle
少数数据库默认隔离级别为:Repeatable Read 比如:MySQL InnoDB
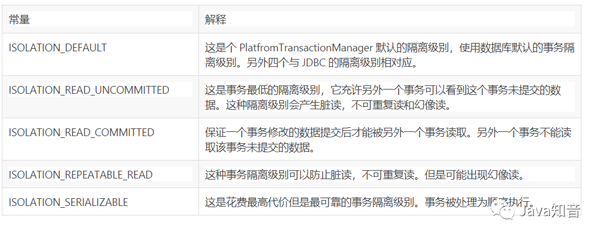
Spring中的隔离级别
事务的嵌套
通过上面的理论知识的铺垫,我们大致知道了数据库事务和spring事务的一些属性和特点,接下来我们通过分析一些嵌套事务的场景,来深入理解spring事务传播的机制。
假设外层事务 Service A 的 Method A() 调用 内层Service B 的 Method B()
PROPAGATION_REQUIRED(spring 默认)
如果ServiceB.methodB() 的事务级别定义为 PROPAGATION_REQUIRED,那么执行 ServiceA.methodA() 的时候spring已经起了事务,这时调用 ServiceB.methodB(),ServiceB.methodB() 看到自己已经运行在 ServiceA.methodA() 的事务内部,就不再起新的事务。
假如 ServiceB.methodB() 运行的时候发现自己没有在事务中,他就会为自己分配一个事务。
这样,在 ServiceA.methodA() 或者在 ServiceB.methodB() 内的任何地方出现异常,事务都会被回滚。
PROPAGATION_REQUIRES_NEW
比如我们设计 ServiceA.methodA() 的事务级别为 PROPAGATION_REQUIRED,ServiceB.methodB() 的事务级别为 PROPAGATION_REQUIRES_NEW。
那么当执行到 ServiceB.methodB() 的时候,ServiceA.methodA() 所在的事务就会挂起,ServiceB.methodB() 会起一个新的事务,等待 ServiceB.methodB() 的事务完成以后,它才继续执行。
他与 PROPAGATION_REQUIRED 的事务区别在于事务的回滚程度了。因为 ServiceB.methodB() 是新起一个事务,那么就是存在两个不同的事务。如果 ServiceB.methodB() 已经提交,那么 ServiceA.methodA() 失败回滚,ServiceB.methodB() 是不会回滚的。如果 ServiceB.methodB() 失败回滚,如果他抛出的异常被 ServiceA.methodA() 捕获,ServiceA.methodA() 事务仍然可能提交(主要看B抛出的异常是不是A会回滚的异常)。
PROPAGATION_SUPPORTS
假设ServiceB.methodB() 的事务级别为 PROPAGATION_SUPPORTS,那么当执行到ServiceB.methodB()时,如果发现ServiceA.methodA()已经开启了一个事务,则加入当前的事务,如果发现ServiceA.methodA()没有开启事务,则自己也不开启事务。这种时候,内部方法的事务性完全依赖于最外层的事务。
PROPAGATION_NESTED
现在的情况就变得比较复杂了, ServiceB.methodB() 的事务属性被配置为 PROPAGATION_NESTED, 此时两者之间又将如何协作呢? ServiceB#methodB 如果 rollback, 那么内部事务(即 ServiceB#methodB) 将回滚到它执行前的 SavePoint 而外部事务(即 ServiceA#methodA) 可以有以下两种处理方式:
a、捕获异常,执行异常分支逻辑
- void methodA() {
- try {
- ServiceB.methodB();
- } catch (SomeException) {
- // 执行其他业务, 如 ServiceC.methodC();
- }
- }
这种方式也是嵌套事务最有价值的地方, 它起到了分支执行的效果, 如果 ServiceB.methodB 失败, 那么执行 ServiceC.methodC(), 而 ServiceB.methodB 已经回滚到它执行之前的 SavePoint, 所以不会产生脏数据(相当于此方法从未执行过), 这种特性可以用在某些特殊的业务中, 而 PROPAGATION_REQUIRED 和 PROPAGATION_REQUIRES_NEW 都没有办法做到这一点。
b、 外部事务回滚/提交 代码不做任何修改, 那么如果内部事务(ServiceB#methodB) rollback, 那么首先 ServiceB.methodB 回滚到它执行之前的 SavePoint(在任何情况下都会如此), 外部事务(即 ServiceA#methodA) 将根据具体的配置决定自己是 commit 还是 rollback
另外三种事务传播属性基本用不到,在此不做分析。
总结
对于项目中需要使用到事务的地方,我建议开发者还是使用spring的TransactionCallback接口来实现事务,不要盲目使用spring事务注解,如果一定要使用注解,那么一定要对spring事务的传播机制和隔离级别有个详细的了解,否则很可能发生意想不到的效果。
Spring Boot 对事务的支持
通过org.springframework.boot.autoconfigure.transaction.TransactionAutoConfiguration类。我们可以看出Spring Boot自动开启了对注解事务的支持 Spring
只读事务(@Transactional(readOnly = true))的一些概念
从这一点设置的时间点开始(时间点a)到这个事务结束的过程中,其他事务所提交的数据,该事务将看不见!(查询中不会出现别人在时间点a之后提交的数据)。
@Transcational(readOnly=true) 这个注解一般会写在业务类上,或者其方法上,用来对其添加事务控制。当括号中添加readOnly=true, 则会告诉底层数据源,这个是一个只读事务,对于JDBC而言,只读事务会有一定的速度优化。而这样写的话,事务控制的其他配置则采用默认值,事务的隔离级别(isolation) 为DEFAULT,也就是跟随底层数据源的隔离级别,事务的传播行为(propagation)则是REQUIRED,所以还是会有事务存在,一代在代码中抛出RuntimeException,依然会导致事务回滚。

随着人工智能技术的兴起以及边缘设备算力的提升,机器视觉的应用场景不断扩展,...
本文档介绍如何在控制台快速购买弹性云服务器。快速购买默认使用“包年/包月”的...
前言 今天说说二叉树。 树 首先看看什么是树??。 如图,这种有节点的结构就是树...
前言 本篇是SLS新版告警系列宣传与培训的第三篇 后续我们会推出20 系列直播与实...
哎呀!距离端午节的.CLUB保留 域名 TOP云 拍卖会只有几天时间了!你们一定会好奇...
本文由 T3 出行大数据平台负责人杨华和资深大数据平台开发工程师王祥虎介绍 Flin...
如今,越来越多的企业依靠人工智能技术为运营业务提供帮助。这项技术非常具有建...
12月9日,小米在日本举行新品发布会,宣布正式进军日本市...
注册域名 费用一般多少钱?一般得看注册什么 域名 后缀,注册域名的品相和含义怎...
在 C++ 中,对文件的读写可以通过使用输入输出流与流运算符 和 来进行。当读写文...

