


在以前的文章中,我们讲到了什么时候用 Yaml,什么时候用 JSON,什么时候用 Protobuf:
JSON 作为几乎每一个语言都支持的序列化格式,在很多地方都得到了广泛应用。但有个弊端,JSON 里面充斥了大量的大括号、中括号和双引号,导致冗余的字符太多,数据量非常大,在对传输速度有高要求的场景下,数据量越大,占用的传输带宽就越大,单位时间传输的数据也就越少。
Protobuf 是 Google 开发的一个二进制序列化格式,与 JSON 相比,Protobuf 的数据非常精简,甚至连数据的字段名都没有。例如有这样一段数据:
- a = {'name': 'kingname', 'salary': 99999, 'address': '上海', 'skill': ['Python', '爬虫', 'Golang']}
如果用 Protobuf 来表示,那么数据的二进制形式是这样的:
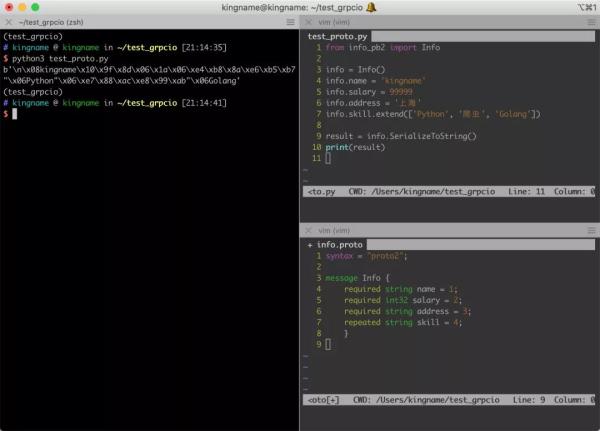
这个二进制数据只有值,但没有字段名,所以要解析这些数据,必须在代码里面额外把字段名带上。所以需要定义一个xxx.proto文件,在里面标记每一个字段的信息。在任何时候任何语言中,需要序列化和反序列化的地方,都要提前使用protoc命令,基于这个.proto文件,生成一个xxx_pb2文件,通过从这个 xxx_pb2文件中导入数据对象来对数据进行处理。
因此,我们说,proto 格式,虽然确实精简了网络中的数据传输量,但却给开发者增加了相当大的工作量。
而最近,又新出来一种二进制序列化格式:CBOR,它的数据比 JSON 小,但是开发起来又比 Protobuf 简单得多。
我们来看看使用 CBOR 对上面的数据进行序列化操作。首先在 Python 中安装CBOR:
- python3 -m pip install cbor2
安装完成以后,我们来对数据进行序列化:
- import cbor2
- a = {'name': 'kingname', 'salary': 99999, 'address': '上海', 'skill': ['Python', '爬虫', 'Golang']}
- result = cbor2.dumps(a)
- print(result)
运行效果如下图所示:
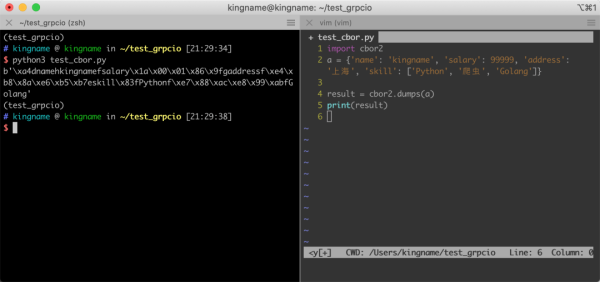
注意,打印出来的是二进制数据,不是字符串。可以看到,数据是自带字段名的,字段名与值之间会有特殊的字符进行分割,CBOR 能够自动识别这些特殊符号,从而区分字段名和字段值。
经过我的测试,一个150MB 的大 JSON文件,读入到内存,然后重新通过 CBOR 序列化以后写文件,这个文件大小可以缩减到60MB 左右。虽然压缩比例不如 Protobuf,可读性不如 JSON;但是压缩比例比 JSON 高,可读性比 Protobuf 好,而且几乎不增加额外工作量。
大家在写微服务或者网站前后端通信的时候,可以考虑试一试 CBOR — Concise Binary Object Representation | Overview[1]。
参考资料
[1]CBOR — Concise Binary Object Representation | Overview: https://cbor.io/
本文转载自微信公众号「未闻Code」,可以通过以下二维码关注。转载本文请联系未闻Code公众号。


TOP云 (west.cn)8月14日消息,本期的sedo 域名交易 榜共有63个 域名 超2000美...
步入2月,美股新一轮财报季渐入高潮。 本周二,包括阿里巴巴、亚马逊、谷歌在内...
Cloud-init是开源的云初始化程序,能够对新创建弹性云服务器中指定的自定义信息...
操作场景 本节操作介绍在Windows和Linux环境中使用SSH密钥对方式远程登录Linux云...
本文转载自公众号读芯术(ID:AI_Discovery) 下面这个模型在一项图像识别竞赛中经...
据IDC评述网(idcps.com)报道,ntldstats.com最新数据显示,截止至2016年3月31...
1. 接口描述 接口请求域名: cvm.tencentcloudapi.com 。 本接口 (ResetInstance...
每年618是年中购物节,每到这一天,大家都会进入网购模式,疯狂的买买买。618购...
【编者的话】本文作者利用自己云原生工程师的优势,分享了他对2021年及之后的云...
云计算服务正在以前所未有的速度在各行各业快速普及,成为IT应用的最主流实现形...

