

公司简介
塑云科技作为一支创业团队,专注于氢能燃料电池生态链的运营支撑,当前主要的业务组成为新能源车整车实时运营监控分析,加氢站实时运营监控分析,车辆安全运营支撑。
业务痛点
- 系统架构中未对OLAP和OLTP系统的范围进行清晰界定,使用JAVA程序对表格存储的表定时进行任务统计,代码复杂并且性能极差并且影响到服务器上其他OLTP系统的正常运行。
- 存储的解析后的报文数据,未针对表格存储的计价规则进行针对性优化,一个大JSON串中冗余的KEY过多,KEY的长度超长(平均30个字符串)。
- 表格存储(阿里云Tablestore)按照公司进行分表设计,存在单个实例下表数量超过表格存储限制(64表)的风险。
- 表格存储以车月作为分区键,单个分区(30G)过大,超过表格存储建议的1G推荐大小。
- 表格存储单车的分区连续分布未做散列,不能在物理机器层面最优并发性能。
- 没有针对最核心的读取场景(按天按车查询报文)进行编码层面的优化。
- 高频数据的实时解析、存储、分析。拿整车实时运营监控分析来讲,每辆车以每秒1K的原始报文上报,要求做到秒级延迟的解析应答以及入库。同时需要针对解析后的每车每秒33K的报文进行快速查询以及后继的分析。
- 考虑到未来车辆接入的量,需要在考虑性能的基础上以最经济的方式进行系统设计。
- 按照每车每秒33K的解析后报文,每车每月预计生成30G的报文数据(车辆按照每天运行10小时计算)。
解决方案
在做系统优化之前,首先要做的就是架构层面的梳理,对产品中需要使用到的中间件产品的适用范围进行了明确的界定。数据在各个环节的流转进行明确的定义如下:
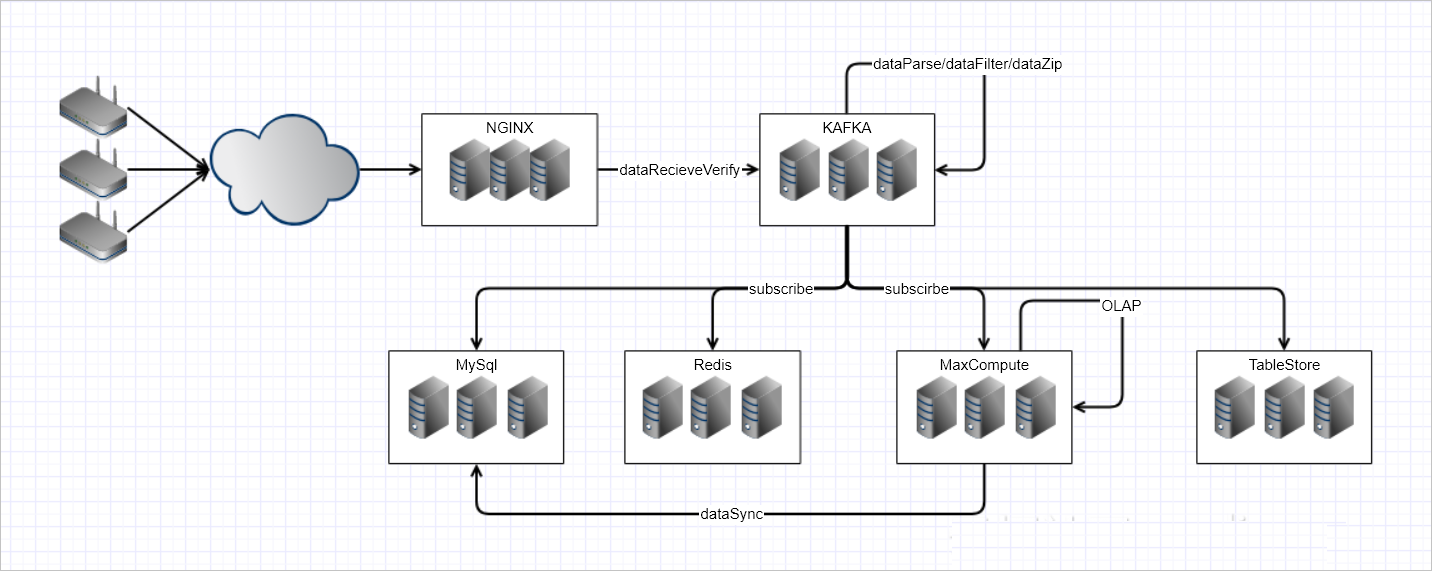
- 引入KAFKA 作为多个环节异步解耦的基础支撑,提升对终端的报文快速回复。
- 引入MaxCompute 作为OLAP系统的基础支撑。将复杂的业务分析转交给MaxCompute 来处理。
- 针对表格存储的计价原则,对表格存储的模型进行了重构。
上云价值
- 性能和成本:
- 根据数据的使用频度将数据切分为在线、 离线、归档三类。车辆终端上报的报文数据作为归档数据选择OSS的归档存储。 在线数据设定N 月的生命周期,主要包括报文解析之后需要实时查询的数据,离线 数据主要包括基于解析的报文数据进行离线分析统计之后形成的各类中间结果、报表数据。
- 针对数据的使用场景界定数据类型之后,这里主要考虑离线数据使用OSS 还是 MaxCompute(ODPS)或者是表格存储来存储的问题。三类产品的存储计算成本对比如下:

表格中已经考虑了通过压缩的方式存储表格存储减少计价存储的情况。MaxCompute 的计价是按照实际压缩存储之后的容量计算。MaxCompute 官方文档介绍的是 5:1 的压缩比,而我们的数据因为本身的特点,实测可以到7~8 :1 的压缩比,所以最后数据方案反倒是MaxCompute 直接存储离线数据性价比最高。同时也符合数据靠近计算的原则。
经过测试使用表格存储外部表作为数据载体的计算性能一般。当前MaxCompute 对表格存储的外部表的Map Reduce 计算直觉觉得是基于表格存储的分片,并且缺少分区的概念,每次都是基于全表扫描,这点可以从MaxCompute 的任务详情可以观测出来。
- 运维能力:
技术选型确定以后,需要考虑如何利用MaxCompute 为业务提供可靠、稳定数据服务。这里特别需要强调的是数仓的建模、数据集成、工作运维的使用。 数据集成主要这方面主要体现MYSQL 跟MaxCompute 的双向同步,,主要是设计上需要考虑到数据的重复同步的设计即可。关于工作运维则是更多地体现在对任务的运行状况的监控以及重跑的支持。
数仓的建模主要考虑的还是成本和模型的复用。首先针对海量、质量不高的底层数据进行分层建模。保证上层的业务模型只依赖中间结果。这里带来的直接效益就是计算成本的大幅下降。其次是中间模型为系统补数带来更快的性能,毕竟因为一些业务或者数据的原因需要重跑部分报表,这个时候如果需要重新扫描原始数据的时候,首先就是费钱,其次就是耗时。
相关产品
- 大数据计算服务 · MaxCompute
MaxCompute(原ODPS)是一项大数据计算服务,它能提供快速、完全托管的PB级数据仓库解决方案,使您可以经济并高效的分析处理海量数据。
更多关于阿里云MaxCompute的介绍,参见MaxCompute产品详情页。
- 云数据库RDS MySQL版
MySQL 是全球最受欢迎的开源数据库之一,作为开源软件组合 LAMP(Linux + Apache + MySQL + Perl/PHP/Python)中的重要一环,广泛应用于各类应用场景。
更多关于云数据库RDS MySQL版的介绍,参见云数据库RDS MySQL版产品详情页。
- 云数据库 Redis 版
阿里云数据库Redis版是兼容开源Redis协议标准、提供内存加硬盘混合存储的数据库服务,基于高可靠双机热备架构及可平滑扩展的集群架构,可充分满足高吞吐、低延迟及弹性变配的业务需求。
更多关于云数据库 Redis 版的介绍,参见云数据库 Redis 版产品详情页。
- 消息队列 Kafka 版
消息队列 Kafka 版是阿里云基于 Apache Kafka 构建的高吞吐量、高可扩展性的分布式消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等,是大数据生态中不可或缺的产品之一,阿里云提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
更多关于消息队列 Kafka 版的介绍,参见消息队列 Kafka 版产品详情页。


