

通过面试多家大型互联网企业,总结了如下的高频面试题目:
1、redis 过期键的删除策略?
2、Redus的淘汰策略
redis 内存数据集大小上升到一定大小的时候,就会施行 数据淘汰策略 。redis 提供6种数据淘汰策略:
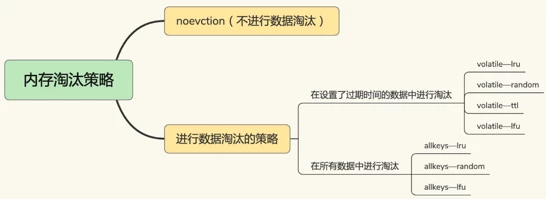
通过淘汰策略也能保证Redis中缓存的都是热点数据。
一个客户端运行了新的命令,添加了新的数据。Redi 检查内存使用情况,如果大于 maxmemory 的限制, 则根据设定好的策略进行回收。
注意这里的 6 种机制,volatile 和 allkeys 规定了是对已设置过期时间的数据集淘汰数据还是从全部数据集淘汰数据,后面的 lru、ttl 以及 random 是三种不同的淘汰策略,再加上一种 no-enviction 永不回收的策略。
使用策略规则:如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用 allkeys-lru;如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用
- allkeys-random
3、Redis分布式锁的实现
Redis的分布式缓存特性使其成为了分布式锁的一种基础实现。通过Redis中是否存在某个锁ID,则可以判断是否上锁。为了保证判断锁是否存在的原子性,保证只有一个线程获取同一把锁,Redis有 SETNX (即SET if Note Exists)和 GETSET (先写新值,返回旧值,原子性操作,可以用于分辨是不是首次操作)操作。
(1)关于setnx:
(2)关于set:一般操作
为了防止主机宕机或网络断开之后的死锁,Redis没有ZK那种天然的实现方式,只能依赖设置超时时间来规避。所以如果使用setnx来实现分布式锁,则实现步骤如下:
Redis 的 setnx 命令是当 key 不存在时设置 key ,但 setnx 不能同时完成 expire 设置失效时长,不能保证 setnx 和 expire 的原子性。我们可以使用 set 命令完成 setnx 和 expire 的操作,并且这种操作是原子操作。举个例子如下:
- 案例:设置name=p7+,失效时长100s,不存在时设置
- 1.1.1.1:6379> set name p7+ ex 100 nx
- OK
- 1.1.1.1:6379> get name
- "p7+"
- 1.1.1.1:6379> ttl name
- (integer) 94
从上面可以看出,多个命令放在同一个 redis 连接中并且 redis 是单线程的,因此上面的操作可以看成 setnx 和 expire 的结合体,是原子性的。
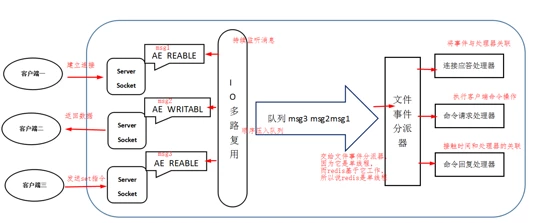
4、Redis的Reactor模式
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。
因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。
5、redis支持事务回滚吗?
“ 不支持回滚动作,redis是支持简单事务模式,只能discard,不能rollback ”
Redis在执行事务命令的时候,在命令入队的时候, Redis 就会检测事务的命令是否正确,如果不正确则会产生错误。无论之前和之后的命令都会被事务所回滚,就变为什么都没有执行。
当命令格式正确,而因为操作数据结构引起的错误 ,则该命令执行出现错误,而其之前和之后的命令都会被正常执行。这点和数据库很不一样,这是需注意的地方。
对于一些重要的操作,我们必须通过程序去检测数据的正确性,以保证 Redis 事务的正确执行,避免出现数据不一致的情况。 Redis 之所以保持这样简易的事务,完全是为了保证移动互联网的核心问题一性能。
6、Redis的事务机制及CAS
watch指令在redis事物中提供了CAS的行为。为了检测被watch的keys在是否有多个clients同时改变引起冲突,这些keys将会被监控。如果至少有一个被监控的key在执行exec命令前被修改,整个事物将会回滚,不执行任何动作,从而保证原子性操作,并且执行exec会得到null的回复。
7、Redis和Memcached的区别
Redis的特性:
与Memcached的区别在于:
Redis直接自己构建了VM(Virtual Memory)机制 ,因为一般的系统调用系统函数的话(例如java调用自己的API),会浪费一定的时间去移动和请求。
8、缓存穿透、缓存击穿和缓存雪崩
(1)缓存穿透
查询不存在的数据,缓存中没有数据,数据库也没有数据。因此所有的请求都访问到了数据库,给数据库造成了压力。解决方法如下:
采用布隆过滤器,将所有可能存在的数据,哈希到一个很大的 bitmap 中,一个一定不存在的数据会被 bitmap 拦截调,从而避免了对数据库的查询压力。
如果查询的数据为空,那么直接将空数据也缓存起来并设置较短的过期时间。这样下次访问的时候,就直接返回空值。
(2)缓存击穿
缓存击穿是指缓存过期之后,瞬时间并发客户端特别多查询同一条数据的情况下,导致数据库压力过大。业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,
而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,
再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。类似下面的代码:
- public String get(String key) {
- String value = redis.get(key);
- if (value == null) { // 代表缓存值过期
- // 设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
- if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { // 代表设置成功
- value = db.get(key);
- redis.set(key, value, expire_secs);
- redis.del(key_mutex);
- }
- // 这个时候代表同时候的其他线程已经load db并回设到缓存了,
- // 这时候重试获取缓存值即可
- else {
- sleep(50);
- get(key); // 重试
- }
- } else {
- return value;
- }
- }
(3)缓存雪崩
雪崩就是指缓存中大批量热点数据过期后系统涌入大量查询请求,因为大部分数据在Redis层已经失效,请求渗透到数据库层,大批量请求犹如洪水一般涌入,引起数据库压力造成查询堵塞甚至宕机。
解决办法:
将缓存失效时间分散开,比如每个key的过期时间是随机,防止同一时间大量数据过期现象发生,这样不会出现同一时间全部请求都落在数据库层,如果缓存数据库是分布式部署,将热点数据均匀分布在不同Redis和数据库中,有效分担压力,别一个人扛。
让Redis数据永不过期(如果业务准许)。
9、Redis数据倾斜
1、存在bigkey:业务层避免创建bigkey,把集合类型的bigkey拆分成多个小集合,分散保存bigkey 保存了大量集合元素(集合类型),会导致这个实例的数据量增加,内存资源消耗也相应增加。bigkey 的操作一般都会造成实例 IO 线程阻塞,如果 bigkey 的访问量比较大,就会影响到这个实例上的其它请求被处理的速度。
2、slot手工分配不均匀:避免把较多的slot分配到一个实例上,进行槽的迁移
3、存在热点数据:采用带有不同key前缀的多副本方法。 我们把热点数据复制多份,在每一个数据副本的 key 中增加一个随机前缀,让它和其它副本数据不会被映射到同一个 Slot 中。这样一来, 热点数据既有多个副本可以同时服务请求,同时,这些副本数据的 key 又不一样,会被映射到不同的 Slot 中。在给这些 Slot 分配实例时, 我们也要注意把它们分配到不同的实例上,那么,热点数据的访问压力就被分散到不同的实例上了。 热点数据多副本方法只能针对只读的热点数据。如果热点数据是有读有写的话,就不适合采用多副本方法了,因为要保证多副本间的数据一致性,会带来额外的开销。
10、为什么Redis单线程模型也能效率这么高?
11、Redis做异步和延时队列?
一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep 一会再重试。如果对方追问可不可以不用 sleep 呢?list 还有个指令叫 blpop,在没有消息的时候,它会阻塞住直到消息到来。如果对 方追问能不能生产一次消费多次呢?使用 pub/sub 主题订阅者模式,可以实现 1:N 的消息队列。
使用 zset(有序集合),拿时间戳作为score,消息内容作为 key 调用 zadd 来生产消息,消费者用 zrangebyscore 指令获取 N 秒之前的数据轮询进行处理。
12、Redis的集群策略
(1)Redis主从同步Redis的主从结构一主一从,一主多从或级联结构,复制类型可以根据是否是全量而分为全量同步和增量同步。
(2)Redis哨兵 在主从复制实现之后,如果想对master进行监控,Redis提供了一种哨兵机制,哨兵的含义就是监控Redis系统的运行状态,并做相应的响应。Redis Sentinal 着眼于高可用,在 master 宕机时会自动将 slave 提升为master,继续提供服务。
(3)Redis Cluster 着眼于扩展性,在单个 redis 内存不足时,使用 Cluster 进行分片存储。在redis-cluster架构中,redis-master节点一般用于接收读写,而redis-slave节点则一般只用于备份,其与对应的master拥有相同的slot集合,若某个redis-master意外失效,则再将其对应的slave进行升级为临时redis-master。
13、 Redis 的同步机制
Redis 可以使用主从同步,从从同步。第一次同步时,主节点做一次 bgsave,并同时将后续修改操作记录到内存 buffer,待完成后将 rdb 文件全量同步到复制节点,复制节点接受完成后将 rdb 镜像加载到内存。加载完成后,再通知主节点
将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。

阿里巴巴、腾讯、支付宝、网易、IBM、谷歌、京东、 百度、滴滴等一线互联网公司...
本月DataWorks产品月刊为您带来 产品活动 1.参与阿里云DataWorks问卷调研 (Aliyu...
【51CTO.com快译】 数据分析是对数据进行判断、细化、更改和建模的过程,目的是...
大家在开发Python的过程中,一定会遇到很多反斜杠的问题,很多人被反斜杠的数量...
人脸识别 是目前商业应用最成熟、最广泛的人工智能技术之一,成为开发者、企业接...
大数据市场如今正在呈爆炸式增长。根据调研机构Markets and Markets公司的调查,...
操作场景 您可以删除不需要的私有镜像。 删除私有镜像后,将无法找回,请谨慎操...
公司介绍 长沙营智信息技术有限公司旗下易撰网,2017年10月份上线以来,基于数据...
案例背景 永安稻香小镇的体验式数字农业基地是余杭街道依托“阿里以西10分钟”的...
【51CTO.com快译】不知道您是否听说过软件架构师最讨厌意大利面这个梗?它是指软...

